《神经网络与深度学习》第二部分 (三)
不懂的章节先放下了,之后再来看。
7. 网络优化与正则化
优化问题:损失函数是一个非凸函数(比如二维损失函数L(w1,w2)会有多个山峰 山谷)、梯度消失、参数过多
泛化问题:采用正则化降低过拟合
7.1非凸函数
凸函数是指一维函数只有一个波峰或波谷,二维函数只有一个山峰或山谷。而实际中,很多损失函数都是非凸函数。
一维函数 y=x+x**2-x**3有两个极值点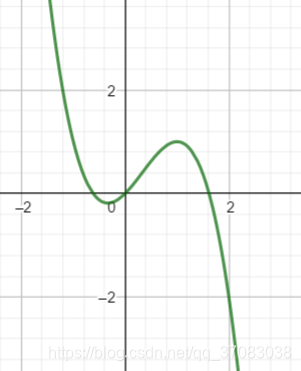
二维函数 z=x**2-y**2 (马鞍面)
马鞍点是该维度的极小值点,即y=0,z=x**2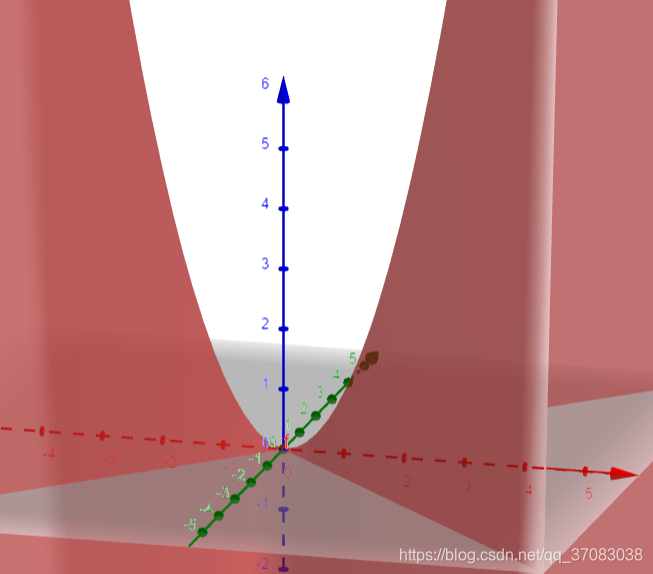
马鞍点是该维度的极大值点,即x=0,z=-y**2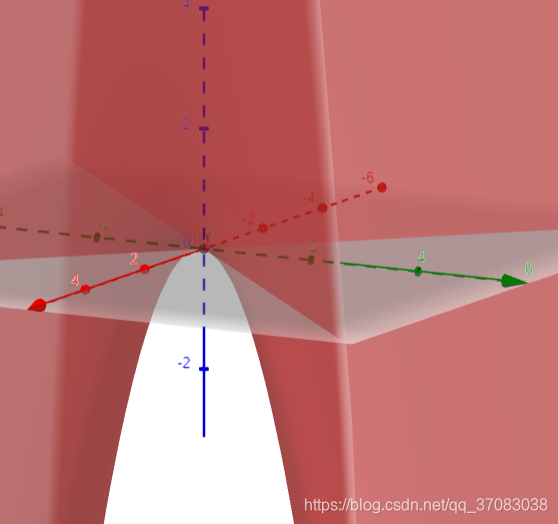
7.2优化算法
小批量梯度下降法
如:tf中选择batch大小,选择指数衰减学习率,选择合适的优化器。这就分别对应影响小批量梯度下降法的三个因素:批量大小、学习率、梯度估计。
7.3参数初始化
参数服从高斯分布或均匀分布
7.4 数据预处理
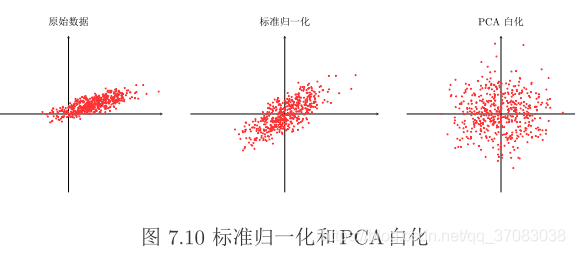
缩放归一化:每一个特征取值范围都在[0,1]或[-1,1]
标准归一化:计算输入特征的方差σ与均值μ,每一个特征x_new = (x_old - μ) / σ
注:输入层的特征,输出层的特征、以及隐藏层都需要缩放归一化与标准归一化。可选择对隐藏层单个神经元或所有神经元的净输入z进行归一化。
数据白化:可通过主成分分析方法PCA实现
7.5 超参数优化
7.6 网络正则化
正则项、权重衰减、提前停止训练、dropout舍弃法、数据增强(图片翻转、缩放、平移等等,来扩展训练集)、标签平滑
8. 注意力与外部记忆
对于过载的输入信息,人脑并不能同时处理。采用注意力与记忆机制的方法来解决不能同时处理过载信息的问题。
神经网络也可以借鉴这两个方法。
注意力机制:既然不能同时处理所有信息,就处理其中重要的信息。
