Spark SQL中的函数操作实例+Scala代码演示
目录
- 一、环境准备
- 二、Spark 读取MySQL数据的五种方式
- 三、Spark 读取 json 数据
- 四、Spark-sql 中常见函数
- (1)去重函数:distinct / dropDuplicates
- (2)过滤函数:filter / except / intersect
- (3)Map函数:map / flatMap / mapPartition
- (4)重分区函数:coalesce 和 repartition
- (5)join:根据某一个字段,关联合并两个数据集
- (6)sort:对数据表排序
- (7)切分函数:randomSplit / sample
- (8)分组函数:groupBy
- (9)current_date / current_timestamp / rand / round / concat 函数
- (10)agg操作函数:avg / sum / max / min / count
- (11)行列转换函数:collect_list / collect_set
- (12)withColumn
- (13)select / selectExpr
- (14)collectAsList : DataFrame 转 List 集合
- (15) head / first
- (16)schema
- (17)union
- (18)describe
- (19)col / apply
本文涉及到的代码在文末会给出代码仓库地址
Spark SQL 里面有很多的函数操作,比如 DataSet 类里就有去重、重分区、过滤、交差集、Map函数、排序、随机、列操作等很多的函数,工欲善其事必先利其器,这些函数操作需要熟练掌握才能提高开发效率和质量。
Spark 的数据源可以是多种的,正常生产环境下应该都是以hive表为主,数据量比较大(几亿~几十亿),一个数据任务可能要跑一天甚至更久,企业的大数据任务环境往往还有层层的审批,导致流程繁琐,而且搭建Hadoop环境也很繁琐。由于我们的目的是快速验证Spark SQL 相关的函数操作,采用Mysql或者json为数据源,可以支持我们快速验证相关函数,省去Hadoop等集群环境的搭建,当然有时间和精力的情况下也可以去搭建一下windows下的大数据开发环境或者本地安装虚拟机去搭建。
一、环境准备
- MySQL ,本地安装并初始化一下表数据,以供后续验证使用:
CREATE TABLE `student` (`Sno` int(11) NOT NULL COMMENT '学号',`Sname` varchar(20) NOT NULL COMMENT '姓名',`Ssex` varchar(20) NOT NULL COMMENT '性别',`Sbirthday` datetime DEFAULT NULL COMMENT '生日',`ClassCode` varchar(100) DEFAULT NULL COMMENT '班级'
) ENGINE=InnoDB DEFAULT CHARSET=utf8 ROW_FORMAT=DYNAMIC COMMENT='学生表';
CREATE TABLE `score` (`Sno` varchar(20) NOT NULL COMMENT '学号',`Cno` varchar(20) NOT NULL COMMENT '课程编号',`Degree` decimal(4,1) NOT NULL COMMENT '成绩'
) ENGINE=InnoDB DEFAULT CHARSET=utf8 ROW_FORMAT=DYNAMIC COMMENT='成绩表';
INSERT INTO imok.student
(Sno, Sname, Ssex, Sbirthday, ClassCode)
VALUES(101, ‘李军’, ‘男’, ‘1976-02-20 00:00:00’, ‘95033’);
INSERT INTO imok.student
(Sno, Sname, Ssex, Sbirthday, ClassCode)
VALUES(103, ‘陆君’, ‘男’, ‘1974-06-03 00:00:00’, ‘95031’);
INSERT INTO imok.student
(Sno, Sname, Ssex, Sbirthday, ClassCode)
VALUES(105, ‘匡明’, ‘男’, ‘1975-10-02 00:00:00’, ‘95031’);
INSERT INTO imok.student
(Sno, Sname, Ssex, Sbirthday, ClassCode)
VALUES(107, ‘王丽’, ‘女’, ‘1976-01-23 00:00:00’, ‘95033’);
INSERT INTO imok.student
(Sno, Sname, Ssex, Sbirthday, ClassCode)
VALUES(108, ‘曾华’, ‘男’, ‘1977-09-01 00:00:00’, ‘95033’);
INSERT INTO imok.student
(Sno, Sname, Ssex, Sbirthday, ClassCode)
VALUES(109, ‘王芳’, ‘男’, ‘1975-02-10 00:00:00’, ‘95031’);
INSERT INTO imok.student
(Sno, Sname, Ssex, Sbirthday, ClassCode)
VALUES(110, ‘王鹏’, ‘男’, ‘2022-07-06 18:20:50’, ‘’);
INSERT INTO imok.student
(Sno, Sname, Ssex, Sbirthday, ClassCode)
VALUES(101, ‘李军’, ‘男’, ‘1976-02-20 00:00:00’, ‘95033’);
INSERT INTO imok.student
(Sno, Sname, Ssex, Sbirthday, ClassCode)
VALUES(102, ‘李军’, ‘男’, ‘1976-02-20 00:00:00’, ‘95033’);
INSERT INTO imok.student01
(Sno, Sname, Ssex, Sbirthday, ClassCode)
VALUES(2101, ‘李军’, ‘男’, ‘1976-02-20 00:00:00’, ‘95033’);
INSERT INTO imok.student01
(Sno, Sname, Ssex, Sbirthday, ClassCode)
VALUES(2103, ‘陆君’, ‘男’, ‘1974-06-03 00:00:00’, ‘95031’);
INSERT INTO imok.student01
(Sno, Sname, Ssex, Sbirthday, ClassCode)
VALUES(2105, ‘匡明’, ‘男’, ‘1975-10-02 00:00:00’, ‘95031’);
INSERT INTO imok.student01
(Sno, Sname, Ssex, Sbirthday, ClassCode)
VALUES(2107, ‘王丽’, ‘女’, ‘1976-01-23 00:00:00’, ‘95033’);
INSERT INTO imok.student01
(Sno, Sname, Ssex, Sbirthday, ClassCode)
VALUES(2108, ‘曾华’, ‘男’, ‘1977-09-01 00:00:00’, ‘95033’);
INSERT INTO imok.student01
(Sno, Sname, Ssex, Sbirthday, ClassCode)
VALUES(2109, ‘王芳’, ‘男’, ‘1975-02-10 00:00:00’, ‘95031’);
INSERT INTO imok.student01
(Sno, Sname, Ssex, Sbirthday, ClassCode)
VALUES(2110, ‘王鹏’, ‘男’, ‘2022-07-06 18:20:50’, ‘95031’);
INSERT INTO imok.student01
(Sno, Sname, Ssex, Sbirthday, ClassCode)
VALUES(101, ‘李军’, ‘男’, ‘1976-02-20 00:00:00’, ‘95033’);
INSERT INTO imok.student01
(Sno, Sname, Ssex, Sbirthday, ClassCode)
VALUES(102, ‘李军’, ‘男’, ‘1976-02-20 00:00:00’, ‘95033’);
INSERT INTO imok.score
(Sno, Cno, Degree)
VALUES(‘103’, ‘3-245’, 86.0);
INSERT INTO imok.score
(Sno, Cno, Degree)
VALUES(‘105’, ‘3-245’, 75.0);
INSERT INTO imok.score
(Sno, Cno, Degree)
VALUES(‘109’, ‘3-245’, 68.0);
INSERT INTO imok.score
(Sno, Cno, Degree)
VALUES(‘101’, ‘3-105’, 64.0);
INSERT INTO imok.score
(Sno, Cno, Degree)
VALUES(‘107’, ‘3-105’, 91.0);
INSERT INTO imok.score
(Sno, Cno, Degree)
VALUES(‘108’, ‘3-105’, 78.0);
————————————————————————————
——————————————————————————————
- Json ,为了展示多数据源,本地初始化一些Json文件,以供后续验证使用:
anhui-city.json
[{"code": "3401","name": "hefei","num" : [1,6,9,0],"children": [{"code": "340102","name": "yaohai"},{"code": "340103","name": "luyang"},{"code": "340104","name": "shushan"},{"code": "340111","name": "baohe"},{"code": "340121","name": "changfeng"},{"code": "340122","name": "feidong"},{"code": "340123","name": "feixi"},{"code": "340124","name": "lujiang"},{"code": "340171","name": "gaoxin"},{"code": "340172","name": "jingkai"},{"code": "340173","name": "xinzhan"},{"code": "340181","name": "chaohu"}]},{"code": "3402","name": "wuhu","num" : [12,6,9,10],"children": [{"code": "340202","name": "jinghu"},{"code": "340208","name": "sanshan"},{"code": "340221","name": "wuhuxian"},{"code": "340222","name": "fanchang"},{"code": "340223","name": "anlin"},{"code": "340225","name": "wuwei"},{"code": "340271","name": "wuhujingkai"}]},{"code": "3403","name": "bengbu","num" : [2,6,0],"children": [{"code": "340302","name": "longzihu"},{"code": "340303","name": "bengshan"},{"code": "340304","name": "yuhui"},{"code": "340311","name": "huaishang"},{"code": "340321","name": "huaiyuan"},{"code": "340322","name": "wuhe"},{"code": "340323","name": "guzhen"},{"code": "340371","name": "bengbujingkai"}]},{"code": "3404","name": "huainan","num" : [12,6,9,0],"children": [{"code": "340402","name": "datong"},{"code": "340403","name": "tinajiaan"},{"code": "340404","name": "xiejiaji"},{"code": "340405","name": "bagongshan"},{"code": "340406","name": "panji"},{"code": "340421","name": "fengtai"},{"code": "340422","name": "shouxian"}]},{"code": "3405","name": "maanshan","num" : [12,6,9,0],"children": [{"code": "340503","name": "huashan"},{"code": "340504","name": "yushan"},{"code": "340506","name": "bowang"},{"code": "340521","name": "dangtu"},{"code": "340522","name": "hanshan"},{"code": "340523","name": "hexian"}]},{"code": "3406","name": "huaibei","num" : [12,16,39,0],"children": [{"code": "340602","name": "duji"},{"code": "340603","name": "xiangshan"},{"code": "340604","name": "lieshan"}]},{"code": "3407","name": "tonglin","num" : [12,46,59,0],"children": [{"code": "340705","name": "tongguan"},{"code": "340706","name": "yian"},{"code": "340711","name": "jiaoqu"},{"code": "340722","name": "zongyang"}]},{"code": "3408","name": "anqing","num" : [12,6,9,0],"children": [