【2020人工智能培训课】笔记四 深度学习 基础讲解
深度学习为端到端的学习方式
一般而言,机器学习中特征越多,给出信息就越多,识别准确性会得到提升;
但特征多,计算复杂度增加,探索的空间就大,训练数据在全体特征向量中就会显得稀疏,影响相似性判断;
更重要的是,如果有对分类无益的特征,反而可能干扰学习效果。
结论:特征不一定越多越好,获得好的特征是识别成功的关键。需要有多少个特征,需要学习问题本身来决定。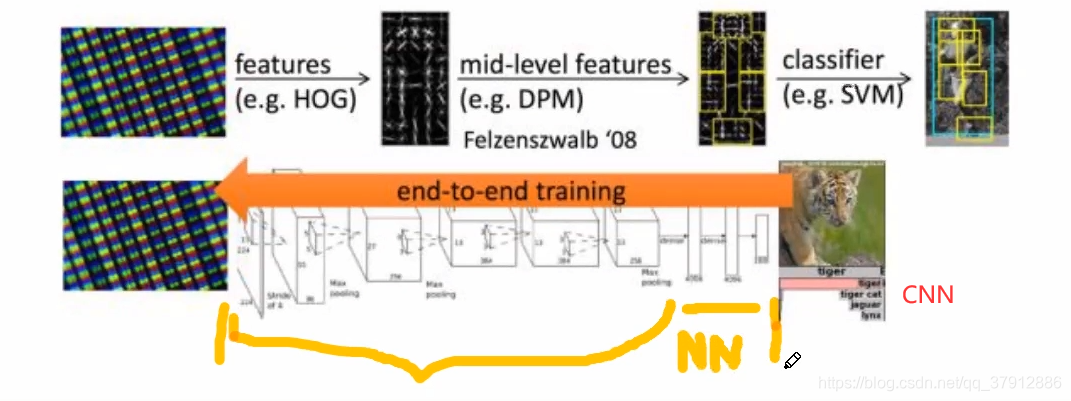
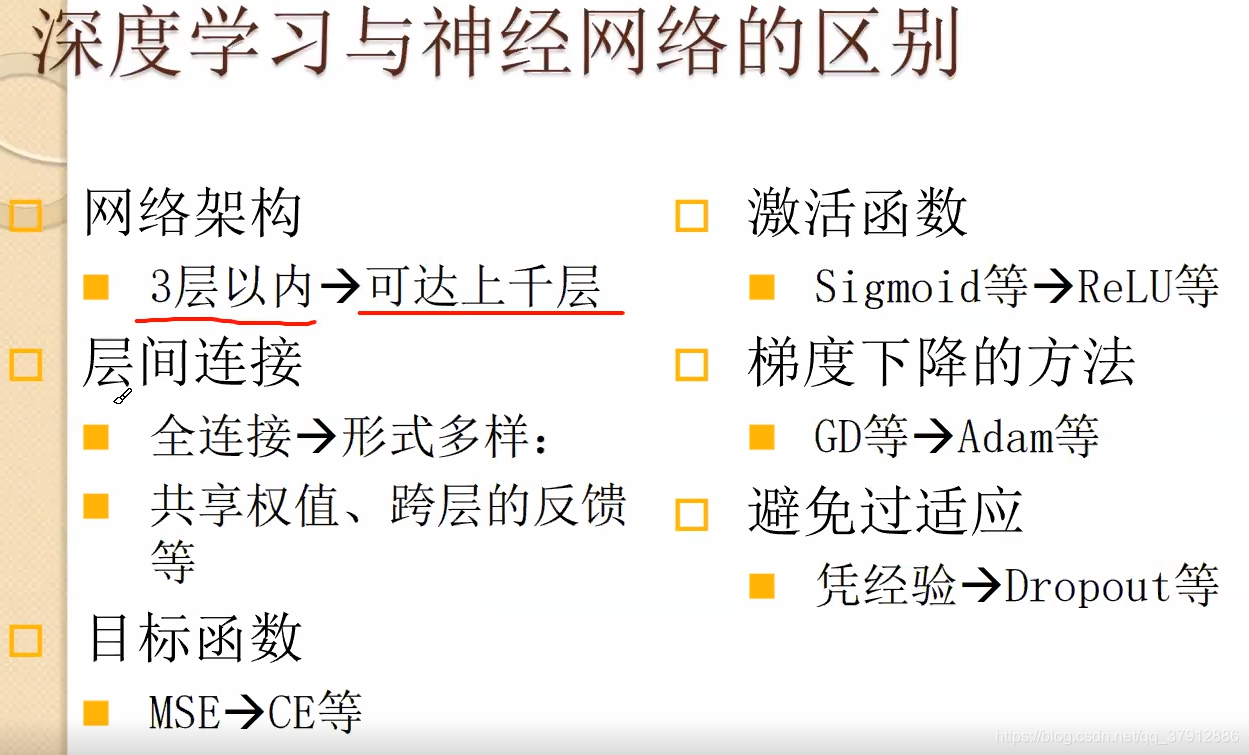
卷积层进行特征提取。卷积核的权重也是由误差反向传播获得的。
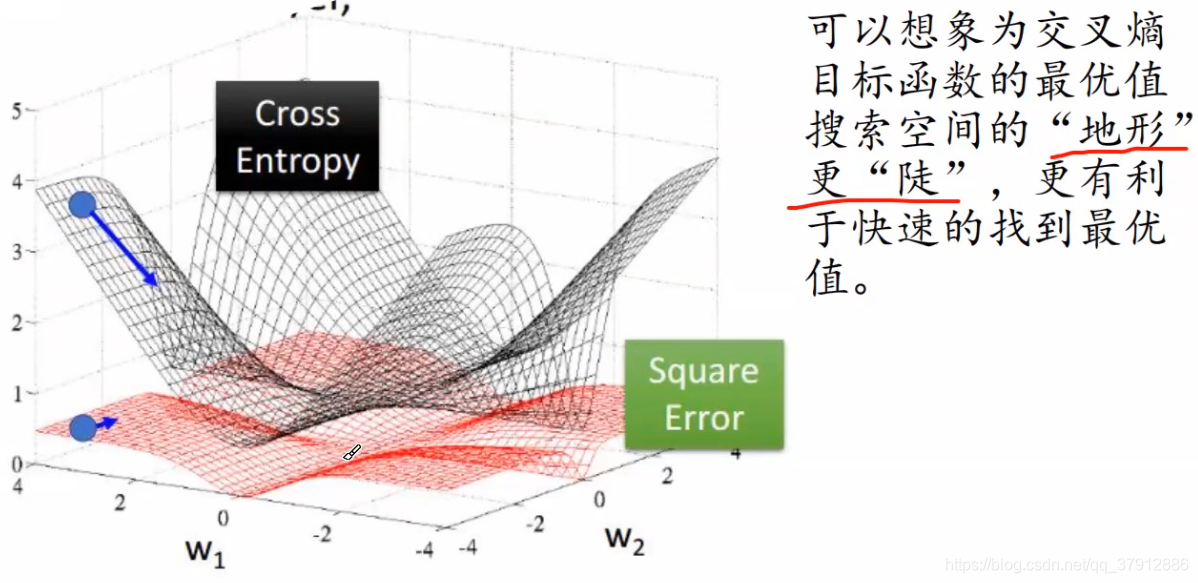
把目标函数转换为交叉熵的办法,在一定程度上避免计算困难。

