产品开发过程中,我们经常会遇到各种决策问题。本文将为你介绍,硅谷决定产品走向的最终统计学判据 — “p 第一组,有95个人看到了,有4个人打开了App。
第二组,有107个人看到了,有11个人打开了App。
跟上面按钮颜色的例子数据处理一样,你开始进行了数据分析:
第一组,是非个性化的推送,接收到推送之后,用户的App打开率是 4 / 95 = 4.21%
对于第二组的个性化推送组,App打开率是11 / 107 = 10.28%。
于是你直接得出结论:第二组更好!
事情就……结束了么?要是在硅谷的话,你会被直接喷回来。
为什么??因为这个结论,根本不可靠!两组的打开App的行为很有可能只是巧合,是一个完全随机的事情!
比如,你先用左手抛硬币5次,发现2次硬币正面朝上。之后再用右手抛硬币5次,发现3次硬币正面朝上。 于是你得出结论,右手抛硬币出现正面的概率是60%,高于左手的40%。 – 这明显是错误的。因为无论那个手抛硬币,都应该是50%的概率而已。
同样的道理,回到推送的分析案例,那凭什么,你在这里就能直接相信这个结果呢?提高的打开率,真的是因为“个性化”的原因造成的呢,还是仅仅只是一个巧合呢?
对于此,统计学上会有一个概念,叫做 – “p值” 。
p值是啥?
在展开复杂的计算之前,为防止你被绕晕,先直接上一句最最最简单的灵魂总结:
p值,就是实验结果不能被相信的概率。
也就是说,p值就是“实验结果完全是瞎猫碰到死耗子”的几率。
直觉告诉我们,这个p值应该是越低越好,因为越低,他就表示我们的实验越可以被相信。
那么多低是低呢?标准是啥?硅谷各公司,普遍采用的p值标准线是0.05。 如果p小于0.05,那结论就可以被相信了!
下面咱们来计算一下p值。(需要你静下心来读)
统计方法上,我们会先来一个 “无效假设(Null Hypothesis)” :也就是假设结果纯属巧合,也就是假设“个性化”通知根本没啥卵用。如果没啥用的话,那就是说。。。两组之间的实际App打开率应该相等的*(此处有简化,详情见文末)。
我们来算一下,第一组的App打开率 4/95 = 4.21%。
下面,重点来了,我们需要计算的是,按照4.21%这个打开率,第二组出现11个人打开App的概率是多少呢?这个概率,就是“无效假设”成立的概率。
无论文科理科,这是一道高考送分题,答案就是: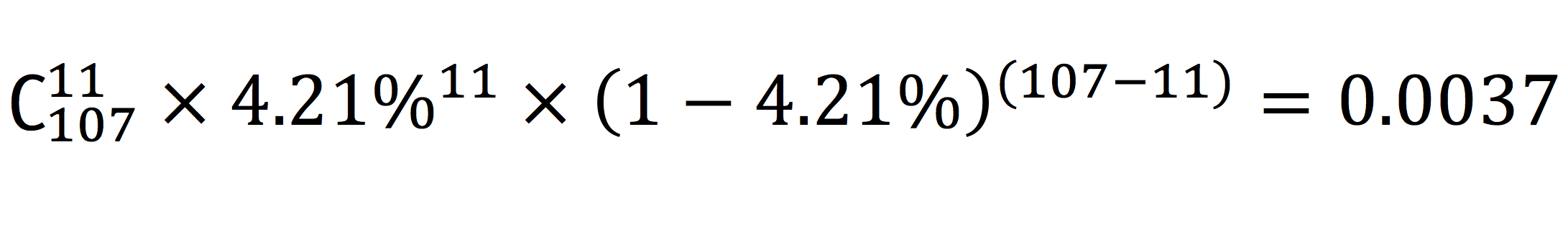
这个值,就是p值, p = 0.0037。它代表, “个性化通知”没有任何用处的概率仅为0.0037。
刚刚说过,p值的检测标准是0.05,你看,咱打开率的p值小于0.05,那么就可以说实验可信! “个性化”通知,对于促进用户打开App,有效!你们决定上线新产品!
