2021年炼丹笔记最受欢迎的10篇技术文章
阶段性整理知识笔记是炼丹笔记的习惯,在这里我们温故而知新,根据文章在全网的阅读情况整理了2021年度,最受欢迎的10篇文章,错过的朋友可以补一下哦。

推荐系统内容实在太丰富了,以至于刚开始学的人都无从下手,当年无意中翻到谷歌这篇教程,然后就开启了入"坑"推荐系统的神奇旅程,极力推荐给大家,大家也可以推荐给想学推荐系统的童鞋们。
传送门:入坑推荐系统,从Google这篇开始

从文章的内容来看,Normalization对于模型的帮助是非常大的。对Embedding之后的特征进行Normalization(数值Embedding处用LayerNorm相关的Normalization,Categorical部分使用BatchNorm相关的处理,MLP部分使用VO-LN)可以取得非常大的提升,非常值得一试。
传送门:Normalization在CTR问题中的迷之效果

长尾物品(Tail Items)在推荐系统中是非常常见的,长尾的存在导致了样本的不均衡,对于热门头部物品(Head Items)的样本量多,模型学习这部分的效果越好,而长尾物品的样本量少,导致模型对该部分Item的理解不够充分,效果自然也就较差。
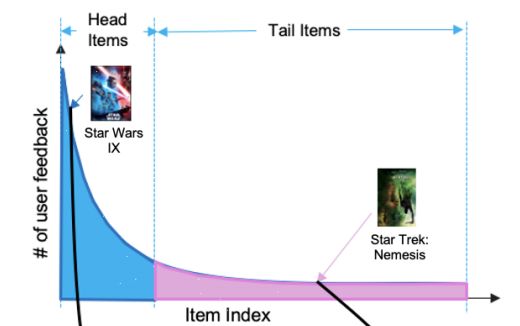
那么,针对长尾物品的推荐,有哪些较好的解决方法呢?本文从几个角度来聊一下这个问题。长尾问题,可以看成是推荐系统倾向于推荐热门商品,而忽略了非热门物品,即推荐系统如何解决纠偏问题?
传送门:推荐系统中的长尾物品(Tail Items)推荐问题

随着深度学习的快速发展,目前已经出现了海量的不同结构的神经网络,本文介绍11种炼丹师都需要知道一点的神经网络结构。
传送门:炼丹侠必知的11大神经网络结构汇总

大家在做模型的时候,往往关注一个特定指标的优化,如做点击率模型,就优化AUC,做二分类模型,就优化f-score。然而,这样忽视了模型通过学习其他任务所能带来的信息增益和效果上的提升。通过在不同的任务中共享向量表达,我们能够让模型在各个任务上的泛化效果大大提升。本文谈论的主题-多任务学习(MTL)。
传送门:一文梳理多任务学习(MMoE/PLE/DUPN/ESSM等)

在实践中,做推荐系统的很多朋友思考的问题是如何对数据进行挖掘,大多数论文致力于开发机器学习模型来更好地拟合用户行为数据。然而,用户行为数据是观察性的,而不是实验性的。这里面带来了非常多的偏差,典型的有:选择偏差、位置偏差、曝光偏差和流行度偏差等。如果不考虑固有的偏差,盲目地对数据进行拟合,会导致很多严重的问题,如线下评价与在线指标的不一致,损害用户对推荐服务的满意度和信任度等,本篇文章对推荐系统中的Bias问题进行了调研并总结了推荐中的七种偏差类型及其定义和特点。
传送门:推荐系统中的Bias/Debias大全

从简单到复杂,每一步我们都会对将要发生的事情做出具体的假设,然后通过实验验证这些假设,或者进行研究,直到我们发现一些问题。我们努力防止的是一次引入大量“未经验证”的复杂假设,这必然会引入错误/错误配置,这将需要花费很长时间才能找到(如果有的话)。
传送门:神经网络调参经验大汇总

对于基于向量召回,那就不得不提到双塔。为什么双塔在工业界这么常用?双塔上线有多方便,真的是谁用谁知道,user塔做在线serving,item塔离线计算embeding建索引,推到线上即可。本文给大家介绍一些经典的双塔模型,快速带大家过一遍,如果想了解细节,强烈建议看论文。
传送门:做向量召回 All You Need is 双塔

文章总结了深度学习领域的各种炼丹技巧,让你在深度学习使用的过程中,掌握各种小Trick。
传送门:大道至简:算法工程师炼丹Trick手册

损失函数是一种评估“你的算法/模型对你的数据集预估情况的好坏”的方法。如果你的预测是完全错误的,你的损失函数将输出一个更高的数字。如果预估的很好,它将输出一个较低的数字。当调整算法以尝试改进模型时,损失函数将能反应模型是否在改进。“损失”有助于我们了解预测值与实际值之间的差异。损失函数可以总结为3大类,回归,二分类和多分类。
传送门:一文弄懂各种loss function
本文来自互联网用户投稿,文章观点仅代表作者本人,不代表本站立场,不承担相关法律责任。如若转载,请注明出处。 如若内容造成侵权/违法违规/事实不符,请点击【内容举报】进行投诉反馈!