Apache Calcite
前言
Calcite 之前的名称叫做 optiq,optiq 起初在 Hive 项目中,为 Hive 提供基于成本模型的优化,2014 年 5 月 optiq 独立出来,成为 Apache 社区的孵化项目,主要作用是提供标准的SQL语言查询底层各种数据源的一个工具,可以将各种SQL语句解析成抽象语法术AST(Abstract Syntax Tree), 之后通过操作AST就可以把SQL中所要表达的算法与关系体现在具体代码之中。
Calcite 的目标是"one size fits all "(一种方案适应所有需求场景),希望能为不同计算平台和数据源提供统一的查询引擎,成为动态的数据管理系统(其实Calcite并没有数据库,需要我们在代码里告诉Calcite,虚拟出来的表是什么、字段是什么、字段类型是什么等,整体抽象为一个个Schema,对于我们来说就查Calcite虚拟出来东西,不用关心底层真正对接了哪些数据源),并以类似传统数据库的访问方式(SQL 和高级查询优化)来访问数据。
使用Calcite作为SQL解析与处理引擎有Hive、Drill、Flink、Phoenix和Storm,可以肯定的是还会有越来越多的数据处理引擎采用Calcite作为SQL解析工具。
特性及功能
-
支持标准SQL 语言;
-
独立于编程语言和数据源,可以支持不同的前端和后端,且架构比较精简,利用Calcite写几百行代码就可以实现一个SQL查询方案;
-
支持关系代数、可定制的逻辑规划规则和基于成本模型优化的查询引擎;
-
支持物化视图( materialized view)的管理(创建、丢弃、持久化和自动识别),基于物化视图的 Lattice 和 Tile 机制,以应用于 OLAP 分析;
-
支持对流数据的查询,Calcite 对其 SQL 和关系代数进行了扩展以支持流查询。
Calcite架构
2种常用场景:
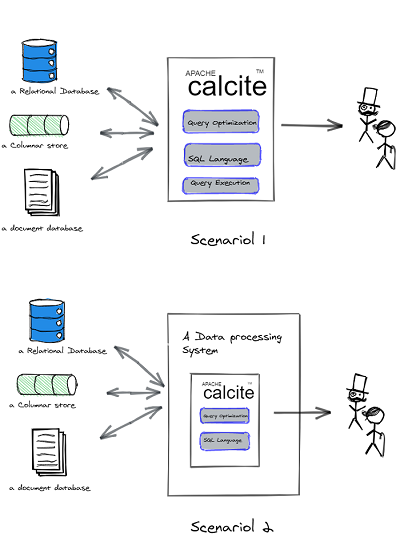
-
在场景1中,calcite 作为独立运行的进程,后台通过适配器与外部的存储系统连接,前台通过JDBC 接口 使用SQL 语言通用户交互 。在这个场景里,calcite 作为一个中间件,为一些没有或缺乏友好的查询语言的存储系统(比如HBase, Cassandra, Kafka, ES, Redis) 提供查询语言(比如SQL)。 calcite在 内部将用户提交的查询优化并运行再自己的进程里,并在优化的过程中将适当的部分下推给存储系统 。
-
在场景2中,calcite 作为嵌入式的组件运行在一个查询引擎里。这些查询引擎用自己的方式连接后台数据源,并使用自己的集群用分布的方式执行查询。 查询引擎善于获取数据和执行查询,需要calcite 提供查询语言和优化查询的能力 。
场景2是calcite 最受欢迎的和最擅长的场景, 相比查询执行、连接数据源, calcite 更擅长的是制造查询语言,解析查询, 和查询优化 。为什么这么说呢 , 那就要看看它的架构了:
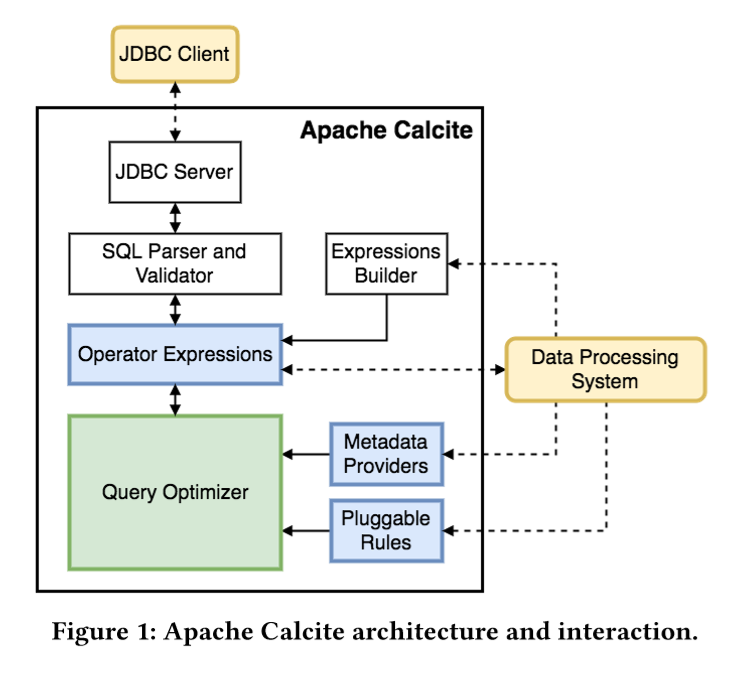
1、SQL parser and validator是Calcite的SQL 语言的解释器,它将用户用SQL语言编写的查询解析城Opeator Expressions ,并验证它的合法性 。
2、Query Optimizer (优化器)是calcite 的核心,它接受查询计划,输出优化的查询计划 ,主要包含三个部分:
