mysql8高级——视图、事务、窗口函数与常用日期时间函数
目录
一、视图
(一)视图的创建
(二)查看视图
语法1:查看数据库的表对象、视图对象
语法2:查看视图的结构
语法3:查看视图的属性信息
语法4:查看视图的详细定义信息
(三)视图的修改
(四)删除视图
二、事务
(一)事务概述
(二)事务四大特征(面试常考)——(ACID)
(三)事务的实现过程
(四)索引的其他操作
1.给表中字段添加索引
2.添加主键索引
3.删除索引
三、Explain
四、数据库的备份与恢复
(一)数据库的备份
(二)数据库的恢复
五、group_concat()字符串连接函数
1.表中数据与字符串简单拼接
2.表中数据通过分隔符按照顺序连接
3.表中数据较复杂连接
六、开窗函数
1.row_number()——1234
2.rank()——1134
3.dense_rank()——1223
4.lead()与lag()
5.first_value()与last_value()
6.NTH_VALUE(expr, n)
7.ntile()
七、常用的日期时间函数
(一)日期(date)函数
1.返回当前日期
2.将日期转换为数字并进行计算
(二)时间(time)函数
1.返回当前时间
2.日期和时间函数——时间戳
(三)日期与时间的比较
(四)日期与时间的运算
1.时间戳之间的运算
2.日期差
3.时间差
(五)日期与时间的格式化
1.DATE_FORMAT(date,format)函数——时间转字符串
2.STR_TO_DATE(str,format)——字符串转时间
3.其他日期函数
一、视图
(一)视图的创建
# 简单创建视图
# 视图中的字段与基表中的字段一一对应
CREATE VIEW VU_emp1
AS SELECT StudentId,StudentName,StudentAge
FROM student;# 查询视图中的数据
SELECT *
FROM VU_emp1;# 按条件创建视图
# 查询语句中字段的别名会作为视图中字段的名称出现
CREATE VIEW VU_emp2
AS SELECT StudentId ID,StudentName NAME,StudentAge age
FROM student
HAVING age>20;# 小括号内的字段个数与SELECT中字段个数相同
CREATE VIEW VU_emp3(ID,NAME,AGE)
AS SELECT StudentId,StudentName,StudentAge
FROM student
WHERE StudentAge=20;# 视图中的字段在基表中可能没有对应的字段
# 查询平均年龄
CREATE VIEW VU_emp4
AS SELECT StudentId,StudentName,StudentAge,AVG(StudentAge) avg_age
FROM student
GROUP BY StudentId,StudentName,StudentAge;# 在视图的基础上创建视图
CREATE VIEW VU_emp5
AS SELECT StudentId,StudentName,StudentAge
FROM VU_emp4;# 其他形式的视图的创建
CREATE VIEW VU_emp6
AS SELECT CONCAT(stu.Studentname,'(',stu.studentClass,')') emp_info
FROM student stu;(二)查看视图
语法1:查看数据库的表对象、视图对象
SHOW TABLES;语法2:查看视图的结构
