读论文《Relation-Enhanced Multi-Graph Attention Network for Recommendation》
0 Summary:
Title: Relation-Enhanced Multi-Graph Attention Network for Recommendation
conference: 2020 IEEE 11th International Conference on Software Engineering and Service Science (ICSESS)
Abstract:
知识图谱捕捉了一组实体之间的结构化信息和关系。研究人员经常在推荐系统中引入知识图(KG),以获得更准确、更易于解释的推荐。近年来,许多研究者将带有知识图的图神经网络(GNN)应用于推荐系统中。但是,它们没有考虑适当的聚合,并且忽略了的层限制
为了解决这些问题,我们提出了一个新的推荐框架,名为关系增强的多重图注意网络(简称REMAN),对推荐过程中实体间的异构、高阶关系进行建模。
首先,我们将用户行为和条目知识编码为统一的关系图。然后我们利用关系特定的注意聚合器来聚合异构邻居的嵌入。第三,我们提出了一种关系增强的用户图,以弥补GNN层在推荐方面的局限性。最后,我们根据在图中学习到的嵌入进行预测。在三个基准数据集上的大量实验表明,我们的框架明显优于强推荐方法。
文章目录
- 0 Summary:
- 1 引言
- 2 相关工作
- 2.1 知识感知推荐
- 2.2 图神经网络
- 3 目标介绍
- 4 模型
- 4.1 异构图神经网络层
- 4.2 关系增强用户图谱神经网络层
- Heterogeneous and Homogeneous Graph
