每日一课 | 栈与队列的存储结构与实现

05.
栈与队列的存储结构与实现
大家好,我是小C,上期给大家分享—— 栈与队列的定义
本期分享内容:栈与队列的存储结构与实现
本期小C邀请的是春晨溅雨·4位算法工程师为我们分享《数据结构算法面试全解析》专栏。
数据结构算法面试
栈与队列的存储结构与实现
1 栈的多种存储结构以及实现
栈有两种实现方式一种是顺序存储结构、还有一种是链式存储结构。这两种存储结构对应两种存储的数据结构:数组和链表。数组和链表的相关内容可以参考本文其他章节的内容。
1.1 栈的顺序存储结构
前面我们说了栈是数据结构中线性表的特殊存在,所以栈的顺序存储方式也就是线性表的顺序存储的方式,也就是我们接下来要讲的顺序栈,因此顺序栈的实现形式也就是线性表顺序存储的实现形式-数组。因为栈底的变化最小,所以将数组下标为 0 的一端作为栈底,同时还要定义一个变量,用来表示栈顶元素在数组中的位置。
1.2 顺序栈的各类功能实现
/*
@author T-Cool
*/
//属性定义和构造函数
public class SortStack {public Object[] data; // 数组表示栈内元素public int maxSize; // 栈空间大小public int top; // 栈顶指针(指向栈顶元素)//初始化栈的长度public SortStack(int initialSize){if(initialSize>=0){this.data=new Object[initialSize];this.maxSize=initialSize;this.top=-1;}else{System.out.println("栈初始化失败!");}}//判断栈是否为空public boolean isEmpty(){return top == -1 ? true : false;}//判断是否栈满public boolean isFull(){return top == maxSize-1 ? true : false;}//入栈public void push(Object value){if(!isFull()){System.out.print(value+"入栈 ");data[++top]=value;}else{System.out.println("满栈,无法进行入栈操作!");}}/*** * 先判断是否为空栈* @return*///元素出栈public Object pop(){Object num=null;if(!isEmpty()){num = data[top--];return num;}else{return "空栈,无法进行出栈操作!";}}// 获取栈顶元素public Object getPeek(){if(top>=0){return data[top];}else{return "栈顶指针为空,无栈顶元素!";}}//遍历栈内元素public void displayStack(){// 栈顶指针不为—1,栈内有元素,进行打印if(top>=0){for(int i=top;i>=0;i--){System.out.print(data[i] + " ");}System.out.println();}else{System.out.println("栈内元素为空!");} }//获取栈顶指针为 n 的栈内元素public Object getPeekN(int n){if(n1.3 栈的链式存储结构
栈的链式结构是通过链表连接起来的。好了,我们现在再回忆一下栈的结构,栈是先进后出,所有的操作都在栈顶完成,包括插入和删除,所以要考虑一下讲栈顶放在整个链表的头部还是尾部。因为链表具体头结点,因此可以考虑将栈顶和头结点结合。我们将栈顶的元素放在一条链表的头部。所以通常来说,对于栈链来说,是不需要头结点的。
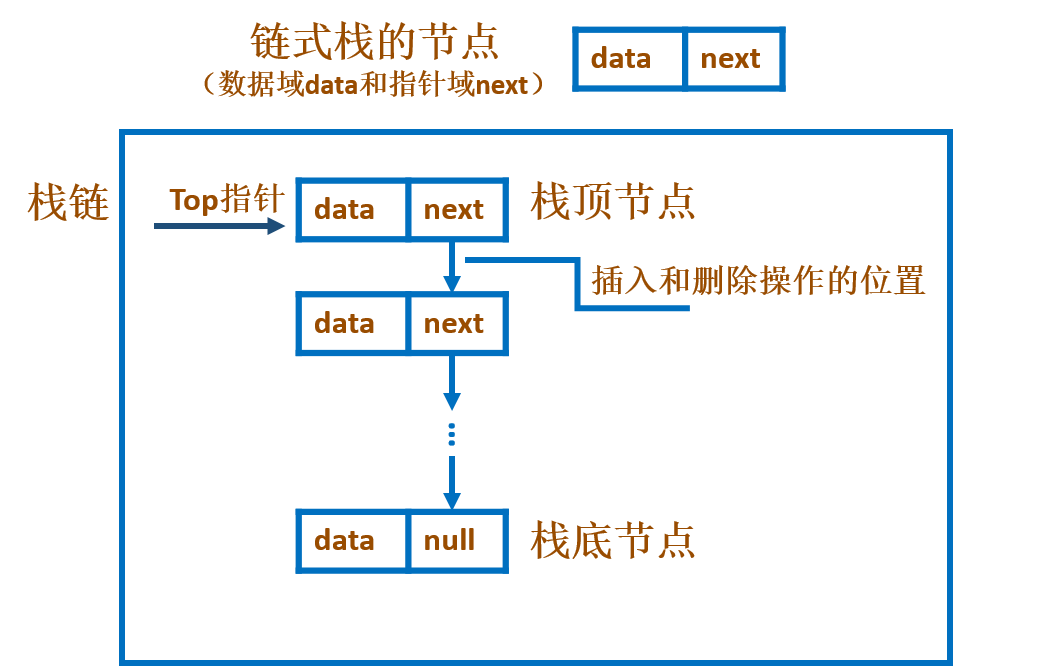