可是就在这时,数据部门,突然给你发来了最新的另一组数据。。。
实战应用
数据部门告诉你,用户看了推送通知之后,其实还有一些用户有删除App的行为发生。可能是因为看了太多推送太烦了,直接删了App。数据是这样的: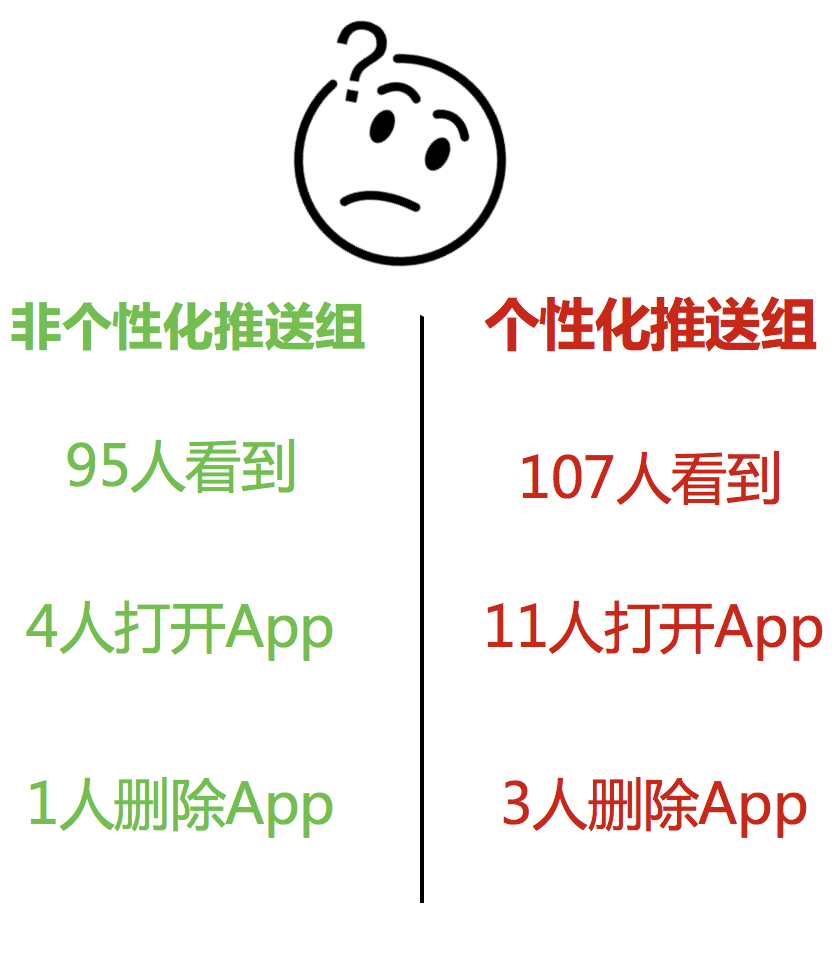
现在这样看来,第二组收到个性化推送的人,删除率是2.8%,高于第一组的1.1%。甚至都已经双倍了!难道是因为用户看到了自己的名字在推送里,很害怕然后就把App删掉了?
这可怎么评价啊!!太烦了,要是两组数据结论不同,还怎么上线新产品啊。。。看来又要撕逼了,哎。
稍等,我们刚刚介绍了p值的概念呀!!赶紧计算一下删除率的p值!
经过一番计算,删除率的p值等于……p = 0.1795!!大于0.05,什么意思,p值大于上面提到的分界线!也就是说, 删除率上升,纯属偶然 !
这下好啦!! 产品决策清晰了!
相比原来的非个性化推送,我们发现个性化的推送 打开率 有 显著性提升 ,而 删除率 则 没有显著的统计学差异 。
于是,你欢快地决定:上线“个性化推送”功能!! 今晚请大家吃鸡!!