{"code": "340802","name": "yingjiang"},{"code": "340803","name": "daguan"},{"code": "340811","name": "yixiu"},{"code": "340822","name": "huaining"},{"code": "340825","name": "taihu"},{"code": "340826","name": "susong"},{"code": "340827","name": "wangjiang"},{"code": "340828","name": "yuexi"},{"code": "340871","name": "anqingjingkai"},{"code": "340881","name": "tongcheng"},{"code": "340882","name": "qianshan"}]},{"code": "3410","name": "huangshan","num" : [112,6,9,0],"children": [{"code": "341002","name": "tunxi"},{"code": "341004","name": "huizhou"},{"code": "341022","name": "xiuning"},{"code": "341024","name": "qimen"}]},{"code": "3411","name": "chuzhou","num" : [12,66,9,0],"children": [{"code": "341102","name": "langya"},{"code": "341103","name": "nanqiao"},{"code": "341122","name": "laian"},{"code": "341124","name": "quanjiao"},{"code": "341125","name": "dingyuan"},{"code": "341126","name": "fengyang"},{"code": "341172","name": "chuzhoujingkai"}]},{"code": "3415","name": "luan","num" : [12,6,9,60],"children": [{"code": "341502","name": "jinan"},{"code": "341503","name": "yuan"},{"code": "341504","name": "yeji"},{"code": "341522","name": "huoqiu"},{"code": "341523","name": "shucheng"},{"code": "341524","name": "jinzai"},{"code": "341525","name": "huoshan"}]}
]
================================================================================================
person.json
{"name":"zhang", "age":3}
{"name":"li", "age":30}
{"name":"song", "age":19}
{"name":"song", "age":19}
{"name":"song", "age":32}
================================================================================================
person1.json
{"name":"zhang", "age":32}
================================================================================================
subject.json
{"id":"subject-1", "subjectName":"English"}
{"id":"subject-2", "subjectName":"Math"}
================================================================================================
teacher.json
{"name":"Zhang", "workYear":3}
{"name":"Li", "workYear":4}
{"name":"Liu", "workYear":5}
{"name":"Song", "workYear":4}
================================================================================================
teacher1.json
{"subjectId":"subject-1", "name":"zhang", "workYear":3}
{"subjectId":"subject-2", "name":"li", "workYear":4.5}
{"subjectId":"subject-2", "name":"song", "workYear":3.5}
{"subjectId":"subject-1", "name":"wang", "workYear":4}
- 项目里引入的依赖情况
<project xmlns="http://maven.apache.org/POM/4.0.0"xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd"><modelVersion>4.0.0modelVersion><groupId>org.examplegroupId><artifactId>spark-scala-demoartifactId><version>1.0-SNAPSHOTversion><properties><scala.version>2.12.16scala.version><hadoop.spark.version>2.4.5hadoop.spark.version><hadoop.spark.scala.version>2.12hadoop.spark.scala.version>properties><repositories><repository><id>scala-tools.orgid><name>Scala-Tools Maven2 Repositoryname><url>http://scala-tools.org/repo-releasesurl>repository>repositories><pluginRepositories><pluginRepository><id>scala-tools.orgid><name>Scala-Tools Maven2 Repositoryname><url>http://scala-tools.org/repo-releasesurl>pluginRepository>pluginRepositories><dependencies><dependency><groupId>org.scala-langgroupId><artifactId>scala-libraryartifactId><version>${scala.version}version>dependency><dependency><groupId>junitgroupId><artifactId>junitartifactId><version>4.4version><scope>testscope>dependency><dependency><groupId>org.specsgroupId><artifactId>specsartifactId><version>1.2.5version><scope>testscope>dependency><dependency><groupId>org.scala-toolsgroupId><artifactId>maven-scala-pluginartifactId><version>2.12version>dependency><dependency><groupId>org.apache.maven.pluginsgroupId><artifactId>maven-eclipse-pluginartifactId><version>2.5.1version>dependency><dependency><groupId>org.apache.sparkgroupId><artifactId>spark-core_${hadoop.spark.scala.version}artifactId><version>${hadoop.spark.version}version><exclusions><exclusion><artifactId>scala-libraryartifactId><groupId>org.scala-langgroupId>exclusion>exclusions>dependency><dependency><groupId>org.apache.sparkgroupId><artifactId>spark-sql_${hadoop.spark.scala.version}artifactId><version>${hadoop.spark.version}version>dependency><dependency><groupId>org.apache.sparkgroupId><artifactId>spark-streaming_${hadoop.spark.scala.version}artifactId><version>${hadoop.spark.version}version>dependency><dependency><groupId>commons-collectionsgroupId><artifactId>commons-collectionsartifactId><version>3.2.2version>dependency><dependency><groupId>mysqlgroupId><artifactId>mysql-connector-javaartifactId><version>5.1.46version>dependency><dependency><groupId>org.projectlombokgroupId><artifactId>lombokartifactId><version>1.16.10version>dependency>dependencies><build><sourceDirectory>src/main/scalasourceDirectory><testSourceDirectory>src/test/scalatestSourceDirectory><plugins><plugin><groupId>org.scala-toolsgroupId><artifactId>maven-scala-pluginartifactId><executions><execution><goals><goal>compilegoal><goal>testCompilegoal>goals>execution>executions><configuration><scalaVersion>${scala.version}scalaVersion><args><arg>-target:jvm-1.5arg>args>configuration>plugin><plugin><groupId>org.apache.maven.pluginsgroupId><artifactId>maven-eclipse-pluginartifactId><configuration><downloadSources>truedownloadSources><buildcommands><buildcommand>ch.epfl.lamp.sdt.core.scalabuilderbuildcommand>buildcommands><additionalProjectnatures><projectnature>ch.epfl.lamp.sdt.core.scalanatureprojectnature>additionalProjectnatures><classpathContainers><classpathContainer>org.eclipse.jdt.launching.JRE_CONTAINERclasspathContainer><classpathContainer>ch.epfl.lamp.sdt.launching.SCALA_CONTAINERclasspathContainer>classpathContainers>configuration>plugin>plugins>build><reporting><plugins><plugin><groupId>org.scala-toolsgroupId><artifactId>maven-scala-pluginartifactId><configuration><scalaVersion>${scala.version}scalaVersion>configuration>plugin>plugins>reporting>
project>
二、Spark 读取MySQL数据的五种方式
基于以上的数据准备,我们可以去实际验证相关的API了。首先看下spark读取MySQL数据的五种方式。
import java.util.Properties/*** Spark之读取MySQL数据的五种方式*/
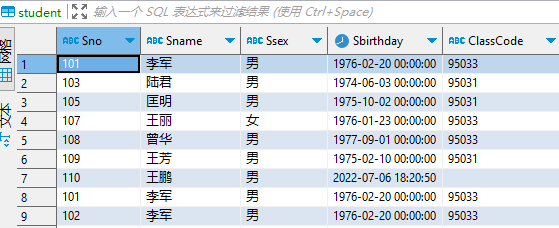
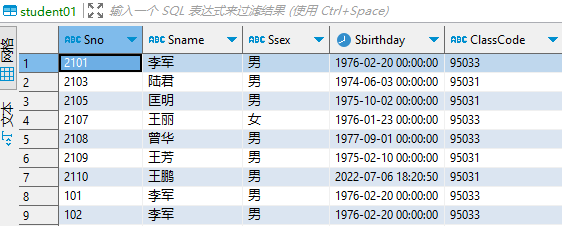
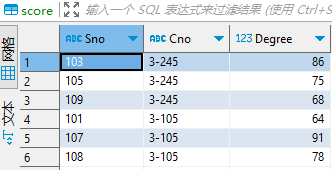