DESC EMP1;语法3:查看视图的属性信息
(XSHELL中输入)mysql> SHOW TABLE STATUS LIKE 'EMP'\G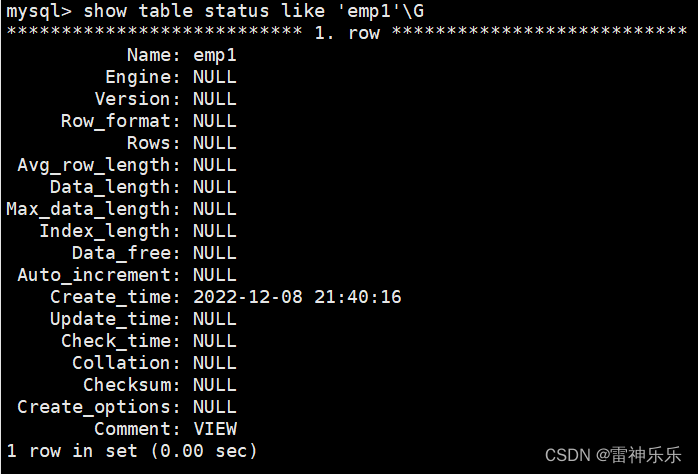
语法4:查看视图的详细定义信息
SHOW CREATE VIEW EMP1\G
(三)视图的修改
方式一:
CREATE OR REPLACE VIEW emp1
AS SELECT Sname,Ssex
FROM student
WHERE SID>'05';方式二:
ALTER VIEW students.emp1
AS SELECT Sname,Ssex 性别
FROM student
WHERE SID<'05';(四)删除视图
DROP VIEW IF EXISTS students.emp1;二、事务
(一)事务概述
事务是一组操作的集合,它是一个不可分割的工作单位,事务会把所有的操作作为一个整体一起向系统提交或撤销操作请求,即这些操作要么同时成功,要么同时失败。比较典型的事务案例是银行转账。
(二)事务四大特征(面试常考)——(ACID)
- 原子性(Atomicity):事务是不可分割的最小操作单元,要么全部成功,要么全部失败。
- 一致性(Consistention):事务完成时,必须使所有的数据都保持一致状态。
- 隔离性(Isolation):数据库系统提供的隔离机制,保证事务在不受外部并发操作影响的独立环境下运行。
- 持久性(Durability):事务一旦提交或回滚,它对数据库中的数据的改变就是永久的。
(三)事务的实现过程
mysql中默认事务是自动提交,使用事务时应关闭自动提交
改变事务自动提交模式的方法——使用SET语句
# 关闭自动提交模式
SET AUTOCOMMIT=0;
# 开启自动提交模式
SET AUTOCOMMIT=1;
我们先建立一个account表
create table if not exists account
(id int(10) not null primary key auto_increment,name varchar(32) not null,cash decimal(9, 2) not null
);# 往表中插入数据
insert into account(name, cash)
values ('张三', 3000.00),('李四', 2000.00);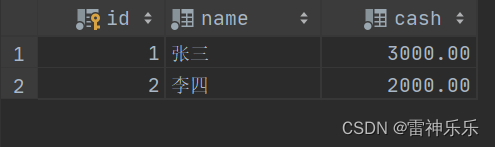
# 关闭事务自动提交
set autocommit = 0;# 开启事务
start transaction;# 张三给李四转账500元
update account set cash = cash - 500 where id = 1;# 查看转账是否成功
select * from account;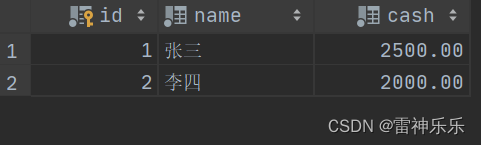
发现张三的账户-500,但是李四的账户并没有+500
此时要进行事务的回滚,回到最初状态
rollback;回滚后,张三减去的500元已经成功+回来
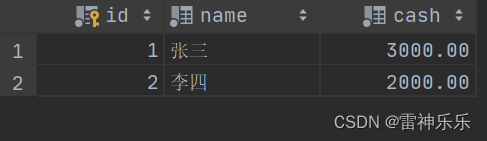
那么如何让一方-500,一方+500呢?
# 我们要执行两条语句:
update account set cash = cash - 500 where id = 1;update account set cash = cash + 500 where id = 2;# 再查看表中的数据,执行成功,数据无误!
