对比表示学习必知的几种训练目标
对比学习的主要思想就是相似的样本的向量距离要近,不相似的要远.对比学习在有监督/无监督场景下都取得了非常亮眼的成绩,所以是我们炼丹的必备知识.早期的对比学习是只有一个正样本和一个负样本进行对比,最近的训练目标变成了一个batch内多个正/负样本进行训练.
Contrastive Loss
有一系列样本{xi},它们的label yi = {1, ..., L}, L类,还有个函数f将样本xi映射成embedding,有着相同yi的样本有着相似的embedding, 因此对比学习loss定义如下:
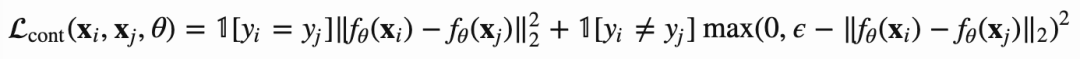
Triplet Loss
Triplet loss大家应该并不陌生,最早出现在FaceNet的论文里,这篇论文主要学习人脸表达,需要同一个人在不同角度位置的表达都很相近.
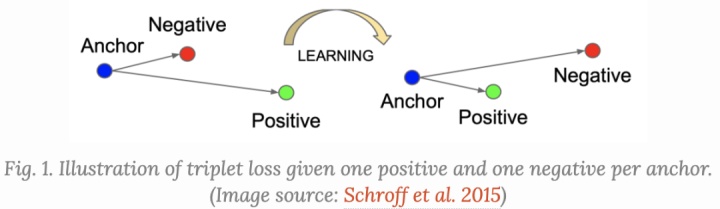
定义一个锚点(anchor) x,有个正例x+和一个负例x-,所以目标函数就是要最小化x和x+的距离,最大化x和x-的距离,定义如下所示:
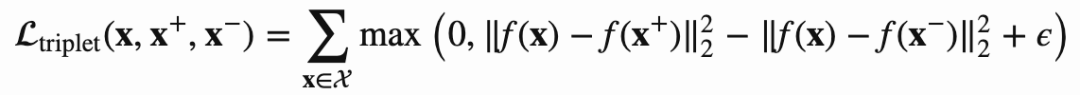
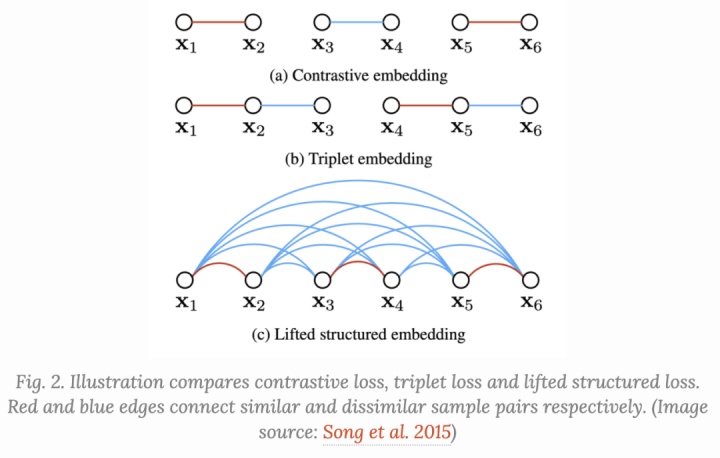
Lifted Structured Loss
该loss为了更好的计算效率,充分利用了一个batch内所有pairwise的边.
