【Sarsa&Q-learning】表格型强化学习方法
文章目录
- 1. 项目准备
- 1.1. 问题导入
- 1.2. 环境介绍
- 2. SARSA算法
- 2.1. 算法简介
- 2.2. 算法伪码
- 2.3. 算法实现
- (1) 前期准备
- (2) 构建智能体
- (3) 训练与测试
- 3. Q-learning算法
- 3.1. 算法简介
- 3.2. 算法伪码
- 3.3. 算法实现
- (1) 前期准备
- (2) 构建智能体
- (3) 训练与测试
- 4. 实验结论
- 写在最后
1. 项目准备
1.1. 问题导入
Sarsa算法和Q-learning算法是两种基于表格的经典强化学习方法,本文将对比探究这两种方法在解决悬崖行走(Cliff Walking)问题时的表现。
1.2. 环境介绍
本次实验所用的训练环境为gym库的“悬崖行走”(CliffWalking-v0)环境。

如上图所示,该问题需要智能体从起点S点出发,到达终点G,同时避免掉进悬崖(cliff)。智能体每走一步就有-1分的惩罚,掉进悬崖会有−100分的惩罚,但游戏不会结束,智能体会回到出发点,然后游戏继续,直到智能体到达重点结束游戏。
2. SARSA算法
2.1. 算法简介
-
SARSA全称是state-action-reward-state'-action',目的是学习特定的state下,特定action的价值Q,最终建立和优化一个Q表格,以state为行,action为列,根据与环境交互得到的reward来更新Q表格,更新公式为:
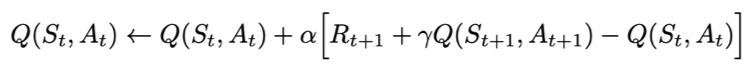
-
SARSA在训练中为了更好的探索环境,采用
ε-greedy方式来训练,有一定概率随机选择动作输出。
2.2. 算法伪码

2.3. 算法实现
(1) 前期准备
- 导入模块
import numpy as np
import gym
- 设置超参数
TRAIN_EPOCHS = 500 # 训练轮数
LOG_GAP = 50 # 日志打印间隔LEARNING_RATE = 0.1 # 学习率
GAMMA = 0.95 # 奖励衰减因子
EPSILON = 0.1 # 随机选取动作的概率MODEL_PATH = "./sarsa.npy" # Q表格保存路径
(2) 构建智能体
class SarsaAgent(object):def __init__(self, obs_dim, act_dim, learning_rate=0.01,gamma=0.9, epsilon=0.1):self.act_dim = act_dim # 动作维度,即可选动作数self.lr = learning_rate # 学习率self.gamma = gamma # reward衰减因子self.epsilon = epsilon # 随机选取动作的概率self.Q = np.zeros((obs_dim, act_dim)) # Q表格# 依据输入的状态,采样输出的动作值,包含探索def sample(self, obs):if np.random.uniform(0, 1) < self.epsilon:return np.random.choice(self.act_dim) # 随机探索选取动作else: # 根据table的Q值选动作return self.predict(obs) # 根据表格的Q值选动作# 依据输入的观察值,预测输出的动作值def predict(self, obs):Q_list = self.Q[obs, :]maxQ = np.max(Q_list)act_list = np.where(Q_list == maxQ)[0] # 找出最大Q值对应的动作return np.random.choice(act_list) # 随机选取一个动作# 更新Q-Table的学习方法def learn(self, obs, action, reward, next_obs, next_act, done):'''【On-Policy】obs:交互前的状态,即s[t];action:本次交互选择的动作,即a[t];reward:本次动作获得的奖励,即r;next_obs:本次交互后的状态,即s[t+1];next_act:根据当前Q表格,针对next_obs会选择的动作,即a[t+1];done:episode是否结束;'''current_Q = self.Q[obs, action] # 当前的Q值if done: # 如果没有下一个状态了,即当前episode已结束target_Q = reward # 目标值就是本次动作的奖励值else: # 否则采用SARSA的公式获取目标值target_Q = reward + self.gamma * self.Q[next_obs, next_act]self.Q[obs, action] += self.lr * (target_Q - current_Q)# 保存Q表格的数据到文件def save(self, path):np.save(path, self.Q)print("\033[1;32m Save data into file: `%s`. \033[0m" % path)# 从文件中读取数据到Q表格def restore(self, path):self.Q = np.load(path)print("\033[1;33m Load data from file: `%s`. \033[0m" % path)
(3) 训练与测试
# run_episode()是agent在一个episode中训练学习的函数,
# 它使用agent.sample()与环境交互,使用agent.learn()训练Q表格
def run_episode(env, agent, render=False):done, total_steps, total_reward = False, 0, 0obs = env.reset() # 重置环境,开始新的episodeaction = agent.sample(obs) # 根据状态选择动作while not done:next_obs, reward, done, _ = env.step(action) # 与环境进行一个交互next_act = agent.sample(next_obs) # 根据状态选取动作agent.learn(obs, action, reward, next_obs, next_act, done) # 学习obs, action = next_obs, next_act # 记录新的状态和动作total_reward += rewardtotal_steps += 1if render: # 如果需要渲染一帧图形env.render()return total_reward, total_steps# test_episode()是agent在一个episode中测试效果的函数,