object SparkMysql5Methods {val urldb = "jdbc:mysql://localhost:3306/imok?user=root&password=123456&useSSL=false"def main(args: Array[String]): Unit = {val spark = SparkSession.builder().appName("SparkMysql5MethodsTest").master("local[2]").getOrCreate()method1(spark)method2(spark)method3(spark)method4(spark)method5(spark)spark.stop()}/*** 方式一:不指定查询条件* 所有的数据由RDD的一个分区处理,如果你这个表很大,很可能会出现OOM** @param spark*/def method1(spark: SparkSession): Unit = {val url = urldbval prop = new Properties()val df = spark.read.jdbc(url, "student", prop)println(df.count()) // 9println(df.rdd.partitions.size) // 1df.createOrReplaceTempView("student")import spark.sqlsql("select * from student").show()/** * +---+-----+----+-------------------+---------+* |Sno|Sname|Ssex| Sbirthday|ClassCode|* +---+-----+----+-------------------+---------+* |101| 李军| 男|1976-02-20 00:00:00| 95033|* |103| 陆君| 男|1974-06-03 00:00:00| 95031|* |105| 匡明| 男|1975-10-02 00:00:00| 95031|* |107| 王丽| 女|1976-01-23 00:00:00| 95033|* |108| 曾华| 男|1977-09-01 00:00:00| 95033|* |109| 王芳| 男|1975-02-10 00:00:00| 95031|* |110| 王鹏| 男|2022-07-06 18:20:50| |* |101| 李军| 男|1976-02-20 00:00:00| 95033|* |102| 李军| 男|1976-02-20 00:00:00| 95033|* +---+-----+----+-------------------+---------+ */}/*** 方式二:指定数据库字段的范围* 通过lowerBound和upperBound 指定分区的范围* 通过columnName 指定分区的列(只支持整形)* 通过numPartitions 指定分区数量 (不宜过大)** @param spark*/def method2(spark: SparkSession): Unit = {val lowerBound = 1val upperBound = 100000val numPartitions = 5val url = urldbval prop = new Properties()val df = spark.read.jdbc(url, "student", "Sno", lowerBound, upperBound, numPartitions, prop)println(df.count()) // 9println(df.rdd.partitions.size) // 5df.show()/** * +---+-----+----+-------------------+---------+* |Sno|Sname|Ssex| Sbirthday|ClassCode|* +---+-----+----+-------------------+---------+* |101| 李军| 男|1976-02-20 00:00:00| 95033|* |103| 陆君| 男|1974-06-03 00:00:00| 95031|* |105| 匡明| 男|1975-10-02 00:00:00| 95031|* |107| 王丽| 女|1976-01-23 00:00:00| 95033|* |108| 曾华| 男|1977-09-01 00:00:00| 95033|* |109| 王芳| 男|1975-02-10 00:00:00| 95031|* |110| 王鹏| 男|2022-07-06 18:20:50| |* |101| 李军| 男|1976-02-20 00:00:00| 95033|* |102| 李军| 男|1976-02-20 00:00:00| 95033|* +---+-----+----+-------------------+---------+*/}/*** 方式三:根据任意字段进行分区* 通过predicates将数据根据score分为2个区** @param spark*/def method3(spark: SparkSession): Unit = {val predicates = Array[String]("Degree <= 75", "Degree > 75 and Degree <= 100")val url = urldbval prop = new Properties()val df = spark.read.jdbc(url, "score", predicates, prop)println(df.count()) // 6println(df.rdd.partitions.size) // 2df.rdd.partitions.foreach(println) // JDBCPartition(Degree <= 75,0) JDBCPartition(Degree > 75 and Degree <= 100, 1)import spark.sqldf.createOrReplaceTempView("score")sql("select * from score").show()/** * +---+-----+------+* |Sno| Cno|Degree|* +---+-----+------+* |105|3-245| 75.0|* |109|3-245| 68.0|* |101|3-105| 64.0|* |103|3-245| 86.0|* |107|3-105| 91.0|* |108|3-105| 78.0|* +---+-----+------+*/}/*** 方式四:通过load获取,和方式二类似* @param spark*/def method4(spark: SparkSession): Unit = {val url = urldbval df = spark.read.format("jdbc").options(Map("url" -> url, "dbtable" -> "student")).load()println(df.count()) // 9println(df.rdd.partitions.size) // 1import spark.sqldf.createOrReplaceTempView("student")sql("select * from student").show()/** +---+-----+----+-------------------+---------+* |Sno|Sname|Ssex| Sbirthday|ClassCode|* +---+-----+----+-------------------+---------+* |101| 李军| 男|1976-02-20 00:00:00| 95033|* |103| 陆君| 男|1974-06-03 00:00:00| 95031|* |105| 匡明| 男|1975-10-02 00:00:00| 95031|* |107| 王丽| 女|1976-01-23 00:00:00| 95033|* |108| 曾华| 男|1977-09-01 00:00:00| 95033|* |109| 王芳| 男|1975-02-10 00:00:00| 95031|* |110| 王鹏| 男|2022-07-06 18:20:50| |* |101| 李军| 男|1976-02-20 00:00:00| 95033|* |102| 李军| 男|1976-02-20 00:00:00| 95033|* +---+-----+----+-------------------+---------+ */}/*** 方式五:加载条件查询后的数据* @param spark*/def method5(spark: SparkSession): Unit = {val url = urldbval df = spark.read.format("jdbc").options(Map("url" -> url, "dbtable" -> "(SELECT * FROM score where Degree > 75 ) t_score")).load()println(df.count()) // 3println(df.rdd.partitions.size) // 1import spark.sqldf.createOrReplaceTempView("t_score")sql("select * from t_score").show()Thread.sleep(60 * 1000)/** +---+-----+------+* |Sno| Cno|Degree|* +---+-----+------+* |103|3-245| 86.0|* |107|3-105| 91.0|* |108|3-105| 78.0|* +---+-----+------+*/}
}
实际上以上的spark.read.jdbc()多种重载方法,上面是传入的table,还有一种重载方法可以传入sql:
object SparkMysql1 {val database= "jdbc:mysql://localhost:3306/imok"val database_props = new Properties()database_props.setProperty("user", "root")database_props.setProperty("password", "123456")database_props.setProperty("driver", "com.mysql.jdbc.Driver")database_props.setProperty("useSSL", "false")def main(args: Array[String]): Unit = {val spark = SparkSession.builder().appName("Spark SQL basic example").config("spark.some.config.option", "some-value").master("local[*]").getOrCreate()val sqlStudent =s"""|(| select| *| from student|) a""".stripMarginval sqlStudentDF = spark.read.jdbc(database, sqlStudent, database_props)sqlStudentDF.show()/** +---+-----+----+-------------------+---------+* |Sno|Sname|Ssex| Sbirthday|ClassCode|* +---+-----+----+-------------------+---------+* |101| 李军| 男|1976-02-20 00:00:00| 95033|* |103| 陆君| 男|1974-06-03 00:00:00| 95031|* |105| 匡明| 男|1975-10-02 00:00:00| 95031|* |107| 王丽| 女|1976-01-23 00:00:00| 95033|* |108| 曾华| 男|1977-09-01 00:00:00| 95033|* |109| 王芳| 男|1975-02-10 00:00:00| 95031|* |110| 王鹏| 男|2022-07-06 18:20:50| |* |101| 李军| 男|1976-02-20 00:00:00| 95033|* |102| 李军| 男|1976-02-20 00:00:00| 95033|* +---+-----+----+-------------------+---------+ */
}
注意:
以上链接MySql时要加上useSSL=false 或者 setProperty("useSSL", "false"),否则运行时可能会报一下错误:
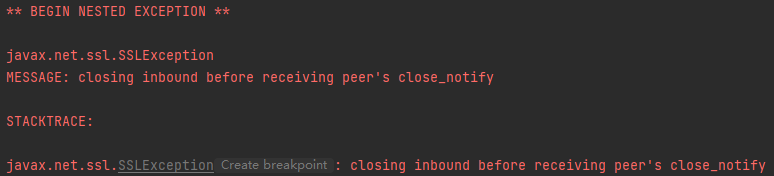
三、Spark 读取 json 数据
val path = "src/main/java/spark/json/anhui-city.json"val jsonDF = spark.read.json(spark.sparkContext.wholeTextFiles(path).values)jsonDF.createOrReplaceTempView("cityCode")val cityDF = spark.sql("select * from cityCode")cityDF.show()
+--------------------+----+---------+---------------+
| children|code| name| num|
+--------------------+----+---------+---------------+
|[[340102, yaohai]...|3401| hefei| [1, 6, 9, 0]|
|[[340202, jinghu]...|3402| wuhu| [12, 6, 9, 10]|
|[[340302, longzih...|3403| bengbu| [2, 6, 0]|
|[[340402, datong]...|3404| huainan| [12, 6, 9, 0]|
|[[340503, huashan...|3405| maanshan| [12, 6, 9, 0]|
|[[340602, duji], ...|3406| huaibei|[12, 16, 39, 0]|
|[[340705, tonggua...|3407| tonglin|[12, 46, 59, 0]|
|[[340802, yingjia...|3408| anqing| [12, 6, 9, 0]|
|[[341002, tunxi],...|3410|huangshan| [112, 6, 9, 0]|
|[[341102, langya]...|3411| chuzhou| [12, 66, 9, 0]|
|[[341502, jinan],...|3415| luan| [12, 6, 9, 60]|
+--------------------+----+---------+---------------+
注意:
这里读取Json文件的时候,如果是这种多行的格式那么需要加上spark.sparkContext.wholeTextFiles(path).values,否则会报错。
四、Spark-sql 中常见函数
为了方便演示,这里先读取student、student01、以及anhui-city.json中的数据,这些作为演示数据:
import java.util.Properties
import org.apache.spark.sql.{DataFrame, SparkSession}/*** Dataset里方法测试*/
