Decoupling Representation and Classifier for Long-Tailed Recognition 图像领域长尾分布分类问题方法
文章目录
- 往期文章链接目录
- Introduction
- Recent Directions
- Sampling Strategies
- Methods of Learning Classifiers
- Classifier Re-training (cRT)
- Nearest Class Mean classifier (NCM)
- τ \tau τ-normalized classifier ( τ (\tau (τ-normalized)
- Experiments
- Datasets
- Evaluation Protocol
- Results
- Sampling matters when training jointly
- Instance-balanced sampling generalize well
- Decoupled Learning strategy helps
- Weight Norm Visualization
- Compare to SOTA
- Contributions
- 往期文章链接目录
往期文章链接目录
Introduction
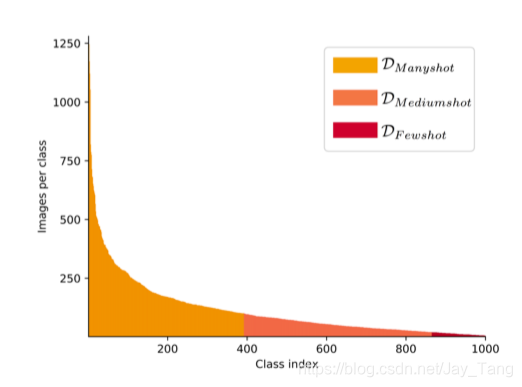
When learning with long-tailed data, a common challenge is that instance-rich (or head) classes dominate the training procedure. The learned classification model tends to perform better on these classes, while performance is significantly worse for instance-scarce (or tail) classes (under-fitting).
The general scheme for long-tailed recognition is: classifiers are either learned jointly with the representations end-to-end, or via a two-stage approach where the classifier and the representation are jointly fine-tuned with variants of class-balanced sampling as a second stage.
In our work, we argue for decoupling representation and classification. We demonstrate that in a long-tailed scenario, this separation allows straightforward approaches to achieve high recognition performance, without the need for designing sampling strategies, balance-aware losses or adding memory modules.
Recent Directions
Recent studies’ directions on solving long-tailed recognition problem:
- Data distribution re-balancing. Re-sample the dataset to achieve a more balanced data distribution. These methods include over-sampling, down-sampling and class-balanced sampling.
- Class-balanced Losses. Assign different losses to different training samples for each class.
- Transfer learning from head- to tail classes. Transfer features learned from head classes with abundant training instances to under-represented tail classes. However it is usually a non-trivial task to design specific modules for feature transfer.
Sampling Strategies
For most sampling strategies presented below, the probability p j p_j pj of sampling a data point from class j j j is given by: p j = n j q ∑ i = 1 C n i q p_{j}=\frac{n_{j}^{q}}{\sum_{i=1}^{C} n_{i}^{q}} pj=∑i=1Cniqnjq where q ∈ [ 0 , 1 ] q \in[0,1] q∈[0,1], n j n_j nj denote the number of training sample for class j j j and
本文来自互联网用户投稿,文章观点仅代表作者本人,不代表本站立场,不承担相关法律责任。如若转载,请注明出处。 如若内容造成侵权/违法违规/事实不符,请点击【内容举报】进行投诉反馈!