Intelligent Condition Based Monitoring of Rotating Machines using Sparse Auto-encoders(翻译)
基于稀疏自动编码器的旋转机械智能状态监测
原文:https://ieeexplore.ieee.org/document/6621447
摘要
支持向量机(SVM)作为分类器在机器故障诊断中得到了广泛的应用。在大多数复杂的机器学习问题中,主要的挑战在于找到好的特征。稀疏自动编码器能够在无监督的情况下从输入数据中学习良好的特征。稀疏自动编码器和其他深层结构已经在文本分类、说话人和语音识别以及人脸识别等方面取得了很好的效果。本文比较了稀疏自编码器、基于Mahalanobis距离的快速分类器和支持向量机在空压机故障诊断中的性能。
关键词-稀疏自动编码器,支持向量机,马氏距离,特征提取,特征选择
一、 简介
机器是工业的一个组成部分,在生产力方面起着重要的作用。这使得机器故障诊断受到高度关注。随着时间的推移,机器会发生磨损和故障。为了防止巨大的经济损失、不必要的人员伤亡和提高工业生产率,对机器进行即时健康监测具有非常重要的意义。除此之外,如果在故障变得严重之前就发现了故障,那么维护成本也可以大大降低。
机器在运行过程中产生的声音信号是其运行状态的特征。当机器出现故障时,这些信号会逐渐变化。基于这些变化,可以根据声信号的特征来判断机器的健康状态。这些特征随后用于检测机器中的各种故障。
在机器故障诊断方面,人们已经用不同的信号和算法做了大量的工作。Tse等人[1]提出了对加速度计采集的振动数据进行分析的方法。特征提取采用精确小波分析。Huang等人[2]利用经验模态分解将原始振动信号分解为固有模态函数。这些函数表示组成机械系统的部件产生的振荡模式。陈志刚等[3]提出了小波包分解的小波包熵特征向量选取方法,并将支持向量机用于故障识别。王凤涛等[4]提出了利用压力-容积(P-V)指示图分析空气压缩机健康状况的方法。Verma等人[5][6] 利用支持向量机对空压机故障进行时域、频域和小波域的故障诊断。
通常支持向量机的内存和计算复杂度都大于O(n2)[7]。因此,为了加快分类速度,我们使用基于马氏距离的分类器,因为它的计算复杂度为O(n2),而且几乎不需要训练。稀疏自动编码器作为一种生成模型,能够学习高阶特征。它们具有更好的性能,因为原始数据特征在深层以更好的方式表示,使得分类器即使在较少的训练样本数下也能给出更准确的结果。
论文组织如下。第二节介绍了本实验室之前建立的基于支持向量机的模型的概述。第三节介绍了基于马氏距离的分类器和基于深层结构的分类器的理论。第四节概述了deep体系结构和基于mahalanobis距离的分类器的实现方法,然后是第五节的结果。
二、旧的数据挖掘模型
在这里,我们描述了数据挖掘模型的概述,该模型在我们的实验室中用于诊断空气压缩机的故障[5]。
A、 记录阶段
我们使用了通过传感器获得的记录以及NI的DAQ和Labview。每个样品持续5秒。
B、 预处理阶段
然后对原始数据进行预处理,以提高数据质量。预处理包括以下步骤。首先,将数据向下采样2倍。从5s样本中,我们选择标准差最小的Is样本。这个过程被称为限幅,它的执行是因为具有最小标准差的窗口被期望是一个稳定的信号,与其他可能有突发或突发噪声的窗口相比。此外,数据被平滑以消除尖峰的影响(如果可用),最后将数据标准化为0到1。
C、 特征提取:
1) 时域信号和波形通常出现在时域中。但是,由于时域表示是表示数据的一种非常基本的方法,因此无法得出太多的推论。然而,从时域中提取了七个统计参数。它们是绝对平均值、均方根、均方根、方差、峰度因子、峰值因子和偏度。
2) 频域
频域特征显示了信号能量如何随频率变化。为了研究信号的频域特性,需要利用快速傅立叶变换(FFT)将时域信号转换为频域信号。FFT允许我们获得频率分量的频谱,然后将其分成n个相等的段,称为bin。
