Python金融数据分析_2_使用pandas和numpy进行数据处理
Pandas入门
Pandas(Python Data Analysis Library)由AQR Capital Management 于2008年4月开发,并于2009年底开源出来。现在绝大部分的金融数据分析工作,都是基于pandas进行的。
Pandas的核心包括:
1、一维数组Series和二维数组DataFrame
2、可直接读取数据库文件、包括本地excel格式数据
3、兼容各类金融分析算法,并直接对数据做处理
Pandas适合处理多种类型的数据:
- 具有不同数据类型的表格数据,如SQL表或Excel电子表格
- 有序或无序(不固定频率)的时间序列数据
- 带有行和列标签的任意矩阵数据
- 任何其他形式的观测/统计数据集
Pandas 可以用于处理绝大多数金融,统计,社会科学和许多工程领域的典型问题。
Series 基础
# Series 是带有标签的一维数组(带有标签的list)
# 可以保存任何数据类型(整数、字符串、浮点数、Python对象等)
# 轴标签统称为索引import pandas as pd# 记录持仓数量
trade_volume = [1100,500,400,2000]
stock = ["平安银行","万科A","上汽集团","贵州茅台" ]trade_volume_series = pd.Series(trade_volume)
trade_volume_series = pd.Series(trade_volume,index=stock)
trade_volume_series_2 = pd.Series([1100,500,400,2000],index=["平安银行","万科A","上汽集团","贵州茅台" ])
代码运行结果如下:



# Series = list + dictholding_position = {"平安银行":100,"万科A":200}
代码运行结果如下:

# 常数构建Series# 每只股票都要买 100手
buy_stock_series = pd.Series(100,index=["平安银行","万科A","上汽集团","贵州茅台"]) 代码运行结果如下:

# 公司A的财务数据
# Seriesincome_sheet = pd.Series([5000,10000,300],index=["净利润","总收入","利息支出"])# 通过顺序、位置提取数据
income_sheet[0]# 通过索引 提取数据
income_sheet["利息支出"]a = ["总收入","利息支出"]
income_sheet[a]
income_sheet[["总收入","利息支出"]]# 通过 顺序切片 提取数据
#[0:2]=[0,1]
income_sheet[0:2]# 通过 索引切片 提取数据
income_sheet[["净利润":"利息支出"]]# 通过 布尔值 提取数据
income_sheet_2 = pd.Series([5000,100000,500,300,10000,None],index=["净利润","总收入","利息支出","所得税总支出","毛利润","固定资产成本"])
# 剔除数据为None的项目
income_sheet_2[income_sheet_2.notnull()]
# 数值>5000的会计科目
income_sheet_2[income_sheet_2>5000]
# 数值<=5000的会计科目
income_sheet_2[income_sheet_2<=5000]代码运行结果如下:




income_sheet_2 = pd.Series([5000,100000,500,300,10000,None],index=["净利润","总收入","利息支出","所得税总支出","毛利润","固定资产成本"])# 查看头部数据
income_sheet_2.head()# 查看尾部数据
income_sheet_2.tail()
income_sheet_2[-5:]代码运行结果如下:


# 重新定义索引income_sheet_new = income_sheet_2.reindex(["净利润","总收入","利息支出","所得税总支出","毛利润","管理费用"])# 数据处理
# 数据来源于多个数据库,对同一个数据,命名方式不一样
# 净利润 = netProfit/net_profit/NetP代码运行如下:

# 删除 drops1 = trade_sheet_new.drop("管理费用")代码运行结果如下:

DataFrame
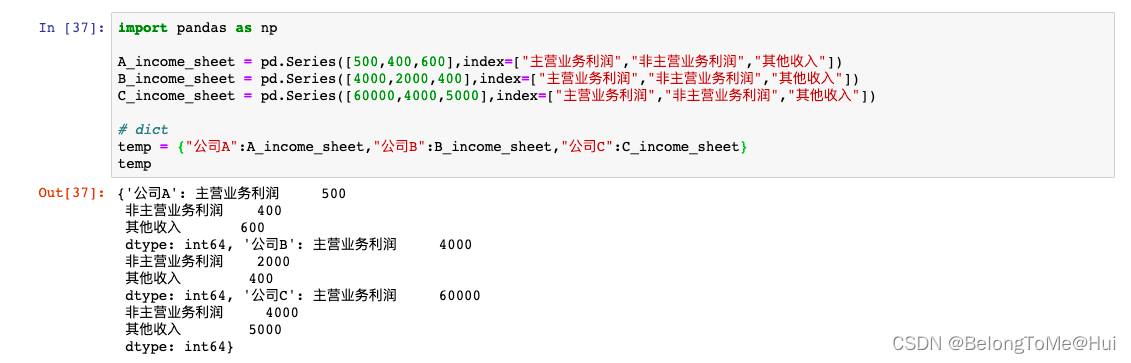
# “二维数组”DataFrame:是一个表格型的数据结构,包含一组有序的列,其列的值类型可以是数值、字符串、布尔值。# DataFrame中的数据以一个或多个二维块存放,不是列表、字典或一维数组结构。# DataFrame 是多个Series的组合。import pandas as pdA_income_sheet = pd.Series([500,400,600],index=["主营业务利润","非主营业务利润","其他收入"])
B_income_sheet = pd.Series([4000,2000,400],index=["主营业务利润","非主营业务利润","其他收入"])
C_income_sheet = pd.Series([60000,4000,5000],index=["主营业务利润","非主营业务利润","其他收入"])# dict
temp ={"公司A":A_income_sheet,"公司B":B_income_sheet,"公司C":C_income_sheet}# 创建DataFrame
df = pd.DataFrame(temp)代码运行结果如下:

# 顺序 提取数据
df.iloc[] # 行顺序,列顺序,中间以逗号分开df.iloc[0,1]代码运行结果如下:

# 索引 提取数据
df.loc[] # 行索引,列索引,中间用逗号分开df.loc["主营业务利润","公司A"]
df.loc["主营业务利润", :]代码运行结果如下:

# 转置,行和列之间对换df1 = df.T# 金融数据使用较多,行的索引 是日期,列的 属性代码运行结果如下:

# 增加、修改数值a = [200,500,3000]df1.loc[:,"管理费用"] = a代码运行结果如下:


# 修改数据df1.iloc[0,0] = 450
代码运行结果如下:

# 删除数据
# dropdf1.drop(index=["公司A"])
df1.drop(columns = ["其他收入"])代码运行结果如下:

# 排序数据
df1.sort_values(by=["非主营业务利润"],ascending=False) # 降序代码运行结果如下:

本文来自互联网用户投稿,文章观点仅代表作者本人,不代表本站立场,不承担相关法律责任。如若转载,请注明出处。 如若内容造成侵权/违法违规/事实不符,请点击【内容举报】进行投诉反馈!