A/B测试
上面提到的,整个新产品的验证过程,被称之为“A/B Test”(AB测试)。A和B就是指,实验里的两个组。
AB测试是最最简单的工具啦,实际工作中会遇到更多的奇葩情况,那“A/B Test”可就不够了。比如,涉及到两个用户以上的社交功能,还有涉及到“钱”的情况等等,这些我以后再讲。。。
可以说, 硅谷就是由实验驱动着的 。无论是一个小小的UI变动,还是推荐算法模型的升级,都会进行一次实验。因为实在是太常用了,很多大型App里,往往同时运行着超级多的实验。
为了提高效率,各厂们都纷纷开发了,专门的实验工具和分析系统,让人们快速使用。
比如:
Google 旗下Analytics产品的Content Experiments工具:
他可以快速的通过UI创建一个实验,还能在运行时,利用Multi-armed bandit算法,自动调整并分配流量比例,到不同的用户组,以加快实验速度。结束后,还会自动生成报表。
Uber 的实验平台 XP :
XP不仅是实验和分析工具,还帮助Uber安全上线和部署新功能,实时观测数据。
Airbnb 的实验框架 ERF (Experimentation Reporting Framework):
ERF的交互设计非常好,还提供了美观的报表系统,p值一目了然: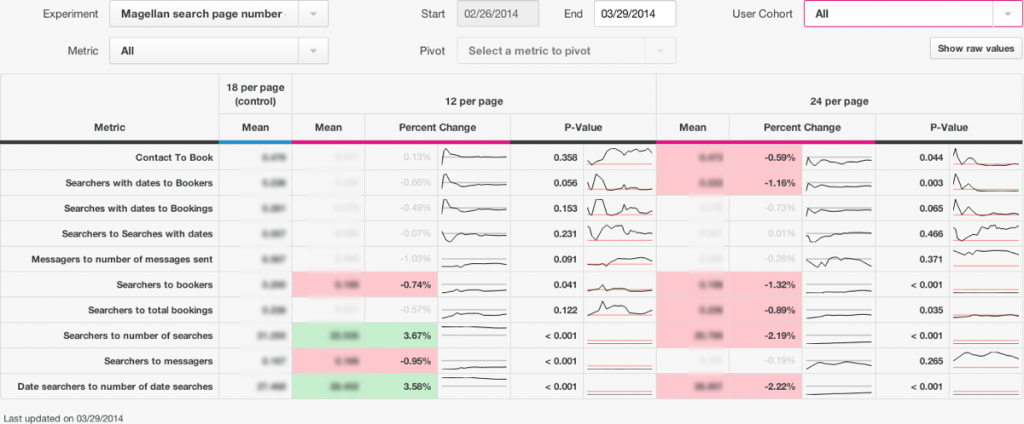
Netflix 的跨平台实验工具 ABlaze :
他有着跨平台的优良特性。要知道,其实Netflix的压力非常大。数据发现,如果用户不能在90秒内找到自己喜欢的影片,他们就会关掉App。借助ABlaze,Netflix得以快速迭代产品,以便满足全球超过一亿用户的观影需求。
其实,这里还是要提一句,硅谷各企业的产品决策, 绝对不是只考虑“p<0.05”这么简单啦。
这里也仅是出于科普的目的,对实际情况进行了极大的简化。
比如,当年 “扁平化设计” 刚出的时候,通过数据来看,用户肯定不满意,觉得丑。但是苹果, 偏是不听呢 ~ 就要上线,就要上线,就要上线~ 最后你看,用户乃至业界还不都是被成功的教育了。
更进一步
你可能会问,为啥这些硅谷企业都选0.05这个数字呢?
答案就是:
嗯……其实这个真的就只是一个约定俗成的数值而已。
Tommy告诉我,提出这个值的人,还是和英国有关。这是几十年前,英国统计学家Ronald Fisher提出来的,后人沿用了而已。
当然,很多产品为了更加可靠,也会使用更低的p值, 比如0.01。
不仅仅是硅谷这样的工业界啦, 在学术界 ,尤其是统计学支撑的学科,比如心理学,生物医学甚至经济学, “p < 0.05”早就被当作常识一样了。