- 4.3 预测层
- 4.4 优化
- 5 实验
- 5.1 准备
- 5.2 **比较**
- 5.3 **消融实验**
- 总结
1 引言
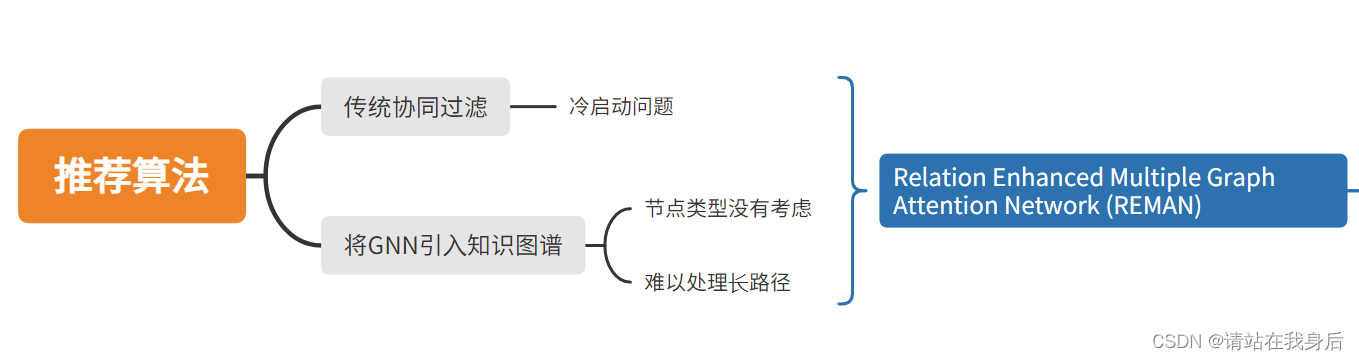
推荐算法比如协同过滤会产生冷启动等问题,因此提出用知识图谱来获取实体的数据和关系。
知识图谱是由 Google 公司在 2012 年提出来的一个新的概念。从学术的角度,我们可以对知识图谱给一个这样的定义:“知识图谱本质上是语义网络(Semantic Network)的知识库”。但这有点抽象,所以换个角度,从实际应用的角度出发其实可以简单地把知识图谱理解成多关系图(Multi-relational Graph)。
也有将GNN引入推荐的基于混合传播的方法,但他们的模型也有以下问题
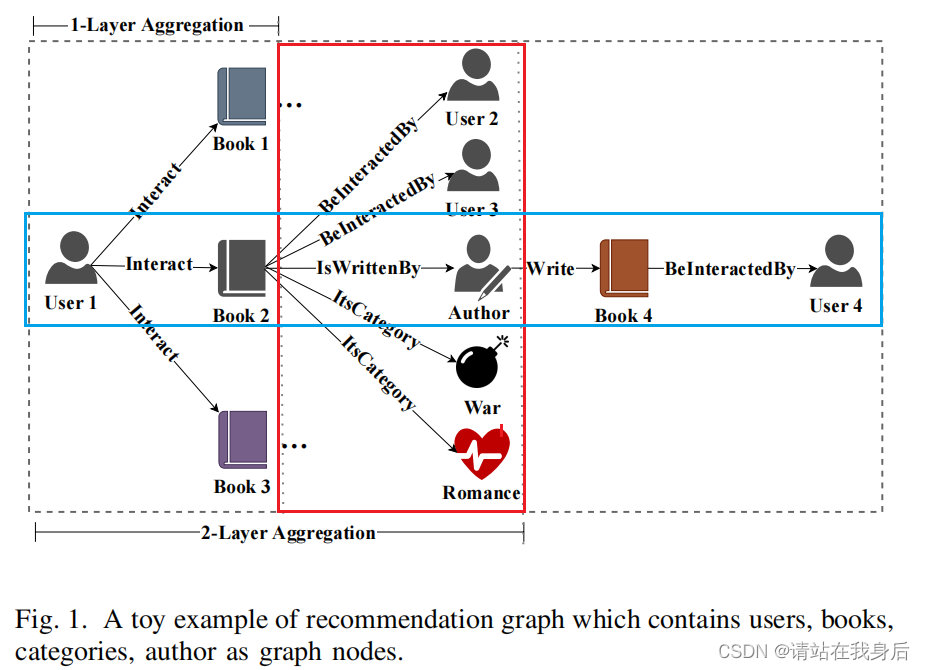
例如图1所示,
1.红框所示,模型在第二层将所有邻居节点完成聚合,但没有考虑这些节点的类型
2.蓝框所示,当目标路径过长会导致GNN聚合很多不相关的因素
为解决以上问题,本文提出了一个Relation Enhanced Multiple Graph Attention Network (REMAN forshort),
首先,我们将用户行为和项目信息编码为统一的关系图。其次,我们利用关系特定的注意力聚合器来聚合异构邻居的嵌入。第三,我们提出了一种关系增强的用户图,以弥补以往方法在挖掘用户个人偏好时的不足和 GNN 层推荐的局限性。最后,我们根据图中学习的嵌入进行预测。
2 相关工作
2.1 知识感知推荐
目前知识图谱推荐系统分为三类:基于嵌入的方法,基于路径的方法,混合方法
1、

2.

3.