举例:
显著性注意力:汇聚、门控
8.1 神经网络中的注意力机制
输入向量X = [x1,x2,...,xn]
查询向量q
注意力打分函数s(xi,q):计算X与q的相关性
注意力分布αi:在给定X与q的条件下,选择第xi的概率αi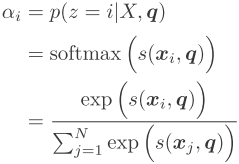
s(xi,q)的几种模型: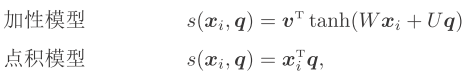
 W U v为可学习的参数
W U v为可学习的参数
对输入信息进行汇总
软性注意力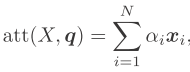
硬性注意力![]() xj为概率最大的输入向量,或者xj为随机的某个输入向量
xj为概率最大的输入向量,或者xj为随机的某个输入向量
键值对注意力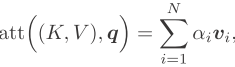
多头注意力![]()
![]()
下图为两种汇总模式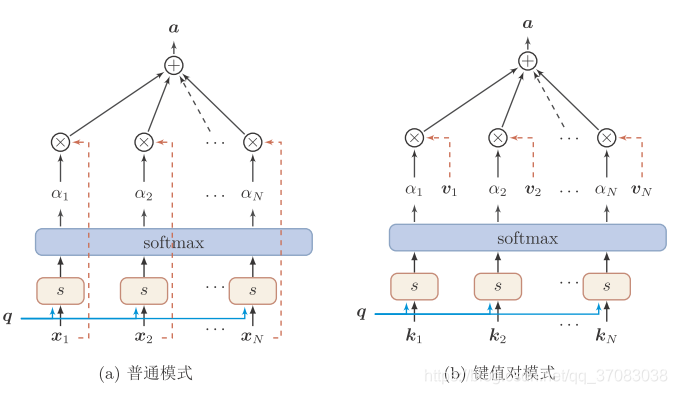
8.2 外部记忆
8.3 补充
生成模型:从数据中学习联合概率分布P(X,Y),将联合概率分布P(X,Y)转化为条件概率分布P(Y|X)作为预测的模型
判别模型:从数据中学习决策函数Y=f(X)或条件概率分布P(Y|X;θ)作为预测的模型
GAN包含生成器与判别器
生成器:从随机噪声中生成图像
判别器:输入为生成器生成的图像或训练集的图像,输出为0~1的连续值,接近1表示输入为训练集的图像,接近0表示输入为生成器的图像 x~训练集 而且 x~样本空间
判别器优化:尽可能判断准确![]()
生成器优化:尽可能使自己生成的图片让判别器以为是服从样本空间的图片![]()
GAN的训练:固定G训练D,固定D训练G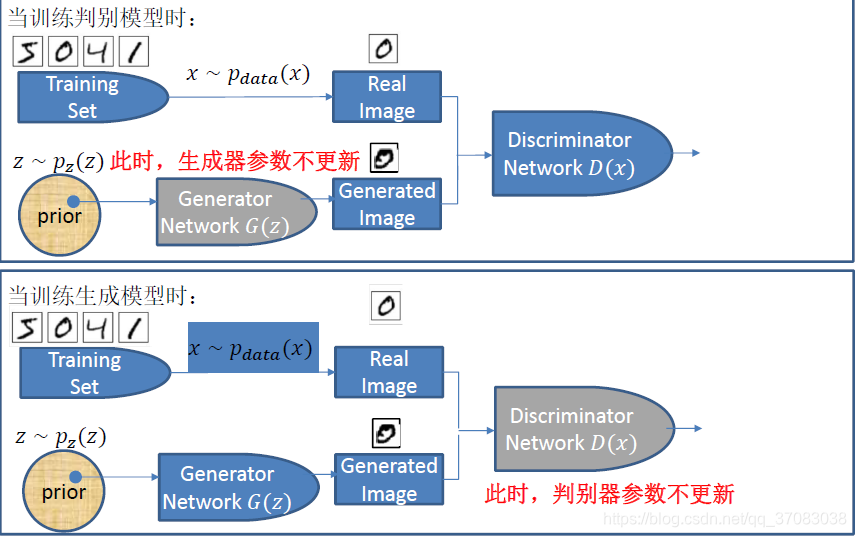
编码器-解码器或seq2seq模型:用到了两个RNN,分别叫encoder和decoder。encoder分析输入序列,decoder生成输出序列。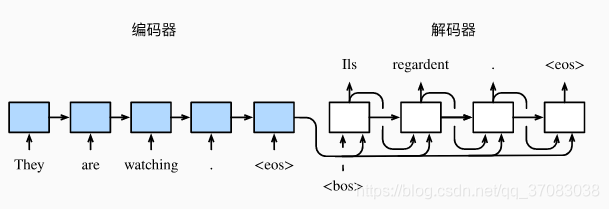
