
一 python操作数据库
# coding: utf-8
二 pandas清洗数据
df
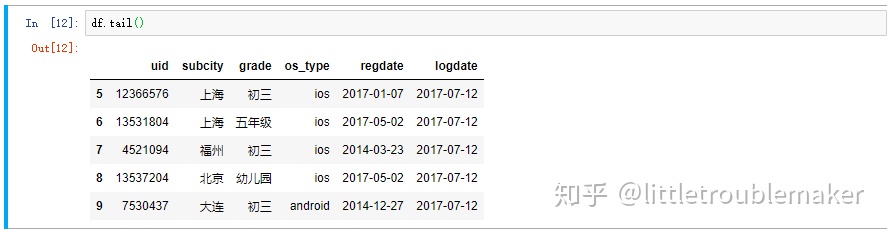 获取查询数据末尾5行
获取查询数据末尾5行 - pd.value_counts(Series)统计Series中不同元素出现的次数
data
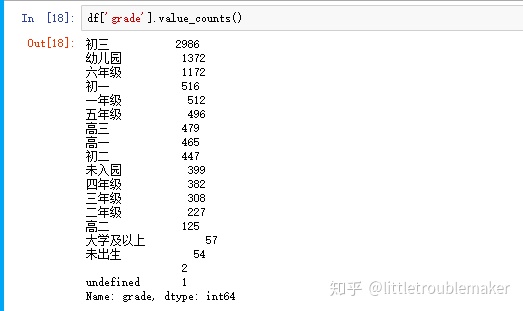 各个年级出现的次数
各个年级出现的次数 - reset_index将serives转化为dataframe
data=data.reset_index()
series.duplicated(keep='first')
判断series是否有重复值,标记第一次出现以后的数据为重复
series.duplicated(keep='last')
标记最后一个出现之前的数据为重复 重复=False 否则=True
i) df.duplicated()#判断所有列
ii) df.duplicated('col1')#判断col1
iii) df.duplicated(['col1','col2'])#判断col1,col2
df
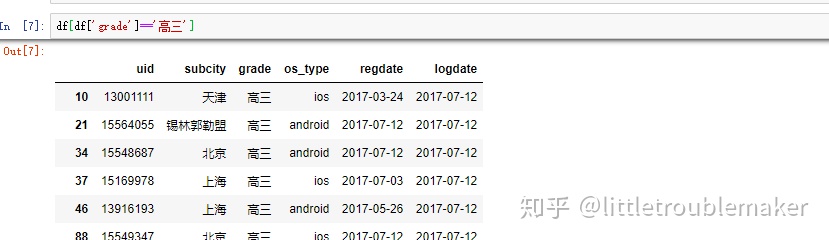 单条件取值
单条件取值  多条件取值
多条件取值 pd.merge(df,data,left_on='grade',right_on='index',how='left')
# 次操作类似于excel中的vlookup函数,又能将他和数据库中left join联系起来,
# 此时你有没有想到数据库还有inner join,right join等连接方式,bingo,改变how后面的left参数就ok了
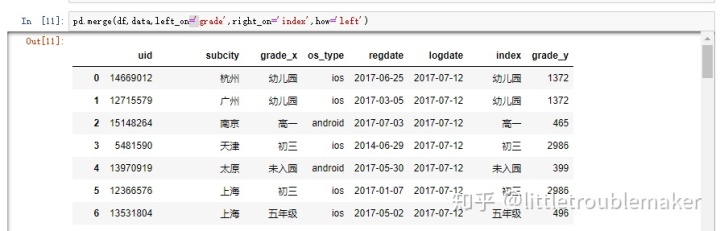 将原数据df与data进行匹配
将原数据df与data进行匹配 今年的笔记都到这里了,希望对困扰的你有帮助哦,同时同步给大家一个"吉德林法则",把难题清清楚楚地写出来,问题便已经解决了一半。希望大家在遇到难题时将自己的想法、思维从点连城线,用纸简单的写下来,或者用思维导图画出来,抑或讲给人挺,那问题就已经决绝了一半了
本文来自互联网用户投稿,文章观点仅代表作者本人,不代表本站立场,不承担相关法律责任。如若转载,请注明出处。 如若内容造成侵权/违法违规/事实不符,请点击【内容举报】进行投诉反馈!