而从计算机内存的角度看栈链,基本不存在栈满的情况,除非内存没有了可以使用的空间。更直观地解释栈链与数组栈之间的区别就是,一个是充分利用内存中的零碎空间,还有一个是占据内存中的大块空间。
1.4 栈链的各类功能实现
/*
@author T-Cool
*/
//属性定义和构造函数
class InitStack{private int [] data = new int[1]; //存储元素值private InitStack nextStack; //存储下一地址public InitStack() { //用于生成头结点this.data = null;this.nextStack = null;}public InitStack(int data) { //用于生成链栈结点this.data[0] = data;this.nextStack = null;}
}
//清空栈链
public void clearStack() {this.nextStack = null; //令头结点的下一地址为空,链栈即被清空}
// 检查栈链是否为空
public int stackLength() {InitStack theStack = this.nextStack; //获取头结点的下一地址即链栈的第一个结点int i = 0; //初始化计数器for (i = 0; theStack != null; i++) { //循环判断如不为空,则计数器加一theStack = theStack.nextStack;}return i;
}
// 获取栈顶元素
public int [] getTop() {if(this.nextStack == null) { //判断是否为空栈return null;}return this.nextStack.data;
}
// 进行压栈
public void push(int input) {InitStack initStack = new InitStack(input);initStack.nextStack = this.nextStack;this.nextStack = initStack;}
//元素出栈
public int [] pop() {if (this.nextStack == null) { //判断栈是否为空return null;}int [] i = this.nextStack.data; //获取栈顶元素值this.nextStack = this.nextStack.nextStack; //删除栈顶元素return i;
}
//栈顶到栈底遍历栈
public String stackTraverse() { //这里通过输出栈元素值来表示遍历InitStack theStack = this.nextStack;String s = "";while(theStack != null) { //循环遍历栈s = theStack.data[0] + "、" + s;theStack = theStack.nextStack;}if(s.length() == 0) { //如果未获得值,则直接输出空字符串return s;}return s.substring(0,s.length() - 1); //除去最后的顿号后返回字符串2 队列的多种存储结构以及实现
和栈一样,队列也有两种实现的方式,顺序队列和链式队列。其中顺序队列中需要注意所谓的“溢出”问题。在接下来的内容中,我将详细讲述。
2.1 队列的顺序存储结构
建立顺序型队列必须进行静态内存分配或者动态地申请一块连续的内存空间,然后再设置两个内存指针进行空间管理。队头指针为front,指向队头元素;队尾指针rear,指向下一个入队元素的存储位置。在队尾插入一个新的元素,rear+1;在队头删除一个元素,front+1。当队列进行插入删除操作时,队列元素的个数不断变化,队列所占存储空间在队列初始分配的连续空间中移动。