基于嵌入的方法使用知识边图嵌入 (KGE) 算法对 KG 进行预处理,该算法对严格的语义相关性进行建模,但这些方法缺乏高阶建模,扩展性较差。
基于路径的方法通过设计元路径模式或路径选择算法来利用知识图谱结构来提取异构知识图中的潜在 特征。但是路径选择对很大程度上依赖于手动设计的元路径/元图有很大的影响。
在KGAT采用注意力机制聚合和传播实体的局部邻域信息,没有考虑用户对实体的个性化偏好。
这些基于混合传播的方法通过逐层传播隐式聚合高阶邻域信息
本文也属于基于混合传播的一个实例
2.2 图神经网络
图神经网络通过同时对边和节点属性进行建模,虽然这可以对知识图谱信息进行建模,但它们只是使用 GNN 来预测项目,并没有充分考虑针对推荐场景进行设计。


3 目标介绍
异构图:
G = ( V , E , R ) E = ( h , r , t ) ∣ h , t ∈ V , r ∈ R \cal G=(V,E,R)\\ \cal E= {(h, r, t)|h, t \in V, r \in R} G=(V,E,R)E=(h,r,t)∣h,t∈V,r∈R
协同知识图(CKG):,
G C K = ( V C K , E C K , R C K ) V C K = U ⋃ I ⋃ A \cal G_{CK} = (V_{CK},E_{CK},R_{CK})\\ \cal V_{CK}=U\bigcup I\bigcup A GCK=(VCK,ECK,RCK)VCK=U⋃I⋃A
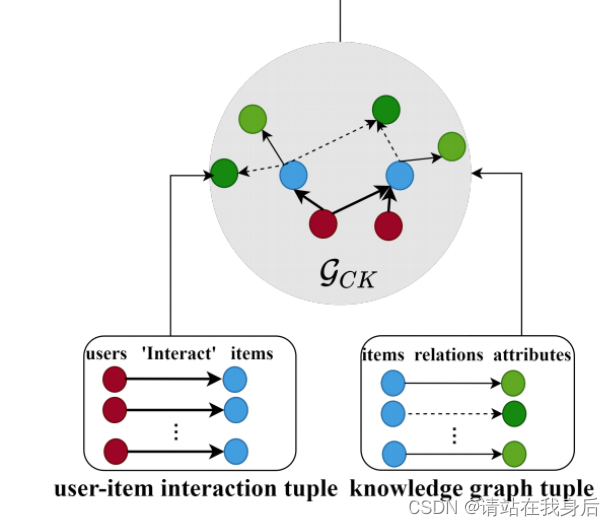
CKG为KGAT中提到的一个概念,通过将图谱关系信息及用户user点击商品item的交互图融合到一个异构图空间里,可以融合CF信息及KG信息,同时也可以通过CKG发现高阶的关系信息
关系增强的用户图谱:
由于层长的限制,我们缺乏探索长路径信息的能力。且CKG item通过一跳直接连接到了user,导致item 邻居聚合的信息要远比user的丰富 ,因此CKG聚合对用户信息的挖掘不足,难以对用户的个人偏好进行建模