# 需要评估agent能在一个episode中拿到多少奖励total_reward
def test_episode(env, agent, render=False):agent.restore(MODEL_PATH) # 读取训练好的模型参数done, total_reward = False, 0obs = env.reset() # 重置环境,开始新的episodewhile not done:action = agent.predict(obs) # 根据状态预测动作next_obs, reward, done, _ = env.step(action) # 与环境进行一个交互total_reward += rewardobs = next_obsif render: # 如果需要渲染一帧图形env.render()return total_reward
env = gym.make("CliffWalking-v0") # 创建悬崖环境agent = SarsaAgent(env.observation_space.n, # 状态的数量env.action_space.n, # 动作的种类数learning_rate=LEARNING_RATE, # 学习率gamma=GAMMA, # 奖励衰减因子epsilon=EPSILON, # 随机选取动作的概率
) # 创建SARSA智能体for ep in range(TRAIN_EPOCHS + 1):ep_reward, ep_steps = run_episode(env, agent, False)if ep % LOG_GAP == 0: # 定期输出一次分数print("Episode: %3d; Steps: %3d; Reward: %.1f" %(ep, ep_steps, ep_reward))agent.save(MODEL_PATH) # 保存模型参数(Q表格)
test_reward = test_episode(env, agent, False) # 测试模型
print("【Eval】\t Reward: %.1f" % test_reward)
实验结果如下(Reward值越大,说明学习效果越好):
Episode: 0; Steps: 857; Reward: -2144.0Episode: 50; Steps: 33; Reward: -33.0Episode: 100; Steps: 30; Reward: -129.0Episode: 150; Steps: 44; Reward: -44.0Episode: 200; Steps: 15; Reward: -15.0Episode: 250; Steps: 19; Reward: -118.0Episode: 300; Steps: 26; Reward: -125.0Episode: 350; Steps: 19; Reward: -19.0Episode: 400; Steps: 17; Reward: -17.0Episode: 450; Steps: 22; Reward: -22.0Episode: 500; Steps: 19; Reward: -19.0【Eval】 Reward: -15.0
3. Q-learning算法
3.1. 算法简介
-
Q-learning也是采用Q表格的方式存储Q值(状态动作价值),决策部分与SARSA是一样的,采用ε-greedy方式增加探索。 -
Q-learning跟SARSA不一样的地方是更新Q表格的方式。
- SARSA是on-policy的更新方式,先做出动作再更新。
- Q-learning是off-policy的更新方式,更新learn()时无需获取下一步实际做出的动作next_action,并假设下一步动作是取最大Q值的动作。
- Q-learning的更新公式为:
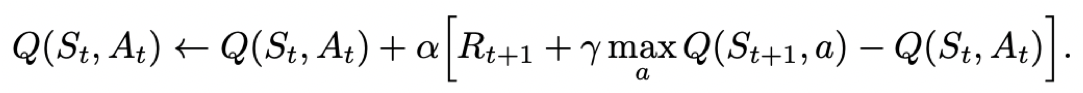
3.2. 算法伪码

3.3. 算法实现
(1) 前期准备
- 导入模块
import numpy as np
import gym
- 设置超参数
TRAIN_EPOCHS = 500 # 训练轮数
LOG_GAP = 50 # 日志打印间隔LEARNING_RATE = 0.1 # 学习率
GAMMA = 0.95 # 奖励衰减因子
EPSILON = 0.1 # 随机选取动作的概率MODEL_PATH = "./q_learning.npy" # Q表格保存路径
(2) 构建智能体
class QLearningAgent(object):def __init__(self, obs_dim, act_dim, learning_rate=0.01,gamma=0.9, epsilon=0.1):self.act_dim = act_dim # 动作维度,即可选动作数self.lr = learning_rate # 学习率self.gamma = gamma # 奖励衰减因子self.epsilon = epsilon # 随机选取动作的概率self.Q = np.zeros((obs_dim, act_dim)) # Q表格# 依据输入的状态,采样输出的动作值,包含探索def sample(self, obs):if np.random.uniform(0, 1) < self.epsilon:return np.random.choice(self.act_dim) # 随机探索选取动作else: # 根据table的Q值选动作return self.predict(obs) # 根据表格的Q值选动作# 依据输入的观察值,预测输出的动作值def predict(self, obs):Q_list = self.Q[obs, :]maxQ = np.max(Q_list)act_list = np.where(Q_list == maxQ)[0] # 找出最大Q值对应的动作return np.random.choice(act_list) # 随机选取一个动作# 更新Q-Table的学习方法def