假设队列有 n 个元素,则顺序存储的队列空间必然要大于 n,并将数组下标为 0 设置为队列头。入队操作,我们很好理解,就是在数组最后添加上一个新的元素。而出队操作就不太方便了,需要将队列头位置空出,同时还要将数组其他位置的元素向前移动,保证队列头非空。这样的操作逻辑导致了顺序队列的空间复杂度较大。如果我们转变一下思维,将固定的首尾索引,改为可以来回变化的索引,这样就能极大提升队列的性能。
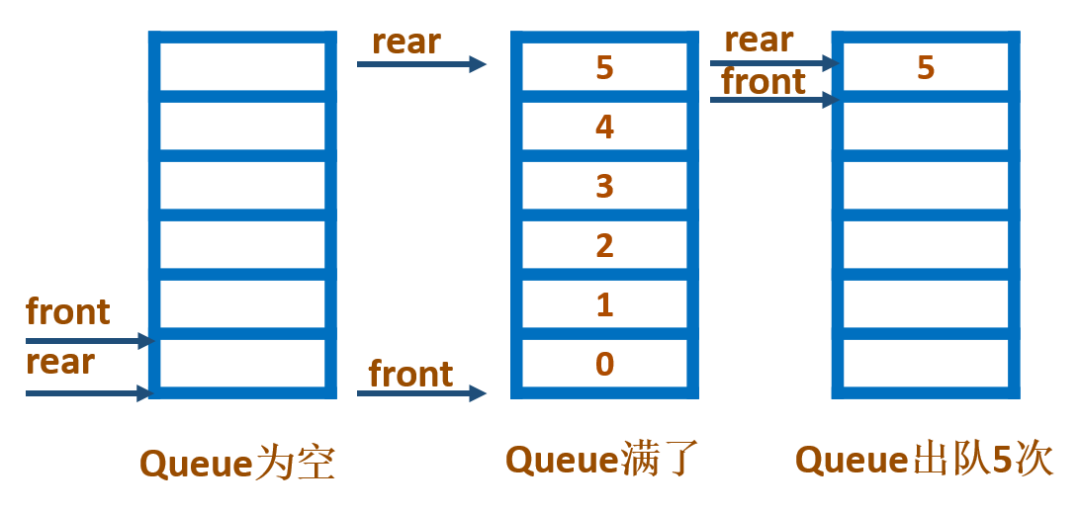
从上图可以看出,当队列中的元素依次出队,队列只剩下一个元素时,队列的front和rear均指向队尾元素。此时,再想向队列中加入新的元素,队列就会产生数组越界错误,然后队列中还有很多位置时空闲的,我们将这个问题称之为:“假溢出”。这样就会出现我们经常所说的“假溢出”现象:由于入队和出队操作中,头尾指针只增加不减小,致使被删元素的空间永远无法重新利用。当队列中实际的元素个数远远小于向量空间的规模时,也可能由于尾指针已超越向量空间的上界而不能做入队操作。这个问题由队列“队尾入队,队头出”的操作原则造成的。除了“假溢出”现象,这里在介绍另外两个“溢出”现象:
"下溢"现象:当队列为空时,出队运算产生的溢出现象。“下溢”是正常现象,常用作程序控制转移的条件。
"真上溢"现象:当队列满时,做进栈运算产生空间溢出的现象。“真上溢”是一种出错状态,应设法避免。
解决假溢出的方法是将顺序队列看成是首尾相接的循环结构,这种队列也叫作循环顺序队列。那问题来了,之前所说的,空队列,front指针等于rear指针。而我们引入了循环队列之后,队列满的时候,rear也等于front。所以该如何判断队列是空还是满呢?现在比较流行的,有三种方案:
方案一:设置一个标志(
flag)用来指示队列的满与空的状态。初始时设置flag=0,当入队操作成功就设置flag=1;当出队操作成功就设置flag=0。那么对列为空的判断条件是:rear==front && tag==0;队列满的判断条件是:rear==front && tag==1。方案二:保留一个元素的存储空间。此时队列满时的判断条件为
(rear+1)%maxsize==front;队列为空的判断条件还是front==rear。方案三:可以设计一个计数器
count,统计队列中的元素个数。此时,队列满的判断条件为:count>0 && rear==front;判断队列为空的条件为count==0
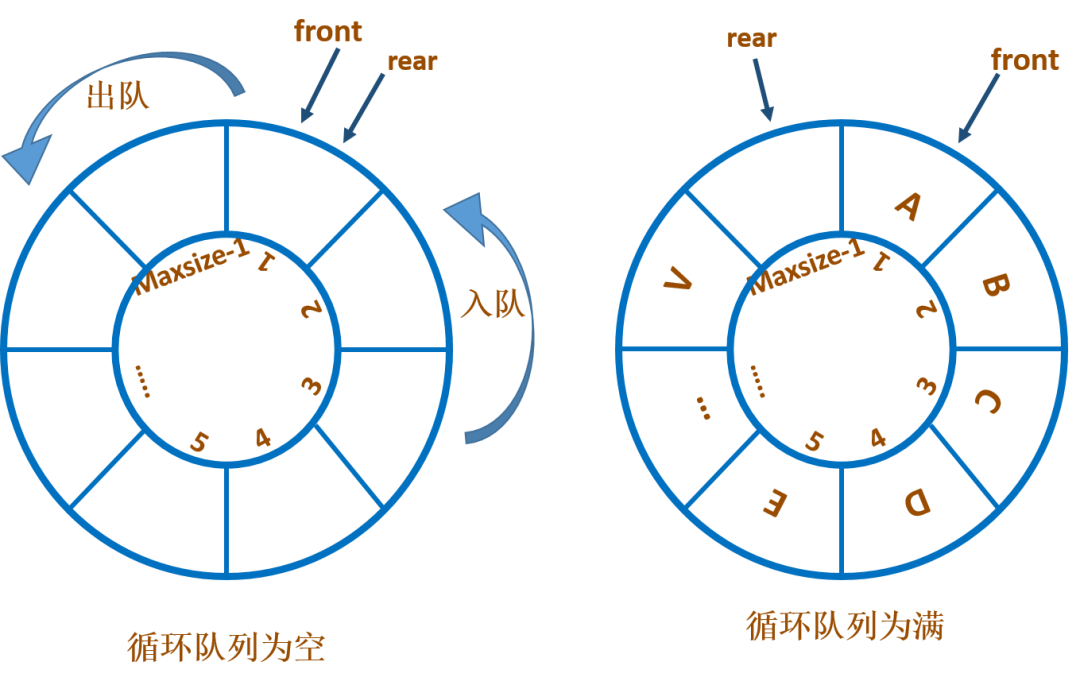
我们在这里选择第二套方案,需要注意的是:
队头指示器的
+1操作:front=(front+1)%maxsize队尾指示器的
+1操作:rear=(rear+1)%maxsize判断队列为空的条件:
rear=front判断队列为满的条件:
(rear+1)%maxsize=front队列元素个数:
(rear-front+maxsize)%maxsize相关参数的含义:
front表示队头,rear表示队尾,两者的范围是:0-maxsize-1
2.2 顺序队列各类功能实现
public class SeqQueue implements IQueue {private int maxsize; //队列的容量private E[] data; // 存储循环顺序队列中的数据元素private int front; // 指示最近一个己经离开队列的元素所占的位置private int rear; // 指示最近一个进行入队列的元素的位置//初始化队列@SuppressWarnings("unchecked")public SeqQueue(Class type, int maxsize) {data = (E[]) Array.newInstance(type, maxsize);this.maxsize = maxsize;front = rear = -1;}//入队列操作public boolean enqueue(E