Apache Griffin 开源的数据质量分析工具
文章目录
- 一 简介
- 二 架构
- Apache Griffin具备的能力
- Apache Griffin处理数据的方式
- Apache Griffin架构图
- Apache Griffin的工作流
- 三 环境部署
- 1,部署jdk版本
- 2,部署mysql版本
- 3,部署hadoop版本
- 4,部署hive版本
- 5,部署Spark版本
- 6,部署Livy版本
- 7,部署Elasticsearch5版本
- 8,部署Zookeeper
- 四 使用实例
- 基于Apache Griffin Hive数据库源数据计算
- 基于Apache Griffin Kafka源数据计算
- 五 源码分析
- 1,任务调度源码
- 2,livy任务提交spark
- 3,measure引擎计算
- 3.1 Hadoop
- 3.2 Spark
- 3.2 measuer源码
- 五 技术栈
- 六 问题
- 1,Apache Giffin目前的数据源是支持HIVE,TXT,文件,avro文件和实时数据源kafka,mysql和其他关系型数据库的扩展需要自己进行扩展
- 2,Apache Griffin进行Mesausre生成之后,会形成Spark大数据执行规则模板,shu的最终提交是交给了Spark执行,需要懂Spark进行扩展
- 3,Apache Griffin中的源码中,只有针对于接口层的数据使用的是Spring Boot,measure关于Spark定时任务的代码为scala 语言,扩展的时候需要在measure中进行扩展,需要了解一下对应的scala脚本
- 4,将对应的measuer.jar包put到hadoop中的/griffin/目录下,es中的metric指标任然没有数据。(已解决)
一 简介
apache Griffin是一个开源的大数据数据质量解决方案,它支持批处理和流模式两种数据质量检测方式,可以从不同维度(比如离线任务执行完毕后检查源端和目标端的数据数量是否一致、源表的数据空值数量等)度量数据资产,从而提升数据的准确度、可信度。
官方网站的介绍:Big Data Quality Solution For Batch and Streaming 官方介绍:http://griffin.apache.org/#about_page
二 架构
Apache Griffin具备的能力
引入官方文档

意思就是Apache Griffn具备提供明确的数据质量的定义域,这个通常覆盖了大多数数据质量的问题,同时能够支持用户自定义数据质量的标准,通过扩展DSL(Apache Griffn定义),用户能够自定义扩展自己的数据定义功能
Apache Griffin处理数据的方式
官方文档

1,对于数据质量的定义,用户可以通过Apache Griffin UI功能,对于他们关注的数据进行质量定义,例如准确性,完整性,及时性等
2,数据指标计算,Apache Griffin基于数据质量的维度定义,从流模式(kafka模型),批处理(定时功能)的方式抽取元数据进行计算,
3,数据质量结果落盘,数据质量报告作为度量将被逐出指定的目标。
4,apache Griffin提供了易于在ApacheGriffin平台上提供任何新的数据质量要求并编写综合逻辑以定义其数据质量的插件扩展。
Apache Griffin架构图
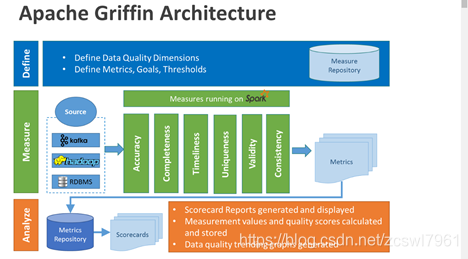
各个部分的主要职能:
- Define:主要负责定义数据质量统计的维度,比如数据质量统计的时间跨度、统计的目标(源端和目标端的数据数量是否一致,数据源里某一字段的非空的数量、不重复值的数量、最大值、最小值、top5的值数量等
- Measure:主要负责执行统计任务,生成统计结果
- Analyze:主要负责保存与展示统计结果
Apache Griffin的元数据来源:kafka,hadoop,RDBMS(关系型数据库),
Apache Griffin的运行指标模型:基于Spark
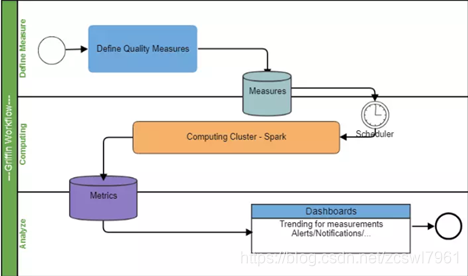
Apache Griffin的工作流
1,注册数据,把想要检测数据质量的数据源注册到griffin。
2,配置度量模型,可以从数据质量维度来定义模型,如:精确度、完整性、及时性、唯一性等。
3,配置定时任务提交spark集群,定时检查数据。
4,在门户界面上查看指标,分析数据质量校验结果。
三 环境部署
1,部署jdk版本
步骤略(jdk版本要求1.8以上)
2,部署mysql版本
步骤略
3,部署hadoop版本
(1)下载hadoop版本 :https://mirrors.tuna.tsinghua.edu.cn/apache/hadoop/core/ 2.7.7版本
(2)上传到/opt/hadoop,没有hadoop目录可以自己创建 mkdir /opt/hadoop(也可以自行创建其他目录)
tar hadoop-2.7.7.tar.gz
vi /etc/profile
追加Hadoop目录
export HADOOP_HOME=/opt/hadoop/hadoop-2.7.7
export PATH=$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATH
source /etc/profile
追加hadoop的jdk环境变量‘
cd $HADOOP_HOME/etc/hadoop
vi hadoop-env.sh
在文件中追加JDK环境变量
export JAVA_HOME=/usr/local/jdk(实际自己的jdk部署目录)
编辑core-site.xml文件
cd $HADOOP_HOME/etc/hadoop/conf
vi core-site.xml
fs.default.name hdfs://localhost:9000
编辑hdfs-site.xml文件
dfs.name.dir /usr/hadoop/hdfs/name namenode上存储hdfs名字空间元数据 dfs.data.dir /usr/hadoop/hdfs/data datanode上数据块的物理存储位置 dfs.replication 1
配置mapred-site.xml,刚开始安装的时候文件名是mapred-site.xml.template,重命名为mapred-site.xml
mapreduce.framework.name yarn
配置yarn-site.xml
yarn.nodemanager.aux-services mapreduce_shuffle
4,部署hive版本
参考 :https://www.cnblogs.com/caoxb/p/11333741.html
5,部署Spark版本
参考: https://blog.csdn.net/k393393/article/details/92440892
6,部署Livy版本
参考:添加链接描述
7,部署Elasticsearch5版本
参考:https://blog.csdn.net/fiery_heart/article/details/85265585
8,部署Zookeeper
基于kafka的时候需要
四 使用实例
基于Apache Griffin Hive数据库源数据计算
http://griffin.apache.org/docs/quickstart.html
本地化举例演示:
(1)访问Apache Griffin可视化界面数据
(2)设置指标模型界面
(3)配置源数据和目标数据,以及对应的指标模型结果数据

(4)按照步骤,配置引擎结果

(5),配置任务的执行Job
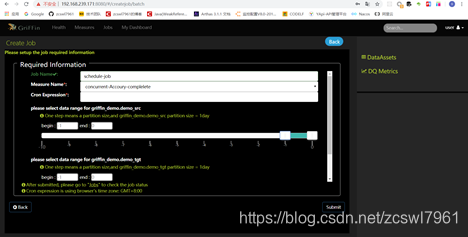
(6),点击保存
设置Job任务:
(1)job任务配置页面设置
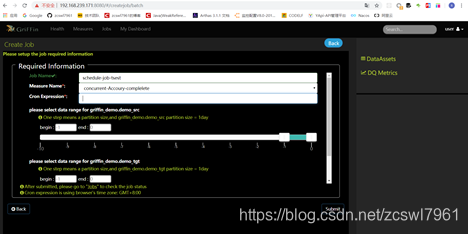
基于Apache Griffin Kafka源数据计算
http://griffin.apache.org/docs/usecases.html (待分析,这个我们不会使用流数据源处理)
五 源码分析
https://github.com/apache/griffin 基于griffin- 0.4.0-rc0版本
个人github:https://github.com/zcswl7961/apache-griffin-expand
源码模块:
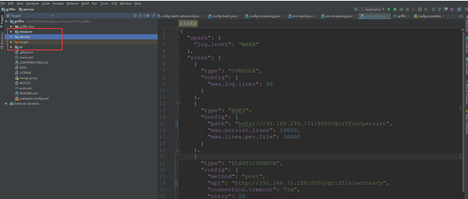