为了解决这些问题,我们将构建元路径图的传统方法应用于我们的用户图。我们设计了基于元路径的关系增强用户图谱,元路径如下
u s e r − i t e m − a t t r i b u t e − i t e m − u s e r G R U = ( V R U , E R U ) E R U = ( h , r u , t ) ∣ h , t ∈ U ( h , r u , t )及表示用户元路径 user - item- attribute-item -user\\ \cal G_{RU} = (V_{RU} , E_{RU} )\\ \cal E_{RU} = {(h, r_u, t)|h, t \in U} \\ (h,r_u,t)及表示用户元路径 user−item−attribute−item−userGRU=(VRU,ERU)ERU=(h,ru,t)∣h,t∈U(h,ru,t)及表示用户元路径
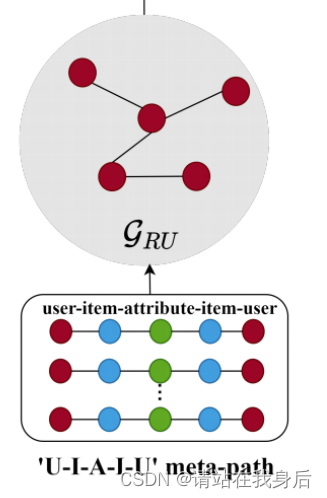
任务描述:
给定CKG 和GRU,生成用户兴趣排序列表
4 模型
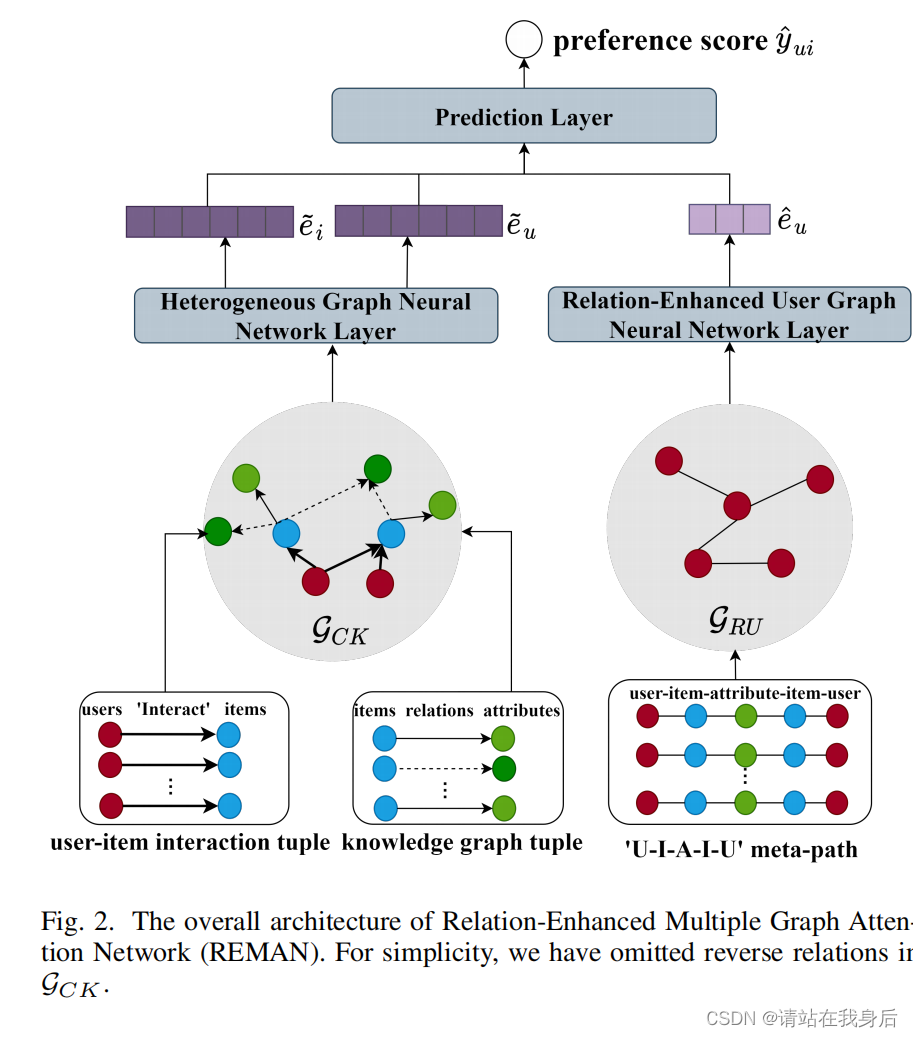
REMAN给定的CKG和RUG,通过三个组件进行预测:
Heterogeneous Graph Neural Network layer,
Relation Enhanced User Graph Neural Network layer
Prediction layer.
4.1 异构图神经网络层
为了捕捉CKG中节点的异构和高阶关系,该层利用我们提出的关系特定注意力聚合器来聚合来自不同边缘的异构邻居的信息。
1)关系特定的注意力聚合器:
来处理各种类型的边(节点间关系),来自不同类型边的邻居应该被区别对待,以下举例,图三为聚合过程: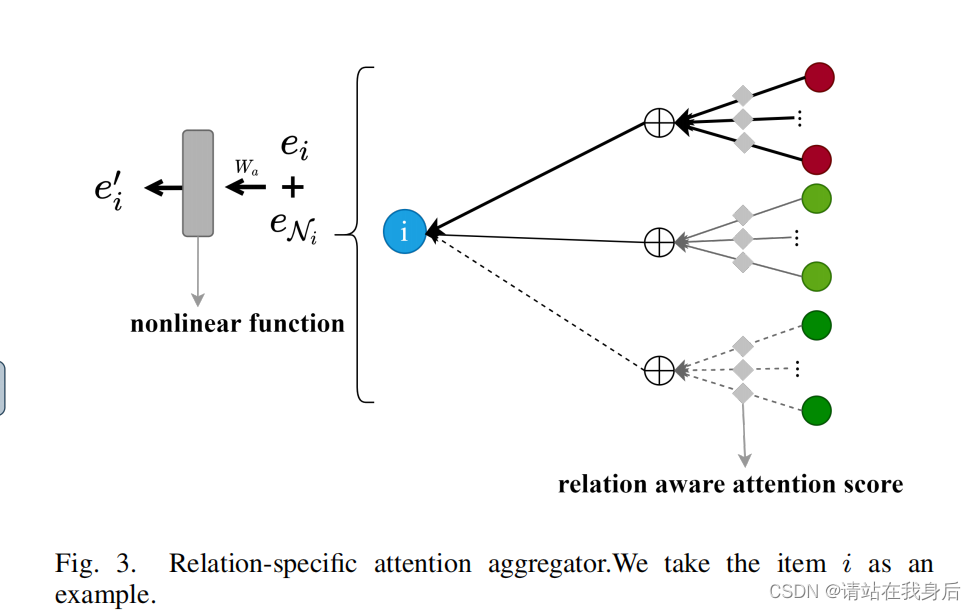
该层流程如下
1.将邻居按边类型分组( N_h,r为邻居节点集合 ,h为目标节点,r为所选关系)
2.将分组后的邻居通过注意力评分α(h, r, t) 嵌入到e中
