用Dropout思想做特征选择,保证效果还兼顾了线上性能?
这篇论文《Towards a Better Tradeoff between Effectiveness and Efficiency in Pre-Ranking: A Learnable Feature Selection based Approach》教会了我们如何做粗排模型兼顾模型的效率和效果.提出了可学习的特征选择方法FSCD,并在真实电商系统中应用.
简介
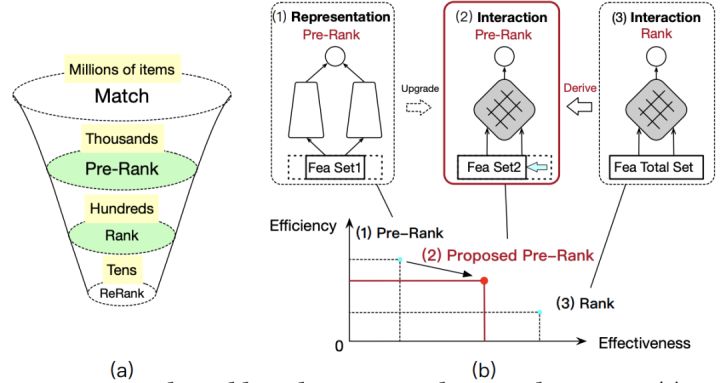
如上图(a)所示,受系统时延约束,推荐系统往往是多阶段的.再看图(b),论文提到简单的representation-focused(RF)模型会严重制约我们模型的表达能力(如传统双塔,最后一层向量Dot,就是简单RF模型),主要是缺少特征交叉.所以我们能否在特征上做优化,只保留效果好的特征又能保证模型推断效率更高,用上和精排一样interaction-focused(IF)的模型呢?当然是可以的!
FSCD
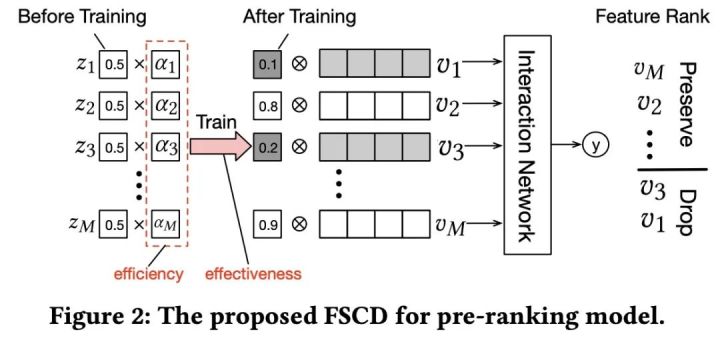
粗排用上精排的模型并且要保持高效率,也就意味着在某些方面要做牺牲,那果断就是在特征上入手了,因此IF的粗排模型用上的特征是精排的子集.如上图所示,FSCD方法中效果是通过梯度优化,效率是通过特征维度的正则化来保证.在训练过程中就可以挖掘到一批有用的特征.
对于每个特征而言,都有个可学习的dropout参数Z ∈ {0, 1} ,并且是符合伯努利分布:
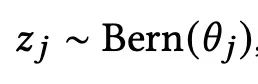
该分布的超参是由特征复杂度cj决定的,cj是由特征的计算复杂度oj,向量维度ej,还有key的多少nj一起决定的.
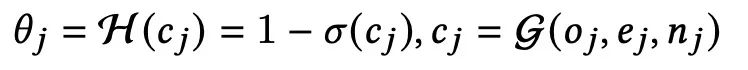
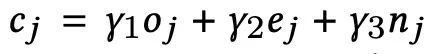
最终损失函数如下所示:
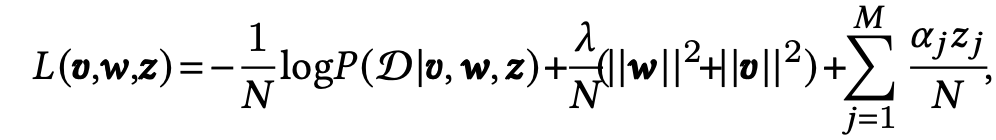
我们可以看到每个zj还会乘上正则化系数:
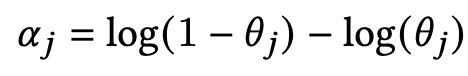
又因为zj的伯努利分布不可导,可以近似为:
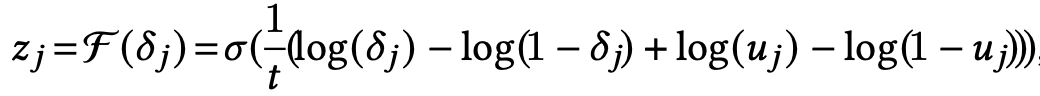
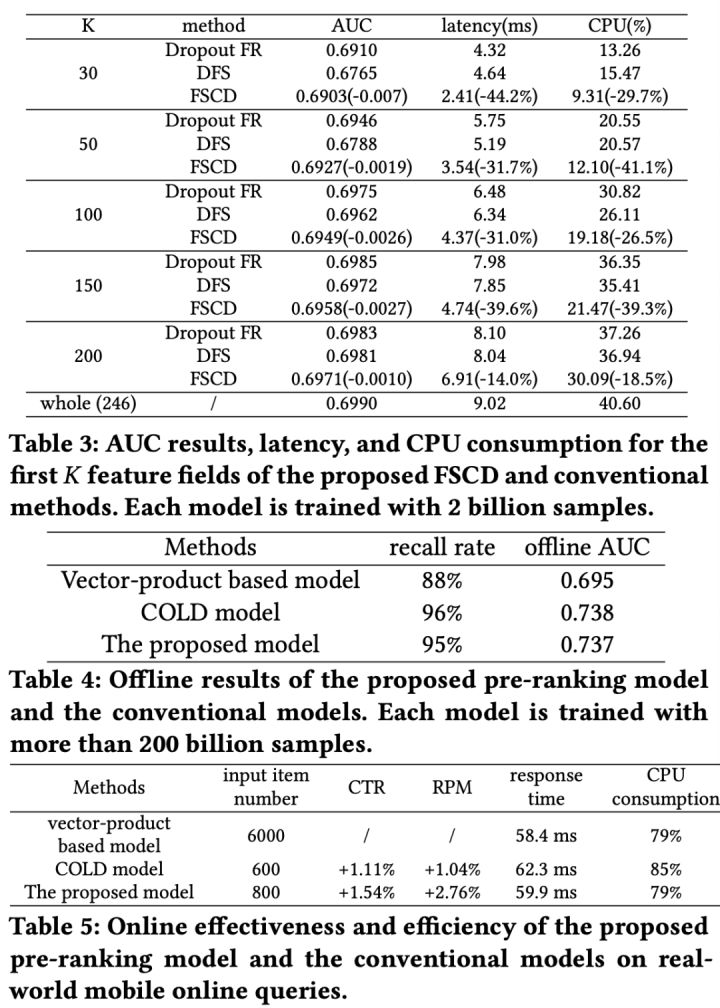
实验
参考文献
1、Towards a Better Tradeoff between Effectiveness and Efficiency in Pre-Ranking: A Learnable Feature Selection based Approach https://arxiv.org/pdf/2105.07706.pdf
2、https://zhuanlan.zhihu.com/p/375943741
本文来自互联网用户投稿,文章观点仅代表作者本人,不代表本站立场,不承担相关法律责任。如若转载,请注明出处。 如若内容造成侵权/违法违规/事实不符,请点击【内容举报】进行投诉反馈!