service:spring boot代码,做web配置 和监控界面服务端数据
measure: scala 代码,Spark定时任务代码
ui:前端界面
数据依赖配置模块:
application.properties
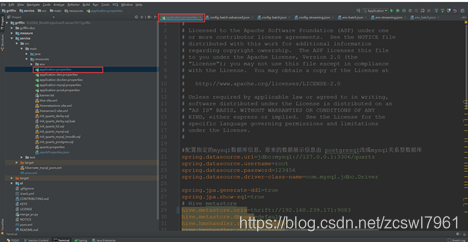
env:流和批处理
1,任务调度源码
(1)首先是由前端进行作业任务保存之后,调用JobController的 POST /jobs方法,判断对应的是为批处理还是流处理作业任务,如果为批处理,创建BatchJob数据,然后保存本地的quartz的job
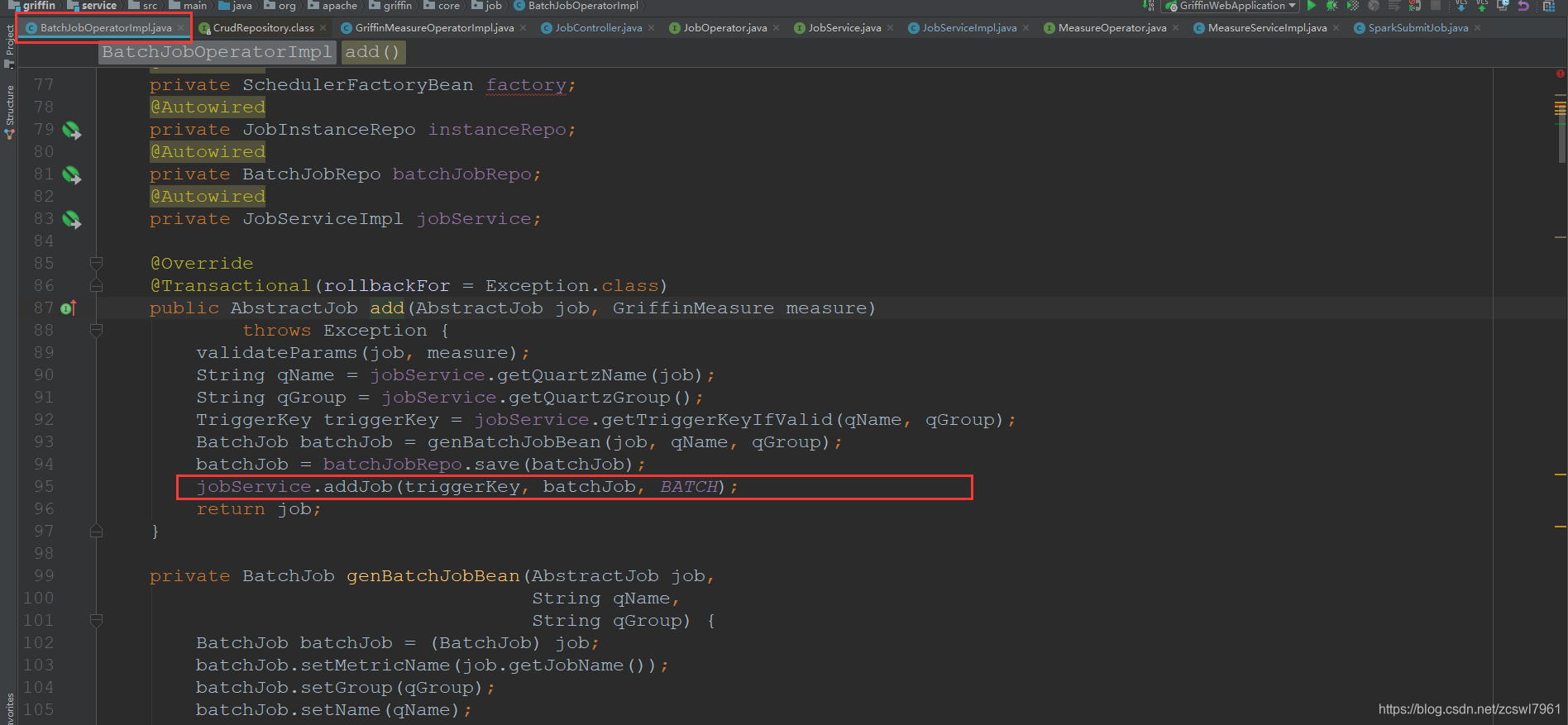
同时执行jobService.addJob(triggerKey, batchJob, BATCH);方法,创建定时任务,执行SparkSubmitJob job作业
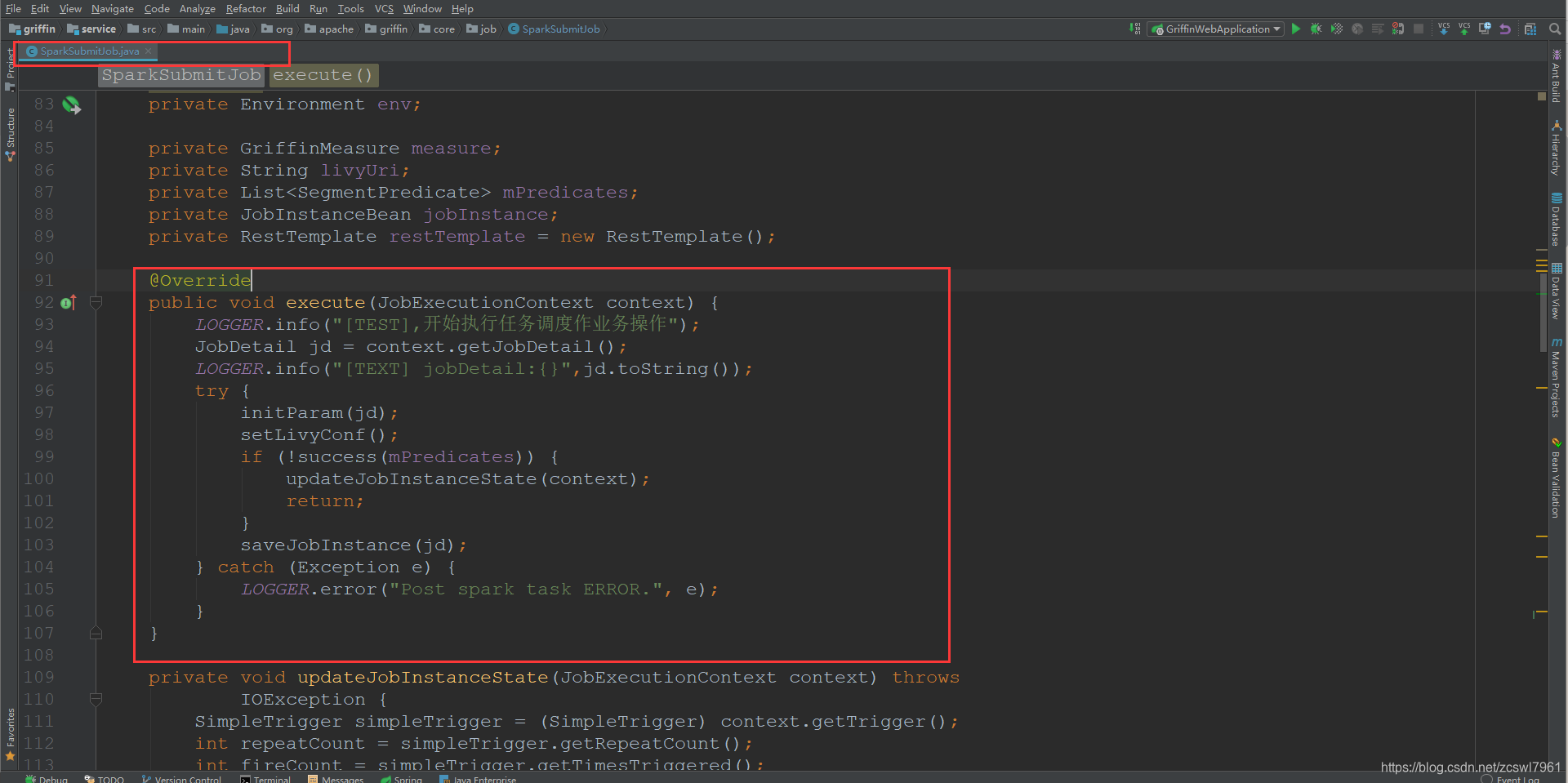
initParam(jd);初始化相关参数信息,包括从JobDetail中获取measure,jobInstance,获取livy.url的配置信息,
setLivyConf(); 设置livy任务提交的相关参数赋值给livyConfMap实例,主要是对于sparkProperties.json文件的解析,同时追加了一个raw参数
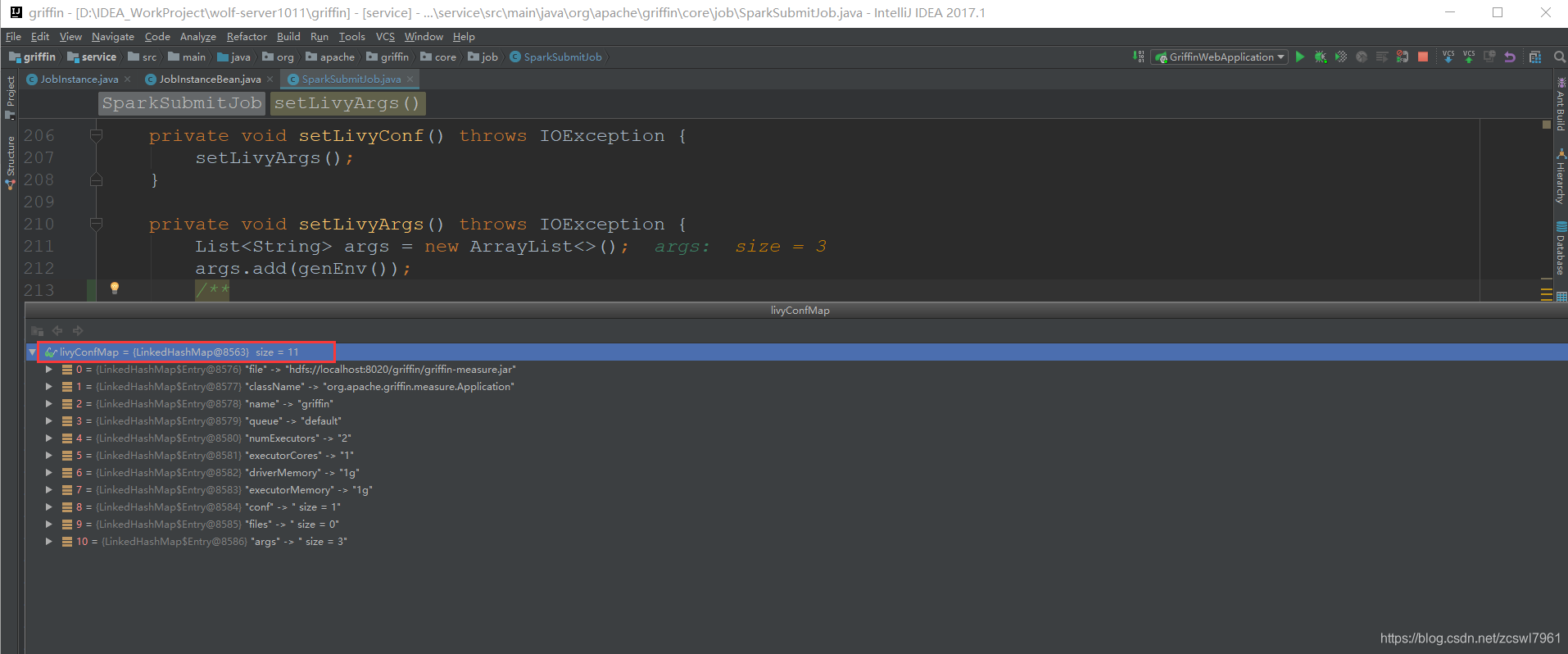
saveJobInstance(jd);通过livy提交spark任务,同时将当前的任务执行历史存入到本地quartz库中,进入到saveJobInstance方法中,首先执行post2Livy方法 ,首先设置了livy任务提交的HttpEntity
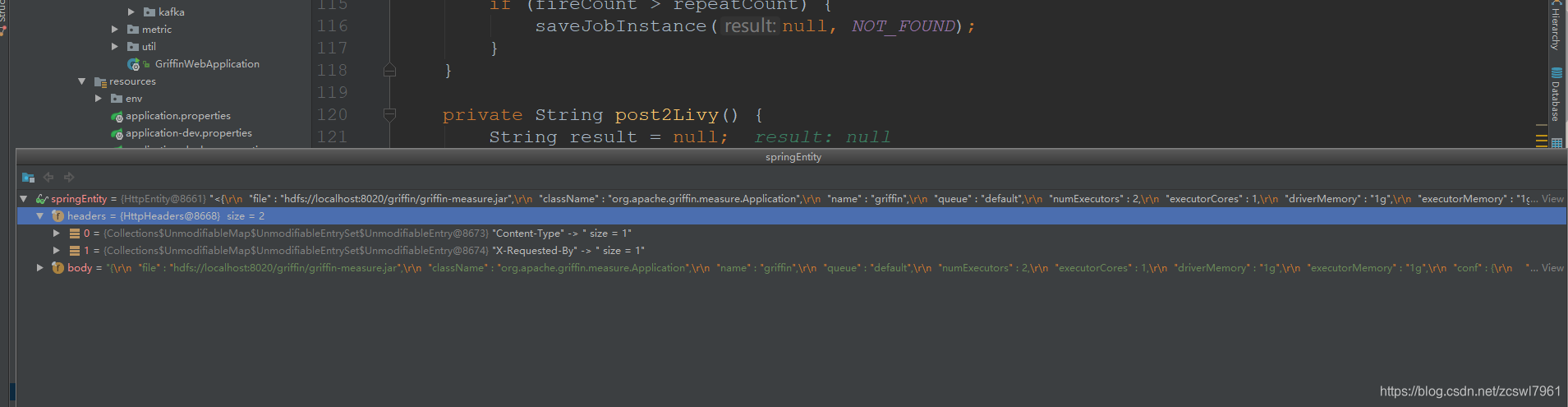
最终的livy任务提交中,调用的接口是 url:http://192.168.239.171:8998/batches ,body信息为:
{"file":"hdfs://localhost:8020/griffin/griffin-measure.jar","className":"org.apache.griffin.measure.Application","name":"griffin","queue":"default","numExecutors":2,"executorCores":1,"driverMemory":"1g","executorMemory":"1g","conf":{"spark.yarn.dist.files":"hdfs://localhost:8020/home/spark_conf/hive-site.xml"},"files":[],"args":["{"spark" : {"log.level" : "WARN"},"sinks" : [ {"type" : "CONSOLE","config" : {"max.log.lines" : 10}}, {"type" : "HDFS","config" : {"path" : "hdfs://localhost:8020/griffin/persist","max.persist.lines" : 10000,"max.lines.per.file" : 10000}}, {"type" : "ELASTICSEARCH","config" : {"method" : "post","api" : "http://localhost:9200/griffin/accuracy","connection.timeout" : "1m","retry" : 10}} ],"griffin.checkpoint" : [ ]
}","{"measure.type" : "griffin","id" : 3355,"name" : "schedule-job-zcg","owner" : "test","description" : "test","deleted" : false,"timestamp" : 1569477360000,"dq.type" : "ACCURACY","sinks" : [ "ELASTICSEARCH", "HDFS" ],"process.type" : "BATCH","data.sources" : [ {"id" : 3358,"name" : "source","connectors" : [ {"id" : 3359,"name" : "source1569548839003","type" : "HIVE","version" : "1.2","predicates" : [ ],"data.unit" : "1day","data.time.zone" : "","config" : {"database" : "griffin_demo","table.name" : "demo_src","where" : "dt='20190927' AND hour = '09'"}} ],"baseline" : false}, {"id" : 3360,"name" : "target","connectors" : [ {"id" : 3361,"name" : "target1569548846717","type" : "HIVE","version" : "1.2","predicates" : [ ],"data.unit" : "1day","data.time.zone" : "","config" : {"database" : "griffin_demo","table.name" : "demo_tgt","where" : "dt='20190927' AND hour = '09'"}} ],"baseline" : false} ],"evaluate.rule" : {"id" : 3356,"rules" : [ {"id" : 3357,"rule" : "source.id=target.id","dsl.type" : "griffin-dsl","dq.type" : "ACCURACY","out.dataframe.name" : "accuracy"} ]},"measure.type" : "griffin"
}","raw,raw"]
}
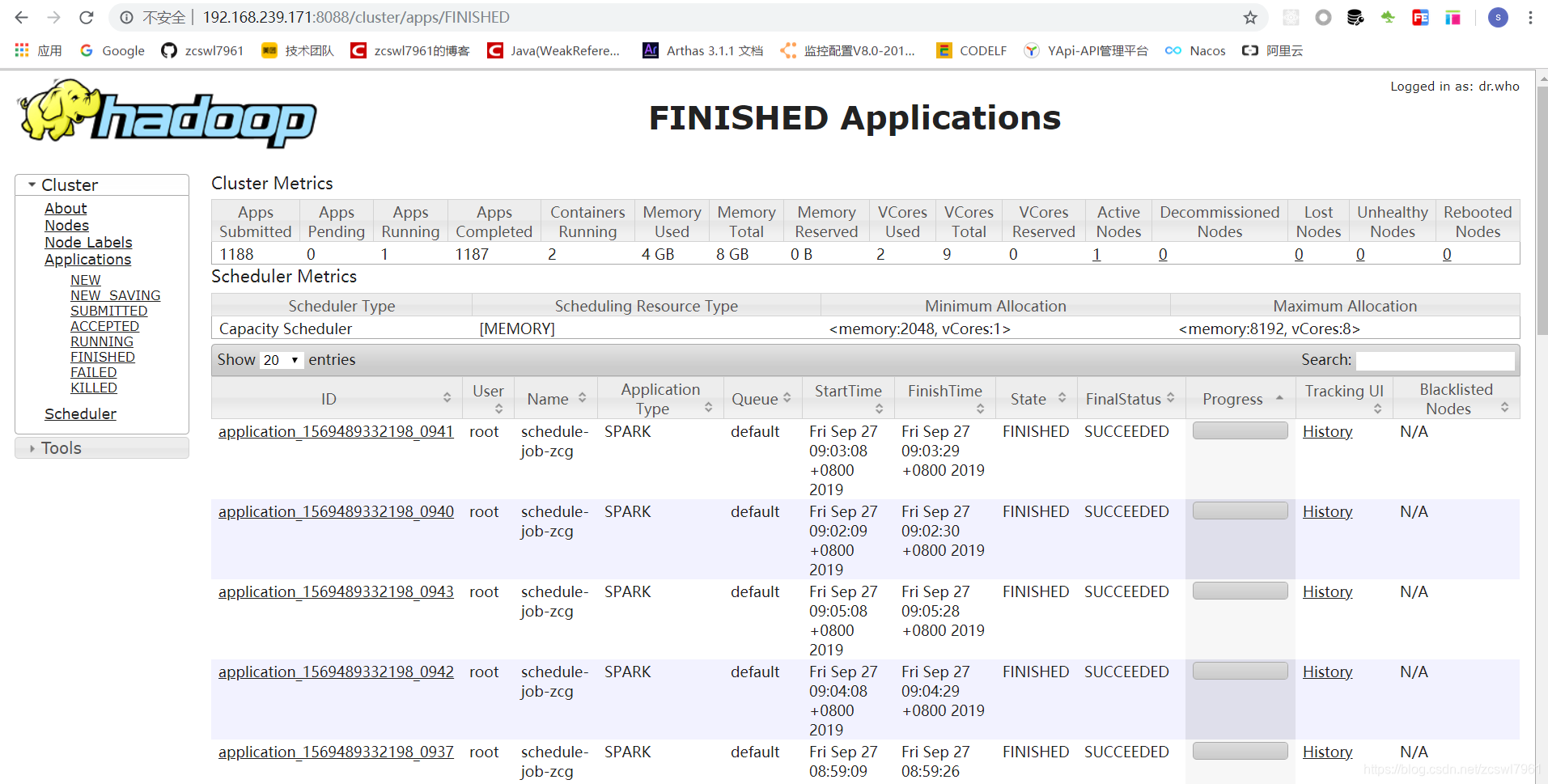
2,livy任务提交spark
livy接收到service提交的任务之后,提交到spark,spark接受的到任务之后,进行执行,首先是获取hadoop中配置的fileName:hdfs://localhost:8020/griffin/griffin-measure.jar,通过获取对应的className进行执行任务调度
3,measure引擎计算
首先measuer计算是依赖于measuer.jar ,同时spark通过访问hadoop中的上传的measuer.jar进行执行,这个配置是在griffin源码中的sparkProperties.json的配置信息中。

在去讲解源码之前,首先大致介绍一下Spark和Hadoop
3.1 Hadoop
首先,Hadoop是为了解决大数据存储和大数据分析的一套开源的分布式基础架构,
Hadoop有两大核心:HDFS和MapReducer
- HDFS(Hadoop Distributed File
System)是可扩展、容错、高性能的分布式文件系统,异步复制,一次写入多次读取,主要负责存储。 - MapReduce 为分布式计算框架,包含map(映射)和 reduce(归约)过程,负责在 HDFS 上进行计算。
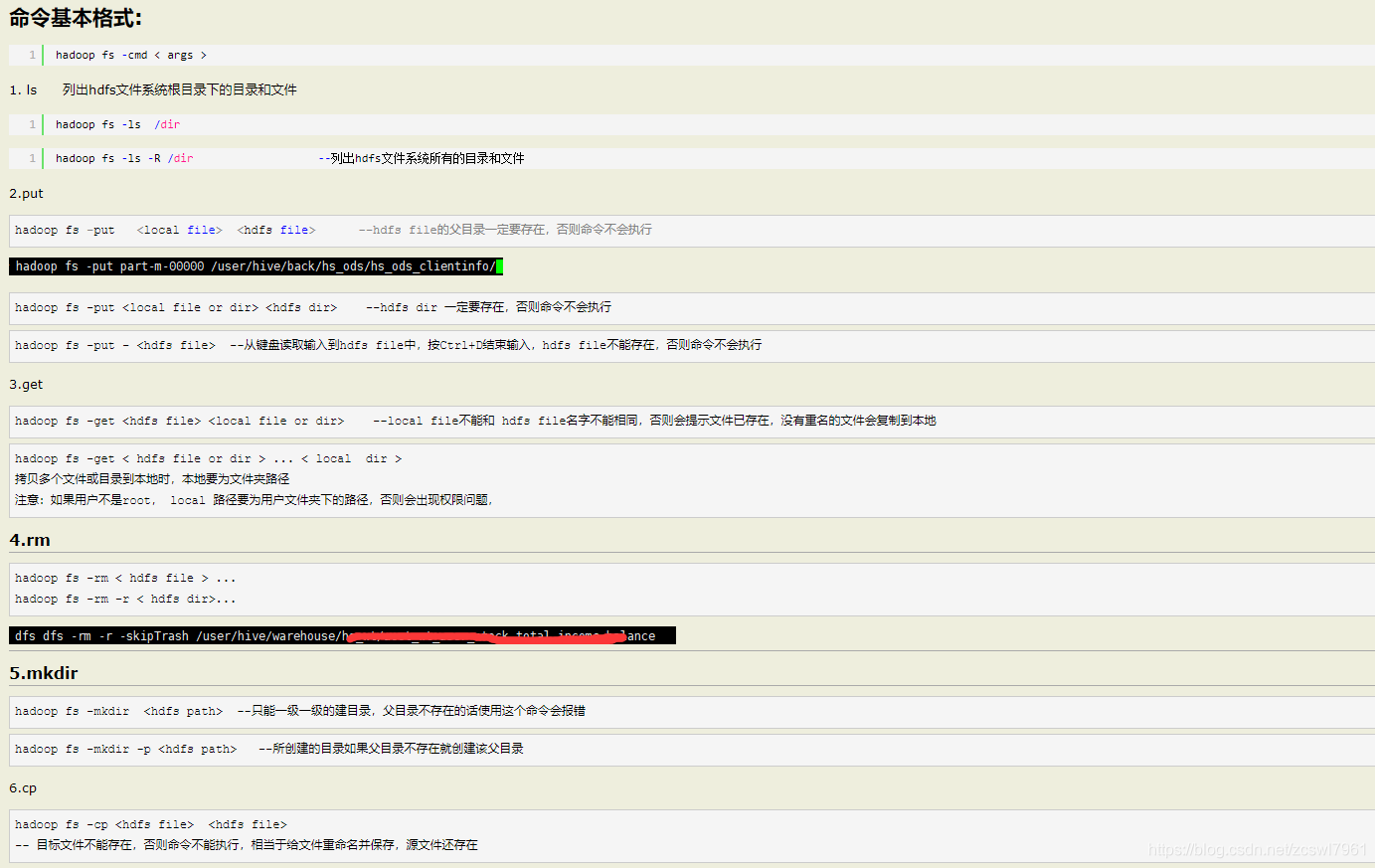
HDFS 就像一个传统的分级文件系统,可以进行创建、删除、移动或重命名文件或文件夹等操作,与 Linux 文件系统类似。
基础的文件操作命令:
MapReduce:MapReduce 是 Google 提出的一个软件架构,用于大规模数据集(大于1TB)的并行运算。概念“Map(映射)”和“Reduce(归纳)”以及它们的主要思想,都是从函数式编程语言借来的,还有从矢量编程语言借来的特性。
当前的软件实现是指定一个 Map(映射)函数,用来把一组键值对映射成一组新的键值对,指定并发的 Reduce(归纳)函数,用来保证所有映射的键值对中的每一个共享相同的键组。

mapReduce的执行示例:
MapReduce的执行示例