object DatasetApiTest {case class Student(Sno: String, Sname: String, Ssex: String, Sbirthday: String, ClassCode: String)case class Teacher(name: String, workYear: BigInt)case class Teacher1(subjectId: String, name: String, workYear: Double)case class Subject(id: String, subjectName: String)val urldb = "jdbc:mysql://localhost:3306/imok?user=root&password=123456&useSSL=false"def main(args: Array[String]): Unit = {val spark = SparkSession.builder().appName("MysqlSupport").master("local[2]").getOrCreate()import spark.implicits._// 获取 student 表中全量的数据val studentDF = getStudentSourceData(spark)studentDF.show()println(s"=================以上为 student 表全量数据,数量为${studentDF.count()} ==================")// 获取 student01 表中全量的数据val student01DF = getStudent01SourceData(spark)student01DF.show()println(s"=================以上为 student01 表全量数据,数量为${student01DF.count()} ==================")// 获取 score 表中全量的数据val scoreDF = getScoreSourceData(spark)scoreDF.show()println(s"=================以上为 score 表全量数据,数量为${scoreDF.count()} ==================")val path = "src/main/java/spark/json/anhui-city.json"val jsonDF = spark.read.json(spark.sparkContext.wholeTextFiles(path).values)jsonDF.createOrReplaceTempView("cityCode")val cityDF = spark.sql("select * from cityCode")cityDF.show()println(s"=================以上为 anhui-city json 文件全量数据,数量为${cityDF.count()} ==================")val teacherFilePath = "src/main/java/spark/json/teacher.json"val teacherDS = spark.read.json(teacherFilePath).as[Teacher]teacherDS.show()println(s"=================以上为 teacher json 文件全量数据,数量为${teacherDS.count()} ==================")val teacher1FilePath = "src/main/java/spark/json/teacher1.json"val teacher1DS = spark.read.json(teacherFilePath).as[Teacher1]teacher1DS.show()println(s"=================以上为 teacher1 json 文件全量数据,数量为${teacher1DS.count()} ==================")val subjectFilePath = "src/main/java/spark/json/subject.json"val subjectDS = spark.read.json(subjectFilePath).as[Subject]subjectDS.show()println(s"=================以上为 subject json 文件全量数据,数量为${subjectDS.count()} ==================")/** 【各种测试method】 */distinctTest(spark, studentDF)dropDuplicatesTest(spark, studentDF)filterTest(spark, cityDF)exceptTest(studentDF, student01DF)intersectTest(studentDF, student01DF)mapTest(spark, studentDF)flatMapTest(spark, studentDF)mapPartitionTest(spark,studentDF)coalesceAndRepartitionsTest(spark, studentDF)joinTest(spark, studentDF, scoreDF)sortTest(spark, teacherDS)sampleAndRandomSplit(spark, teacherDS)groupByTest(spark, teacher1DS, subjectDS)dateRoundRandConcatTest(spark, teacher1DS, subjectDS)aggTest(spark, teacher1DS, subjectDS)collect_listCollect_setTest(spark, teacher1DS, subjectDS)withColumnTest(spark, studentDF)selectTest(spark, studentDF)collectAsListTest(spark, studentDF)firstHeadTest(spark, studentDF)schemaTest(spark, studentDF)unionTest(spark, studentDF)describeTest(spark, studentDF)colApplyTest(spark, studentDF)spark.stop()}def getStudentSourceData(spark: SparkSession): DataFrame = {import spark.implicits._val df = spark.read.jdbc(urldb, "student", new Properties())df.createOrReplaceTempView("student")spark.sql("select * from student")}def getStudent01SourceData(spark: SparkSession): DataFrame = {val df = spark.read.jdbc(urldb, "student01", new Properties())df.createOrReplaceTempView("student01")spark.sql("select * from student01")}def getScoreSourceData(spark: SparkSession): DataFrame = {val df = spark.read.jdbc(urldb, "score", new Properties())df.createOrReplaceTempView("score")spark.sql("select * from score")}
}
(1)去重函数:distinct / dropDuplicates
distinct:是根据每一条数据进行完整内容的对比和去重
def distinctTest(spark: SparkSession, df: DataFrame): Unit = {val studentDistinctDF = df.distinct();studentDistinctDF.show()println(s"==================以上为 student 表全量 distinct 后数据,数量为${studentDistinctDF.count()} ===========")}
+---+-----+----+-------------------+---------+
|Sno|Sname|Ssex| Sbirthday|ClassCode|
+---+-----+----+-------------------+---------+
|107| 王丽| 女|1976-01-23 00:00:00| 95033|
|105| 匡明| 男|1975-10-02 00:00:00| 95031|
|103| 陆君| 男|1974-06-03 00:00:00| 95031|
|108| 曾华| 男|1977-09-01 00:00:00| 95033|
|101| 李军| 男|1976-02-20 00:00:00| 95033|
|102| 李军| 男|1976-02-20 00:00:00| 95033|
|110| 王鹏| 男|2022-07-06 18:20:50| |
|109| 王芳| 男|1975-02-10 00:00:00| 95031|
+---+-----+----+-------------------+---------+
==================以上为 student 表全量 distinct 后数据,数量为8 ============
dropDuplicates:可以根据指定的字段进行去重
def dropDuplicatesTest(spark: SparkSession, df: DataFrame): Unit = {val studentDropDuplicatesDF = df.dropDuplicates("ClassCode")studentDropDuplicatesDF.show()println(s"====以上为 student 表全量 dropDuplicates 后数据,数量为${studentDropDuplicatesDF.count()} ====")}
+---+-----+----+-------------------+---------+
|Sno|Sname|Ssex| Sbirthday|ClassCode|
+---+-----+----+-------------------+---------+
|101| 李军| 男|1976-02-20 00:00:00| 95033|
|103| 陆君| 男|1974-06-03 00:00:00| 95031|
|110| 王鹏| 男|2022-07-06 18:20:50| |
+---+-----+----+-------------------+---------+
====以上为 student 表全量 dropDuplicates 后数据,数量为3 ====
(2)过滤函数:filter / except / intersect
filter:根据我们自己的业务逻辑,如果返回true,就保留该元素,如果是false,就不保留该元素
def filterTest(spark: SparkSession, df: DataFrame): Unit = {// val studentFilterDF = df.filter("Sno = 101");val studentFilterDF = df.filter(s"array_contains(num, 1)");studentFilterDF.show()println(s"==================以上为 filter 后数据,数量为${studentFilterDF.count()} ==================")//使用自定义函数的方式val resultDF = df.filter(new MyFilterFunction)resultDF.show()println(s"==================以上为 使用自定义函数 filter 后数据,数量为${resultDF.count()} ==================")}
import org.apache.spark.api.java.function.FilterFunctionclass MyFilterFunction extends FilterFunction[Row] {override def call(value: Row): Boolean = {println(value.getString(2))println(value.getList(3))value.getList(3).toString.contains("1") && "hefei".equals(value.getString(2))}}
+--------------------+----+-----+------------+
| children|code| name| num|
+--------------------+----+-----+------------+
|[[340102, yaohai]...|3401|hefei|[1, 6, 9, 0]|
+--------------------+----+-----+------------+
==================以上为 filter 后数据,数量为1 ==================
hefei
[1, 6, 9, 0]
wuhu
[12, 6, 9, 10]
bengbu
[2, 6, 0]
huainan
[12, 6, 9, 0]
maanshan
[12, 6, 9, 0]
huaibei
[12, 16, 39, 0]
tonglin
[12, 46, 59, 0]
anqing
[12, 6, 9, 0]
huangshan
[112, 6, 9, 0]
chuzhou
[12, 66, 9, 0]
luan
[12, 6, 9, 60]
+--------------------+----+-----+------------+
| children|code| name| num|
+--------------------+----+-----+------------+
|[[340102, yaohai]...|3401|hefei|[1, 6, 9, 0]|
+--------------------+----+-----+------------+
==================以上为 使用自定义函数 filter 后数据,数量为1 ==================
except:获取在当前的dataset中有,但是在另一个dataset中没有的元素