learn(self, obs, action, reward, next_obs, done):'''【Off-Policy】obs:交互前的状态,即s[t];action:本次交互选择的动作,即a[t];reward:本次动作获得的奖励,即r;next_obs:本次交互后的状态,即s[t+1];done:episode是否结束;'''cur_Q = self.Q[obs, action]if done:target_Q = rewardelse:target_Q = reward + self.gamma * np.max(self.Q[next_obs, :])self.Q[obs, action] += self.lr * (target_Q - cur_Q) # 更新表格# 保存Q表格的数据到文件def save(self, path):np.save(path, self.Q)print("\033[1;32m Save data into file: `%s`. \033[0m" % path)# 从文件中读取数据到Q表格def restore(self, path):self.Q = np.load(path)print("\033[1;33m Load data from file: `%s`. \033[0m" % path)
(3) 训练与测试
# run_episode()是agent在一个episode中训练学习的函数,
# 它使用agent.sample()与环境交互,使用agent.learn()训练Q表格
def run_episode(env, agent, render=False):done, total_steps, total_reward = False, 0, 0obs = env.reset() # 重开一局,重置环境while not done:action = agent.sample(obs) # 根据状态选择动作next_obs, reward, done, _ = env.step(action) # 与环境进行一次交互agent.learn(obs, action, reward, next_obs, done) # 学习obs = next_obs # 记录新的状态total_reward += rewardtotal_steps += 1if render: # 如果需要渲染一帧图形env.render()return total_reward, total_steps# test_episode()是agent在一个episode中测试效果的函数,
# 需要评估agent能在一个episode中拿到多少奖励total_reward
def test_episode(env, agent, render=False):agent.restore(MODEL_PATH) # 读取训练好的模型参数done, total_reward = False, 0obs = env.reset() # 重开一局,重置环境while not done:action = agent.predict(obs) # 根据状态选取动作next_obs, reward, done, _ = env.step(action) # 与环境进行一次交互total_reward += rewardobs = next_obs # 记录新的状态if render:env.render()return total_reward
env = gym.make("CliffWalking-v0") # 创建悬崖环境agent = QLearningAgent(env.observation_space.n, # 状态维度env.action_space.n, # 动作维度learning_rate=LEARNING_RATE, # 学习率gamma=GAMMA, # 奖励衰减因子epsilon=EPSILON, # 随机选取动作的概率
) # 创建Q-learning智能体for ep in range(TRAIN_EPOCHS + 1):ep_reward, ep_steps = run_episode(env, agent, False)if ep % LOG_GAP == 0: # 定期输出一次分数print("Episode: %3d; Steps: %3d; Reward: %.1f" %(ep, ep_steps, ep_reward))agent.save(MODEL_PATH) # 保存模型参数(Q表格)
test_reward = test_episode(env, agent, False) # 测试模型
print("【Eval】\t Reward: %.1f" % test_reward)
实验结果如下(Reward值越大,说明学习效果越好):
Episode: 0; Steps: 519; Reward: -1608.0Episode: 50; Steps: 20; Reward: -20.0Episode: 100; Steps: 21; Reward: -21.0Episode: 150; Steps: 47; Reward: -146.0Episode: 200; Steps: 18; Reward: -18.0Episode: 250; Steps: 30; Reward: -228.0Episode: 300; Steps: 20; Reward: -20.0Episode: 350; Steps: 13; Reward: -13.0Episode: 400; Steps: 17; Reward: -17.0Episode: 450; Steps: 14; Reward: -14.0Episode: 500; Steps: 50; Reward: -248.0【Eval】 Reward: -13.0
4. 实验结论
在解决悬崖行走问题的过程中,我们发现:
- Q-learning对环境的探索比较激进胆大,更倾向于最优路线
- SARSA对环境的探索就比较谨慎胆小,更倾向于安全路线

写在最后
- 如果您发现项目存在问题,或者如果您有更好的建议,欢迎在下方评论区中留言讨论~
- 这是本项目的链接:实验项目 - AI Studio,点击
fork可直接在AI Studio运行~- 这是我的个人主页:个人主页 - AI Studio,来AI Studio互粉吧,等你哦~
- 【友链滴滴】欢迎大家随时访问我的个人博客~
本文来自互联网用户投稿,文章观点仅代表作者本人,不代表本站立场,不承担相关法律责任。如若转载,请注明出处。 如若内容造成侵权/违法违规/事实不符,请点击【内容举报】进行投诉反馈!