Softwax层的作用是突出“最大值”并转换成概率的形式。一般,先通过softmax层,然后计算CE。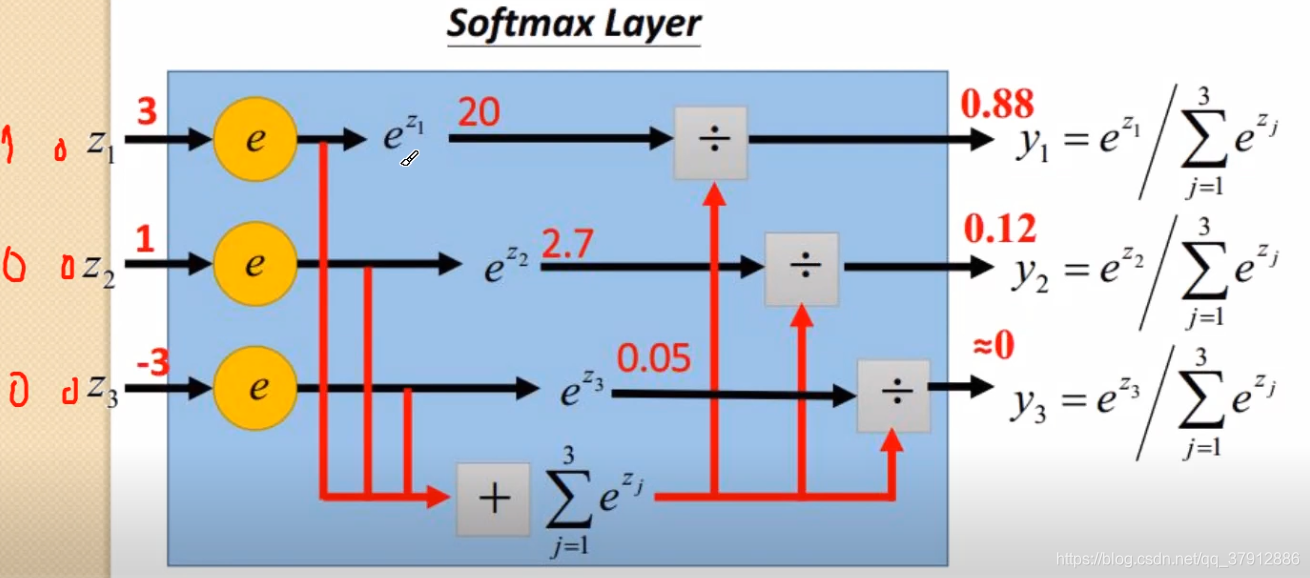
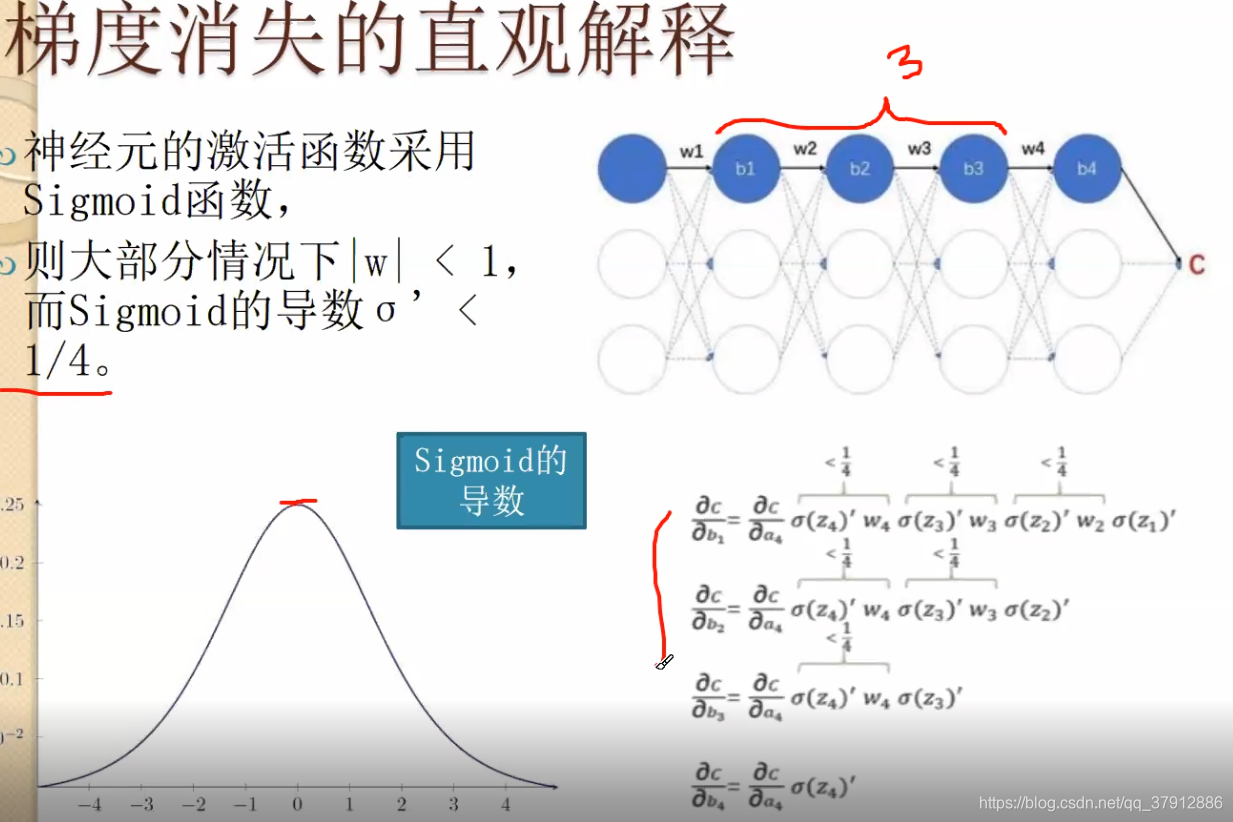
现在使用relu,能解决梯度消失问题。因为大于0部分,梯度为1. 多阶连乘保证梯度爆炸或者梯度消失

学习步长:学习步长的设置是个难题:若学习步长过大,则目标函数可能不降低(学习发散);但若学习步长过小,则训练过程可能非常缓慢。
解决之道:训练几轮后就按一些因素调整学习步长。一般结构简单的网络模型可以使用较大的学习步长,复杂的网络学习步长较小。10-4甚至10-6的
可以动态调整步长,例如![]() t:训练轮次。上式分母为t+1, 是为了防止分母为0
t:训练轮次。上式分母为t+1, 是为了防止分母为0
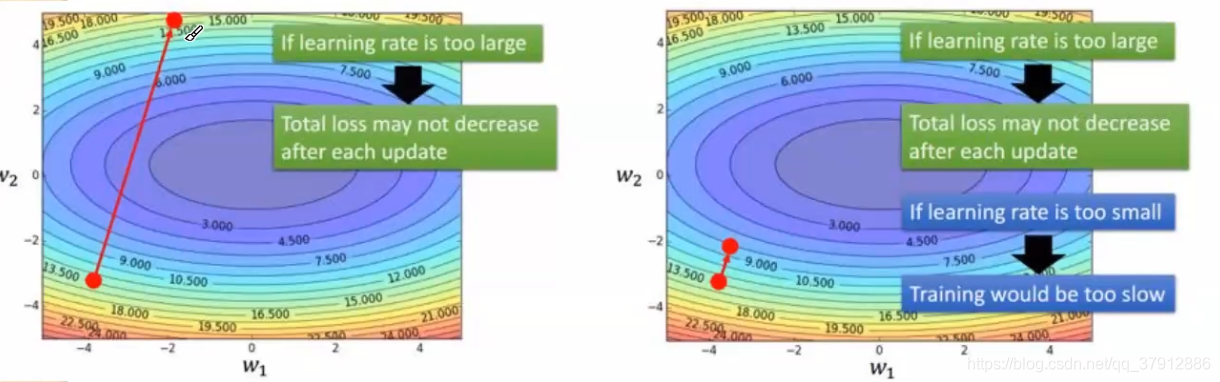
