多对多多语言神经机器翻译的对比学习
©原创作者 | 朱林
论文解读:
Contrastive Learning for Many-to-many Multilingual Neural Machine Translation
论文作者:
Xiao Pan, Mingxuan Wang, Liwei Wu, Lei Li
论文地址:
https://aclanthology.org/2021.acl-long.21.pdf
收录会议:
ACL2021
01 介绍
目前机器翻译的研究热点仍然集中在英语与其他语言翻译的方向上,而非英语方向的研究成果仍然寥寥无几。
如何有效利用不同语言的特征去构建模型,提高多种语言,尤其是非英语之间的翻译水平是个越发重要的课题。
传统思路中,为了解决两种语言机器翻译问题,人们往往分别学习这两种语言的特征再匹配,而忽略了两种语言在特征表达上的较大差异,导致模型效果较差。
本篇ACL会议论文提出了一种统一多语言翻译模型mRASP2来改进翻译性能,利用多语言对比学习能综合表达的优点改进了机器翻译性能,尤其提高了非英语方向的翻译质量。
该模型由两种技术支撑:
(1)对比学习,用于缩小不同语言表示之间的差距;
(2)对多个平行语料和单语语料进行数据增强,以进一步对齐标记表示。
实验表明,以英语为中心的方向,mRASP2模型的性能优于现有的最佳统一模型,并且在WMT数据集的数十个翻译方向上的性能超过了当前性能顶尖的mBART模型。
在非英语方向,与Transformer基线模型相比,mRASP2也实现了平均10 BLEU(性能指标)以上的性能改进。
02 方法
mRASP2需要输入一对平行句子(或增强伪平行句子),并使用多语言编解码器计算交叉熵损失。此外,它计算正样本和随机生成的负样本的对比损失,总体框架如图1所示:
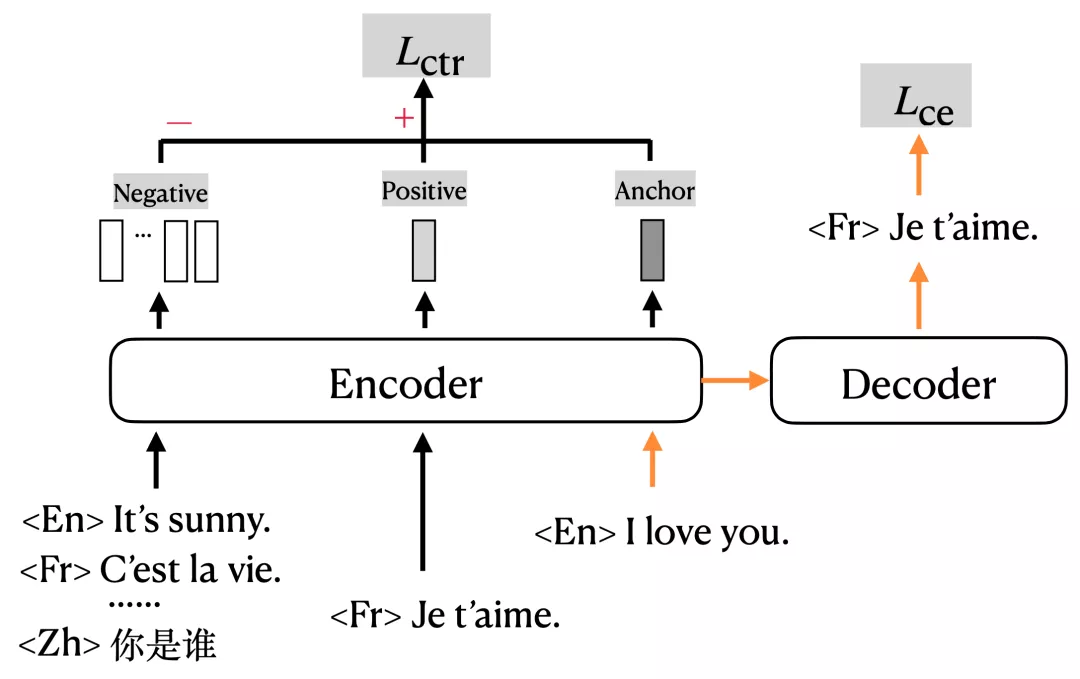
图1 mRASP2模型

图2 通过替换同义词词典中具有相同含义的单词,对平行数据和单语数据进行对齐增强。生成包括伪平行示例(左)和伪自平行示例(右)。
多语言转换器
模型采用了多语言神经机
本文来自互联网用户投稿,文章观点仅代表作者本人,不代表本站立场,不承担相关法律责任。如若转载,请注明出处。 如若内容造成侵权/违法违规/事实不符,请点击【内容举报】进行投诉反馈!