-
metadata providers:主要是向优化器提供信息,这些信息会有助于指导优化器向着目标(减少整体 cost)进行优化,信息可以包括行数、table 哪一列是唯一列等。
-
rules:也就是匹配规则,Calcite 内置上百种 Rules 来优化 relational expression,当然也支持自定义 rules。
-
Opeator Expressions是一种用于表示关系代数表达式的树状数据结构。解释器将SQL 查询解释成关系代数表达式, 之后优化器调用规则将其修改为最优表达式。优化规则会根据关系代数的等价交换原理将表达式变形从而使表达式的代价降低。
如何判断代价是否降低? 办法有两种:
一种是根据经验,学名称做启发式模型, 相应的优化器被称作启发式优化器,基于规则优化(RBO)。例如谓词下推,子查询替换,常量替换等。
一种是根据代价模型,学名叫火山模型。 相应的优化器被称作火山优化器,基于成本优化(CBO)。例如Mysql中的成本优化器。
这三个组件是calcite 可扩展部分,因此与外部系统有连接 。
3、黄色框框Data Processing System( 简称DPS)与蓝色框框有虚线连接,是DPS 对calcite 的扩展部分。 这里的Data Processing System所指的就是场景2里的查询引擎。它通过扩展metadata provider 和 pluggable rules , 向优化器提供更准确的元数据信息,更适合的代价模型, 更高效的优化规则, 利用calcite 优化器产生最优化查询计划。
4、Expression Builder 是一种绕过SQL解析,直接生成关系表达式的工具。 这种方式适用于单元测试。
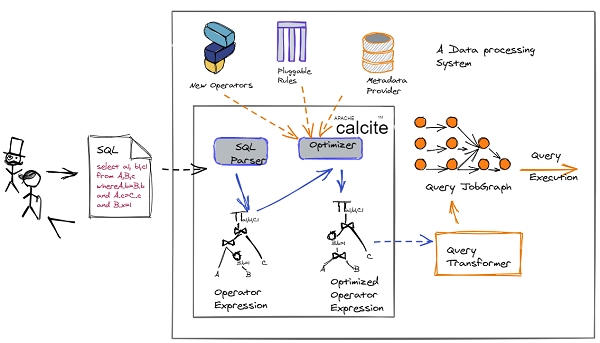
用数据流图的方式描述一下calcite 和Data Processing System 的交互, 更容易理解:

-
解析 SQL, 把 SQL 转换成为 AST (Abstract Syntax Tree,抽象语法树),在 Calcite 中用 SqlNode 来表示;
-
语法检查,根据数据库的元数据信息进行语法验证,验证之后还是用 SqlNode 表示 AST 语法树;
-
语义分析,根据 SqlNode 及元信息构建 RelNode 树,也就是最初版本的逻辑计划(Logical Plan);
-
逻辑计划优化,优化器的核心,根据前面生成的逻辑计划按照相应的规则(Rule)进行优化;
-
物理执行,生成物理计划,物理执行计划执行。
Calcite中的概念
1、关系代数表达式:SQL 形式化语言——关系代数_QuinnNorris的博客-CSDN博客_sql关系代数
2、等价交换原理:「 数据库原理 」查询优化(关系代数表达式优化) - Postbird - 猫既吾命
3、两种优化方式:
-
基于规则优化(RBO):
基于规则的优化器(Rule-Based Optimizer,RBO):根据优化规则对关系表达式进行转换,这里的转换是说一个关系表达式经过优化规则后会变成另外一个关系表达式,同时原有表达式会被裁剪掉,经过一系列转换后生成最终的执行计划。
RBO 中包含了一套有着严格顺序的优化规则,同样一条 SQL,无论读取的表中数据是怎么样的,最后生成的执行计划都是一样的。同时,在 RBO 中 SQL 写法的不同很有可能影响最终的执行计划,从而影响执行计划的性能。