随机梯度下降(SGD)的问题:
learning rate不易确定、如果选择的太小收敛速度会很慢;如果太大,loss function就会在极小值处不停地震荡甚至偏离。
每个参数的learning rate都是相同的,如果数据是稀疏的,则希望对出现频率低的特征进行大一点的更新。
深层神经网络之所以比较难训练,并不是因为容易进入局部最小,而是因为学习过程容易陷入到马鞍面中,在这种区域中,所有方向的梯度值都几乎是0。
Momentu:一阶矩,解决惯性问题
为了避免容易陷入马鞍面或者较差的局部最优解,加入Momentu(动量、冲量)的机制。给一定惯性,
Momentum借用了物理中的动量概念,即前几次的梯度也会参与运算。为了表示动量,引入了一个新的变量V。V是之前的梯度的累加,但每回合都有一定的衰减。前后梯度方向一致时,能够加速学习;前后梯度方向不一致时,能够抑制震荡。
m是每个mini batch的样本数量。θ是权重,L是损失函数。v是动量。当前拍动量的继承了上一次的动量(乘以权重α),再与梯度加和。然后θ根据动量进行调整。
Nesterov Momentum
对Momentum的一种改进:先对参数进行估计,然后使用估计后的参数来计算误差。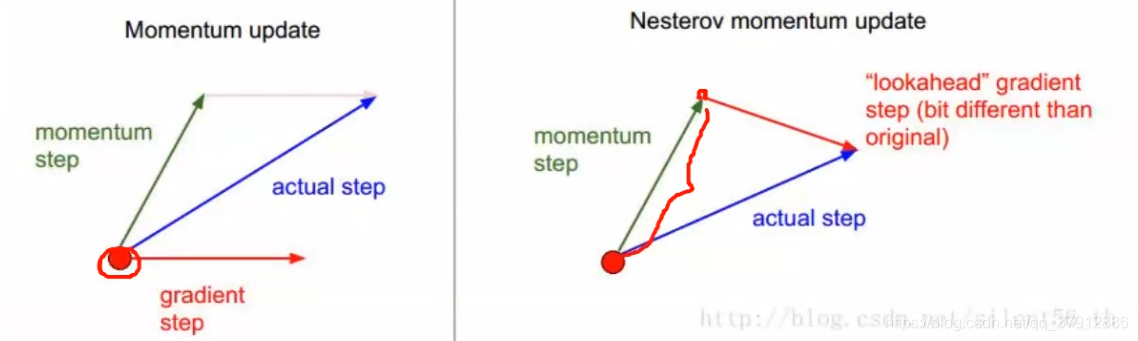
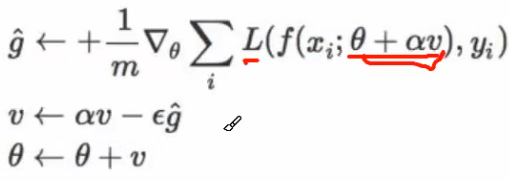
f是实际网络估计出的值,即。此公式为一阶矩?
Adagrad: 二阶矩,解决学习步长自适应问题
应该为不同的参数设置不同的学习步长。应该为不同的参数设置不同的学习步长。应该为不同的参数设置不同的学习步长。想象一下:在缓坡上,可以大步地往下跑;而且陡坡上,只能小步地往下挪。
ε为原先的固定步长,δ为是为了防止分母为0的极小量。 是梯度。
