通过Python实现一个简单的爬虫——获取掘金网站文章列表
先来看下实现的结果
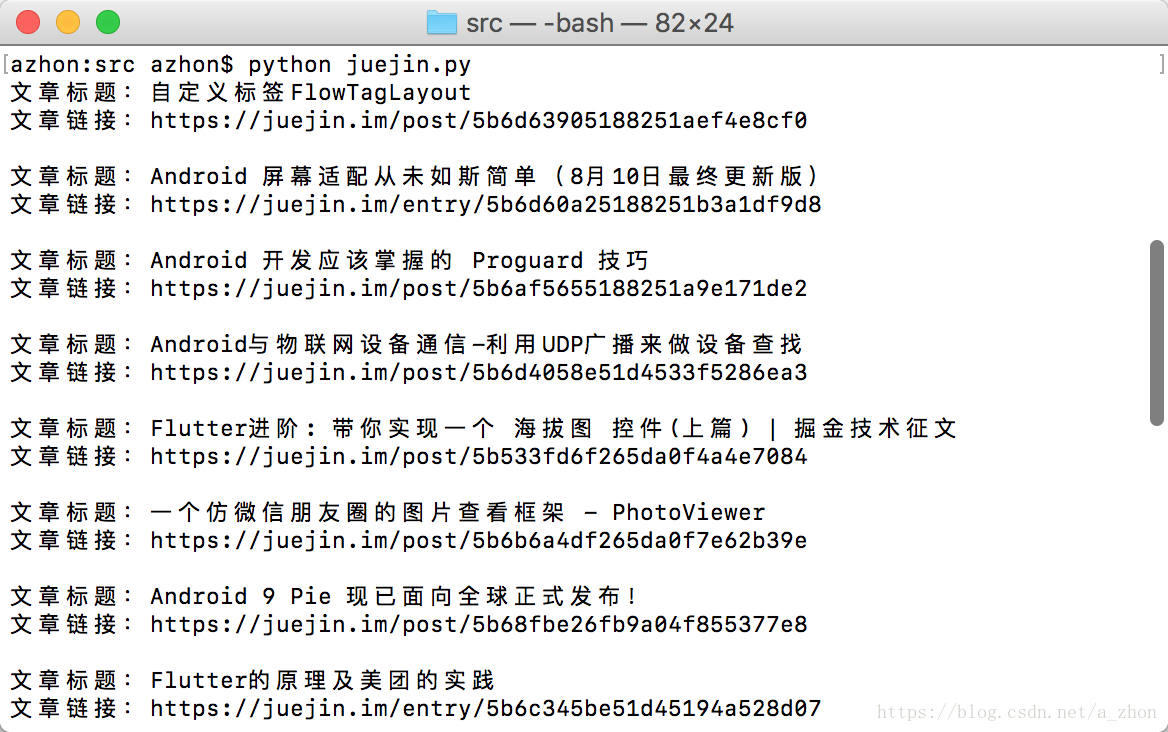
掘金文章爬虫源码
这里通过python命令直接运行我们的爬虫程序,很轻松的就获取到了网站首页的第一页文章(爬取的Android分类下文章),当然代码量也是只有几十行。
一: 首先我们要获取到我们要爬取的地址,然后通过分析网站返回的网页或者json数据来获取我们需要的数据;如下图:
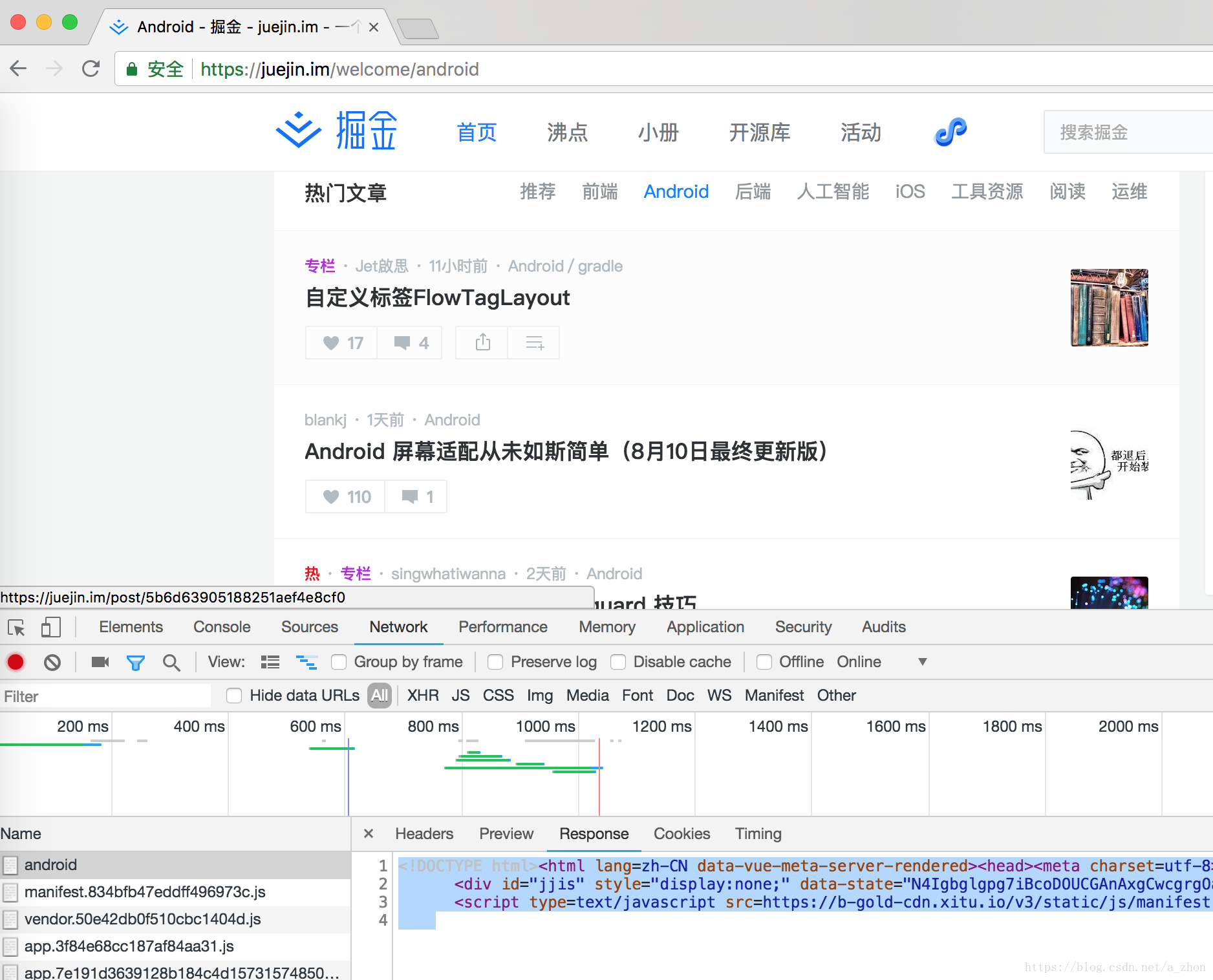
二:接下来就需要对html解析来,这里使用到了BeautifulSoup这个html解析库 ,体的使用方法就可以看文档了。
BeautifulSoup文档地址
安装这个依赖库
$ pip install beautifulsoup4- 首先我们需要发起一个请求获取到html内容,这里就直接使用原生的
urllib了
# 引入网络请求库
from urllib import request# 首页地址
jjUrl = "https://juejin.im/welcome/android"# 添加UA标识讲这个爬虫程序伪装成浏览器访问
user_agent = "User-Agent"
user_agent_value = "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/68.0.3440.84 Safari/537.36"# 发起网络请求,获取到返回的html
resp = request.Request(jjUrl)
# 模拟浏览器
resp.add_header(user_agent, user_agent_value)
resp = request.urlopen(resp)
# 网页返回的数据
htmlCode = resp.read().decode("utf-8")
print(htmlCode)可以看到和我们在浏览器中看到的数据是一样的