3) 小波域
频域适用于平稳信号,即当信号的频率特性不随时间变化时。这里,我们处理非平稳信号。小波域分析为非平稳信号的时频分析提供了一种强有力的工具。根据不同时域窗口中的不同频率分量对信号进行分析。
a) Morlet小波特征:
Morlet小波是一个余弦信号,两边都呈指数衰减。从数学上定义为:
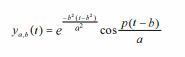
式中(1)为a和b分别对母小波展开和平移得到的子小波。利用morlet小波对信号进行卷积,将信号从时间域变换到时频域。根据得到的小波系数,计算标准差、小波熵、峰度因子、偏度、方差、过零率和峰值和等特征。
b) 离散小波变换:
它是数字信号处理中的另一个强大工具。它使用低通和高通滤波器对信号进行分解。这些滤波器有几个家族,如Haar、Daubechies、Coifflets等。信号与滤波器卷积后得到两组系数。从低通滤波器获得的系数称为近似系数,从高通滤波器获得的系数称为细节系数[4]。卷积表达式由以下公式给出:
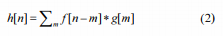
其中,h[n]是函数f和g的卷积输出。进一步分解近似系数,得到一组新的近似系数和细节系数。另一方面,细节系数没有进一步分解。对于离散小波变换,我们在应用中使用了Daubechies 4分解滤波器。这两个滤波器,即db4低通滤波器和db4高通滤波器分别由8个系数组成。
D、 使用支持向量机进行分类:
无论从理论上还是实践上,支持向量机都被认为是一种非常合适的分类算法。在Vapnik[8]的广义理论中,他证明了如果训练样本足够大(超过某个阈值),并且VC维数不够高,经验风险最小化会导致结构风险最小化(SRM)。通过这种方法,分类器变得通用化,并且与其他常规分类器相比,能够以更高的精度对未知样本进行正确分类。
a) 最大边缘分类器
它是最简单的模型之一,它在首次引入时处理线性可分离数据。构造分离超平面的任务转化为一个凸优化问题。给定一个线性可分的训练数据集X=((x1,y1),(x2,y2)…(xn,yn)),问题如下:
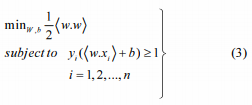
我们需要找到最优超平面的(w,b),这是通过对Lagranian应用优化条件得到的。因此,我们将分类器设为:
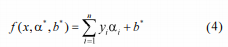
其中α*是通过求解Langranian和下面式子
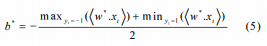
对于非线性数据,采用核函数进行分类。
b) 软边界分类器
实际上,现实世界中的大多数问题都是不可分离的,因此最大边缘分类器并不适用于这些问题。为了适应这一问题,在确定以ξi为单位的裕度时,稍作修改,作为成本函数中带有成本C的惩罚[8]。
这种情况下的优化问题可以表述为:
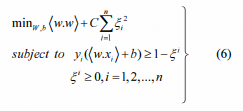
三、 基于马氏距离和稀疏自动编码的分类器
A、 马氏距离
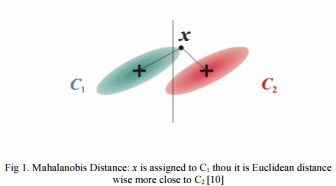
距离度量或相似性度量是比较两个元素在空间中是集合还是点的最基本的方法。在机器学习中,距离度量用于特征选择或分类算法。Ll(曼哈顿距离)范数和L2(欧氏距离)范数是最常用的距离度量。但是,他们没有给我们提供足够的信息。例如,L2范数没有考虑变量之间的相关性,也没有考虑尺度问题。中心趋势度量,如均值、中位数、标准差、协方差等,也传递了有关特征空间中数据分布的重要信息。为了克服这些问题,使用了马氏距离,它考虑了变量的协方差。通过这种方式,标度的问题也得到了解决,因为协方差项给出了这些具有不同单位的变量如何相关的度量。当距离度量变得依赖于类时,马氏距离在检测异常值方面也相对更好[9]。
