基于深度主动学习的命名实体识别 | 分享总结 众所周知,深度学习在多种实际应用中取得了突破,其背后的主要推动力来自于大数据、大模型及算法。在很多问题中,获取标注准确的大量数据需要很高的成本,这也往往限制了深度学习的应用。而主动学习通过对未标注的数据进行筛选,可以利用少量的标注数据取得较
不扁平的设计:我们的世界没有一处是光滑和平整的 设计中最难的部分就是要在这两种模式之间切换,他们需要完全不同的心态。好的设计师需要在非常天真的相信和完全的自信之间切换。更重要的是,他们需要知道什么时候应该天真,什么时候应该自信。通常,设计师们总是太早的陷入自信满满的状态,但是一个过度自信
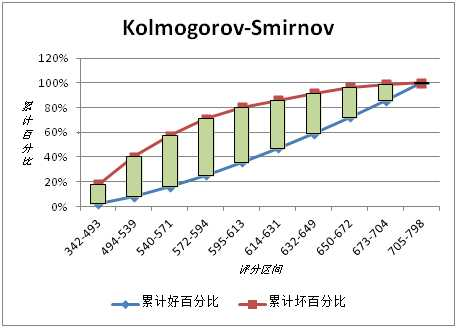
“高大上”的风控,究竟是什么? (一) 最近工作有点心情抑郁的我,来撸几个文吧。如果有不对的地方请各位勿喷,只是经验之谈。本期只针对风控做个概述,初步的认识,后续会进行从产品到策略上的深度解析。风控对于很多人来说觉得很高大上,其实是挺高大上的,但也不是那么难的。很多人问我,是不是
做好增长获客,利用这个模型找到适合自己的方法 存量时代,获客难且贵,所以关键要找对方法。也就是,获客的策略是什么。前几天看到刘润在谈这个话题,但不太实操。这篇文章更聚焦在策略执行,分享给大家。先解释上图