def exceptTest(df: DataFrame, df01: DataFrame): Unit = {val value = df.except(df01)val value01 = df01.except(df)value.show()println(s"==================以上为 except value 后数据,数量为${value.count()} ==================")value01.show()println(s"==================以上为 except value01 后数据,数量为${value01.count()} ==================")}
+---+-----+----+-------------------+---------+
|Sno|Sname|Ssex| Sbirthday|ClassCode|
+---+-----+----+-------------------+---------+
|107| 王丽| 女|1976-01-23 00:00:00| 95033|
|110| 王鹏| 男|2022-07-06 18:20:50| |
|103| 陆君| 男|1974-06-03 00:00:00| 95031|
|105| 匡明| 男|1975-10-02 00:00:00| 95031|
|109| 王芳| 男|1975-02-10 00:00:00| 95031|
|108| 曾华| 男|1977-09-01 00:00:00| 95033|
+---+-----+----+-------------------+---------+
==================以上为 except value 后数据,数量为6 ==================
+----+-----+----+-------------------+---------+
| Sno|Sname|Ssex| Sbirthday|ClassCode|
+----+-----+----+-------------------+---------+
|2108| 曾华| 男|1977-09-01 00:00:00| 95033|
|2101| 李军| 男|1976-02-20 00:00:00| 95033|
|2103| 陆君| 男|1974-06-03 00:00:00| 95031|
|2107| 王丽| 女|1976-01-23 00:00:00| 95033|
|2110| 王鹏| 男|2022-07-06 18:20:50| 95031|
|2109| 王芳| 男|1975-02-10 00:00:00| 95031|
|2105| 匡明| 男|1975-10-02 00:00:00| 95031|
+----+-----+----+-------------------+---------+
==================以上为 except value01 后数据,数量为7 ==================
intersect:获取两个dataset中的交集
def intersectTest(df: DataFrame, df01: DataFrame): Unit = {val value = df.intersect(df01)value.show()println(s"==================以上为 intersect 取交集后数据,数量为${value.count()} ==================")}
+---+-----+----+-------------------+---------+
|Sno|Sname|Ssex| Sbirthday|ClassCode|
+---+-----+----+-------------------+---------+
|102| 李军| 男|1976-02-20 00:00:00| 95033|
|101| 李军| 男|1976-02-20 00:00:00| 95033|
+---+-----+----+-------------------+---------+
==================以上为 intersect 取交集后数据,数量为2 ==================
(3)Map函数:map / flatMap / mapPartition
map:将数据集中的每条数据做一个映射,返回一条映射
一开始我们定义一个Student:
case class Student(Sno: String, Sname: String, Ssex: String, Sbirthday: String, ClassCode: String)
def mapTest(spark: SparkSession, df: DataFrame): Unit = {import spark.implicits._df.as[Student].show()println("==================df.as[Student]==================")df.as[Student].map(stu => {Seq(Student(stu.Sno, stu.Sname + "imok", stu.Ssex + "2", stu.Sbirthday + "3", stu.ClassCode + 4 ))}).show()println("==================df.as[Student] Seq==================")val value = df.rdd.map(row => {row.getAs[String]("Sname") + "_imok"}).collect().toListprintln(s"====以上为map后数据${value}====")}
+---+-----+----+-------------------+---------+
|Sno|Sname|Ssex| Sbirthday|ClassCode|
+---+-----+----+-------------------+---------+
|101| 李军| 男|1976-02-20 00:00:00| 95033|
|103| 陆君| 男|1974-06-03 00:00:00| 95031|
|105| 匡明| 男|1975-10-02 00:00:00| 95031|
|107| 王丽| 女|1976-01-23 00:00:00| 95033|
|108| 曾华| 男|1977-09-01 00:00:00| 95033|
|109| 王芳| 男|1975-02-10 00:00:00| 95031|
|110| 王鹏| 男|2022-07-06 18:20:50| |
|101| 李军| 男|1976-02-20 00:00:00| 95033|
|102| 李军| 男|1976-02-20 00:00:00| 95033|
+---+-----+----+-------------------+---------+
==================df.as[Student]==================
+-----------------------+
| value|
+-----------------------+
|[[101, 李军imok, 男2...|
|[[103, 陆君imok, 男2...|
|[[105, 匡明imok, 男2...|
|[[107, 王丽imok, 女2...|
|[[108, 曾华imok, 男2...|
|[[109, 王芳imok, 男2...|
|[[110, 王鹏imok, 男2...|
|[[101, 李军imok, 男2...|
|[[102, 李军imok, 男2...|
+-----------------------+
==================df.as[Student] Seq==================
====以上为map后数据List(李军_imok, 陆君_imok, 匡明_imok, 王丽_imok, 曾华_imok, 王芳_imok, 王鹏_imok, 李军_imok, 李军_imok)====
flatMap:数据集中的每条数据都可以返回多条数据
def flatMapTest(spark: SparkSession, df: DataFrame): Unit = {val value = df.rdd.flatMap(row => {row.getAs[String]("Sname")+ "_imok"}).collect().toListprintln(s"==以上为 flatMap 后数据${value}===")}
==以上为 flatMap 后数据List(李, 军, _, i, m, o, k, 陆, 君, _, i, m, o, k, 匡, 明, _, i, m, o, k, 王, 丽, _, i, m, o, k, 曾, 华, _, i, m, o, k, 王, 芳, _, i, m, o, k, 王, 鹏, _, i, m, o, k, 李, 军, _, i, m, o, k, 李, 军, _, i, m, o, k)===
mapPartition:一次性对一个partition中的数据进行处理
def mapPartitionTest(spark: SparkSession, df: DataFrame){val value = df.rdd.mapPartitions(iter => {var result = scala.collection.mutable.ArrayBuffer[(String, Long)]()while (iter.hasNext){var student = iter.next()println(s"===========${student}===")}result.iterator})println(s"==以上为 mapPartition 后数据${value.collect().toList}====")}
===========[101,李军,男,1976-02-20 00:00:00.0,95033]===
===========[103,陆君,男,1974-06-03 00:00:00.0,95031]===
===========[105,匡明,男,1975-10-02 00:00:00.0,95031]===
===========[107,王丽,女,1976-01-23 00:00:00.0,95033]===
===========[108,曾华,男,1977-09-01 00:00:00.0,95033]===
===========[109,王芳,男,1975-02-10 00:00:00.0,95031]===
===========[110,王鹏,男,2022-07-06 18:20:50.0,]===
===========[101,李军,男,1976-02-20 00:00:00.0,95033]===
===========[102,李军,男,1976-02-20 00:00:00.0,95033]===
==以上为 mapPartition 后数据List()====
(4)重分区函数:coalesce 和 repartition
都是用来进行重分区的
coalesce只能用于减少分区的数据,而且可以选择不发生shufflerepartition可以增加分区的数据,也可以减少分区的数据,必须会发生shuffle,相当于进行了一次重新分区操作
def coalesceAndRepartitionsTest(spark: SparkSession, df: DataFrame): Unit = {println(df.rdd.partitions.size)// repartitionval studentDFRepartition = df.repartition(4)println(studentDFRepartition.rdd.partitions.size)studentDFRepartition.rdd.partitions.foreach(println)// coalesceval studentDFCoalesce = studentDFRepartition.coalesce(3)println(studentDFCoalesce.rdd.partitions.size)studentDFCoalesce.rdd.partitions.foreach(println)}
1
4
org.apache.spark.sql.execution.ShuffledRowRDDPartition@0
org.apache.spark.sql.execution.ShuffledRowRDDPartition@1
org.apache.spark.sql.execution.ShuffledRowRDDPartition@2
org.apache.spark.sql.execution.ShuffledRowRDDPartition@3
3
CoalescedRDDPartition(0,ShuffledRowRDD[58] at rdd at DatasetApiTest.scala:166,[I@2210e466,None)
CoalescedRDDPartition(1,ShuffledRowRDD[58] at rdd at DatasetApiTest.scala:166,[I@be1c08a,None)
CoalescedRDDPartition(2,ShuffledRowRDD[58] at rdd at DatasetApiTest.scala:166,[I@10408ea,None)
(5)join:根据某一个字段,关联合并两个数据集
def joinWith(spark: SparkSession, studentDF: DataFrame, scoreFD: DataFrame): Unit = {import spark.implicits._studentDF.joinWith(scoreFD, $"student.Sno" === $"score.Sno").show()}
+-----------------------+------------------+
| _1| _2|
+-----------------------+------------------+
|[108, 曾华, 男, 1977...|[108, 3-105, 78.0]|
|[101, 李军, 男, 1976...|[101, 3-105, 64.0]|
|[101, 李军, 男, 1976...|[101, 3-105, 64.0]|
|[103, 陆君, 男, 1974...|[103, 3-245, 86.0]|
|[107, 王丽, 女, 1976...|[107, 3-105, 91.0]|
|[109, 王芳, 男, 1975...|[109, 3-245, 68.0]|
|[105, 匡明, 男, 1975...|[105, 3-245, 75.0]|
+-----------------------+------------------+
(6)sort:对数据表排序