为调整后的学习步长。注意:学习步长的总原则,学习随着轮次增加,步长越来越小。前式r的累加使得分母越来越大。但是这个累加的存在导致步长只能越来越小学习速度放慢,过早结束。这也是Adagrad存在的问题。
RMSprop:改进的Adagrad
过引人一个衰减系数,让r每回合都衰减一定比例。这种方法很好的解决了Adagrad过早结束的问题,适合处理非平稳目标,对于RNN效果很好。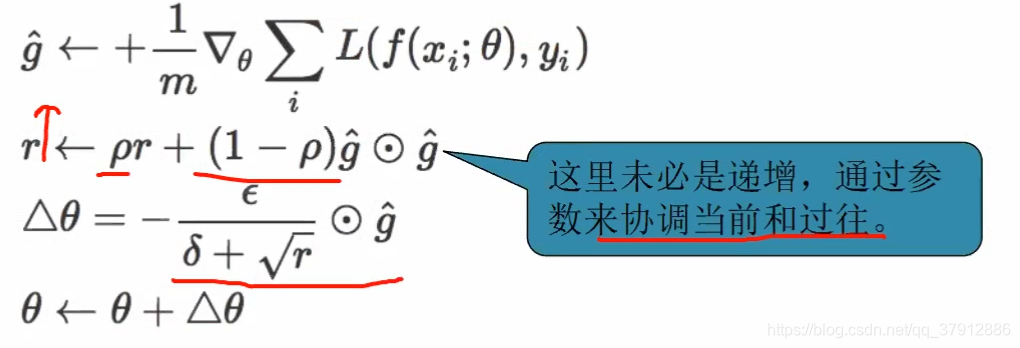
Adam :综合以上的方法
Adam这个名字来源于adaptive momentestimation,自适应矩估计。Adam本质上是带有动量项的RMSprop
它利用梯度的一阶矩估计和二阶矩估计动态调整每个参数的学习率。ρ1,ρ2的参数分别为0.9和0.999
N-adam:Nesterov+Adam 效果更好。
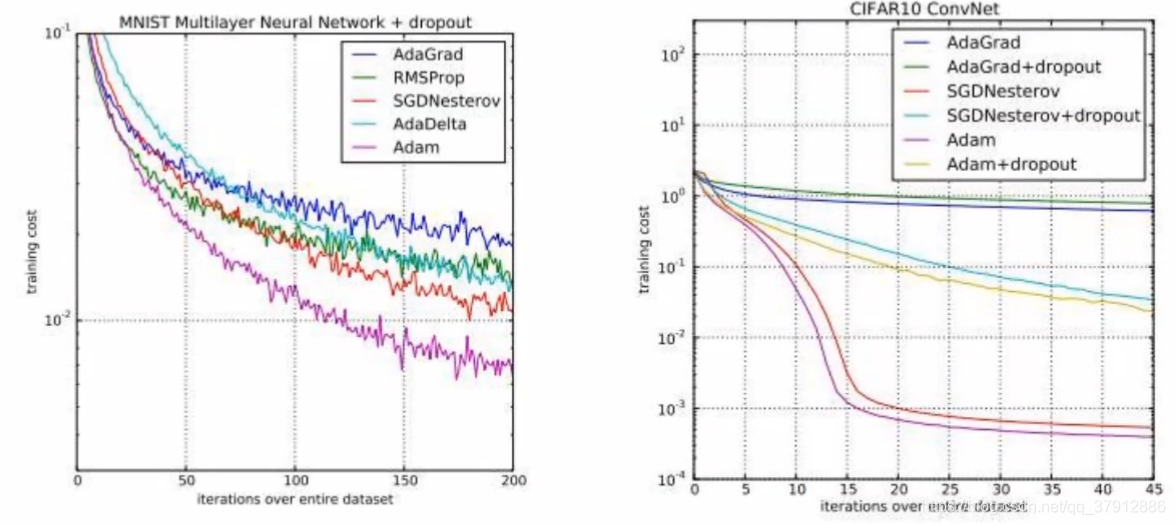
各种梯度下降算法的比较
左: 在 MNIST上训练多层神经网络
右: 在CIFAR10上训练卷积神经网络
下图为损失函数随着随着训练轮次的减小情况。泛化误差的大小一般与选用的梯度下降的方法无关,与网络的过拟合情况相关较大。
Batch Normalization
训练和测试都需要做。但是做法不一样
在每次SGD( 随机梯度下降)时,通过mini-batch来对相应的activation做规范化操作,使得结果(输出信号个维度)的均值为0,方差为1。剪掉均值,除以方差。不只是输入,而且层与层之间也可能会有Normalization。 最后的“scaleand shift”操作则是为了让因训练所需而“刻意”加入的BN能够有可能还原最初的输入。

避免过适应
只要在训练集图片中稍加一些噪声,学习机就不能做出正确的判断。过适应的根本原因:权重参数太多,而样本量不足。如何避免过适应?