e N h r = ∑ t ∈ N h , r α ( h , r , t ) e t 注意力评分计算如下 注意力系数: e ( h , r , t ) = e h w r e t T α ( h , r , t ) = e x p ( e ( h , r , t ) ) ∑ ( h , r , t ′ ) e x p ( e ( h , r , t ′ ) ) e_{N_h}^r=\sum \limits _{t \in N_{h,r}} \alpha(h,r,t)e_t\\ 注意力评分计算如下\\ 注意力系数:\ e(h,r,t)=e_hw_re_t^T\\ \alpha(h,r,t) = \frac {exp(e(h,r,t))}{\sum _(h,r,t^ \prime)exp(e(h,r,t^\prime))} eNhr=t∈Nh,r∑α(h,r,t)et注意力评分计算如下注意力系数: e(h,r,t)=ehwretTα(h,r,t)=∑(h,r,t′)exp(e(h,r,t′))exp(e(h,r,t))
3.聚合所有关系类型的邻居嵌入
e N h = ∑ r ∈ R e N h r e_{N_h} = \sum \limits _{r\in R} e^r_{N_h} eNh=r∈R∑eNhr
4.根据其邻居以及h本身的聚合信息来更新h的嵌入
e h ′ = a g g ( e h , e N h ) = σ ( W a ( e N h + e h ) ) e_h^\prime = agg(e_h,e_{N_h})=\sigma(W_a (e_{N_h}+e_h)) eh′=agg(eh,eNh)=σ(Wa(eNh+eh))
**2)多跳聚合:**为了对节点之间的高阶关系进行建模,最终h的嵌入如下
e ~ h = e h ( 0 ) ∣ ∣ e h ( 1 ) … ∣ ∣ e h ( n ) e ~ h 是来自不同聚合层的嵌入的串联 \tilde e_h = e_h^{(0)}|| e_h^{(1)}…|| e_h^{(n)}\\ \tilde e_h 是来自不同聚合层的嵌入的串联 e~h=eh(0)∣∣eh(1)…∣∣eh(n)e~h是来自不同聚合层的嵌入的串联
