【集成学习】(task1)机器学习中的数学(史上最全)
学习心得
(1)《随机过程》直白的理解就是概率论加上时间维度变成过程,然后在这基础上开始狂算概率论。关于随机过程的其他理解和入门也参考知乎回答——https://www.zhihu.com/question/26694486/answer/349872296。其中很多知识也是强化学习和时间序列分析的基础。
(2)描述随机过程的武器——概率空间、随机变量等;能否研究一个随机过程的关键就是减少问题的维度-这也是物理的核心思想。而达到这个目的的神器有:
1)马尔科夫过程(Markov Processes)—随机过程的精华,即随机过程的每一步的结果最多只与上一步有关,而与其它无关。
2)马尔可夫链(Markov chain)—即用数学语言表述makov过程;如果一个过程是markov过程,这个过程就得到了神简化,你只需要知道第n步是如何与第n-1步相关的,一般由一组条件概率表述,就可以求得整个过程。
(3)随机变量即一元函数,而随机向量是多元函数。
本次学习资源
(1)集成学习——b站视频;机器学习的数学基础——b站视频;
数学推理部分可以参考:b站白板推导和3b1b。
(2)在很多机器学习比赛(如kaggle等),会发现除了深度学习以外的高分模型,无一例外地见到了集成学习和模型融合的身影。所有我们有必要从基础模型的推导以及 sklearn应用过渡到使用集成学习的技术去优化我们的基础模型,使得我们的模型能更好地解决机器学习问题。
文章目录
- 学习心得
- 本次学习资源
- 一、随机过程
- 1.1 随机过程的基本概念
- 1.2 Poisson过程
- (1) 计数过程
- (2)泊松过程
- (3)呼叫泊松流
- (4)泊松过程的汇合和分流
- 1.3 Markov过程(离散时间)
- (1)马尔可夫链及其转移概率矩阵
- (2)C-K方程
- (3)极限分布和平稳条件
- (4)鞅
- (5)高斯过程
- 1.4 随机采样与随机模拟
- 二、高等数学
- 2.1 梯度
- 2.2 雅克比矩阵
- 2.3 黑塞矩阵
- 2.4 多元函数的极值
- 2.5 求带等式约束的优化问题(拉格朗日乘子法)
- 2.6 泰勒公式
- 三、高数代码部分
- 3.1 基于梯度的优化方法--梯度下降法
- 3.2 基于梯度的优化方法--牛顿迭代法
- 牛顿法和梯度下降法的比较
- 四、概率论与数理统计
- 4.1 基础概念回顾
- 五、概率论相关代码
- 5.1 随机模拟:π的估值
- 5.2 电子元件寿命问题
- 5.3 三门问题
- 六、线性代数
- 6.1 向量空间
- 6.2 向量及其内积
- 6.3 向量的范数
- 6.4 矩阵及其秩
- 6.5 矩阵范数
- 6.6 矩阵的秩 齐次线性方程组及其解空间
- 6.7 特征值与特征向量及矩阵的迹
- 6.8 二次型
- 正定二次型与Hesse矩阵(黑赛矩阵)
- 七、作业:最小解发现
- 7.1 实验目的
- 7.2 实验环境
- 7.3 实验内容-第一问
- 7.4 实验内容-第二小问
- 附:学习大纲
- Reference
一、随机过程
1.1 随机过程的基本概念
-
随机变量:随机变量 X X X是定义在样本空间 Ω \Omega Ω上的函数,当x是 X X X的观测值时,存在 Ω \Omega Ω中的 w w w使得 x = X ( w ) x=X(w) x=X(w) 。即解决随机事件能被人利用于建模(符号化了)。分为离散随机变量和连续随机变量。
-
随机向量:随机向量 ( X 1 , X 2 , . . . , X n ) (X_1,X_2,...,X_n) (X1,X2,...,Xn)是定义在样本空间 Ω \Omega Ω上的n元函数,当 ( x 1 , x 2 , . . . , x n ) (x_1,x_2,...,x_n) (x1,x2,...,xn)是 ( X 1 , X 2 , . . . , X n ) (X_1,X_2,...,X_n) (X1,X2,...,Xn)的观测值时,存在w使得 ( x 1 , x 2 , . . . , x n ) = ( X 1 ( w ) , X 2 ( w ) , . . . , X n ( w ) ) (x_1,x_2,...,x_n) = (X_1(w),X_2(w),...,X_n(w)) (x1,x2,...,xn)=(X1(w),X2(w),...,Xn(w)),这时称 ( x 1 , x 2 , . . . , x n ) (x_1,x_2,...,x_n) (x1,x2,...,xn)为 ( X 1 , X 2 , . . . , X n ) (X_1,X_2,...,X_n) (X1,X2,...,Xn)的一次观测或者一次实现。
-