1、早期停止训练(early stop) 2、权重衰减(weight decay) 3、Dropout
早期停止训练
当目标函数在“验证集”上不再减小时,训练就应该停止了。
不能一味追求“训练集”的误差减小。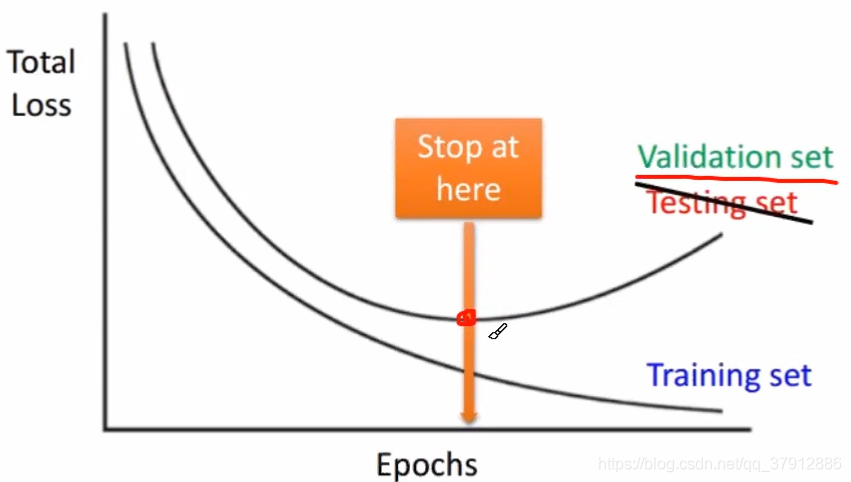
权重衰减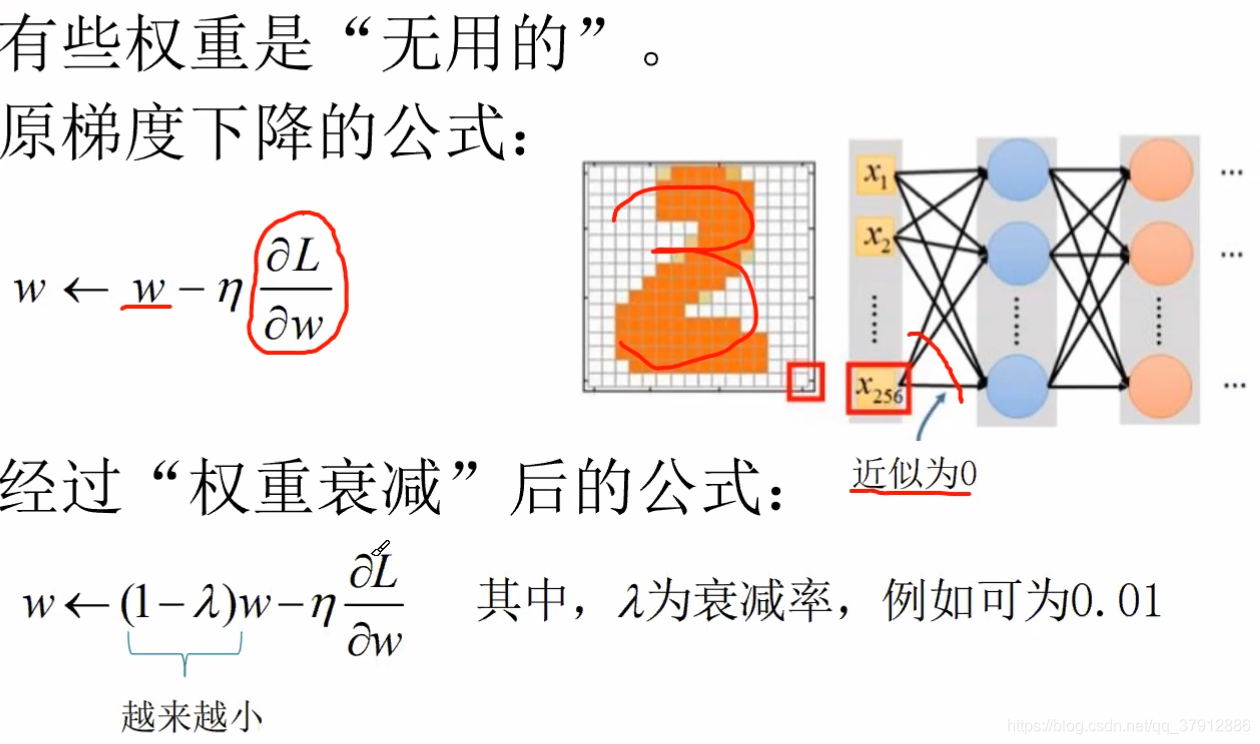
Dropout
每次新输入一个mini-batch时候,按一定的比例删减部分神经元(一般保留下来的神经元的个数为0.7-0.5),然后进行训练。