基于成本优化(CBO):
基于代价的优化器(Cost-Based Optimizer,CBO):根据优化规则对关系表达式进行转换,这里的转换是说一个关系表达式经过优化规则后会生成另外一个关系表达式,同时原有表达式也会保留,经过一系列转换后会生成多个执行计划,然后 CBO 会根据统计信息和代价模型 (Cost Model) 计算每个执行计划的 Cost,从中挑选 Cost 最小的执行计划。
CBO 中有两个依赖:统计信息和代价模型。统计信息的准确与否、代价模型的合理与否都会影响 CBO 选择最优计划。 从上述描述可知,CBO 是优于 RBO 的,原因是 RBO 是一种只认规则,对数据不敏感的呆板的优化器,而在实际过程中,数据往往是有变化的,通过 RBO 生成的执行计划很有可能不是最优的。事实上目前各大数据库和大数据计算引擎都倾向于使用 CBO,但是对于流式计算引擎来说,使用 CBO 还是有很大难度的,因为并不能提前预知数据量等信息,这会极大地影响优化效果,CBO 主要还是应用在离线的场景。
Calcite执行流程
sql:
select u.id as user_id, u.name as user_name, j.company as user_company, u.age as user_age
from users u join jobs j on u.name=j.name
where u.age > 30 and j.id>10
order by user_idStep 1: SQL parse(SQL -> SqlNode)
使用 Calcite 进行 Sql 解析的代码如下:
SqlParser parser = SqlParser.create(sql);
SqlNode sqlNode = parser.parseStmt();Calcite 使用 JavaCC 做 SQL 解析,JavaCC 根据 Calcite 中定义的 Parser.jj 文件,生成一系列的 java 代码,生成的 Java 代码会把 SQL 转换成 AST 的数据结构(这里是 SqlNode 类型)。与 Javacc 相似的工具还有 ANTLR,JavaCC 中的 jj 文件也跟 ANTLR 中的 G4文件类似。 Javacc 这里要实现一个 SQL Parser,它的功能有以下两个,这里都是需要在 jj 文件中定义的。 1. 设计词法和语义,定义 SQL 中具体的元素; 2. 实现词法分析器(Lexer)和语法分析器(Parser),完成对 SQL 的解析,完成相应的转换。
SQL 经过前面的解析之后,会生成一个 SqlNode:
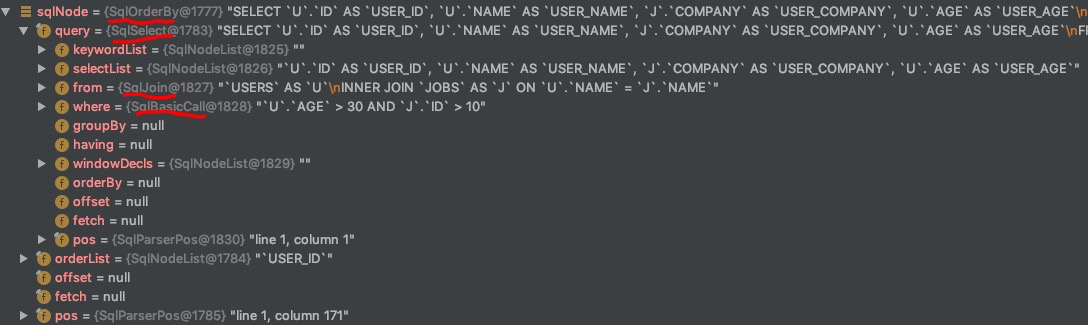
Step 2: SqlNode validate(SqlNode–>SqlNode)
经过上面的第一步,会生成一个 SqlNode 对象,它是一个未经验证的抽象语法树,下面就进入了一个语法检查阶段,我们知道 Calcite 本身是不管理和存储元数据的,在检查之前,需要先把元信息注册到 Calcite 中;这个检查会包括表名、字段名、函数名、数据类型的检查。进行语法检查的实现如下:
它的处理逻辑主要分为三步:
-
rewrite expression,将其标准化,便于后面的逻辑计划优化;