3.2 Spark
Spark是用于大规模数据处理的统一分析引擎。
Spark是MapReduce的替代方案,而且兼容HDFS、Hive,可融入Hadoop的生态系统,以弥补MapReduce的不足。
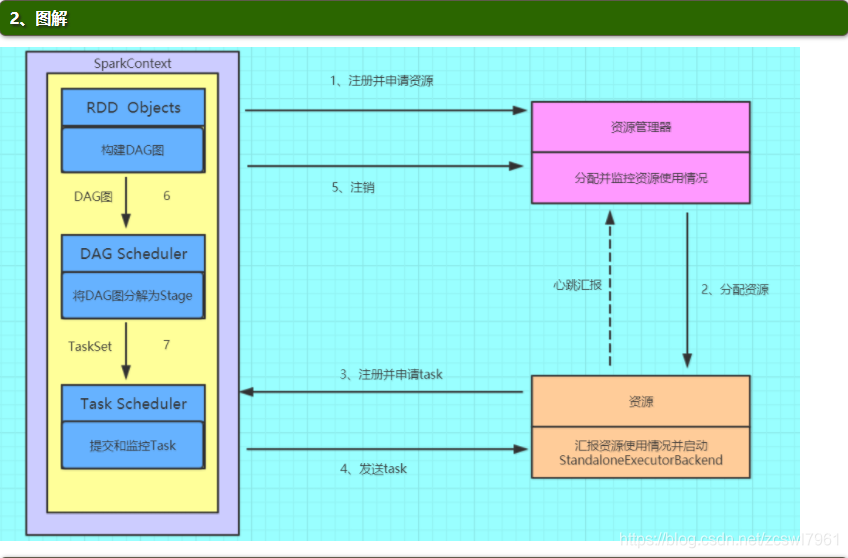
Spark的基本运行流程:
- (1)构建Spark
Application的运行环境(启动SparkContext),SparkContext向资源管理器(可以是Standalone、Mesos或YARN)注册并申请运行Executor资源; - (2)资源管理器分配Executor资源并启动StandaloneExecutorBackend,Executor运行情况将随着心跳发送到资源管理器上;
- (3)SparkContext构建成DAG图,将DAG图分解成Stage,并把Taskset发送给Task
Scheduler。Executor向SparkContext申请Task - (4)Task Scheduler将Task发放给Executor运行同时SparkContext将应用程序代码发放给Executor。
- (5)Task在Executor上运行,运行完毕释放所有资源。
3.2 measuer源码
进入到meauser模块中,执行Application.scala类,首先是获取启动类传递的两个参数args
val envParamFile = args(0)
val dqParamFile = args(1)
envParamFile:表示对应环境配置信息,包括对应的spark的日志级别,数据源的输出目的地,
{//对应的spark的日志级别"spark":{"log.level":"WARN"},//数据源的输出目的地"sinks":[{"type":"CONSOLE","config":{"max.log.lines":10}},{"type":"HDFS","config":{"path":"hdfs://localhost:8020/griffin/persist","max.persist.lines":10000,"max.lines.per.file":10000}},{"type":"ELASTICSEARCH","config":{"method":"post","api":"http://localhost:9200/griffin/accuracy","connection.timeout":"1m","retry":10}}],"griffin.checkpoint":[]
}
dbParamFile:表示对应的执行任务的数据配置,包括对应的数据源的配置,计算规则信息
{"measure.type":"griffin","id":3355,"name":"schedule-job-zcg","owner":"test","description":"test","deleted":false,"timestamp":1569492180000,"dq.type":"ACCURACY","sinks":["ELASTICSEARCH","HDFS"],"process.type":"BATCH","data.sources":[{"id":3358,"name":"source","connectors":[{"id":3359,"name":"source1569548839003","type":"HIVE","version":"1.2","predicates":[],"data.unit":"1day","data.time.zone":"","config":{"database":"griffin_demo","table.name":"demo_src","where":"dt='20190927' AND hour = '09'"}}],"baseline":false},{"id":3360,"name":"target","connectors":[{"id":3361,"name":"target1569548846717","type":"HIVE","version":"1.2","predicates":[],"data.unit":"1day","data.time.zone":"","config":{"database":"griffin_demo","table.name":"demo_tgt","where":"dt='20190927' AND hour = '09'"}}],"baseline":false}],"evaluate.rule":{"id":3356,"rules":[{"id":3357,"rule":"source.id=target.id","dsl.type":"griffin-dsl","dq.type":"ACCURACY","out.dataframe.name":"accuracy"}]}
}
Application.scala核心代码:
object Application extends Loggable {def main(args: Array[String]): Unit = {// info(args.toString)val args = new Array[String](2)// 测试代码args(0) = "{\n \"spark\":{\n \"log.level\":\"WARN\",\n \"config\":{\n \"spark" +".master\":\"local[*]\"\n }\n },\n \"sinks\":[\n {\n \"type\":\"CONSOLE\",\n " +" \"config\":{\n \"max.log.lines\":10\n }\n },\n {\n " +"\"type\":\"HDFS\",\n \"config\":{\n " +"\"path\":\"hdfs://localhost:8020/griffin/batch/persist\",\n \"max.persist" +".lines\":10000,\n \"max.lines.per.file\":10000\n }\n },\n {\n " +"\"type\":\"ELASTICSEARCH\",\n \"config\":{\n \"method\":\"post\",\n " +"\"api\":\"http://192.168.239.171:9200/griffin/accuracy\",\n \"connection" +".timeout\":\"1m\",\n \"retry\":10\n }\n }\n ],\n \"griffin" +".checkpoint\":[\n\n ]\n}";args(1) = "{\n \"name\":\"accu_batch\",\n \"process.type\":\"batch\",\n \"data" +".sources\":[\n {\n \"name\":\"source\",\n \"baseline\":true,\n " +"\"connectors\":[\n {\n \"type\":\"avro\",\n \"version\":\"1.7\"," +"\n \"config\":{\n \"file.name\":\"src/test/resources/users_info_src" +".avro\"\n }\n }\n ]\n },\n {\n \"name\":\"target\",\n " +" \"connectors\":[\n {\n \"type\":\"avro\",\n \"version\":\"1.7\"," +"\n \"config\":{\n \"file.name\":\"src/test/resources/users_info_target" +".avro\"\n }\n }\n ]\n }\n ],\n \"evaluate.rule\":{\n " +"\"rules\":[\n {\n \"dsl.type\":\"griffin-dsl\",\n \"dq" +".type\":\"accuracy\",\n \"out.dataframe.name\":\"accu\",\n \"rule\":\"source" +".user_id = target.user_id AND upper(source.first_name) = upper(target.first_name) AND " +"source.last_name = target.last_name AND source.address = target.address AND source.email =" +" target.email AND source.phone = target.phone AND source.post_code = target.post_code\"\n " +" }\n ]\n },\n \"sinks\":[\n \"CONSOLE\",\n \"ELASTICSEARCH\"\n ]\n}";if (args.length < 2) {error("Usage: class ")sys.exit(-1)}val envParamFile = args(0)val dqParamFile = args(1)info(envParamFile)info(dqParamFile)// read param files// args(0)信息,将其转换成对应的EnvConfig对象,val envParam = readParamFile[EnvConfig](envParamFile) match {case Success(p) => pcase Failure(ex) =>error(ex.getMessage, ex)sys.exit(-2)}// args(2)信息,将其转换成对应的DQConfig配置信息val dqParam = readParamFile[DQConfig](dqParamFile) match {case Success(p) => pcase Failure(ex) =>error(ex.getMessage, ex)sys.exit(-2)}val allParam: GriffinConfig = GriffinConfig(envParam, dqParam)// choose process// 选择对应的进程对象进行执行,这里面的就是BatchDQAppval procType = ProcessType(allParam.getDqConfig.getProcType)val dqApp: DQApp = procType match {case BatchProcessType => BatchDQApp(allParam)case StreamingProcessType => StreamingDQApp(allParam)case _ =>error(s"${procType} is unsupported process type!")sys.exit(-4)}startup// (1)初始化griffin定时任务执行环境// 具体代码见下个代码块,主要逻辑是创建sparkSession和注册griffin自定义的spark udf// dq app initdqApp.init match {case Success(_) =>info("process init success")case Failure(ex) =>error(s"process init error: ${ex.getMessage}", ex)shutdownsys.exit(-5)}// dq app run// (2)执行对应的定时任务作业,这里的处理就是批处理任务,val success = dqApp.run match {case Success(result) =>info("process run result: " + (if (result) "success" else "failed"))resultcase Failure(ex) =>error(s"process run error: ${ex.getMessage}", ex)if (dqApp.retryable) {throw ex} else {shutdownsys.exit(-5)}}// dq app enddqApp.close match {case Success(_) =>info("process end success")case Failure(ex) =>error(s"process end error: ${ex.getMessage}", ex)shutdownsys.exit(-5)}shutdownif (!success) {sys.exit(-5)}}private def readParamFile[T <: Param](file: String)(implicit m : ClassTag[T]): Try[T] = {val paramReader = ParamReaderFactory.getParamReader(file)paramReader.readConfig[T]}private def startup(): Unit = {}private def shutdown(): Unit = {}}
首先进入到**(1)**中 初始化griffiin定时任务执行环境源码,进入到BatchDQApp的init方法
def init: Try[_] = Try {// build spark 2.0+ application contextval conf = new SparkConf().setAppName(metricName)conf.setAll(sparkParam.getConfig)conf.set("spark.sql.crossJoin.enabled", "true")sparkSession = SparkSession.builder().config(conf).enableHiveSupport().getOrCreate()sparkSession.sparkContext.setLogLevel(sparkParam.getLogLevel)sqlContext = sparkSession.sqlContext// register udfGriffinUDFAgent.register(sqlContext)}
该段代码主要的功能是根据dqParam中的name属性,创建对应的SparkSession,同时获取对应的SqlContext,
SparkSession是spark2.0引入的新概念,SparkSession为用户提供了统一的切入点,来让用户学习spark的各项功能。
在最后的代码中
GriffinUDFAgent.register(sqlContext)
注册udf,udf是hive中支持的自定义函数,其中udf即最基本的自定义函数,类似to_char,to_data等,其中还有udaf和udtf两种类型:
- UDF(User-Defined-Function),即最基本的自定义函数,类似to_char,to_date等
- UDAF(User- Defined Aggregation Funcation),用户自定义聚合函数,类似在group
by之后使用的sum,avg等 - UDTF(User-Defined Table-Generating
Functions),用户自定义生成函数,有点像stream里面的flatMap
源码中,通过GriffinUDFs注册了基础的udf函数,index_of,matches,reg_replace,通过GriffinUDAggFs注册了udaf函数(这部分可以进行扩展)
def register(sqlContext: SQLContext): Unit = {sqlContext.udf.register("index_of", indexOf _)sqlContext.udf.register("matches", matches _)sqlContext.udf.register("reg_replace", regReplace _)}
object GriffinUDAggFs {def register(sqlContext: SQLContext): Unit = {}}
然后,进入到执行对应的定时任务作业 ,这一部分是spark计算的核心代码所在