现在就需要通过使用
BeautifulSoup来解析这些html代码了,当然使用也是很简单的

# 导入库并取别名为bs
from bs4 import BeautifulSoup as bs# 格式化html(htmlCode就是上面我们请求到的数据)
soup = bs(htmlCode, "html.parser")
# 输出格式化好的html内容
print(soup.prettify())结果就不贴了就是将返回的数据进行格式化了。
- 分析html代码提取我们需要的内容,如下图

文章的标题和跳转的详情链接都是在这个a标签里面,现在来解析这些数据并保存起来:
# 文章对象
class jjArticle(object):def __init__(self, title, url):self.title = titleself.url = urldef to_string(self):return "文章标题:" + self.title + "\n" + "文章链接:" + self.url# 获取a标签内class属性为title的元素 即为文章的标题
articleList = soup.find_all("a", {"class", "title"})
# 获取到的所有文章标题
allArticle = []
for article in articleList:url = article.get("href")# 创建一个保存文章的对象article = jjArticle(article.string, "https://juejin.im" + url)allArticle.append(article)
源码下载地址
到这里这个简单的爬虫就说完了代码也非常的简单
本文来自互联网用户投稿,文章观点仅代表作者本人,不代表本站立场,不承担相关法律责任。如若转载,请注明出处。 如若内容造成侵权/违法违规/事实不符,请点击【内容举报】进行投诉反馈!