Dij = || f(xi) - f(xj) ||2, Loss函数定义如下:
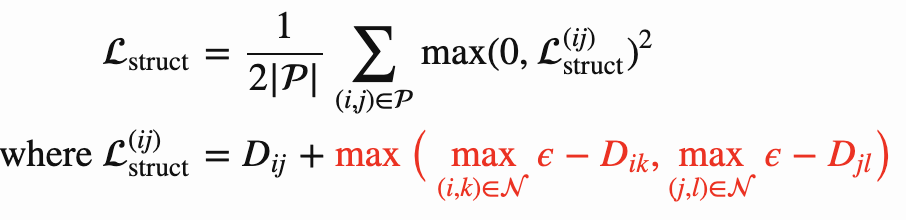
红色部分是为了挖掘hard负样本,但是不是很平滑,难收敛,因此可以改为下式:
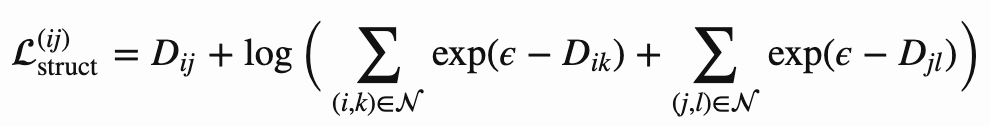
N-pair Loss
在负样本同时有多个的时候,{x,x+, x1-, ..., x(N-1)-},包含1个正样本和N-1个负样本,N-pair loss定义如下所示:
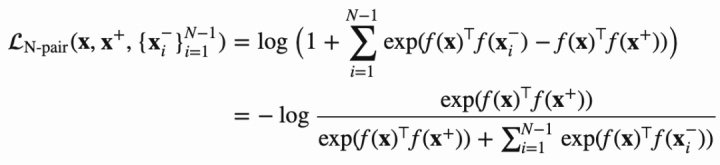
NCE
NCE本身是统计模型做参数估计的方法,思想就是用罗杰斯特回归来区分数据和噪声.非噪声样本的概率用P表示,噪声样本的概率用q表示,如下所示:
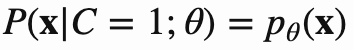
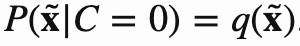
所以NCE的loss函数定义如下:
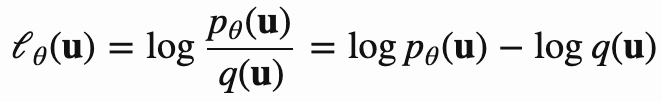
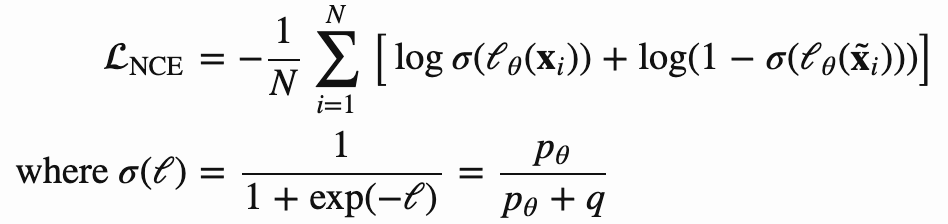
我们看到NCE loss只对一个正样本和一个噪声样本生效.
InfoNCE
受到NCE的启发,InfoNCE使用了交叉熵损失,用在一个正样本和一系列噪声样本上.给定一个上下文环境c,我们可以得到条件概率p(x|c),N-1的负样本直接从概率分布p(x)提取,独立于c. 我们有个样本集合X = {xi},i=1~N, 其中只有一个正样本x_pos, 我们能得到下式
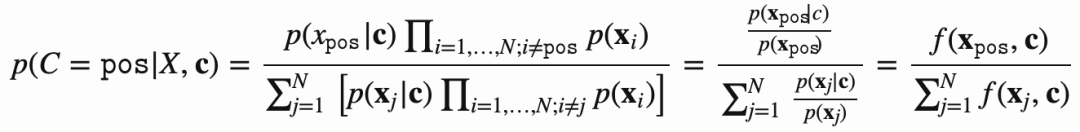
f(x,c)就是模型的打分函数,所以InfoNCE loss优化log loss,如下式:
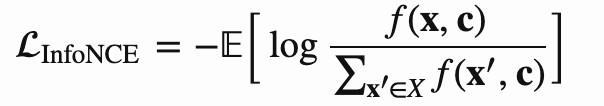
Soft-Nearest Neighbors Loss
该loss扩展到包含多个正样本,假设有个batch {xi, yi} i = 1~B, 该loss会有个温度系数控制,如下所示:
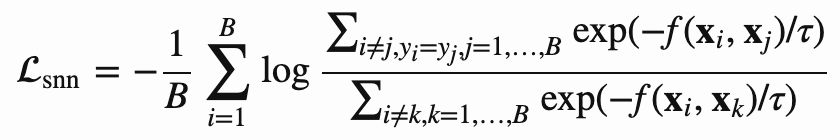
温度τ用于调整特征在表示空间中的集中程度。例如,当温度较低时,损失主要是由小距离造成的,而大范围分离的表示不能起到很大作用。
本文来自互联网用户投稿,文章观点仅代表作者本人,不代表本站立场,不承担相关法律责任。如若转载,请注明出处。 如若内容造成侵权/违法违规/事实不符,请点击【内容举报】进行投诉反馈!