def run: Try[Boolean] = Try {// start timeval startTime = new Date().getTimeval measureTime = getMeasureTimeval contextId = ContextId(measureTime)// 根据配置获取数据源 即dq对应的data.sources配置,// get data sourcesval dataSources = DataSourceFactory.getDataSources(sparkSession, null, dqParam.getDataSources)// 数据源初始化操作dataSources.foreach(_.init)// 创建griffin执行上下文// create dq contextval dqContext: DQContext = DQContext(contextId, metricName, dataSources, sinkParams, BatchProcessType)(sparkSession)// 根据对应的sink的配置,输出结果到console和elasticsearch中// start idval applicationId = sparkSession.sparkContext.applicationIddqContext.getSink().start(applicationId)// 创建数据检测对比job信息// build jobval dqJob = DQJobBuilder.buildDQJob(dqContext, dqParam.getEvaluateRule)// dq job executeval result = dqJob.execute(dqContext)// end timeval endTime = new Date().getTimedqContext.getSink().log(endTime, s"process using time: ${endTime - startTime} ms")// clean contextdqContext.clean()// finishdqContext.getSink().finish()result}
run方法中,主要的几大功能
- 1,根据对应的配置args(1)获取数据源,即args(1)DQConfig配置中的data.sources配置
- 2,数据源的初始化
- 3,创建Girffin执行的上下文
- 4,根据对应的skin配置,输出结果到console和elasticsearch中(配置中)
- 5,创建数据检测对应的job信息
- 6,执行任务作业
首先进入到根据配置获取数据源,传递的参数有sparkSession,dqParam.getDataSources即dq对应的data.sources配置
def getDataSources(sparkSession: SparkSession,ssc: StreamingContext,dataSources: Seq[DataSourceParam]): Seq[DataSource] = {dataSources.zipWithIndex.flatMap { pair =>val (param, index) = pairgetDataSource(sparkSession, ssc, param, index)}}
getDataSource()方法中,第一个参数是对应的SparkSession,第二个参数是StreamingContext(这里是null),第三个参数是数据源配置,第四个参数是index
private def getDataSource(sparkSession: SparkSession,ssc: StreamingContext,dataSourceParam: DataSourceParam,index: Int): Option[DataSource] = {val name = dataSourceParam.getNameval connectorParams = dataSourceParam.getConnectorsval timestampStorage = TimestampStorage()// for streaming data cacheval streamingCacheClientOpt = StreamingCacheClientFactory.getClientOpt(sparkSession.sqlContext, dataSourceParam.getCheckpointOpt, name, index, timestampStorage)val dataConnectors: Seq[DataConnector] = connectorParams.flatMap { connectorParam =>DataConnectorFactory.getDataConnector(sparkSession, ssc, connectorParam,timestampStorage, streamingCacheClientOpt) match {case Success(connector) => Some(connector)case _ => None}}Some(DataSource(name, dataSourceParam, dataConnectors, streamingCacheClientOpt))}
调用DataConnectorFactory.getDataConnector函数获取对应的DataConnector对象
第一个参数是SparkSession
第二个参数在batch模式下是null
第三个参数为dbparam配置中data.sources中的connectors参数
第四个参数为时间戳
第五个参数为streaming data cache,为null
def getDataConnector(sparkSession: SparkSession,ssc: StreamingContext,dcParam: DataConnectorParam,tmstCache: TimestampStorage,streamingCacheClientOpt: Option[StreamingCacheClient]): Try[DataConnector] = {val conType = dcParam.getTypeval version = dcParam.getVersionTry {// 数据源映射conType match {case HiveRegex() => HiveBatchDataConnector(sparkSession, dcParam, tmstCache)case AvroRegex() => AvroBatchDataConnector(sparkSession, dcParam, tmstCache)case TextDirRegex() => TextDirBatchDataConnector(sparkSession, dcParam, tmstCache)case CustomRegex() => getCustomConnector(sparkSession, ssc, dcParam, tmstCache, streamingCacheClientOpt)case KafkaRegex() =>getStreamingDataConnector(sparkSession, ssc, dcParam, tmstCache, streamingCacheClientOpt)case _ => throw new Exception("connector creation error!")}}}
最终,我们能看到griffin的meauser默认的数据源配置有以下几种,hive,avro,textDir,kafka等
这里,我们以Hive数据源来分析对应的创建过程,以及数据的执行过程
/*** batch data connector for hive table* 接收三个参数:1,SparkSession 2,connectors配置信息,3,timestampStorage缓存对象*/