马氏距离定义如下:给定m个平均向量为μi,i = 1, 2, …, m和∑ij, 1<=i, j<=m的数据集,∑ij是ith和jth数据集的协方差矩阵,ith和jth数据集之间的马氏平方距离由以下公式定义:
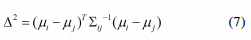
其中,∑ij是一个非奇异的正定协方差矩阵,因此Δ是一个度量。如果变量是不相关的,那么协方差矩阵将只是一个单位矩阵,距离将与欧几里德距离相同。同一个概念用于计算一个点与不同数据集的距离。设X是多元向量,μi是ith数据集的平均向量。那么X和ith数据集之间的马氏距离由下式给出:
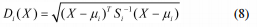
其中,Si是ith数据集的协方差矩阵。Di,即最小值,相应地,i被指定为该数据点的类。
B、 深层架构:
浅层体系结构是一个由很少的组成层组成的模型,如线性模型和一个隐藏的分层神经网络。在用计算单元(隐藏单元和基)的数量来表示高阶关系时,它们可能是低效的,因此在所需示例方面[11]。紧凑地表示高度变化的函数的一种方法是通过许多非线性的组合,即使用深层结构[12]。
最近在深体系结构中的理论研究表明,它可以为复杂分布提供一个有效的模型,并能在具有挑战性的识别任务中获得更好的泛化性能[11][13]。
深层网络有多个隐藏层。每一层计算前一层的非线性变换,因此深度网络比浅层网络具有更大的表示能力。
在深度网络中,我们尝试学习输入的概率,而不是给定输入的标签的概率,即,我们尝试学习p(输入),而不是学习p(标签|输入)[14]。它是一种生成性模型,可以像输入一样产生输出。然而,在深体系结构中学习被证明是困难的[15],因为深层体系结构的训练涉及到一个潜在的棘手的凸优化[11]。这个问题的解决方案由Hinton[16][12]提出。成功训练深层架构的关键因素似乎是使用无监督的训练准则来执行逐层初始化。
在这里,我们试图利用声音数据来识别旋转电机(如感应电机和空气压缩机)的故障。为了对声学数据进行降维和特征学习,我们采用了叠层自动编码器作为无监督学习算法。然后,softmax分类器接收从输入中学习到的高级表示,以便对机器中的各种故障进行分类。
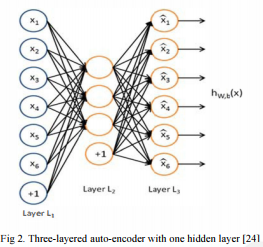
1) 自动编码器
自动编码器是一种经过训练的神经网络,用于计算输入的表示,从中可以尽可能精确地重构输入,正如Hinton等人首先介绍的那样[17]。最近,它们被用作无监督学习算法[11][18]。
自动编码器获取与ith训练示例相对应的输入向量xi∈[0,1],通过确定性映射将其映射到隐藏层a∈[0,1](a是第一隐藏层的激活向量)
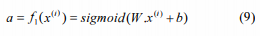
由e∈{W,b}参数化。然后将得到的潜在表示a映射回输入空间中的重构向量a[13] [19]。
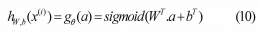
a) 稀疏约束
深层架构的设计应该使每个训练样本都能被一个唯一的代码正确地表示出来,因此可以用一个很小的重构错误从代码中重构出来。这可以通过限制代码的信息内容来有效地实现。
这可以通过使代码成为具有少量不同值的离散变量,或使代码具有比输入更低的维数,或强制代码成为大多数分量为零的“稀疏”向量来实现[20]。
稀疏超完备表示具有许多理论和实际的优点。过完备表示的基向量大于输入的维数。特别是对噪声有很好的鲁棒性[21][22][23]。
我们希望隐藏单元在大部分时间内是不活跃的,也就是说,对于sigmoid激活函数,神经元的输出应该接近于零。如果
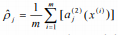
是完全训练数据上隐藏单元j的平均激活,则我们施加约束:ρ^j=ρ,其中ρ是稀疏性参数,其值接近于零。在我们的例子中,我们认为它是0.1[19]。