随机过程:设T为 ( − ∞ , + ∞ ) (-\infty,+\infty) (−∞,+∞)的子集,若对每个 t ∈ T t\in T t∈T, X t X_t Xt是随机变量,则称随机变量的集合 { X t ∣ t ∈ T } \{X_t|t\in T \} {Xt∣t∈T}是随机过程。当每个t都有一次观测,那么会形成一条曲线,则称这条曲线为一条轨道或一条轨迹。即不同时间的随机变量的变化过程。
-
有限维分布:对于任何正整数m和【T中互不相同的 t 1 , . . . , t m t_1,...,t_m t1,...,tm】,称 ( X t 1 , . . . , X t m ) (X_{t_1},...,X_{t_m}) (Xt1,...,Xtm)的联合分布为随机过程 { X t ∣ t ∈ T } \{X_t|t\in T \} {Xt∣t∈T}的一个有限维分布;称全体的有限维分布为该随机过程的概率分布。
-
随机过程的同分布:如果随机过程 { X t ∣ t ∈ T } \{X_t|t\in T \} {Xt∣t∈T}与随机过程 { Y t ∣ t ∈ T } \{Y_t|t\in T \} {Yt∣t∈T}有相同的有限维分布,则称他们同分布。
-
随机过程的独立:如果随机过程 { X t ∣ t ∈ T } \{X_t|t\in T \} {Xt∣t∈T}中任意选出来的 ( X t 1 , . . . , X t i ) (X_{t_1},...,X_{t_i}) (Xt1,...,Xti)与从 { Y t ∣ t ∈ T } \{Y_t|t\in T \} {Yt∣t∈T}中选出来的 ( Y s 1 , . . . , Y s j ) (Y_{s_1},...,Y_{s_j}) (Ys1,...,Ysj)是相互独立的,则称两个随机过程独立。(条件严格:时间、维度、独立)
-
随机序列:如果时间集合T是整数,就是一个随机序列(时间序列),记作 X n X_n Xn

PS:X(t)没有花括号,即是一个随机变量(如果加了花括号就是一个随机过程了)。
1.2 Poisson过程
(1) 计数过程
-
计数过程:随机过程 { N ( t ) , t ⩾ 0 } \{N(t), t \geqslant 0\} {N(t),t⩾0} 称为计数过程,如果 N ( t ) N(t) N(t) 表示从 0 到 t t t 时 刻某一特定事件 A A A 发生的次数,它具备以下两个特点:
(1) N ( t ) ⩾ 0 N(t) \geqslant 0 N(t)⩾0 且取值为整数;
(2) 当 s < t ss<t 时 , N ( s ) ⩽ N ( t ) , \quad N(s) \leqslant N(t) ,N(s)⩽N(t)且 N ( t ) − N ( s ) N(t)-N(s) N(t)−N(s) 表示 ( s , t ] (s, t] (s,t] 时间内事件 A A A 发生的 次数。

-
独立增量性:如果在互不相交的时间段内发生事件的个数是相互独立的,则称相应的计数过程 N ( t ) {N(t)} N(t)具有独立增量性。即:对任意的正整数n和 0 ≤ t 1 < t 2 < . . . < t n 0\le t_1
-
平稳增量性:如果在长度相等的时间段内,事件发生的个数的概率分布是相同的,则称相应的计数过程具有平稳增量性。即:对于任意 s > 0 , t 2 > t 1 ≥ 0 s>0,t_2>t_1\ge 0 s>0,t2>t1≥0,随机变量 N ( t 1 + s , t 2 + s ] N(t_1+s,t_2+s] N(t1+s,t2+s]与 N ( t 1 , t 2 ) N(t_1,t_2) N(t1,t2)同分布,其主要的性质与起始点 t 1 , t 2 t_1,t_2 t1,t2无关,与时间间隔有关。
-
拓展思考(PS:学习时间序列分析也会遇到):
(1)严平稳过程:如果随机过程 { X ( t ) , t ∈ T } \{X(t), t \in T\} {X(t),t∈T} 对任意的 t 1 , t 2 , ⋯ , t n ∈ T t_{1}, t_{2}, \cdots, t_{n} \in T t1,t2,⋯,tn∈T 和任意的 h h h
(使得 t i + h ∈ T , i = 1 , 2 , ⋯ , n ) \left.t_{i}+h \in T, i=1,2, \cdots, n\right) ti+h∈T,i=1,2,⋯,n) 有 ( X ( t 1 + h ) , X ( t 2 + h ) , ⋯ , X ( t n + h ) ) \left(X\left(t_{1}+h\right), X\left(t_{2}+h\right), \cdots, X\left(t_{n}+h\right)\right) (X(t1+h),X(t2+h),⋯,X(tn+h)) 与