case class HiveBatchDataConnector(@transient sparkSession: SparkSession,dcParam: DataConnectorParam,timestampStorage: TimestampStorage) extends BatchDataConnector {//connectors配置信息下的config配置val config = dcParam.getConfig//数据库val Database = "database"//表val TableName = "table.name"val Where = "where"//config配置下的database库val database = config.getString(Database, "default")//config配置下的tableval tableName = config.getString(TableName, "")//config下的where配置信息val whereString = config.getString(Where, "")//关联val concreteTableName = s"${database}.${tableName}"val wheres = whereString.split(",").map(_.trim).filter(_.nonEmpty)//sparkSql执行sql语句,返回对应的DataFrame和TimeRate数据def data(ms: Long): (Option[DataFrame], TimeRange) = {val dfOpt = try {val dtSql = dataSqlinfo(dtSql)val df = sparkSession.sql(dtSql)val dfOpt = Some(df)val preDfOpt = preProcess(dfOpt, ms)preDfOpt} catch {case e: Throwable =>error(s"load hive table ${concreteTableName} fails: ${e.getMessage}", e)None}val tmsts = readTmst(ms)(dfOpt, TimeRange(ms, tmsts))}private def tableExistsSql(): String = {
// s"SHOW TABLES LIKE '${concreteTableName}'" // this is hive sql, but not work for spark sqls"tableName LIKE '${tableName}'"}private def metaDataSql(): String = {s"DESCRIBE ${concreteTableName}"}private def dataSql(): String = {val tableClause = s"SELECT * FROM ${concreteTableName}"if (wheres.length > 0) {val clauses = wheres.map { w =>s"${tableClause} WHERE ${w}"}clauses.mkString(" UNION ALL ")} else tableClause}}HiveBatchDataConnector对象首先是继承了BatchDataConnnector,并且BatchDataConnector继承了DataConnector对象,其中,HiveBatchDataConnector实现了DataConnector对象中的data方法,这个是一个比较重要的方法:
def data(ms: Long): (Option[DataFrame], TimeRange) = {val dfOpt = try {val dtSql = dataSqlinfo(dtSql)val df = sparkSession.sql(dtSql)val dfOpt = Some(df)val preDfOpt = preProcess(dfOpt, ms)preDfOpt} catch {case e: Throwable =>error(s"load hive table ${concreteTableName} fails: ${e.getMessage}", e)None}val tmsts = readTmst(ms)(dfOpt, TimeRange(ms, tmsts))}
首先,获取SparkSql的执行sql语句,通过dataSql方法,然后通过SparkSession执行sql语句,获取对应的DataFrame,同时执行DataConnector方法中的preProcess方法,封装最终的DataFrame
def preProcess(dfOpt: Option[DataFrame], ms: Long): Option[DataFrame] = {// new contextval context = createContext(ms)val timestamp = context.contextId.timestampval suffix = context.contextId.idval dcDfName = dcParam.getDataFrameName("this")try {saveTmst(timestamp) // save timestampdfOpt.flatMap { df =>val (preProcRules, thisTable) =PreProcParamMaker.makePreProcRules(dcParam.getPreProcRules, suffix, dcDfName)// init datacontext.compileTableRegister.registerTable(thisTable)context.runTimeTableRegister.registerTable(thisTable, df)// build jobval preprocJob = DQJobBuilder.buildDQJob(context, preProcRules)// job executepreprocJob.execute(context)// out dataval outDf = context.sparkSession.table(s"`${thisTable}`")// add tmst columnval withTmstDf = outDf.withColumn(ConstantColumns.tmst, lit(timestamp))// clean contextcontext.clean()Some(withTmstDf)}} catch {case e: Throwable =>error(s"pre-process of data connector [${id}] error: ${e.getMessage}", e)None}}
}
关于data方法的执行,我们可以在后面的源码中看到,
最终,我们会根据一系列的配置信息,初始化对应的数据源,接着,
dataSources.foreach(_.init)
执行dataSources的初始化方法,以Hive的DataSource为例,init方法没有具体实现内容
接着,执行
val dqContext: DQContext = DQContext(contextId, metricName, dataSources, sinkParams, BatchProcessType)(sparkSession)
创建griffin的上下文DQContext对象
/*** 每一个spark计算的context唯一的上下文对象数据* dq context: the context of each calculation* unique context id in each calculation* access the same spark session this app created*/