item) {if (!isFull()) {rear = (rear + 1) % maxsize;data[rear] = item;return true;} elsereturn false;}//出队列操作public E dequeue() {if (!isEmpty()) {front = (front + 1) % maxsize;return data[front];} elsereturn null;}//取对头元素public E peek() {if (!isEmpty()) {return data[(front + 1) % maxsize];} elsereturn null;}//求队列的长度public int size() {return (rear - front + maxsize) % maxsize;}// 判断队列是否为空public boolean isEmpty() {if (front == rear) {return true;} else {return false;}}// 判断循环顺序队列是否为满public boolean isFull() {if ((front == -1 && rear == maxsize - 1)|| (rear + 1) % maxsize == front) {return true;} else {return false;}}
} 2.3 队列的链式存储结构
队列的链式存储结构,其实说白了就是单链表,同时这根单链表只能在头部删除节点,在尾部添加节点。在这里我们将front设置为队头,rear设置为队尾。
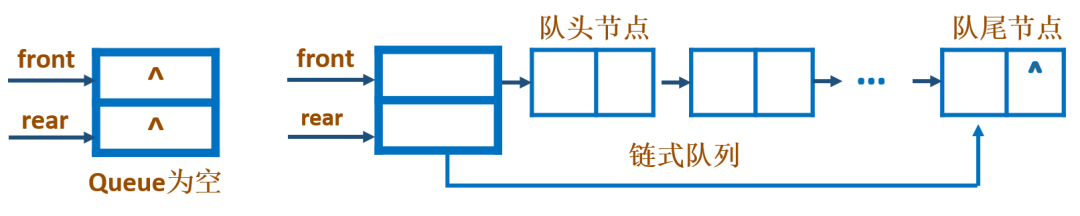
2.4 链式队列各类功能实现
public class LinkQueue {private class Node{private T data;private Node next;@SuppressWarnings("unused")public Node(){}public Node(T element, Node next){this.data = element;this.next = next;}}//代表链式队列的大小private int size;//链式队列的链队首private Node front;//链式队列的链队尾private Node rear;public LinkQueue(){size = 0;front = null;rear = null;}public LinkQueue(T element){rear = new Node(element, null);front = rear;size ++;}//返回链式队列的长度public int length(){return size;}//判断队列是否为空public boolean isEmpty(){return size == 0;}//向 rear 端队尾插入元素public void add(T element){if(isEmpty()){rear = new Node(element, null);front = rear;}else{rear.next = new Node(element, null);rear = rear.next;}size ++;}//从 front 端队首移除元素public T remove(){exceptionForRemove();Node oldNode = front;front = front.next;oldNode.next = null;size --;return oldNode.data;}//返回链式队列的堆首元素,但不删除public T element(){return front.data;}//清空链式队列public void clear(){front = null;rear = null;size = 