//rewrite 前 select u.id as user_id, u.name as user_name, j.company as user_company, u.age as user_age from users u join jobs j on u.name=j.name where u.age > 30 and j.id>10 order by user_id //rewrite 后 SELECT `U`.`ID` AS `USER_ID`, `U`.`NAME` AS `USER_NAME`, `J`.`COMPANY` AS `USER_COMPANY`, `U`.`AGE` AS `USER_AGE` FROM `TEST`.`USERS` AS `U` INNNER JOIN `TEST`.`JOBS` AS `J` ON `U`.`NAME`=`J`.`NAME` WHERE `U`.`AGE` > 30 AND `J`.`ID`>10 ORDER BY `USER_ID` -
注册这个 scopes 和 namespaces(这两个对象代表了其元信息);
-
进行相应的验证,这里会依赖第二步注册的 scopes 和 namespaces 信息。
Step3: 语义分析(SqlNode–>RelNode)
经过上面的sql 解析,会生成一个 SqlNode 对象,SqlNode 是抽象语法树AST的节点, 而 Rel 代表关系代数表达式(Relation Expression), 所以这是一个AST节点变为关系表达式的过程,进过转化后生成的关系表达式为:
LogicalSort(sort0=[$0], dir0=[ASC])LogicalProject(USER_ID=[$0], USER_NAME=[$1], USER_COMPANY=[$5], USER_AGE=[$2])LogicalFilter(condition=[AND(>($2, 30), >($3, 10))])LogicalJoin(condition=[=($1, $4)], joinType=[inner])LogicalTableScan(table=[[USERS]])LogicalTableScan(table=[[JOBS]])Step4: 优化阶段(RelNode–>RelNode)
第四阶段,也就是 Calcite 的核心所在,优化器进行优化的地方,前面 sql 中有一个明显可以优化的地方就是过滤条件的下压,在进行 join 操作前,先进行 filter 操作,这样的话就不需要在 join 时进行全量 join,减少参与 join 的数据量,优化后:
LogicalSort(sort0=[$0], dir0=[ASC])LogicalProject(USER_ID=[$0], USER_NAME=[$1], USER_COMPANY=[$5], USER_AGE=[$2])LogicalJoin(condition=[=($1, $4)], joinType=[inner])LogicalFilter(condition=[>($2, 30)])EnumerableTableScan(table=[[USERS]])LogicalFilter(condition=[>($0, 10)])EnumerableTableScan(table=[[JOBS]])本文来自互联网用户投稿,文章观点仅代表作者本人,不代表本站立场,不承担相关法律责任。如若转载,请注明出处。 如若内容造成侵权/违法违规/事实不符,请点击【内容举报】进行投诉反馈!