指针网络:与seq2seq只是注意力机制不同?
Hopfield网络:是一种RNN模型。有离散与连续两种,前者的神经元只有两种状态-1,1,后者神经元状态是连续值。
离散Hopfield网络
Hebbin法则
深度学习非常好的一本书,刚刚发现的。http://zh.d2l.ai/
论坛Gluon
9. 无监督学习
从无标注的数据中自动学习有效的数据表示,有PCA、稀疏编码、自动编码器
9.1 主成分分析PCA
一种特征降维方法,使得原始特征变换后产生的特征方差最大。但并不能保证新的特征进行分类时可分性更好。
原始样本矩阵X=[x1,x2,x3,...,xN] xi为第i个d维特征向量,X为dxN维矩阵
原始样本的协方差矩阵 ![]()
S的特征值按大小依次排列 λ1,λ2,λ3,...
S的特征值λ1对应的特征向量为v1,λ2对应的特征向量v2,...
最优变换矩阵W为dxd'维,W=[v1,v2,...,vd']
X_new = trans(W)*X 新的特征矩阵X_new为d'xN矩阵
9.2 稀疏编码器
与PCA相比,原始特征转化为一个稀疏的特征
9.3 自编码器
自(动)编码器:属于无监督学习,对一组数据学习出一种表示(也叫表征,编码),常用于降维。
自编码器有两部分:encoder与decoder
encoder ![]()
![]() ,decoder
,decoder
下面的两层全连接神经网络就可看作一个自编码器
encoder:输入层—隐藏层 4维特征转换为2维特征
decoder:隐藏层—输出层 2维特征转换为4维特征
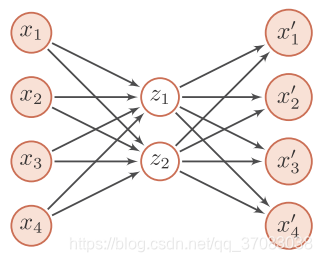
在训练完成后,一般会去掉解码器,只保留编码器
稀疏自编码器、堆叠自编码器、降噪自编码器
9.4 概率密度估计
参数密度估计、非参数密度估计
10. 模型独立的学习方式
本文来自互联网用户投稿,文章观点仅代表作者本人,不代表本站立场,不承担相关法律责任。如若转载,请注明出处。 如若内容造成侵权/违法违规/事实不符,请点击【内容举报】进行投诉反馈!