SELECT * FROM account;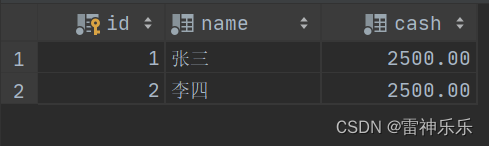
# 执行无误后,事务进行提交
commit;# 提交后的事务即便进行回滚也是无效的,表中的数据的改变是永久的
rollback;SELECT * FROM account;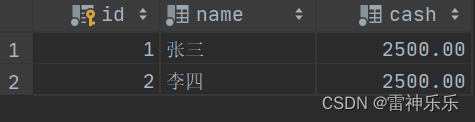
(四)索引的其他操作
1.给表中字段添加索引
mysql> alter table result add index (studentno, subjectno);mysql> show create table result;
| result | CREATE TABLE `result` (`studentno` int DEFAULT NULL,`subjectno` int DEFAULT NULL,`examdate` datetime DEFAULT NULL,`studentresult` int DEFAULT NULL,KEY `studentno` (`studentno`,`subjectno`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci |2.添加主键索引
mysql> alter table result add primary key(studentno,subjectno,examdate);3.删除索引
mysql> alter table result drop index `studentno`;三、Explain
在select语句之前增加explain关键字,执行后MySQL就会返回执行计划的信息,而不是执行sql。但如果from中包含子查询,MySQL仍会执行该子查询,并把子查询的结果放入临时表中。
EXPLAIN SELECT * FROM student;
EXPLAIN SELECT *
FROM student
WHERE Sname IN (SELECT SnameFROM studentGROUP BY Snamehaving COUNT(SID) > 1);
四、数据库的备份与恢复
(一)数据库的备份
数据库的备份
[root@localhost ~]# mysqldump -uroot -proot myschool>/opt/soft/mychool.sql
备份指定数据库下的一张表
[root@localhost ~]# mysqldump -uroot -proot myschool teacher>/opt/soft/teacher.sql
备份指定数据库下的多张表
[root@localhost ~]# mysqldump -uroot -proot myschool grade car>/opt/soft/gradecar.sql(二)数据库的恢复
