C# 高级编程个人笔记搬运 四(托管和非托管资源)
我最近碰到一个机会去做听起来比较高级的事情,有点兴奋,有点害怕,毕竟那个领域不是我很擅长的,但是我多多少少会点,而且我特别想去触碰那个领域!这种复杂的心情伴了我整整一天一夜,以至于我一回家就心心念念拿起了书本去啃,却一个字都没有啃下去。但无疑我是想握住这机会的,像我这种人注定是走钢丝型的:
曾经在 幽幽 暗暗 反反 复复 中追问
才知道 平平 淡淡 从从 容容 才是真
再回首 恍然如梦
再回首 我心依旧
只有那 无尽的长路 伴着我
我还是抓紧时间把这本书的笔记写完,今天很巧要搬运的笔记是关于托管和非托管资源这块的内容,搞c#的经常会听到前辈说这些个词o(* ̄︶ ̄*)o,但很多年轻的程序员压根不重视偏底层的原理!这是非常不对的,你不重视就不知道自己写的好不好、对不对。所以这里我写的尽可能详细点,把我的所思所想都写出来,也当给自己敲个警钟。
后台内存管理
在c#中你会经常听到资源两个子,无论你是在做WPF的时候,还是在做其它的时候。在这里讲的资源就是指——存储在托管或本机堆中的对象。尽管垃圾收集器释放存储在托管堆中的托管对象,但不释放本机堆中的对象。使用托管环境时,很容易注意不到内存管理,因为你认为垃圾回收器(GC)会处理它。所以我们需要一步步去了解内存管理和内存访问的各个方面,才能更加高效地处理内存。
windows使用虚拟寻址系统,该系统把程序可用的内存地址映射到硬件内存中的实际地址上,这些任务完全由windows在后台管理。对于32位的操作系统一般情况下(不管你的物理内存多大)使用的内存为4GB,这里面放执行的代码、代码加载的所有DLL,已经运行中使用的所有变量的内容。而这4GB的内存就称为虚拟地址空间,或虚拟内存。(以下的内存都是虚拟内存,堆都是托管堆)
我稍微做个补充解释,在我们学习《计算机操作系统原理》的时候,或多或少会记得老师讲过的分页存储、分段存储这两个策略行为。在以前我们需要多个运行多个进程的时候,往往都会把他们都放在内存中。后来有了虚拟存储技术,就是你不需要将进程的全部都放在内存之中。有一篇文章介绍挺好的http://c.biancheng.net/view/1270.html。等到时候我把这文章更新,画个图解释一下一定能懂。
回过头,这4GB每个单元都是从0开始往上走的,你需要访问虚拟内存中的某个空间的一个值时,你就需要提供表示该存储单元的数字,你可以理解为变量名其实就是一个内存地址。在这虚拟内存中有堆、栈。栈存储的是非对象成员的值类型,还有你在调用方法时,由栈去传递所有方法的参数副本,就是说参数是复制的不是源的。栈是弹压式逻辑,是后进先出,如:
// 整体上栈是后进先出,像子弹夹的子弹
{int a; // a先别声明进栈{int b; // 但是b先出的作用域(即先失去作用),先出栈}
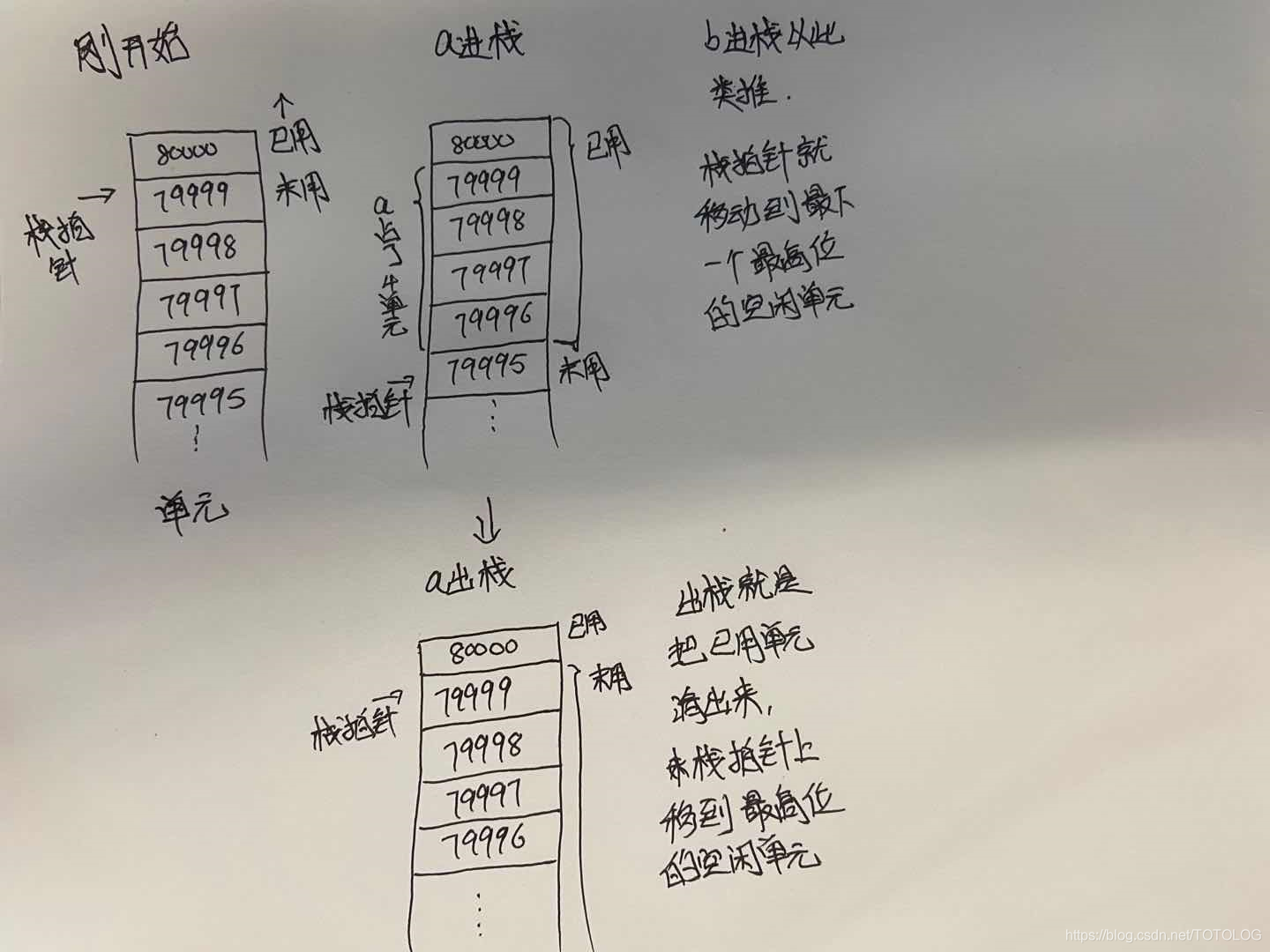
}这里就提出一个问题,ab是连续的地址吗,不是的,没有人知道栈的地址空间在哪里。那么,a存储后,b放哪,那就引出了栈指针概念!程序在第一次运行时,栈指针通常指向栈保留的虚拟内存块的末尾,其实栈其实是上向下填充的,就是高内存地址向低内存地址填充。当第一个数据入栈,栈指针就变成了下一个空闲的存储单元。如