为了实现这一点,增加了一个惩罚项来惩罚偏离稀疏性参数的平均激活。
处罚条款有多种选择。我们用了一个基于KL散度的。
b) 自动编码器的代价函数
对于“m”训练示例的固定训练集{(x(1),y(1)), (x(2),y(2)), …, (x(m),y(m))},初始成本函数如下所示:
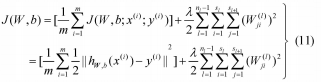
其中,J(W,b)中的第一项是平均平方和误差项。这里的b与(9)和(10)中提到的相同。第二项是正则化项或权值衰减项,它有助于减小权值的大小并防止过拟合,hW,b(x(i))是假设,λ是权值衰减参数。
在增加惩罚项时,代价函数变为
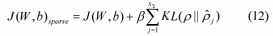
β项控制稀疏惩罚项的权重[19 ]。
2) 堆叠式自动编码器
学习复杂模型的有效方法是组合一组按顺序学习的简单模型。该模型对其输入向量执行非线性变换,并生成将用作序列中下一个模型的输入的向量作为输出。
每一层的自动编码器是预先训练,以产生一个更高层次的代表,它从下面一层收到的输入。每一级产生一个比前一级更抽象的输入表示,因为它是通过组合更多的操作获得的。从这一点上对模型参数进行微调可以防止解决方案停留在较差的局部极小值。
3) 微调
网络权值的微调对测试数据产生了更好的分类性能。
首先,我们执行前馈传递,计算所有层的激活。接下来,对于输出层,我们设置
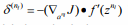
其中∇J=θ(I-P)和I是输入标签,P是条件概率的向量。对于层l = nl-1, nl-2, …, 3, 2,我们设置
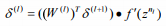
然后计算所需的偏导数:
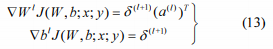
这里W、b和a与(9)和(10)中所述相同。最后,我们应用有限内存Broyden-Fletcher-Goldfarb-Shanno(L-BFGS)最小化算法来最小化总成本函数。
4) Soflmax回归分类
Softmax分类器是一种广义logistic回归,其中类标签可以取多个值[25][26]。对于训练集{(x(1),y(1)), (x(2),y(2)), …, (x(m),y(m))},其中y(i)∈{1, 2, …,k}是类的数。对于给定的测试输入X,假设估计概率p(y=jlx)或j={1, 2, …,k}的每个值,其中k是类的数目,即类标签接受k个不同可能值的概率的估计。因此,假设输出一个k维向量,给出k个估计概率。
softmax回归使用的成本函数如下所示:
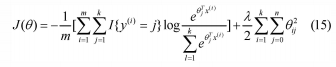
其中,I{·}是指示符函数,因此J{true statement}=1和J{false statement}=0。
对于任何λ>0,代价函数J(θ)现在是严格凸的,并且保证有唯一解。Hessian现在是可逆的,因为J(θ)是凸的,因此L-BFGS收敛到全局最小值。
四、 实施
在Matlab中实现了该模型。模型的声学数据通过传感器和Nl的DAQ从空气压缩机获得,其规格为:
•气压范围:0-500 Ib/m2,0-35 Kg/cm2
•感应电机:5 HP,415V,5安培,3相,50赫兹,1440转/分
•压力开关:类型:PR-15,量程:lOO-213 PSI,7-15Kg/cm2
所构建的模块在6个故障条件下进行了测试,包括健康状态和每个故障对应的100个数据集。故障如下:
•健康
•进水阀(UV)泄漏故障:由于进水阀损坏而发生,直接影响压力波动。
•泄漏出口阀(LOV)故障:在出口阀损坏时发生,导致在要求的压力水平下,储气罐的填充时间消耗增加。
•止回阀(NRV)故障:当气泵和压缩气罐之间的阀门损坏时发生。这可能导致驱动电机故障,因为启动应力增加。