mysql> create database testdemo;
方法一:
[root@localhost ~]# mysql -uroot -proot testdemo use testdemo;
mysql> source /opt/soft/myshool.sql# 数据库中表的恢复
[root@localhost ~]# mysql -uroot -proot testdemo五、group_concat()字符串连接函数
1.表中数据与字符串简单拼接
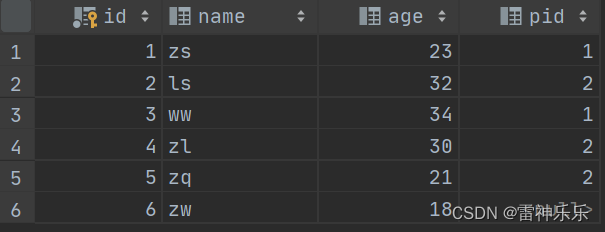
select id,group_concat(name,'-abc') newline
from person
group by id;2.表中数据通过分隔符按照顺序连接
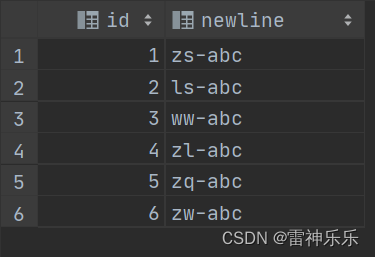
select pid,group_concat(pid order by age desc separator '#') newlist
from person
group by pid;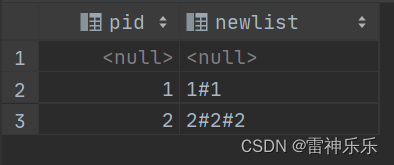
3.表中数据较复杂连接
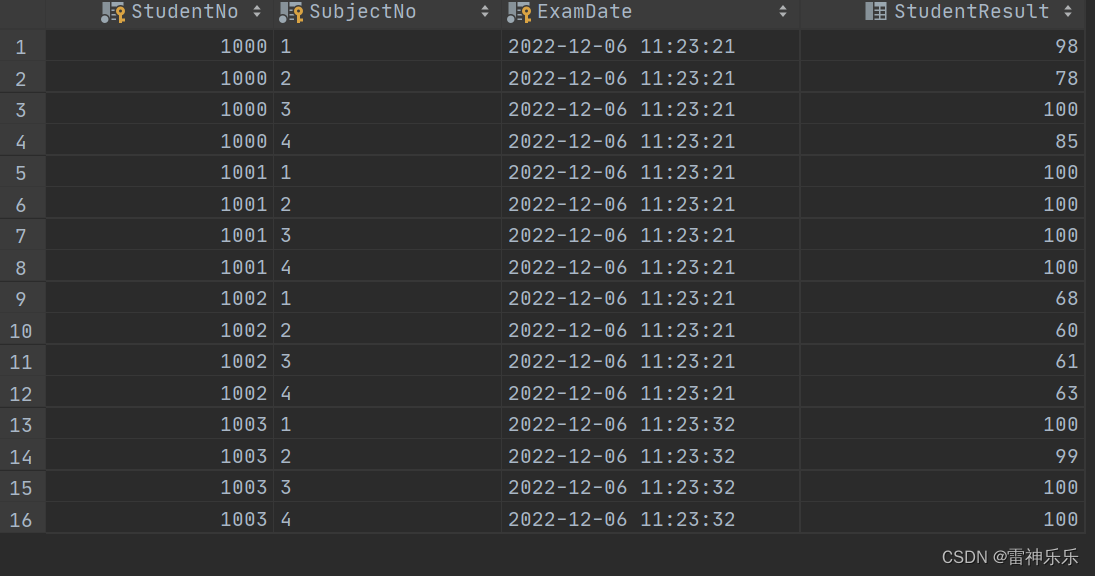
select studentno,
group_concat(distinct subjectno order by subjectno desc separator '#') subjectnolist,
group_concat(distinct studentresult order by studentresult asc) studentresultlist
from result group by studentno;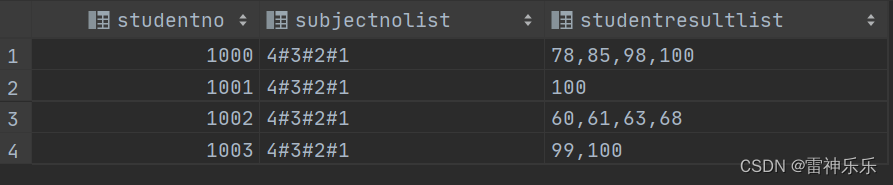
六、开窗函数
开窗函数的讲解大家可以参考这篇博文:
MySQL8中的开窗函数_Gan_1314的博客-CSDN博客_mysql8开窗函数
开窗函数的格式:
Function() over(partition by query_patition_clause order by order_by_clause Window_clause )
函数(Function)的类型
不是所有的函数(Function)都支持开窗函数。目前支持的窗口函数可结合的函数有:
排名函数 ROW_NUMBER();
排名函数 RANK() 和 DENSE_RANK();
错行函数 lead()、lag();
取值函数 First_value()和last_value();
分箱函数 NTILE();