{int a=10; // int占了4个字节,就是占了虚拟内存中栈的4个单元{double b = 3.0; // double占了8个字节,就是占了虚拟内存中栈的8个单元}
}
尽管栈有非常高的性能,但是它如果用于整个程序中的所有变量(包括引用类型等)就显得不够灵活了。因为当我们退出作用域后,栈就会把它抹去。可我们不想这样,我们想说放我们退出一个方法后,我们依然需要这些数据。那如何做呢,那就是用所以对于所有引用类型,我们就需要new运算符来为这些数据请求一个分配空间。这个时候,这种行为就需要使用托管堆。
我们可以解释为,值类型它依靠栈的出了作用域即消除可以不需要我们关注资源释放,而引用类型我们不再使用栈机制,而是额外主动的申请分配空间,那么我们就需要去关注资源释放。这也是托管与非托管资源的一些不同的起因。
这个托管自愿我们就在虚拟内存引入一个托管堆的概念来。c#的托管堆不是我们操作系统上说的传统的堆,它是一种基于堆的概念而被c#的垃圾回收机制控制下工作的。那我们看下引用类型在虚拟内存中的一个变化,如:
{// 声明一个类对象Class1 class1;// 创建这个类对象class1 = new Class1();// Class2派生自基类Class1Class1 class2 = new Class2();
}对于这两种new的情况,都是一样的 过程,我们简单分步来看(实际上更复杂):
①、首先Class1声明了一个对象,他没有new,没有出现真正的实例,这个时候c虚拟内存会在栈上给这个class1引用分配一个空间(这也是我们为什么常对引用类型说它存储在堆栈上的原因,引用会在栈上,实例体才会在托管堆上),这个引用真正占了4个单元。
②、new出来了这个Class1类的真正对象了,这个对象体就会在堆上存储(堆是从低单元开始存储到高单元的,与栈相反,所以先进先出),假设这个实例体占了32个堆的单元。
③、这个时候,栈上的class1引用栈的单元的值就变成了class1这个对象在堆上的地址。

我们分析了这个很明显看出来引用类型比值类型要复杂,所以性能上消耗一点。同样如果这个引用出了作用域,那么它在栈上的空间就被清除了,虽然堆上的数据还在,但是你已经找不到它了,那怎么办?仍有一种机制,在给变量分配内存时,不会受到栈的影响。只需要你把这个引用变量的值赋给另一个更广作用域的变量引用,这样就能保证一份堆上的数据被多种引用。这样是不是更理解了为什么这个叫做引用类型了!
讲完值类型和引用类型在托管堆和栈上的工作方式,那我们顺着来讲下垃圾回收机制。前面那句话也说清楚了,由于引用还在栈上,所以说基于堆的对象的生存周期(堆中)和引用它们的基于栈的变量的作用域(在栈中)不一致。那么我们想清除掉对象的实体数据,就要依靠垃圾回收机制。
我们可以肯定的是在垃圾回收器没运行时,它们在托管堆中就不会被回收。
问:那垃圾回收器运行呢,还有强制GC,会不会把全部的内容都清除了?
答:那肯定不会的,单说程序如果还在服务器中一直运行,全部清除了,还玩什么?!