4.2 关系增强用户图谱神经网络层
对于给定的,使用与异构图神经网络相同的注意力聚合器和传播规则
但由于RUG为同构图,节点邻居的线性嵌入需要改变
e N h = ∑ t ∈ N h α ( h , r u , t ) e t e_{N_h}=\sum \limits _{t \in N_{h}} \alpha(h,r_u,t)e_t\\ eNh=t∈Nh∑α(h,ru,t)et
Heterogeneous and Homogeneous Graph
同构图中,node的种类只有一种,一个node和另一个node的连接关系只有一种
异构图中,有很多种node。node之间也有很多种连接关系(edge),这些连接关系的组合则种类更多(meta-path), 而这些node之间的关系有轻重之分,不同连接关系也有轻重之分。
最后从RUG中通过层传播得到用户嵌入。对于用户u,我们将其输出嵌入表示为ˆe_u
4.3 预测层
整合用户 u 的表示并将 用户和项目表示投影到一个维度空间中:
e u ∗ = M L P ( e ~ u ∣ ∣ e ^ u ; Φ m l p u ) e i ∗ = M L P ( e ~ i ; Φ m l p i ) e ~ u 为异构图神经网络的 u 的表示, e ^ u 为关系增强用户图神经网络用户的表示 Φ m l p 为用于投影的参数 e_u^* = MLP(\tilde e_u ||\hat e_u;\Phi_{mlp}^u)\\ e_i^* = MLP(\tilde e_i;\Phi_{mlp}^i)\\ \tilde e_u 为异构图神经网络的u的表示,\hat e_u为关系增强用户图神经网络用户的表示\\ \Phi_{mlp}为用于投影的参数 eu∗=MLP(e~u∣∣e^u;Φmlpu)ei∗=MLP(e~i;Φmlpi)e~u为异构图神经网络的u的表示,e^u为关系增强用户图神经网络用户的表示Φmlp为用于投影的参数
