对比学习必知要点
数据增强
给定训练样本,我们需要用数据增强来创建带有噪声版本的数据,以作为正样本反馈到损失函数中。正确的数据增强设置对于学习好的泛化性强的embedding至关重要。它在不修改语义的情况下,将非本质变化引入示例中,从而激发模型学习的本质表达。例如,在SimCLR中的实验表明,随机裁剪和随机颜色失真的组合对于学习图像视觉表示的良好性能至关重要。
更大的Batch Size
在很多对比学习方法中,使用一个较大的batch size至关重要,例如SimCLR和CLIP.特别是样本依赖于Batch内负采样.仅当batch size足够大才有足够的负样本,使得损失函数充分收敛,对模型而言才能充分的学习更好的表达来区分各种各样的样本.
困难的负样本挖掘
hard负样本指的是与anchor样本label不同,但是特征与anchor十分接近.在有标签的数据集上,找到hard负样本其实还挺容易的.比方说在学习句子表达上,NLI数据集中,句子对中标签是"contradiction"就是hard的负样本(SimCSE),再例如DPR中,BM25最接近但标签不同的样本就是hard负样本.
然而在纯无监督环境下,找到hard负样本是很棘手的.增加训练的batch size或mermory bank会隐式引入更多hard负样本,但这样做会给内存带来严重负担。
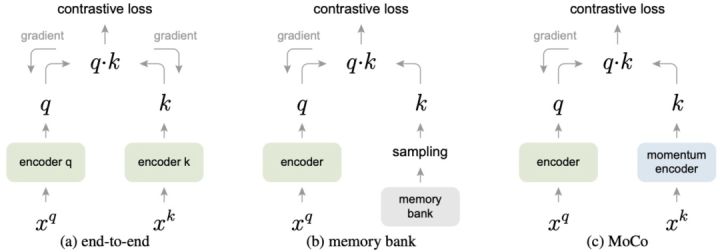
这里解释下memory bank,训练过程中维护一个Embedding库,即Memory Bank, 每次训练完一个batch就把里面的embedding塞到这个库里,下次训练从这个库中随机抽取部分出来做负样本.由于采样问题,不一定能保证库里面emb的一致性.
Moco就提出Momentum Contrast的方法解决Memory Bank的缺点,该方法使用一个队列来存储和采样 negative 样本,队列中存储多个近期用于训练的 batch 的特征向量。队列容量要远小于 Memory Bank,但可以远大于 batch 的容量,如下图所示. 这里momentum encoder可以和encoder完全一致参与梯度下降,也可以是对query encoder的平滑拷贝.
《Debiased Contrastive Learning》这篇论文研究了对比学习中的采样偏差问题,提出了一个纠偏的loss.在无监督的环境中,由于我们不知道真实的标签,我们可能会意外地采样False Negative样本(从下图左图可以看到,给一只狗的图片采样了另一只狗做负样本)。抽样偏差可能会导致学习的效果显著下降。

纠偏后的loss如下:
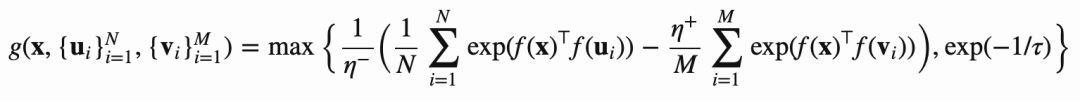
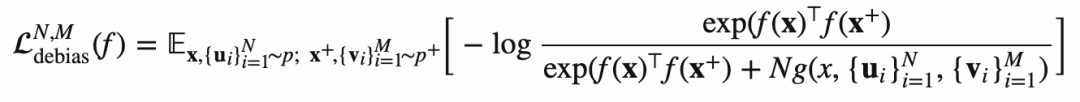
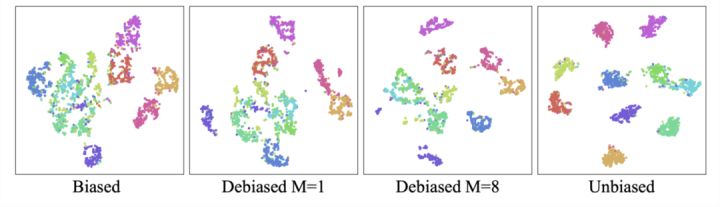
我们可以看到纠偏后用t-SNE可视化后,不同类直接划分的更加明确了.
本文来自互联网用户投稿,文章观点仅代表作者本人,不代表本站立场,不承担相关法律责任。如若转载,请注明出处。 如若内容造成侵权/违法违规/事实不符,请点击【内容举报】进行投诉反馈!