def sortTest(spark: SparkSession, teacherDS: Dataset[Teacher]): Unit = {import spark.implicits._teacherDS.sort($"workYear".desc).show()// 创建临时表,使用sql语句teacherDS.toDF().createOrReplaceTempView("teacher")val result = spark.sql("select * from teacher a where 1=1 order by workYear desc")println("=============sort sql=======================")result.show()}
+-----+--------+
| name|workYear|
+-----+--------+
| Liu| 5|
| Li| 4|
| Song| 4|
|Zhang| 3|
+-----+--------+
=============sort sql=======================
+-----+--------+
| name|workYear|
+-----+--------+
| Liu| 5|
| Li| 4|
| Song| 4|
|Zhang| 3|
+-----+--------+(7)切分函数:randomSplit / sample
randomSplit:根据Array中的元素的数量进行切分,然后再给定每个元素的值来保证对切分数据的权重
换句话说,它的入参实际是个weights权重,是个数组,根据weight(权重值)将一个RDD划分成多个RDD,权重越高划分得到的元素较多的几率就越大。数组的长度即为划分成RDD的数量,如:
rdd1 = rdd.randomSplit([0.25,0.25,0.25,0.25])
上面的作用就是把原本的RDD尽可能的划分成4个相同大小的RDD。
sample:根据我们设定的比例进行随机抽取
sample 会随机在 Dataset 中抽样,可以使用指定的比例,比如说0.1或者0.9,从RDD中随机抽取10%或者90%的数据。
再拿上面的数据来举例:
def sampleAndRandomSplit(spark: SparkSession, teacherDS: Dataset[Teacher]): Unit = {teacherDS.randomSplit(Array(2, 5, 1)).foreach(ds => ds.show())println("=============以下是 sample =======================")teacherDS.sample(false, 0.5).show()}
+----+--------+
|name|workYear|
+----+--------+
| Liu| 5|
+----+--------++-----+--------+
| name|workYear|
+-----+--------+
| Li| 4|
| Song| 4|
|Zhang| 3|
+-----+--------++----+--------+
|name|workYear|
+----+--------+
+----+--------+
=============以下是 sample =======================
+----+--------+
|name|workYear|
+----+--------+
| Li| 4|
| Liu| 5|
+----+--------+
(8)分组函数:groupBy
def groupByTest(spark: SparkSession, teacherDS: Dataset[Teacher1], subjectDS: Dataset[Subject]): Unit = {import spark.implicits._val joinDF = teacherDS.join(subjectDS, $"subjectId" === $"id")joinDF.show()println("=============以下是 groupBy 结果 =======================")joinDF.groupBy("subjectId", "subjectName").sum("workYear").select("subjectId", "subjectName", "sum(workYear)").orderBy($"sum(workYear)".desc).show()}
+-----+---------+--------+---------+-----------+
| name|subjectId|workYear| id|subjectName|
+-----+---------+--------+---------+-----------+
|zhang|subject-1| 3.0|subject-1| English|
| li|subject-2| 4.5|subject-2| Math|
| song|subject-2| 3.5|subject-2| Math|
| wang|subject-1| 4.0|subject-1| English|
+-----+---------+--------+---------+-----------+
=============以下是 groupBy 结果 =======================
+---------+-----------+-------------+
|subjectId|subjectName|sum(workYear)|
+---------+-----------+-------------+
|subject-2| Math| 8.0|
|subject-1| English| 7.0|
+---------+-----------+-------------+
(9)current_date / current_timestamp / rand / round / concat 函数
def dateRoundRandConcatTest(spark: SparkSession, teacherDS: Dataset[Teacher1], subjectDS: Dataset[Subject]): Unit = {import spark.implicits._val joinDF = teacherDS.join(subjectDS, $"subjectId" === $"id")joinDF.show()joinDF.select(current_date(),current_timestamp(),rand(),round($"workYear",2),concat($"name",$"workYear")).show()}
+-----+---------+--------+---------+-----------+
| name|subjectId|workYear| id|subjectName|
+-----+---------+--------+---------+-----------+
|zhang|subject-1| 3.0|subject-1| English|
| li|subject-2| 4.5|subject-2| Math|
| song|subject-2| 3.5|subject-2| Math|
| wang|subject-1| 4.0|subject-1| English|
+-----+---------+--------+---------+-----------+
+--------------+--------------------+--------------------------+------------------+----------------------+
|current_date()| current_timestamp()|rand(-6737295850841925880)|round(workYear, 2)|concat(name, workYear)|
+--------------+--------------------+--------------------------+------------------+----------------------+
| 2023-07-22|2023-07-22 20:50:...| 0.4541815642686837| 3.0| zhang3.0|
| 2023-07-22|2023-07-22 20:50:...| 0.32025655875655334| 4.5| li4.5|
| 2023-07-22|2023-07-22 20:50:...| 0.046929154870246736| 3.5| song3.5|
| 2023-07-22|2023-07-22 20:50:...| 0.6357402473174414| 4.0| wang4.0|
+--------------+--------------------+--------------------------+------------------+----------------------+
(10)agg操作函数:avg / sum / max / min / count
def aggTest(spark: SparkSession, teacherDS: Dataset[Teacher1], subjectDS: Dataset[Subject]): Unit = {import spark.implicits._val joinDF = teacherDS.join(subjectDS, $"subjectId" === $"id")joinDF.show()joinDF.groupBy("subjectId","subjectName").agg(avg("workYear"),sum("workYear"),max("workYear"),min("workYear"),count("name")).show()}
+-----+---------+--------+---------+-----------+
| name|subjectId|workYear| id|subjectName|
+-----+---------+--------+---------+-----------+
|zhang|subject-1| 3.0|subject-1| English|
| li|subject-2| 4.5|subject-2| Math|
| song|subject-2| 3.5|subject-2| Math|
| wang|subject-1| 4.0|subject-1| English|
+-----+---------+--------+---------+-----------+
+---------+-----------+-------------+-------------+-------------+-------------+-----------+
|subjectId|subjectName|avg(workYear)|sum(workYear)|max(workYear)|min(workYear)|count(name)|
+---------+-----------+-------------+-------------+-------------+-------------+-----------+
|subject-1| English| 3.5| 7.0| 4.0| 3.0| 2|
|subject-2| Math| 4.0| 8.0| 4.5| 3.5| 2|
+---------+-----------+-------------+-------------+-------------+-------------+-----------+
============= 和上面的一样,这是另一种写法,结果一样 =======================
+---------+-----------+-------------+-------------+-------------+-------------+-----------+
|subjectId|subjectName|avg(workYear)|sum(workYear)|max(workYear)|min(workYear)|count(name)|
+---------+-----------+-------------+-------------+-------------+-------------+-----------+
|subject-1| English| 3.5| 7.0| 4.0| 3.0| 2|
|subject-2| Math| 4.0| 8.0| 4.5| 3.5| 2|
+---------+-----------+-------------+-------------+-------------+-------------+-----------+
(11)行列转换函数:collect_list / collect_set
collect_list(行转列)将一个分组内指定字段的值收集在一起,不会去重collect_set(行转列)意思同上,唯一的区别就是它会去重
def collect_listCollect_setTest(spark: SparkSession, teacherDS: Dataset[Teacher1], subjectDS: Dataset[Subject]): Unit = {import spark.implicits._val joinDF = teacherDS.join(subjectDS, $"subjectId" === $"id")joinDF.show()joinDF.groupBy("subjectId", "subjectName").agg(collect_list("name")).show()joinDF.groupBy("subjectId", "subjectName").agg(collect_set("name")).show()}
+-----+---------+--------+---------+-----------+
| name|subjectId|workYear| id|subjectName|
+-----+---------+--------+---------+-----------+
|zhang|subject-1| 3.0|subject-1| English|
| li|subject-2| 4.5|subject-2| Math|
| song|subject-2| 3.5|subject-2| Math|
| wang|subject-1| 4.0|subject-1| English|
+-----+---------+--------+---------+-----------+
+---------+-----------+------------------+
|subjectId|subjectName|collect_list(name)|