通过将用户表征和项目表征送入f函数计算用户的偏好评分
y ^ u i = f ( e u ∗ , e i ∗ ) f : R d × R d → R d \hat y _{ui}=f(e^*_u,e^*_i)\\ f:R^d \times R^d \rightarrow R^d y^ui=f(eu∗,ei∗)f:Rd×Rd→Rd
4.4 优化
使用OPR损失函数,具体来说,它假设,观察到的表明更多的用户偏好的交互,应该比未观察到的交互分配更高的预测值:
L = ∑ ( u , i , i ′ ) ∈ T − l n ( y ^ u i − y ^ u i ′ ) + λ ∣ ∣ Θ ∣ ∣ 2 2 i ′ 用一个随机抽样的负数项来替换 i 本身 T 表示三元组集合 λ 为正则化函数 L =\sum \limits {(u,i,i^\prime)\in T} -ln(\hat y _{ui}-\hat y _{ui^\prime})+\lambda||\Theta||^2_2\\ i^\prime用一个随机抽样的负数项来替换i本身\\ T表示三元组集合 \\ \lambda 为正则化函数 L=∑(u,i,i′)∈T−ln(y^ui−y^ui′)+λ∣∣Θ∣∣22i′用一个随机抽样的负数项来替换i本身T表示三元组集合λ为正则化函数
5 实验
5.1 准备
数据集:
Amazon -Books and Beauty.,LastFM,
http://jmcauley.ucsd.edu/data/amazon/
http://www.cp.jku.at/datasets/LFM-1b/
评价指标:
采用 Hit Ratio@N 和 NDCG@N作为评估指标
在top-K推荐中,HR是一种常用的衡量召回率的指标,计算公式为:
分母是所有的测试集合,分子表示每个用户top-K、列表中属于测试集合的个数的总和。
NDCG是在DCG基础上的优化,将一个策略的效果标准归一化,以方便不同策略的效果对比。公式如下:
参数设置:
学习率 10^-4.批量大小为 512,,嵌入大小为64,dropout为0.1,归一化系数10^-5,CKG传播层数为 3,RUG传播层为2