case class DQContext(contextId: ContextId,name: String,dataSources: Seq[DataSource],sinkParams: Seq[SinkParam],procType: ProcessType)(@transient implicit val sparkSession: SparkSession) {val sqlContext: SQLContext = sparkSession.sqlContext//编译val compileTableRegister: CompileTableRegister = CompileTableRegister()//运行环境val runTimeTableRegister: RunTimeTableRegister = RunTimeTableRegister(sqlContext)val dataFrameCache: DataFrameCache = DataFrameCache()val metricWrapper: MetricWrapper = MetricWrapper(name)val writeMode = WriteMode.defaultMode(procType)//数据源名称val dataSourceNames: Seq[String] = {// sort data source names, put baseline data source name to the headval (blOpt, others) = dataSources.foldLeft((None: Option[String], Nil: Seq[String])) { (ret, ds) =>val (opt, seq) = retif (opt.isEmpty && ds.isBaseline) (Some(ds.name), seq) else (opt, seq :+ ds.name)}blOpt match {case Some(bl) => bl +: otherscase _ => others}}dataSourceNames.foreach(name => compileTableRegister.registerTable(name))def getDataSourceName(index: Int): String = {if (dataSourceNames.size > index) dataSourceNames(index) else ""}implicit val encoder = Encoders.STRINGval functionNames: Seq[String] = sparkSession.catalog.listFunctions.map(_.name).collect.toSeq//加载数据val dataSourceTimeRanges = loadDataSources()def loadDataSources(): Map[String, TimeRange] = {dataSources.map { ds =>(ds.name, ds.loadData(this))}.toMap}printTimeRangesprivate val sinkFactory = SinkFactory(sinkParams, name)private val defaultSink: Sink = createSink(contextId.timestamp)def getSink(timestamp: Long): Sink = {if (timestamp == contextId.timestamp) getSink()else createSink(timestamp)}def getSink(): Sink = defaultSinkprivate def createSink(t: Long): Sink = {procType match {case BatchProcessType => sinkFactory.getSinks(t, true)case StreamingProcessType => sinkFactory.getSinks(t, false)}}def cloneDQContext(newContextId: ContextId): DQContext = {DQContext(newContextId, name, dataSources, sinkParams, procType)(sparkSession)}def clean(): Unit = {compileTableRegister.unregisterAllTables()runTimeTableRegister.unregisterAllTables()dataFrameCache.uncacheAllDataFrames()dataFrameCache.clearAllTrashDataFrames()}private def printTimeRanges(): Unit = {if (dataSourceTimeRanges.nonEmpty) {val timeRangesStr = dataSourceTimeRanges.map { pair =>val (name, timeRange) = pairs"${name} -> (${timeRange.begin}, ${timeRange.end}]"}.mkString(", ")println(s"data source timeRanges: ${timeRangesStr}")}}}
创建DQContext对象,传递四个参数
第一个参数为对应的sparkSession
第二个参数为当前执行任务的name信息,也就是dqparam中的name属性
第三个参数为上面获取的数据源配置信息
第四个参数为envparam中配置的sinks配置信息
第五个参数为批处理类型
重点看一下
//加载数据val dataSourceTimeRanges = loadDataSources()
加载数据源中的数据信息,调用DataSource中的loadData()方法,这个时候,我们会看到会执行对应每一个数据源DataConnector实现的data方法,因为我们是以对应的Hive数据源为例,进入到HiveBatchDataConnector类中的data方法,重点研究一下SparkSql的执行逻辑
def preProcess(dfOpt: Option[DataFrame], ms: Long): Option[DataFrame] = {// new context//创建一个新的DQContextval context = createContext(ms)val timestamp = context.contextId.timestampval suffix = context.contextId.idval dcDfName = dcParam.getDataFrameName("this")try {saveTmst(timestamp) // save timestampdfOpt.flatMap { df =>val (preProcRules, thisTable) =PreProcParamMaker.makePreProcRules(dcParam.getPreProcRules, suffix, dcDfName)// init datacontext.compileTableRegister.registerTable(thisTable)context.runTimeTableRegister.registerTable(thisTable, df)// build jobval preprocJob = DQJobBuilder.buildDQJob(context, preProcRules)// job executepreprocJob.execute(context)// out dataval outDf = context.sparkSession.table(s"`${thisTable}`")// add tmst columnval withTmstDf = outDf.withColumn(ConstantColumns.tmst, lit(timestamp))// clean contextcontext.clean()Some(withTmstDf)}} catch {case e: Throwable =>error(s"pre-process of data connector [${id}] error: ${e.getMessage}", e)None}}
}
创建build job信息,进入到
// build job
val preprocJob = DQJobBuilder.buildDQJob(context, preProcRules)
这里源码有个疑惑,在创建DQContext的时候,执行了一次loadDataSources(),内部是创建了一次buildDQJob(),为什么外面又创建了一次??
首先是获取dqparma中的evaluate.rule配置规则,在DQJobBuilder中的buildDQJob方法中,首先是根据dataSource创建 steps