+---------+-----------+------------------+
|subject-1| English| [zhang, wang]|
|subject-2| Math| [li, song]|
+---------+-----------+------------------+
+---------+-----------+-----------------+
|subjectId|subjectName|collect_set(name)|
+---------+-----------+-----------------+
|subject-1| English| [wang, zhang]|
|subject-2| Math| [song, li]|
+---------+-----------+-----------------+
(12)withColumn
- 向DataFrame添加新列
- 更改现有列的值
- 从现有列派生新列
- 更改列数据类型
- 添加,替换或更新多列
- 重命名列名
- 从DataFrame删除列
- 将列拆分为多列
def withColumnTest(spark: SparkSession, df: DataFrame) {// 1) 向DataFrame添加新列val dataFrameNew = df.withColumn("City", lit("shanghai"))val dataFrameNew1 = df.withColumn("City", lit("shanghai")).withColumn("area", lit("jingan"))dataFrameNew.show()dataFrameNew1.show()println(s"==================以上为 withColumn 向DataFrame添加新列 ==================")// 2) 更改现有列的值, 将现有的列名作为第一个参数传递,将值分配为第二个列。请注意,第二个参数应为Columntype。import org.apache.spark.sql.functions.colval dataFrameNew2 = df.withColumn("ClassCode", col("ClassCode") * 100)val dataFrameNew3 = df.withColumn("ClassCode", buildClassCode(col("ClassCode")))dataFrameNew2.show()dataFrameNew3.show()println(s"==================以上为 withColumn 更改现有列的值 ==================")// 3) 从现有列派生新列val dataFrameNew4 = df.withColumn("ClassCodeNew", buildClassCode(col("ClassCode")))dataFrameNew4.show()println(s"==================以上为 withColumn 从现有列派生新列 ==================")// 4) 更改列数据类型val dataFrameNew5 = df.withColumn("ClassCode", col("ClassCode").cast("Integer"))dataFrameNew5.show()println(s"==================以上为 withColumn 更改列数据类型 ==================")// 5) 添加,替换或更新多个列 当您想在Spark DataFrame中添加,替换或更新多列时,建议不要链接withColumn()函数,因为这会导致性能问题,并建议在DataFrame上创建临时视图后使用select()df.createOrReplaceTempView("student")spark.sql("SELECT ClassCode*100 as ClassCode, ClassCode*-1 as CopiedColumn, Ssex as sex FROM student").show()// 6) 重命名列名df.withColumnRenamed("Ssex", "sex").show()println(s"==================以上为 withColumnRenamed 重命名列名 ==================")}
def buildClassCode: UserDefinedFunction = udf((dateStr: String) => {var covertStr = ""try {covertStr = "1--" + dateStr} catch {case e: Exception =>println("Exception happened to buildClassCode", e)}covertStr})
+---+-----+----+-------------------+---------+--------+
|Sno|Sname|Ssex| Sbirthday|ClassCode| City|
+---+-----+----+-------------------+---------+--------+
|101| 李军| 男|1976-02-20 00:00:00| 95033|shanghai|
|103| 陆君| 男|1974-06-03 00:00:00| 95031|shanghai|
|105| 匡明| 男|1975-10-02 00:00:00| 95031|shanghai|
|107| 王丽| 女|1976-01-23 00:00:00| 95033|shanghai|
|108| 曾华| 男|1977-09-01 00:00:00| 95033|shanghai|
|109| 王芳| 男|1975-02-10 00:00:00| 95031|shanghai|
|110| 王鹏| 男|2022-07-06 18:20:50| |shanghai|
|101| 李军| 男|1976-02-20 00:00:00| 95033|shanghai|
|102| 李军| 男|1976-02-20 00:00:00| 95033|shanghai|
+---+-----+----+-------------------+---------+--------+
+---+-----+----+-------------------+---------+--------+------+
|Sno|Sname|Ssex| Sbirthday|ClassCode| City| area|
+---+-----+----+-------------------+---------+--------+------+
|101| 李军| 男|1976-02-20 00:00:00| 95033|shanghai|jingan|
|103| 陆君| 男|1974-06-03 00:00:00| 95031|shanghai|jingan|
|105| 匡明| 男|1975-10-02 00:00:00| 95031|shanghai|jingan|
|107| 王丽| 女|1976-01-23 00:00:00| 95033|shanghai|jingan|
|108| 曾华| 男|1977-09-01 00:00:00| 95033|shanghai|jingan|
|109| 王芳| 男|1975-02-10 00:00:00| 95031|shanghai|jingan|
|110| 王鹏| 男|2022-07-06 18:20:50| |shanghai|jingan|
|101| 李军| 男|1976-02-20 00:00:00| 95033|shanghai|jingan|
|102| 李军| 男|1976-02-20 00:00:00| 95033|shanghai|jingan|
+---+-----+----+-------------------+---------+--------+------+
==================以上为 withColumn 向DataFrame添加新列 ==================
+---+-----+----+-------------------+---------+
|Sno|Sname|Ssex| Sbirthday|ClassCode|
+---+-----+----+-------------------+---------+
|101| 李军| 男|1976-02-20 00:00:00|9503300.0|
|103| 陆君| 男|1974-06-03 00:00:00|9503100.0|
|105| 匡明| 男|1975-10-02 00:00:00|9503100.0|
|107| 王丽| 女|1976-01-23 00:00:00|9503300.0|
|108| 曾华| 男|1977-09-01 00:00:00|9503300.0|
|109| 王芳| 男|1975-02-10 00:00:00|9503100.0|
|110| 王鹏| 男|2022-07-06 18:20:50| null|
|101| 李军| 男|1976-02-20 00:00:00|9503300.0|
|102| 李军| 男|1976-02-20 00:00:00|9503300.0|
+---+-----+----+-------------------+---------+
+---+-----+----+-------------------+---------+
|Sno|Sname|Ssex| Sbirthday|ClassCode|
+---+-----+----+-------------------+---------+
|101| 李军| 男|1976-02-20 00:00:00| 1--95033|
|103| 陆君| 男|1974-06-03 00:00:00| 1--95031|
|105| 匡明| 男|1975-10-02 00:00:00| 1--95031|
|107| 王丽| 女|1976-01-23 00:00:00| 1--95033|
|108| 曾华| 男|1977-09-01 00:00:00| 1--95033|
|109| 王芳| 男|1975-02-10 00:00:00| 1--95031|
|110| 王鹏| 男|2022-07-06 18:20:50| 1--|
|101| 李军| 男|1976-02-20 00:00:00| 1--95033|
|102| 李军| 男|1976-02-20 00:00:00| 1--95033|
+---+-----+----+-------------------+---------+
==================以上为 withColumn 更改现有列的值 ==================
+---+-----+----+-------------------+---------+------------+
|Sno|Sname|Ssex| Sbirthday|ClassCode|ClassCodeNew|
+---+-----+----+-------------------+---------+------------+
|101| 李军| 男|1976-02-20 00:00:00| 95033| 1--95033|
|103| 陆君| 男|1974-06-03 00:00:00| 95031| 1--95031|
|105| 匡明| 男|1975-10-02 00:00:00| 95031| 1--95031|
|107| 王丽| 女|1976-01-23 00:00:00| 95033| 1--95033|
|108| 曾华| 男|1977-09-01 00:00:00| 95033| 1--95033|
|109| 王芳| 男|1975-02-10 00:00:00| 95031| 1--95031|
|110| 王鹏| 男|2022-07-06 18:20:50| | 1--|
|101| 李军| 男|1976-02-20 00:00:00| 95033| 1--95033|
|102| 李军| 男|1976-02-20 00:00:00| 95033| 1--95033|
+---+-----+----+-------------------+---------+------------+
==================以上为 withColumn 从现有列派生新列 ==================
+---+-----+----+-------------------+---------+
|Sno|Sname|Ssex| Sbirthday|ClassCode|
+---+-----+----+-------------------+---------+
|101| 李军| 男|1976-02-20 00:00:00| 95033|
|103| 陆君| 男|1974-06-03 00:00:00| 95031|
|105| 匡明| 男|1975-10-02 00:00:00| 95031|
|107| 王丽| 女|1976-01-23 00:00:00| 95033|
|108| 曾华| 男|1977-09-01 00:00:00| 95033|
|109| 王芳| 男|1975-02-10 00:00:00| 95031|
|110| 王鹏| 男|2022-07-06 18:20:50| null|
|101| 李军| 男|1976-02-20 00:00:00| 95033|
|102| 李军| 男|1976-02-20 00:00:00| 95033|
+---+-----+----+-------------------+---------+
==================以上为 withColumn 更改列数据类型 ==================
+---------+------------+---+
|ClassCode|CopiedColumn|sex|
+---------+------------+---+
|9503300.0| -95033.0| 男|
|9503100.0| -95031.0| 男|
|9503100.0| -95031.0| 男|
|9503300.0| -95033.0| 女|
|9503300.0| -95033.0| 男|
|9503100.0| -95031.0| 男|
| null| null| 男|
|9503300.0| -95033.0| 男|
|9503300.0| -95033.0| 男|
+---------+------------+---+
+---+-----+---+-------------------+---------+
|Sno|Sname|sex| Sbirthday|ClassCode|
+---+-----+---+-------------------+---------+
|101| 李军| 男|1976-02-20 00:00:00| 95033|