统计函数,也就是我们常用的聚合函数 MAX()、MIN()、AVG()、SUM()、COUNT()
开窗函数的使用示例:
建表,插入数据:
create table test
(id int,name varchar(10),sale int
);
insert into test
values (1, 'aaa', 100);
insert into test
values (1, 'bbb', 200);
insert into test
values (1, 'ccc', 200);
insert into test
values (1, 'ddd', 300);
insert into test
values (2, 'eee', 400);
insert into test
values (2, 'fff', 200); 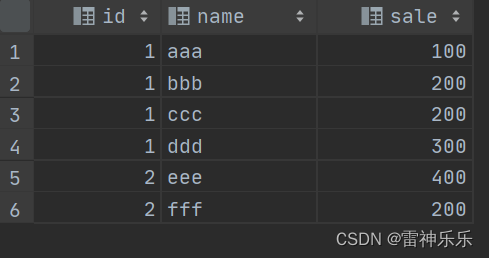
1.row_number()——1234
row_number() over(partition by col1 order by col2)
# 无差别排序
select t.*,row_number() over (order by sale desc) rank1
from test t;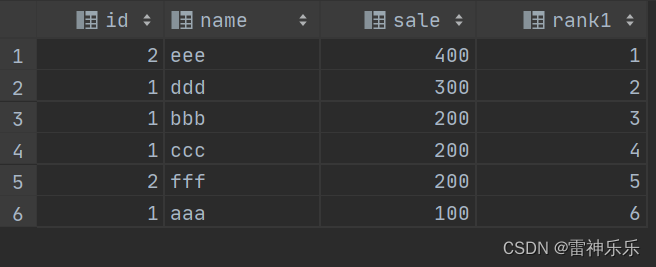
# 根据id进行分组
select t.*,row_number() over (partition by id order by sale desc) as rank1
from test t;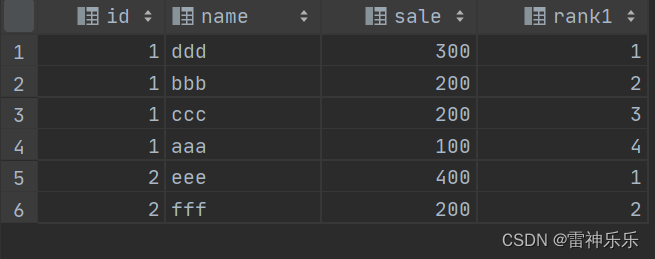
2.rank()——1134
有相同的名次跳过
rank() over(partition by col1 order by col2)
# 跳跃排序
select t.*,rank() over (partition by id order by sale desc) as rank1
from test t;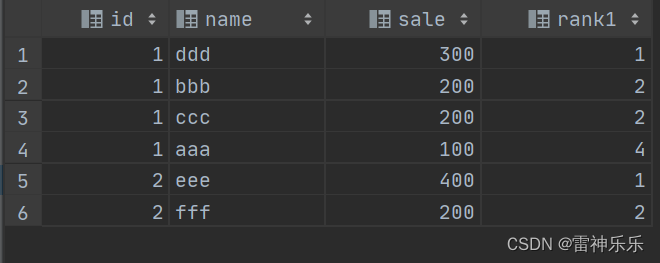
3.dense_rank()——1223
有重复名次也不会跳跃
# 顺延排序
select t.*,dense_rank() over (partition by id order by sale desc) as rank1
from test t; 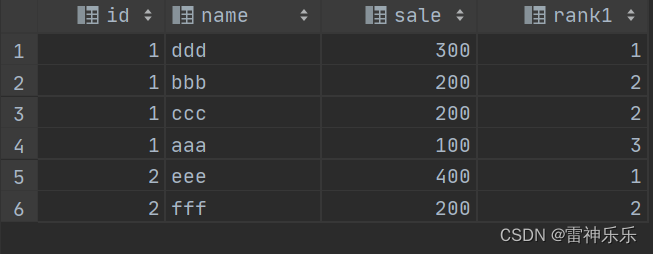
4.lead()与lag()
lead函数与lag函数是两个偏移量函数,主要用于查找当前行字段的上一个值或者下一个值。lead函数是向下取值,lag函数是向上取值,如果向上取值或向下取值没有数据的时候显示为NULL,这两个函数的格式为:
lead(EXPR,
, ) over(partition by col1 order by col2)
lag(EXPR,, ) over(partition by col1 order by col2) EXPR通常是直接是列名,也可以是从其他行返回的表达式;
OFFSET是默认为1,表示在当前分区内基于当前行的偏移行数;
DEFAULT是在OFFSET指定的偏移行数超出了分组的范围时(因为默认会返回null),可以通过设置这个字段来返回一个默认值来替代null。
是按照id分组,sale升序排序,lead()取sale的前一位,如果没有前一位,默认是0;lag()取sale得后一位,如果没有后一位,默认是0。
select t.*,lead(sale, 1, 0) over (partition by id order by sale ) next,lag(sale, 1, 0) over (partition by id order by sale) pre
from test t;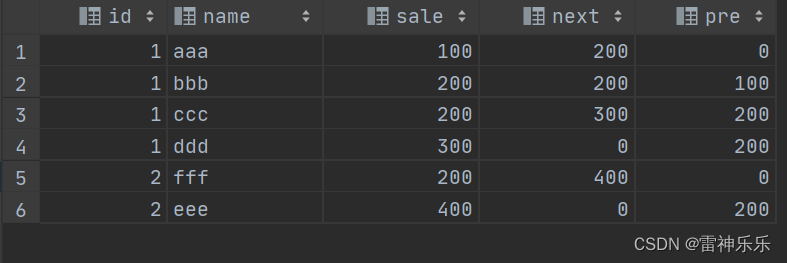
设置偏移量为2,没有默认为null:
select t.*,lead(sale, 2) over (partition by id order by sale ) next,lag(sale, 2) over (partition by id order by sale) pre
from test t;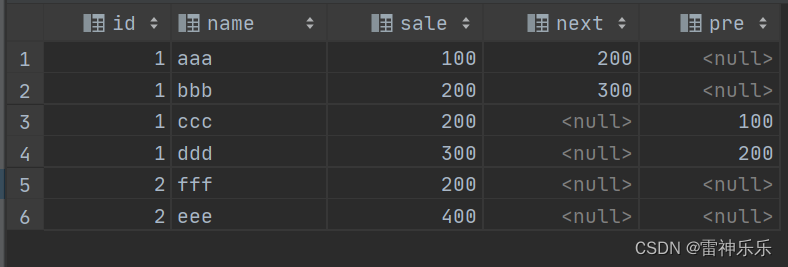 5.first_value()与last_value()
5.first_value()与last_value()
first_value()取每个窗口的第一个数据
last_value()取每个窗口的最后一个数据
select t.*,first_value(sale) over (partition by id order by sale) first,last_value(sale) over (partition by id order by sale) last1,last_value(sale) over (partition by id) last2
from test t;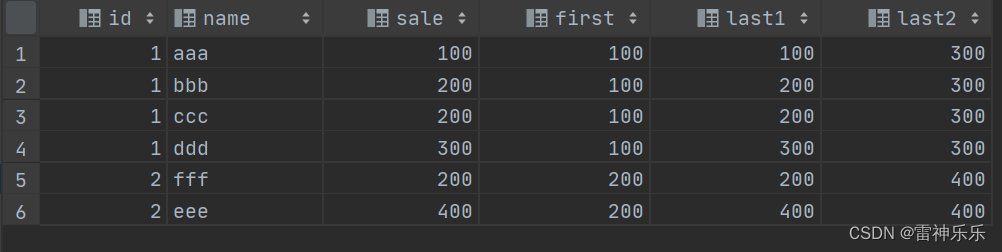
last1与last2的区别:
last1列表中:
查询到第1行sale=100,只有当前一行,最后一个值只有100,开窗结果为100;
查询到第2行sale=100,200两个数据,最后一个值是200,开窗结果为200;
查询到第3行sale=100,200,200三个数据,最后一个值是200,开窗结果为200;
查询到四行sale=100,200,200,300四个数据,最后一个值是300,开窗结果为300,至此id=1的分组查询完毕