def buildDQJob(context: DQContext, ruleParams: Seq[RuleParam]): DQJob = {// build steps by datasourcesval dsSteps = context.dataSources.flatMap { dataSource =>DQStepBuilder.buildStepOptByDataSourceParam(context, dataSource.dsParam)}// build steps by rules/*** SeqDQStep(List(SparkSqlTransformStep(__missRecords,SELECT `source`.* FROM `source` LEFT JOIN `target` ON coalesce(`source`.`user_id`, '') = coalesce(`target`.`user_id`, '') AND upper(`source`.`first_name`) = upper(`target`.`first_name`) AND coalesce(`source`.`last_name`, '') = coalesce(`target`.`last_name`, '') AND coalesce(`source`.`address`, '') = coalesce(`target`.`address`, '') AND coalesce(`source`.`email`, '') = coalesce(`target`.`email`, '') AND coalesce(`source`.`phone`, '') = coalesce(`target`.`phone`, '') AND coalesce(`source`.`post_code`, '') = coalesce(`target`.`post_code`, '') WHERE (NOT (`source`.`user_id` IS NULL AND `source`.`first_name` IS NULL AND `source`.`last_name` IS NULL AND `source`.`address` IS NULL AND `source`.`email` IS NULL AND `source`.`phone` IS NULL AND `source`.`post_code` IS NULL)) AND (`target`.`user_id` IS NULL AND `target`.`first_name` IS NULL AND `target`.`last_name` IS NULL AND `target`.`address` IS NULL AND `target`.`email` IS NULL AND `target`.`phone` IS NULL AND `target`.`post_code` IS NULL),Map(),true), SparkSqlTransformStep(__missCount,SELECT COUNT(*) AS `miss` FROM `__missRecords`,Map(),false), SparkSqlTransformStep(__totalCount,SELECT COUNT(*) AS `total` FROM `source`,Map(),false), SparkSqlTransformStep(accu,SELECT A.total AS `total`,A.miss AS `miss`,(A.total - A.miss) AS `matched`,coalesce( (A.total - A.miss) / A.total, 1.0) AS `matchedFraction`FROM (SELECT `__totalCount`.`total` AS total,coalesce(`__missCount`.`miss`, 0) AS missFROM `__totalCount` LEFT JOIN `__missCount`) AS A,Map(),false), MetricWriteStep(accu,accu,DefaultFlattenType,None), RecordWriteStep(__missRecords,__missRecords,None,None)))*/val ruleSteps = ruleParams.flatMap { ruleParam =>DQStepBuilder.buildStepOptByRuleParam(context, ruleParam)}// metric flush stepval metricFlushStep = MetricFlushStep()/*** ++ 用于连接两个集合* :+ 用于在集合尾部追加集合* +: 用于在集合头部追加集合*/DQJob(dsSteps ++ ruleSteps :+ metricFlushStep)}
然后再创建rulesteps,调用DQStepBuilder.buildStepOptByRuleParam(context, ruleParam)
def buildStepOptByRuleParam(context: DQContext, ruleParam: RuleParam): Option[DQStep] = {val dslType = ruleParam.getDslTypeval dsNames = context.dataSourceNamesval funcNames = context.functionNamesval dqStepOpt = getRuleParamStepBuilder(dslType, dsNames, funcNames).flatMap(_.buildDQStep(context, ruleParam))dqStepOpt.toSeq.flatMap(_.getNames).foreach(name =>context.compileTableRegister.registerTable(name))dqStepOpt}
首先是创建对应的RuleParamStepBuilder,然后调用buildDQStep方法
def buildDQStep(context: DQContext, param: ParamType): Option[DQStep] = {val steps = buildSteps(context, param) //这个没看懂if (steps.size > 1) Some(SeqDQStep(steps))else if (steps.size == 1) steps.headOptionelse None}
根据griffin官方的含义,这个根据对应的解析器dfs进行结对对应的执行步骤
Apache Girffin DSL涉及详见:
https://github.com/apache/griffin/blob/master/griffin-doc/measure/dsl-guide.md
五 技术栈
Spark :学习参考:https://www.cnblogs.com/qingyunzong/category/1202252.html
Hadoop
Hive
Livy
Quartz
六 问题
1,Apache Giffin目前的数据源是支持HIVE,TXT,文件,avro文件和实时数据源kafka,mysql和其他关系型数据库的扩展需要自己进行扩展
2,Apache Griffin进行Mesausre生成之后,会形成Spark大数据执行规则模板,shu的最终提交是交给了Spark执行,需要懂Spark进行扩展
3,Apache Griffin中的源码中,只有针对于接口层的数据使用的是Spring Boot,measure关于Spark定时任务的代码为scala 语言,扩展的时候需要在measure中进行扩展,需要了解一下对应的scala脚本
4,将对应的measuer.jar包put到hadoop中的/griffin/目录下,es中的metric指标任然没有数据。(已解决)
官方网站上给的两个解决的方法1,service/src/main/resources/env/env_batch.json里的ES配置信息不正确 这个已经修复了 2,执行spark任务的yarn服务器上没有配置ES服务器的hostname,连接异常(这个不太明白)
部署参考
https://blog.csdn.net/github_39577257/article/details/90607081
http://griffin.apache.org/docs/quickstart-cn.html
本文来自互联网用户投稿,文章观点仅代表作者本人,不代表本站立场,不承担相关法律责任。如若转载,请注明出处。 如若内容造成侵权/违法违规/事实不符,请点击【内容举报】进行投诉反馈!