对比学习总结
对比学习
1:理论
对比学习的目的是希望我们输入的目标样例尽可能的靠近正样例以及远离负样例,在对比学习里,正负样例的选择非常重要
2:正负样例的选择
- 在多语言翻译里,一般我们把样例和目标翻译语言作为正样例,其他语言非对应目标语言翻译样本作为负样例,将对比损失和翻译损失相加作为最终损失
- 在分类里,我们一般把同类别的样例作为正样例,不同类别的样本作为负样例
- 可以将样本语句通过反向翻译得到的翻译语句作为目标样例的正样本,其他训练语料的语句作为负样本
3:序列到序列模型的对比损失计算
一般来说,对比学习都是在编码端进行,通过编码端计算出样本的表征,进行对比损失计算。在序列到序列模型里,对比的正负样例是在解码端进行,编码端输入是目标样例,正样例是根据正确答案的模型输出,负样例是非正确答案的模型输出,一般我们使用beam search构造负样例。具体理论参照论文Grammatical Error Correction with Contrastive Learning in Low Error Density Domains
4:对比损失计算
一般损失计算(编码端)
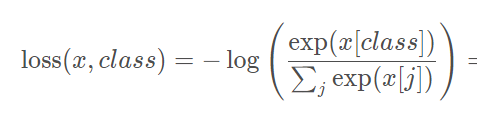
序列到序列模型对比损失计算
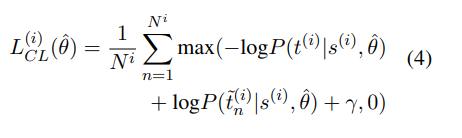
本文来自互联网用户投稿,文章观点仅代表作者本人,不代表本站立场,不承担相关法律责任。如若转载,请注明出处。 如若内容造成侵权/违法违规/事实不符,请点击【内容举报】进行投诉反馈!