基线:
BPRMF,PER,CKE,RippleNet,KGNN-LS,KGAT
BPRMF 基于贝叶斯个性化排名的矩阵分解,这是一种从用户隐式学习成对个性化排名的经典方法
PER 基于路径 对HIM的源路径表示
CKE基于嵌入 源于TransR
RippleNet 混合,记忆网络传播偏好
KGNN‑LS 混合,利用GCN
KGAT
5.2 比较
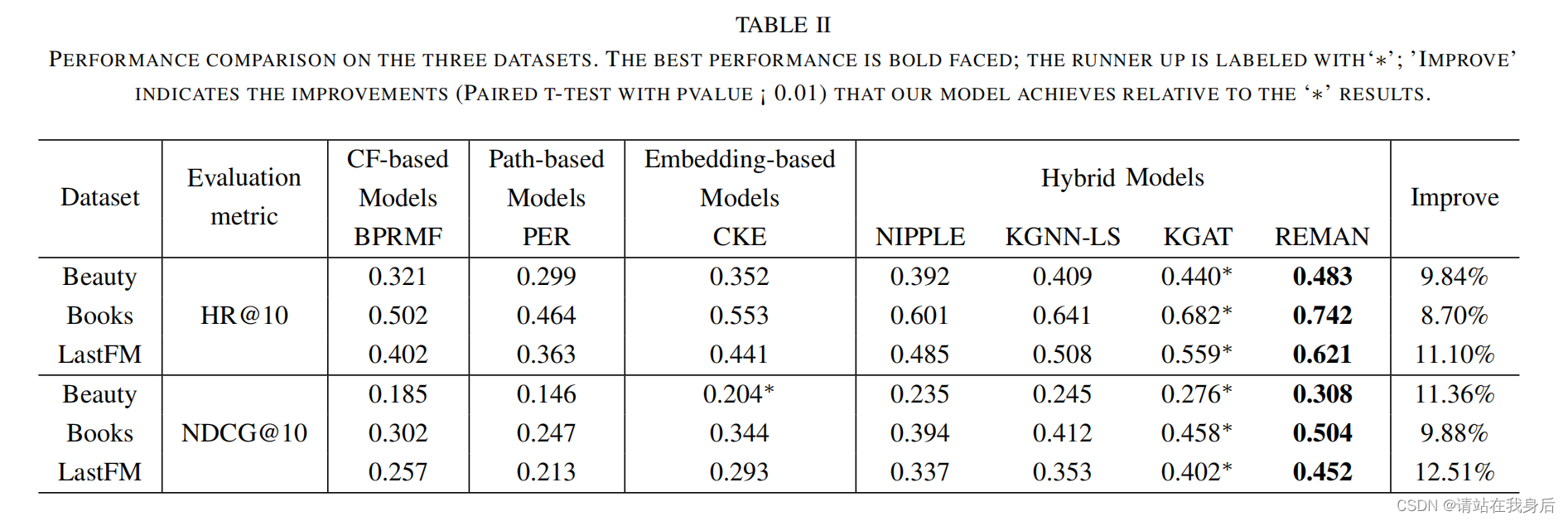
表二:
1.REMAN 优于其他极限,
2.图传播方法KGNN KGAT优于RippleNet ,传播机制在推荐有优势
3.KGAT考虑了高阶关系,但没有考虑异构图信息,在捕捉用户的个性化偏好方面薄弱
5.3 消融实验
在深度学习论文中,ablation study往往是在论文最终提出的模型上,减少一些改进特征(如减少几层网络等),以验证相应改进特征的必要性。
提出了集中变体:
REMAN_w/oKG :忽略项目元属性的知识图谱。
REMAN*_w/oRU*:去除关系增强的用户图 ,只考虑节点嵌入
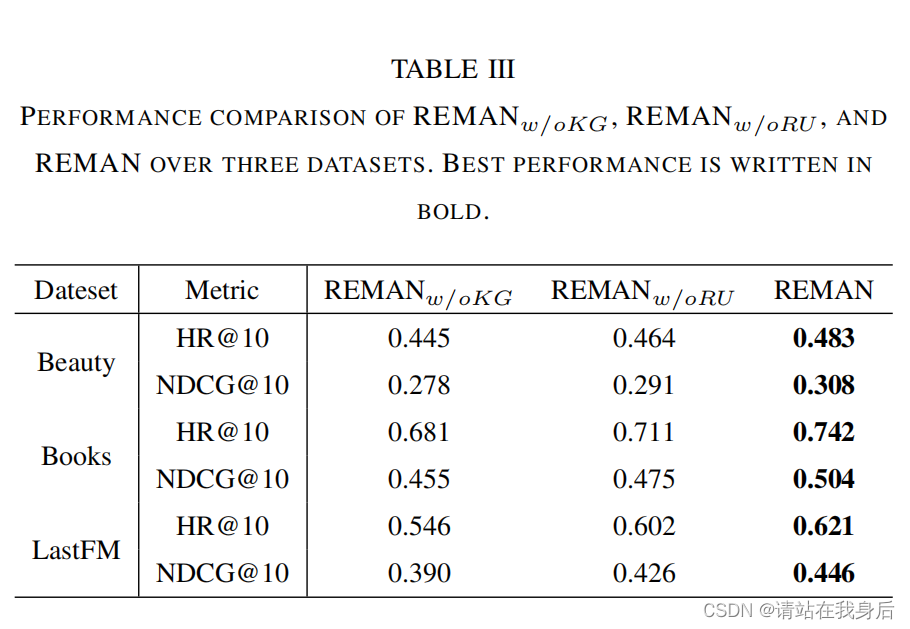
表三表明物品元属性的重要性 ,以及关系增强的用户图适用于个性化推荐
对特定关系注意力聚合器的分析:
REMAN_nr 不考虑邻居聚类中对统一邻居的注意力归一化,使用普通的注意力聚合器
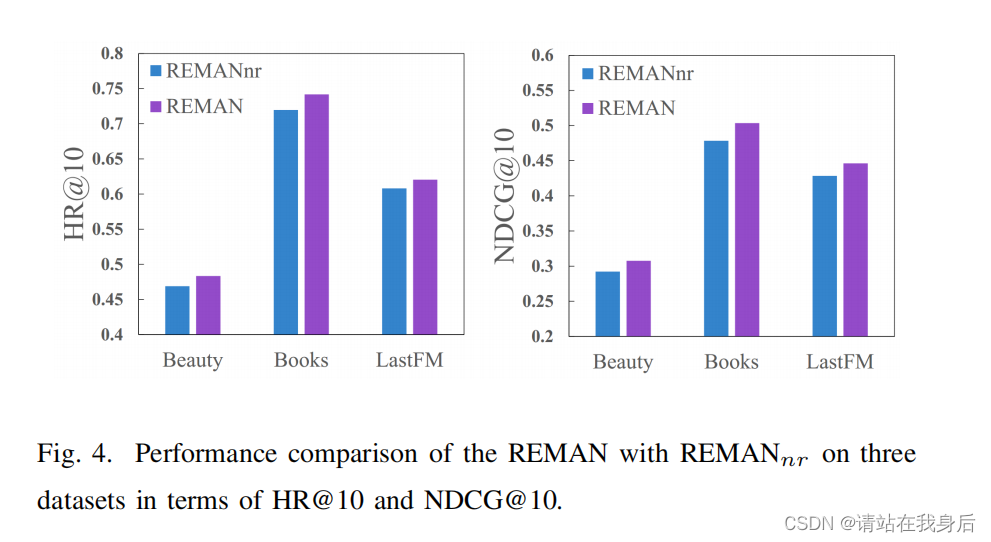
它表明了所提出的关系特定注意力聚合器的有效性。
总结
本文提出了关系增强多图注意力网络,通过对异构和高阶关系进行建模来达到推荐的目的。
本文首先将用户行为和项目知识编码为统一的关系图,然后创新地利用关系特定的注意力聚合器和关系增强的用户图来增强关系的有效性。关系特定的注意聚合器旨在聚合异构邻居的嵌入。
本文来自互联网用户投稿,文章观点仅代表作者本人,不代表本站立场,不承担相关法律责任。如若转载,请注明出处。 如若内容造成侵权/违法违规/事实不符,请点击【内容举报】进行投诉反馈!