删减后整个参与训练的网络变得“更瘦",但是在训练完成测试的时候,是整个网络参与测试的。
本质上,Dropout就是用一小块数据来训练一系列“子网络”;Dropout是“集成学习”的一种。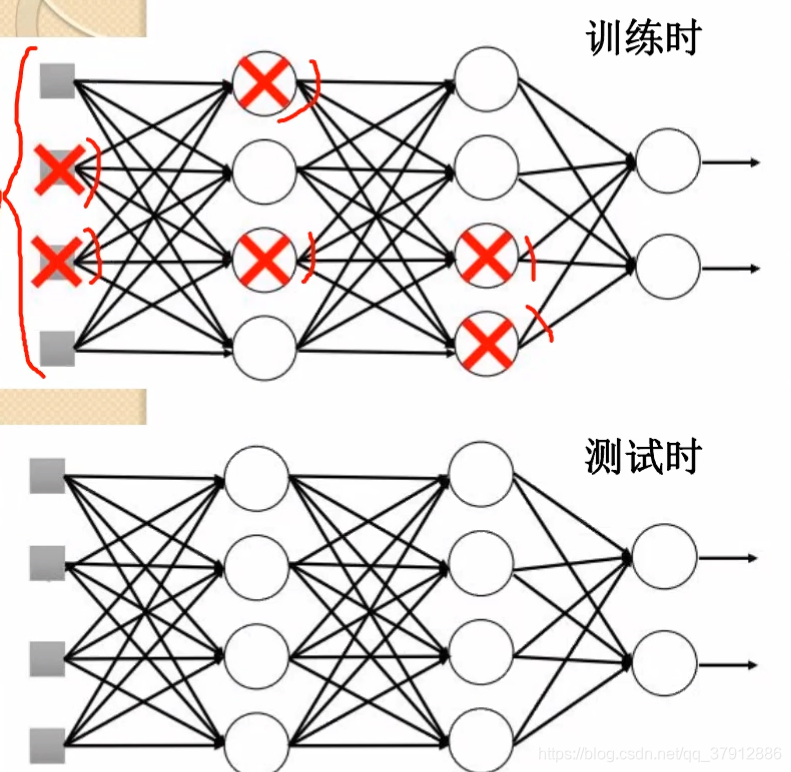
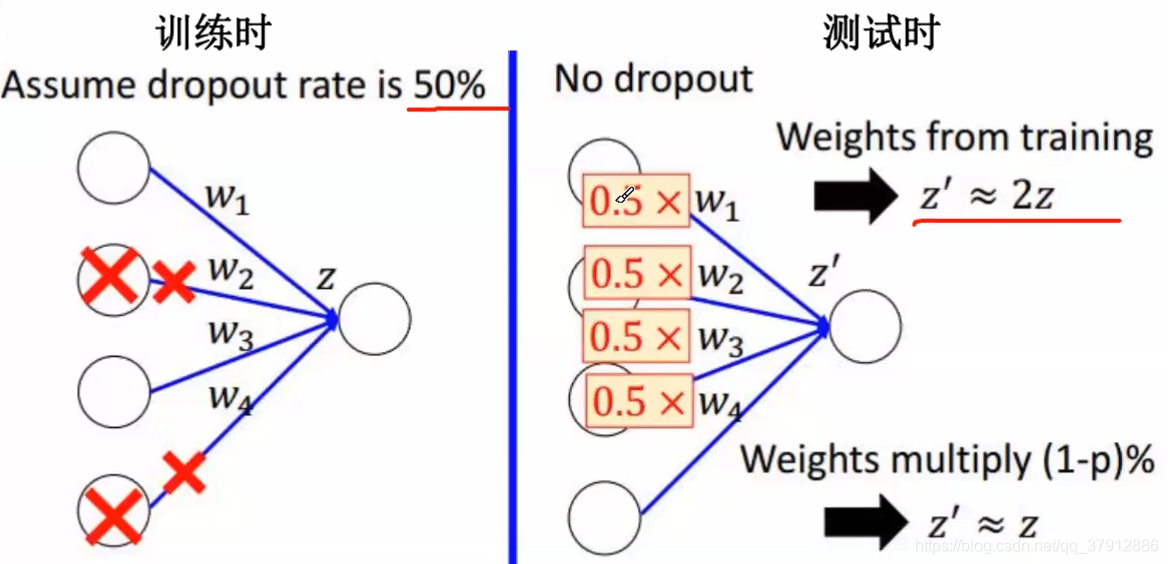
测试时权重应减小:测试时,使用所有的神经元,且权重应根据删减比例缩小。
本文来自互联网用户投稿,文章观点仅代表作者本人,不代表本站立场,不承担相关法律责任。如若转载,请注明出处。 如若内容造成侵权/违法违规/事实不符,请点击【内容举报】进行投诉反馈!