0;}//toString 方法public String toString(){if(isEmpty()){return "[]";}else{StringBuffer sb = new StringBuffer("[");for(Node current = front; current != null; current = current.next){sb.append(current.data.toString() + ",");}return sb.toString().substring(0, sb.length() - 1) + "]";}}private void exceptionForRemove(){if(isEmpty()){throw new IndexOutOfBoundsException("链式队列为空异常");}}
} 3 牛刀小试
学习了上面的这些内容,接下来我们通过几道大厂真题,带你真正掌握这些知识。
3.1 深信服 2020 年春招 C++面试
问:C++内存分配,堆栈区别,堆栈存储哪个存储更大?
答:
C++内存分配
栈区(stack)— 由编译器自动分配释放,存放函数的参数值,局部变量的值等。其操作方式类似于数据结构中的栈。
堆区(heap) — 一般由程序员分配释放,若程序员不释放,程序结束时可能由 OS(操作系统)回收。注意它与数据结构中的堆是两回事,分配方式倒是类似于链表。
全局区(静态区)(static)—,全局变量和静态变量的存储是放在一块的,初始化的全局变量和静态变量在一块区域,未初始化的全局变量和未初始化的静态变量在相邻的另一块区域。程序结束后由系统释放。
文字常量区 —常量字符串就是放在这里的。程序结束后由系统释放。
程序代码区—存放函数体的二进制代码。
堆栈区
管理方式不同;
空间大小不同;
能否产生碎片不同;
生长方向不同;
分配方式不同;
分配效率不同;
堆栈空间大小
一般来讲在 32 位系统下,堆内存可以达到 4G 的空间,从这个角度来看堆内存几乎是没有什么限制的。但是对于栈来讲,一般都是有一定的空间大小的,例如,在 VC6 下面,默认的栈空间大小是 1M(好像是,记不清楚了)。当然,我们可以修改:打开工程,依次操作菜单如下:Project->Setting->Link,在 Category 中选中 Output,然后在 Reserve 中设定堆栈的最大值和 commit。注意:reserve 最小值为 4Byte;commit 是保留在虚拟内存的页文件里面,它设置的较大会使栈开辟较大的值,可能增加内存的开销和启动时间。
3.2 百度系统部 2019 年秋招面试
问:堆栈存储的数据分别是什么?
答:
栈(操作系统):由编译器自动分配释放 ,存放函数的参数值,局部变量的值等。其操作方式类似于数据结构中的栈,栈使用的是一级缓存, 他们通常都是被调用时处于存储空间中,调用完毕立即释放
堆(操作系统): 一般由程序员分配释放, 若程序员不释放,程序结束时可能由 OS 回收,分配方式倒是类似于链表。堆则是存放在二级缓存中,生命周期由虚拟机的垃圾回收算法来决定(并不是一旦成为孤儿对象就能被回收)。所以调用这些对象的速度要相对来得低一些。
3.3 今日头条测试开发 2018 年秋招面试
问:堆栈在线程进程中的区别?
答:因为进程拥有独立的堆栈空间和数据段,所以每当启动一个新的进程必须分配给它一个独立地址空间,建立众多的数据表来维护它的代码段、堆栈段和数据段。而线程拥有独立的堆栈空间,但是共享数据段。
今日内容有get吗,欢迎各位留言讨论!
下期预告:栈与队列的应用
以上专栏均来自CSDN GitChat专栏《数据结构算法面试全解析》,作者春晨溅雨·4位算法工程师,专栏详情可识别下方二维码查看哦!
了解更多详情
可识别下方二维码

本文来自互联网用户投稿,文章观点仅代表作者本人,不代表本站立场,不承担相关法律责任。如若转载,请注明出处。 如若内容造成侵权/违法违规/事实不符,请点击【内容举报】进行投诉反馈!