•皮带座与空压机之间的皮带跑偏故障。这导致整个压缩机的声发射增加。
•轴承故障:轴承磨损时发生。这会导致热量、压力和金属与金属的接触增加,从而导致曲轴和连杆变形。
A、 特征提取
从预先记录的wav文件中提取出健康和故障的特征,即时域、频域和小波域。在时域中,我们计算了上述七个统计参数。在频域中,共计算出64个特征。对于小波域,我们从前面提到的Morlet小波分析中提取了7个特征,从DWT分析中提取了9个特征。
B、 支持向量机
以径向基函数为核,采用多类支持向量机对数据进行分类。通过多次迭代训练,得到盒约束C和sigma等参数的最优值。采用最小二乘法作为求解支持向量机对偶问题的优化方法。
C、 马氏距离
只有当每个类的训练样本数大于特征数时,该方法才有效。因此,在80和87特征的情况下,给出了90个训练实例。在这种情况下,因为没有参数可以改变,所以实现非常简单。
D、 稀疏自动编码器
我们使用堆叠式自动编码器作为无监督学习演算法,以取得良好的特徵。通过高斯分布N(0,0.01)随机初始化各层的权值,并将偏差初始化为零。通过多次迭代训练,得到各层参数如Beta、权重衰减参数、稀疏度参数和潜在单元数的最优值。采用贪婪分层训练。我们用Mark Schmidt的minFunc[27]代替Matlab的fminunc进行最小化算法(L-BFGS)。minFunc是一个Matlab函数,用于解决问题,minFunc比fminunc需要更少的函数求值来收敛。此外,它可以用更大数量的变量优化问题(fminunc被限制为几千个变量),并使用对几种常见的功能病态具有鲁棒性的行搜索。
从第二层叠加的自动编码器激活,然后与训练标签一起给软最大分类器。最后,梯度反向传播以微调权重。通过验证数据验证模型。
五、 结果
我们使用不同的输入向量集来训练模型。用于训练模型的输入向量的不同组合如表一所示。这里所示的精度是通过多次迭代的平均精度得到的。

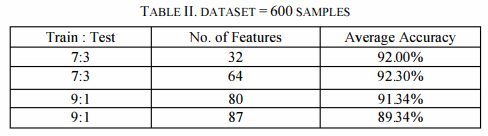
基于马氏距离的分类器是最简单、最快的分类器。它的实现非常简单,结果是在瞬间计算的,即非常快,因为它只涉及数据点之间的距离计算。这里不涉及学习,如支持向量机和稀疏自动编码器的情况。存在一个约束,即训练样本的数目必须大于特征的数目。
从某种意义上说,这不是一个很大的限制,因为它是自然预期,以避免过度拟合,训练样本大小应大于特征大小。最大准确率为92.30%。所得结果列于表二。
支持向量机的性能也很好。与序贯最小优化方法相比,最小二乘法在求解对偶问题时所用的时间相对较少。通过分别在20到210和0.5到10之间改变C和sigma,我们可以获得93%的最大分类准确率。结果列于表三。
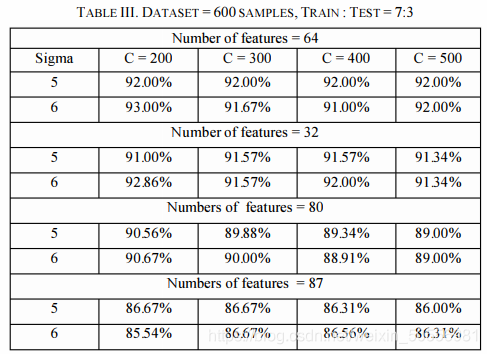
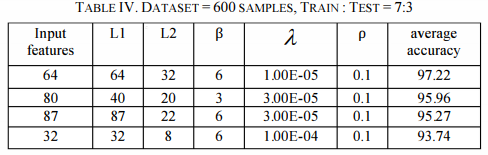
稀疏自编码器的性能优于SVM和Mahalanobis距离分类器,准确率达97.22%。它不仅比支持向量机更精确,而且训练w.r.t.速度更快。稀疏自动编码器的精度可归因于对特征的无监督学习,与原始特征集相比,高阶特征以更好的形式呈现为特征。结果见表四。
六、 结论
在比较了上述算法的结果之后,我们得出结论,每一种算法都有很好的性能。在速度方面,基于马氏距离的分类器是最好的选择,而w.r.t.分类精度方面,稀疏自编码器优于其他分类方法。基于Mahalanobis距离的分类器由于其实现简单,性能良好。总体而言,稀疏自动编码器的性能非常好,可以成功地用于电机和空气压缩机的健康监测和故障诊断。根据我们的经验,必须注意的是稀疏自动编码器是相对难以实现的。
本文来自互联网用户投稿,文章观点仅代表作者本人,不代表本站立场,不承担相关法律责任。如若转载,请注明出处。 如若内容造成侵权/违法违规/事实不符,请点击【内容举报】进行投诉反馈!