问:那程序一直运行,不就一直不会回收了吗?
答:垃圾回收器运行时,它会去删除不再被引用的所有有对象。
听我慢慢道来。
垃圾回收器运行时,它会在引用的根表中找到所有引用的对象,接着在引用的对象表中查找要删除的目标。一旦删除完毕,垃圾回收器会立即把剩下的对象往顶端移动(因为堆是从底端进来的,所以会往高单元推。第一批对象占用的单元成为第0代,回收后剩余的对象往顶部移动称为第1代,以此类推第1代,第2代,当垃圾回收器运行,这种影响是0代往1代堆,1代往2代堆,以此类推。因为最新的对象往往是最可能被早被弃用的对象),再次对堆形成连续的堆内存块。并且在移动对象到新的堆地址空间时,同时也会正确的更新该对象引用在栈中的值(值存的是在堆的地址)。
我们一直都在讲堆、托管堆。是的,如前面所说堆一直都是我们常见的堆,c#谈的最多的是托管堆,它也是堆,只是被垃圾回收器做控制而已,就是上段语句形容的控制。堆在删除内容后,不会移动,不会形成连续的堆内存块。托管堆也是堆,只是被垃圾回收器控制它移动了剩余内容,形成连续的内存块。垃圾回收器的压缩操作就是它们的区别。
在讲一个更复杂的——大对象堆。我们之前说的都是对于小对象而言的,但是对于大对象呢,它就不会放在主堆上了,有属于它的大对象托管堆,成为大对象堆。大对象堆在垃圾回收器删除大对象时,是不会对大对象堆进行压缩位移的操作的。之后呢,垃圾回收器更加改进了,这个时候除了第0代和第1代的大对象会因垃圾回收而占用阻塞主线程,其它从第2代开始的回收都是开启后台线程慢慢回收了。
还有一个有助于提升应用程序性能的优化——垃圾回收平衡,它是专门用于服务器的垃圾回收。服务器一般有一个线程池,对于服务器每个逻辑服务器都有一个垃圾回收堆。这个时候,如果有一个堆把自己的内存用尽了,就会触发垃圾回收机制,其它的堆也会得益于它而进行垃圾回收。还有就是它自己堆的内存消耗远多于别的堆上的,也可以一定程度上认为大多需要被回收的都在这个堆上,而就不用太过多消耗在其它堆上进行回收。
垃圾回收添加了GCSettings.LatencyMode属性,把这个属性设置为GCLatencyMode枚举的一个值,可以控制垃圾回收器进行回收的方式。
强引用和弱引用
垃圾回收器不能回收还在被引用的对象的内存,这是一个强引用,就是说它在被引用中。这种强引用下,如:
// 我们创建一个缓存对象
var cache1 = new MyCache();// 缓存对象引用Class1的对象
var cache1.add(class1);// 假定class1这个实例以后没用了,于是你想它被回收
class1 = null;这种情况下,如果垃圾回收器在运行,它看到你这个class1= null了,它就会把你给回收了。可是在栈上的引用还没有在,并没有被释放,只能等到出了作用域了。就会很可惜。这种情况下就可以使用弱引用(弱引用是使用WeakReference类创建的),但是弱引用可能产生bug和性能问题,要慎重使用。
处理非托管的资源
我们上面讲的都是托管的资源,那些超出作用域被释放的引用,那些不再被引用而回收的对象等等、现在我们来谈谈非托管的资源,比如文件句柄、网络连接和数据库连接等等。垃圾回收器是肯定不会知道如何释放非托管的资源的,所以我们在定义一个类时,可以使用两种机制来自动释放非托管的资源。这两种机制常一起用,它们是:
①、声明一个析构函数(或者终结器),作为类的一个成员;
②、在类中实现Sysytem.IDisposable接口。
我们介绍一下第一种机制,析构函数(析构函数在C++中就常见,在C#中因为底层的.NET体系,等于重写FinaLize(),所以说也可以等于终结器)。构造函数前面说过可以在创建类对象时优先进行一些操作,析构是最后执行的,还可以在垃圾回收器运行前调用析构函数。但是这有个弊端:
①、C#中的析构函数并不能像C++一样在结束时就调用,C#中的析构函数不知道什么时候才会被调用,不同类的析构函数也是没有执行顺序的。
②、C#的析构函数的实现会延迟对象最终从内存中删除的时间。没有析构函数的对象往往一次就会被回收机制清除,有了析构函数就需要两次。第一次调用析构时,没有删除对象,第二次时才会删除。
③、析构函数代码的实现其实是在FinaLize()中的,如果频繁的使用析构函数,而且使用它们进行长时间的清理任务,对性能的影响会很大。
我们介绍下第二种机制,我们推荐这种以实现Sysytem.IDisposable接口代替析构函数(或者终结器)的机制。Dispose()的方法实现代码显示地释放对象直接使用所有非托管资源,并在所有也实现IDisposable接口的封装对象上调用Dispose()方法。要注意使用Dispose()最好用try块,如下:
// 首先我们对一个对象赋为null
Resource1 theResource = new Resource1();// 如果直接Dispose(),那么一旦出了异常,资源还是没法释放
// theResource.Dispose();// 正确的写法是把需要释放的资源放在try块中,用友函数释放
Resource1 theResource = null;
try
{Resource1 theResource = new Resource1();
}
finally
{theResource?.Dispose();
}c#为了各位程序员能更方便又推出了一种代替try{ }finally{ }的一种语法——使用using( ){ }。如:
using(var theResource = new Resource1())
{DO.....
}using( )中的填写是引用变量的声明或者是实例化,这个语法的作用域限定在随后{ }的语句块中。在变量出了限定域(即出了using{ })后,无论有没有错误,都一定会对()里的变量调用的资源进行释放(自动调用Dispose())。
我们为什么说经常要把这两种机制放在一起用,去释放非托管的资源呢。在少量的非托管资源下,我们使用析构函数(终结器)是作为一种保险手段,因为预防我们常规的Dispose()没有被调用。所以融合用如下:(明天补上,今天看看别的书)
本文来自互联网用户投稿,文章观点仅代表作者本人,不代表本站立场,不承担相关法律责任。如若转载,请注明出处。 如若内容造成侵权/违法违规/事实不符,请点击【内容举报】进行投诉反馈!