6.NTH_VALUE(expr, n)
函数的意思是:取排名总的哪个字段(也可以是表达式),取第几个
示例1:按照id分组进行sale字段的排名,并且取sale排名的第2个
select t.*,row_number() over (partition by id order by sale ) 排名,nth_value(sale, 2) over (partition by id order by sale) second
from test t;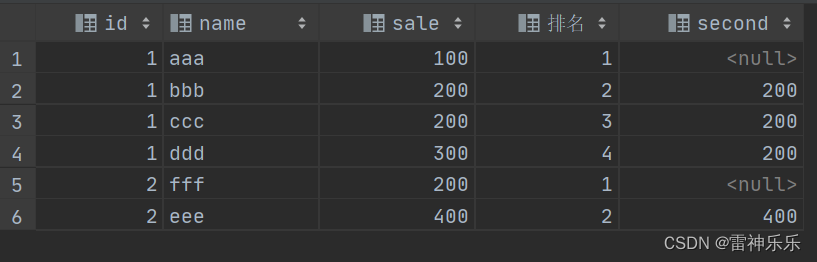
示例1:按照id分组进行sale字段的排名,并且取sale排名的第3个
select t.*,row_number() over (partition by id order by sale ) 排名,nth_value(sale, 3) over (partition by id order by sale) second
from test t;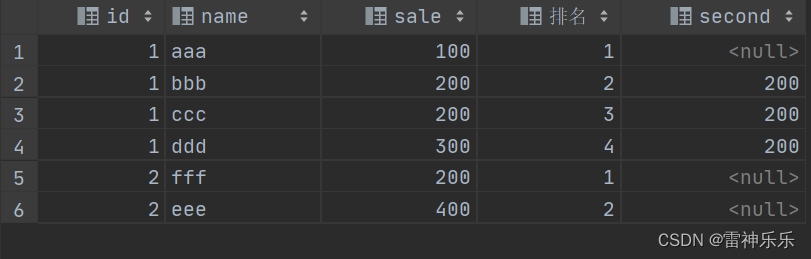
7.ntile()
nitle()函数是将结果集进行划分为不同的桶中,参数为int,意思是划分为几个桶,最大的放在第一个桶中,最小的放在最后一个桶中,其他的分别按照顺序放入别的桶中。
SELECT T.*,NTILE(3) over (PARTITION BY ID ORDER BY SALE DESC) bucket
FROM test T;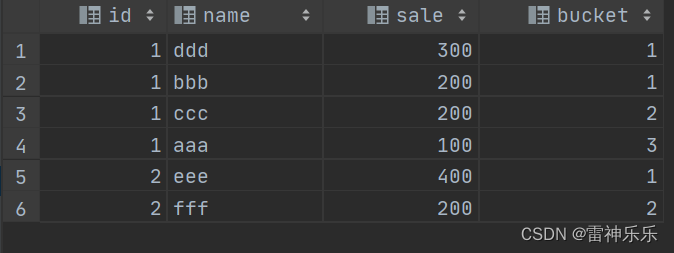
如果桶太多会出现放不尽的情况
SELECT T.*,NTILE(5) over (PARTITION BY ID ORDER BY SALE DESC) bucket
FROM test T;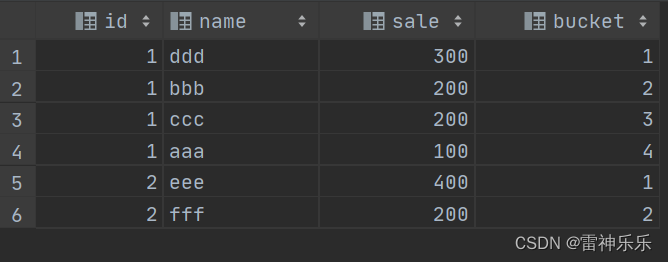
七、常用的日期时间函数
(一)日期(date)函数
1.返回当前日期
SELECT CURDATE(),CURRENT_DATE(),CURRENT_DATE;2.将日期转换为数字并进行计算
SELECT CURDATE(),CURRENT_DATE+10;
(二)时间(time)函数
1.返回当前时间
SELECT CURTIME(),CURRENT_TIME(),CURRENT_TIME;
2.日期和时间函数——时间戳
SELECT CURRENT_TIMESTAMP(), CURRENT_TIMESTAMP, LOCALTIME(), LOCALTIME, LOCALTIMESTAMP(), LOCALTIMESTAMP, NOW(), SYSDATE(); (三)日期与时间的比较