比如,医学领域,有人提出了一种新药。想知道这种新药的效果,那就要进行实验了。简单来讲,他们会找到一些病人,随机的分成两组,比如每组20个人。
双盲测试:医生和患者都不知道分组情况
一组人,作为测试组,会按时吃这种新药。而另一组则是控制组,不会吃这种药。
当然了,也不是啥也不吃。他们会被要求随便吃点啥,比如吃淀粉片,这东西被称为“安慰剂”。
因为心里作用也会影响治疗效果,所以不能让他们知道其实他们吃的东西没啥用嘛。吃安慰剂,就能保证他们不知道自己被分到了控制组。
实验结束之后,会看看哪组人治愈率更高,这我也是从身边好多医学生物学博士朋友那里知道的:他们经常说,科研狗奋斗一生,就为了那0.05,其实硅谷的码农们又何尝不是呀~
后记
我告诉Tommy,你看“p < 0.05”对吧,这就意味着,概率上来讲,咱们 每上线20个产品,其实就会有一个产品是垃圾 。。。所以,别难过了 ,你可能就。。。恰好是那个垃圾。。。
然后Tommy把我打了一顿 
备注
文中p值计算过程和描述并不完全准确哈,而是为了可读性,进行了简化。首先p值不是“无效假设”成立的概率,而只是可以“表示”这个概率的大小。另在案例计算中,因为第一组的4.21%也不能代表真实情况。这里其实是在比较两个样本的分布。特此大感谢我的数据科学家同事+朋友Cora帮我Review~实际比较复杂,比如先看成是一个正态分布,然后计算一堆值,再。。不说了,你去看统计学课本吧。。但是告诉你一个小秘密,已经有很多开源在线工具可以帮你计算p值了: ( 可见对于文中的例子,打开率p值可以为0.0453。)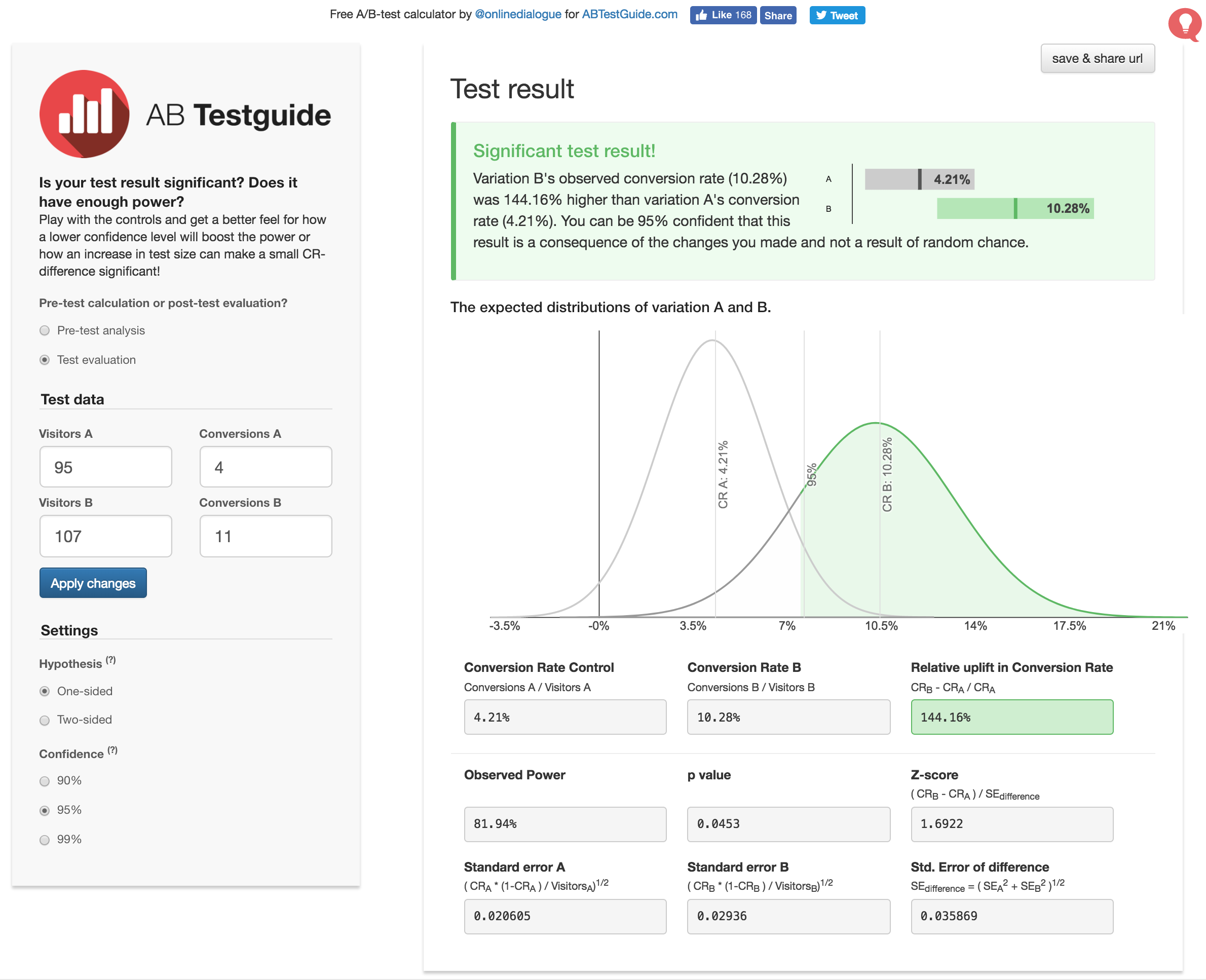
另外,感谢我的博士朋友:(以下为他贡献原文)其实利用p值是频率学派的假设检验方法,而p值的滥用已经是科学界的一个严重问题。2017年nature上有篇文章redefine statistical significance 是一堆统计学大佬写给科学家群体的,大意是我们认为贝叶斯假设检验的框架更好,但是鉴于科学家普遍没有受过贝叶斯框架的训练,那么为了降低得出错误结论的概率,至少把p值的阈值降到0.005。
作者:Han,facebook美国硅谷总部商业产品全栈软件工程师。先后负责facebook中小企业广告及大型电商零售企业广告商业产品开发。微信公众号:涵的硅谷成长笔记(ID:HanGrowth),和我一起向硅谷大牛们发起夸学科学习进击,共同见证进步。
关键字:产品经理, 产品决策, 实验, 推送