|103| 陆君| 男|1974-06-03 00:00:00| 95031|
|105| 匡明| 男|1975-10-02 00:00:00| 95031|
|107| 王丽| 女|1976-01-23 00:00:00| 95033|
|108| 曾华| 男|1977-09-01 00:00:00| 95033|
|109| 王芳| 男|1975-02-10 00:00:00| 95031|
|110| 王鹏| 男|2022-07-06 18:20:50| |
|101| 李军| 男|1976-02-20 00:00:00| 95033|
|102| 李军| 男|1976-02-20 00:00:00| 95033|
+---+-----+---+-------------------+---------+
==================以上为 withColumnRenamed 重命名列名 ==================
(13)select / selectExpr
def selectTest(spark: SparkSession, df: DataFrame): Unit = {df.select("ClassCode", "Ssex").show()df.select(expr("sum(ClassCode)")).show()df.selectExpr("Ssex as s", "ClassCode as code").limit(2).show()}
+---------+----+
|ClassCode|Ssex|
+---------+----+
| 95033| 男|
| 95031| 男|
| 95031| 男|
| 95033| 女|
| 95033| 男|
| 95031| 男|
| | 男|
| 95033| 男|
| 95033| 男|
+---------+----+
+------------------------------+
|sum(CAST(ClassCode AS DOUBLE))|
+------------------------------+
| 760258.0|
+------------------------------+
+---+-----+
| s| code|
+---+-----+
| 男|95033|
| 男|95031|
+---+-----+
(14)collectAsList : DataFrame 转 List 集合
def collectAsListTest(spark: SparkSession, df: DataFrame): Unit = {val rows = df.collectAsList()val subRows = rows.subList(0, 2)subRows.forEach(println)}
[101,李军,男,1976-02-20 00:00:00.0,95033]
[103,陆君,男,1974-06-03 00:00:00.0,95031]
(15) head / first
def firstHeadTest(spark: SparkSession, df: DataFrame): Unit = {val row = df.first()println(row)//显示前2行val rows = df.head(2)rows.foreach(print)}
[101,李军,男,1976-02-20 00:00:00.0,95033]
[101,李军,男,1976-02-20 00:00:00.0,95033][103,陆君,男,1974-06-03 00:00:00.0,95031]
(16)schema
def schemaTest(spark: SparkSession, df: DataFrame): Unit = {df.printSchema()val structType: StructType = df.schemastructType.printTreeString()}
root|-- Sno: integer (nullable = true)|-- Sname: string (nullable = true)|-- Ssex: string (nullable = true)|-- Sbirthday: timestamp (nullable = true)|-- ClassCode: string (nullable = true)root|-- Sno: integer (nullable = true)|-- Sname: string (nullable = true)|-- Ssex: string (nullable = true)|-- Sbirthday: timestamp (nullable = true)|-- ClassCode: string (nullable = true)
(17)union
union并集,根据列位置合并行,列数要一致unionByName并集,根据列名合并行,不同名报错,列数要一致
def unionTest(spark: SparkSession, df: DataFrame): Unit = {val value = df.union(df.filter("ClassCode=95033"));value.show();val value1 = df.unionByName(df.filter("ClassCode=95033"));value1.show();println(s"================== 反向 union ==================")val value3 = df.filter("ClassCode=95033").union(df)value3.show();val value4 = df.filter("ClassCode=95033").unionByName(df);value4.show();}
+---+-----+----+-------------------+---------+
|Sno|Sname|Ssex| Sbirthday|ClassCode|
+---+-----+----+-------------------+---------+
|101| 李军| 男|1976-02-20 00:00:00| 95033|
|103| 陆君| 男|1974-06-03 00:00:00| 95031|
|105| 匡明| 男|1975-10-02 00:00:00| 95031|
|107| 王丽| 女|1976-01-23 00:00:00| 95033|
|108| 曾华| 男|1977-09-01 00:00:00| 95033|
|109| 王芳| 男|1975-02-10 00:00:00| 95031|
|110| 王鹏| 男|2022-07-06 18:20:50| |
|101| 李军| 男|1976-02-20 00:00:00| 95033|
|102| 李军| 男|1976-02-20 00:00:00| 95033|
|101| 李军| 男|1976-02-20 00:00:00| 95033|
|107| 王丽| 女|1976-01-23 00:00:00| 95033|
|108| 曾华| 男|1977-09-01 00:00:00| 95033|
|101| 李军| 男|1976-02-20 00:00:00| 95033|
|102| 李军| 男|1976-02-20 00:00:00| 95033|
+---+-----+----+-------------------+---------+
+---+-----+----+-------------------+---------+
|Sno|Sname|Ssex| Sbirthday|ClassCode|
+---+-----+----+-------------------+---------+
|101| 李军| 男|1976-02-20 00:00:00| 95033|
|103| 陆君| 男|1974-06-03 00:00:00| 95031|
|105| 匡明| 男|1975-10-02 00:00:00| 95031|
|107| 王丽| 女|1976-01-23 00:00:00| 95033|
|108| 曾华| 男|1977-09-01 00:00:00| 95033|
|109| 王芳| 男|1975-02-10 00:00:00| 95031|
|110| 王鹏| 男|2022-07-06 18:20:50| |
|101| 李军| 男|1976-02-20 00:00:00| 95033|
|102| 李军| 男|1976-02-20 00:00:00| 95033|
|101| 李军| 男|1976-02-20 00:00:00| 95033|
|107| 王丽| 女|1976-01-23 00:00:00| 95033|
|108| 曾华| 男|1977-09-01 00:00:00| 95033|
|101| 李军| 男|1976-02-20 00:00:00| 95033|
|102| 李军| 男|1976-02-20 00:00:00| 95033|
+---+-----+----+-------------------+---------+
================== 反向 union ==================
+---+-----+----+-------------------+---------+
|Sno|Sname|Ssex| Sbirthday|ClassCode|
+---+-----+----+-------------------+---------+
|101| 李军| 男|1976-02-20 00:00:00| 95033|
|107| 王丽| 女|1976-01-23 00:00:00| 95033|
|108| 曾华| 男|1977-09-01 00:00:00| 95033|
|101| 李军| 男|1976-02-20 00:00:00| 95033|
|102| 李军| 男|1976-02-20 00:00:00| 95033|
|101| 李军| 男|1976-02-20 00:00:00| 95033|
|103| 陆君| 男|1974-06-03 00:00:00| 95031|
|105| 匡明| 男|1975-10-02 00:00:00| 95031|
|107| 王丽| 女|1976-01-23 00:00:00| 95033|
|108| 曾华| 男|1977-09-01 00:00:00| 95033|
|109| 王芳| 男|1975-02-10 00:00:00| 95031|
|110| 王鹏| 男|2022-07-06 18:20:50| |
|101| 李军| 男|1976-02-20 00:00:00| 95033|
|102| 李军| 男|1976-02-20 00:00:00| 95033|
+---+-----+----+-------------------+---------+
+---+-----+----+-------------------+---------+
|Sno|Sname|Ssex| Sbirthday|ClassCode|
+---+-----+----+-------------------+---------+
|101| 李军| 男|1976-02-20 00:00:00| 95033|
|107| 王丽| 女|1976-01-23 00:00:00| 95033|
|108| 曾华| 男|1977-09-01 00:00:00| 95033|
|101| 李军| 男|1976-02-20 00:00:00| 95033|
|102| 李军| 男|1976-02-20 00:00:00| 95033|
|101| 李军| 男|1976-02-20 00:00:00| 95033|
|103| 陆君| 男|1974-06-03 00:00:00| 95031|
|105| 匡明| 男|1975-10-02 00:00:00| 95031|
|107| 王丽| 女|1976-01-23 00:00:00| 95033|
|108| 曾华| 男|1977-09-01 00:00:00| 95033|
|109| 王芳| 男|1975-02-10 00:00:00| 95031|
|110| 王鹏| 男|2022-07-06 18:20:50| |
|101| 李军| 男|1976-02-20 00:00:00| 95033|
|102| 李军| 男|1976-02-20 00:00:00| 95033|
+---+-----+----+-------------------+---------+
(18)describe
传入一个或多个String类型的字段名,结果仍然为DataFrame对象,用于统计数值类型字段的统计值,比如count, mean, stddev, min, max等。
def describeTest(spark: SparkSession, df: DataFrame): Unit = {df.describe("Sno", "Sname", "Sbirthday", "ClassCode").show()}
+-------+------------------+-----+------------------+
|summary| Sno|Sname| ClassCode|
+-------+------------------+-----+------------------+
| count| 9| 9| 9|
| mean|105.11111111111111| null| 95032.25|
| stddev| 3.515837184954831| null|1.0350983390126753|
| min| 101| 匡明| |
| max| 110| 陆君| 95033|
+-------+------------------+-----+------------------+
注意:
1)常用于计算列字段最大值,最小值
2)Sbirthday是时间类型不识别
(19)col / apply
col:获取指定字段 只能获取一个字段,返回对象为Column类型apply:获取指定字段 只能获取一个字段,返回对象为Column类型
def colApplyTest(spark: SparkSession, df: DataFrame): Unit = {val idCol = df.col("Sno")val idCol1 = df.apply("Sno")val idCol2 = df("Sno")println(s"===== colApplyTest ====${idCol.desc}, ====$idCol1, =====$idCol2====")}
===== colApplyTest ====Sno DESC NULLS LAST, ====Sno, =====Sno====
本文涉及到的代码仓库链接,点我跳转
本文来自互联网用户投稿,文章观点仅代表作者本人,不代表本站立场,不承担相关法律责任。如若转载,请注明出处。 如若内容造成侵权/违法违规/事实不符,请点击【内容举报】进行投诉反馈!