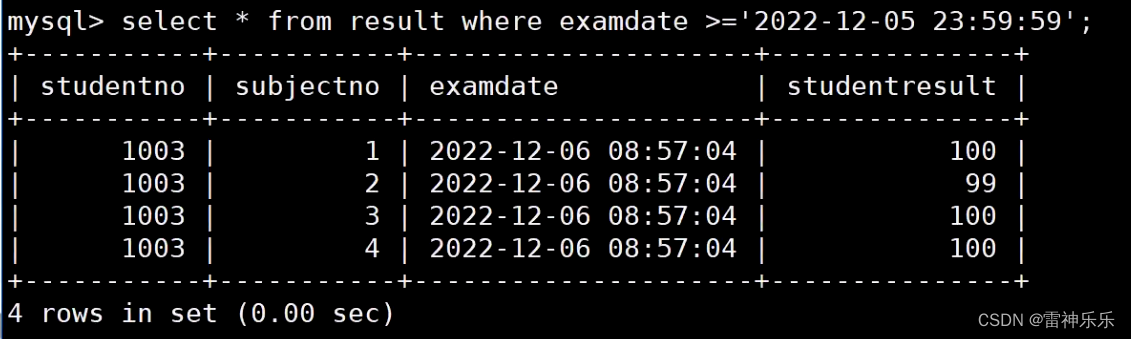
(三)日期与时间的比较
(四)日期与时间的运算
1.时间戳之间的运算
SELECT DATE_ADD(NOW(),INTERVAL 3 MINUTE_MICROSECOND );
SELECT DATE_ADD(NOW(),INTERVAL 3 SECOND );
SELECT DATE_ADD(NOW(),INTERVAL 3 MINUTE );
SELECT DATE_ADD(NOW(),INTERVAL 3 HOUR );
SELECT DATE_ADD(NOW(),INTERVAL 3 DAY );
SELECT DATE_ADD(NOW(),INTERVAL 3 WEEK );
SELECT DATE_ADD(NOW(),INTERVAL -3 MONTH );
SELECT DATE_ADD(NOW(),INTERVAL 3 QUARTER );
SELECT DATE_ADD(NOW(),INTERVAL 3 YEAR );2.日期差
SELECT DATEDIFF(NOW(),'2022-12-01');
SELECT DATEDIFF('2020-01-01','2022-12-01'); (第一个日期)-(第二个日期)
3.时间差
SELECT TIMEDIFF(CURRENT_TIME,'12:30:05');
SELECT TIMEDIFF('15:30:05','12:30:05');
(五)日期与时间的格式化
1.DATE_FORMAT(date,format)函数——时间转字符串
%p:PM 或AM;
%r:HH:mm:ss PM形式时间;
%W:周,周名,如Tuesday;
%w:周,0-6,0为周日;
%j:当前日期所在一年中的天数,3位(001-366)。

SELECT DATE_FORMAT(SYSDATE(),'%Y-%m-%d %H:%i:%s');
SELECT DATE_FORMAT(NOW(),'%M-%D');
2.STR_TO_DATE(str,format)——字符串转时间
将指定的时间格式的字符串按照格式转换为DATETIME类型的值。str要与format的格式保持一致,否则会报错。
SELECT STR_TO_DATE('2022-11-15','%Y-%m-%d');SELECT STR_TO_DATE('2022-11-15 12:15:30','%Y-%m-%d %H:%i:%s');3.其他日期函数
SELECT YEAR(NOW()); # 2022
SELECT MONTH('2021-09-09'); # 9本文来自互联网用户投稿,文章观点仅代表作者本人,不代表本站立场,不承担相关法律责任。如若转载,请注明出处。 如若内容造成侵权/违法违规/事实不符,请点击【内容举报】进行投诉反馈!