( X ( t 1 ) , X ( t 2 ) , ⋯ , X ( t n ) ) \left(X\left(t_{1}\right), X\left(t_{2}\right), \cdots, X\left(t_{n}\right)\right) (X(t1),X(t2),⋯,X(tn)) 具有相同的联合分布,记为:
( X ( t 1 + h ) , X ( t 2 + h ) , ⋯ , X ( t n + h ) ) = d ( X ( t 1 ) , X ( t 2 ) , ⋯ , X ( t n ) ) \left(X\left(t_{1}+h\right), X\left(t_{2}+h\right), \cdots, X\left(t_{n}+h\right)\right) \stackrel{\mathrm{d}}{=}\left(X\left(t_{1}\right), X\left(t_{2}\right), \cdots, X\left(t_{n}\right)\right) (X(t1+h),X(t2+h),⋯,X(tn+h))=d(X(t1),X(t2),⋯,X(tn))
则称 { X ( t ) , t ∈ T } \{X(t), t \in T\} {X(t),t∈T} 为严平稳的。
(2)宽平稳过程:如果随机过程 { X ( t ) } \{X(t)\} {X(t)} 的所有二阶矩都存在,并且 E [ X ( t ) ⌋ = μ , E[X(t)\rfloor=\mu, E[X(t)⌋=μ, 协方差函数 γ ( t , s ) \gamma(t, s) γ(t,s) 只与时间差 t − s t-s t−s 有关,则称 { X ( t ) , t ∈ T } \{X(t), t \in T\} {X(t),t∈T} 为宽平稳过程或二阶平稳过程。

(3)独立增量过程:如果对任意 t 1 , t 2 , ⋯ , t n ∈ T , t 1 < t 2 < ⋯ < t n , t_{1}, t_{2}, \cdots, t_{n} \in T, t_{1}
X ( t 1 ) , X ( t 3 ) − X ( t 2 ) , ⋯ , X ( t n ) − X ( t n − 1 ) X\left(t_{1}\right), X\left(t_{3}\right)-X\left(t_{2}\right), \cdots, X\left(t_{n}\right)-X\left(t_{n-1}\right) X(t1),X(t3)−X(t2),⋯,X(tn)−X(tn−1) 是相互独立的,则称 { X ( t ) , t ∈ T } \{X(t), t \in T\} {X(t),t∈T} 是独立增量过程。
如果对任意 t 1 , t 2 , t_{1}, t_{2}, t1,t2, 有 X ( t 1 + h ) − X ( t 1 ) = d X ( t 2 + h ) − X ( t 2 ) , X\left(t_{1}+h\right)-X\left(t_{1}\right) \stackrel{\mathrm{d}}{=} X\left(t_{2}+h\right)-X\left(t_{2}\right), X(t1+h)−X(t1)=dX(t2+h)−X(t2), 则称 { X ( t ) , t ∈ T } \{X(t), t \in T\} {X(t),t∈T} 是平稳增量过程。 兼有独立增量和平稳增量的过程称为平稳独立增量过程。
(2)泊松过程
- 泊松过程(定义一):计数过程 { N ( t ) , t ⩾ 0 } \{N(t), t \geqslant 0\} {N(t),t⩾0} 称为参数为 λ ( λ > 0 ) \lambda(\lambda>0) λ(λ>0) 的 Poisson 过程, 如果
(1) N ( 0 ) = 0 N(0)=0 N(0)=0 ;
(2)过程有独立增量;
(3)在任一长度为 t t t 的时间区间中事件发生的次数服从均值为 λ t \lambda t λt 的 Poisson 分 布,即对一切 s ⩾ 0 , t > 0 , s \geqslant 0, t>0, s⩾0,t>0, 有:
P { N ( t + s ) − N ( s ) = n } = e − λ t ( λ t ) n n ! , n = 0 , 1 , 2 , ⋯ P\{N(t+s)-N(s)=n\}=\mathrm{e}^{-\lambda t} \frac{(\lambda t)^{n}}{n !}, \quad n=0,1,2, \cdots P{N(t+s)−N(s)=n}=e−λtn!(λt)n,n=0,1,2,⋯
由上式可以看出, { N ( t + s ) − N ( s ) = n } \{N(t+s)-N(s)=n\} {N(t+s)−N(s)=n}与起始点s无关,只与时间间隔t有关,因此具有平稳增量性。设 { N ( t ) } \{N(t) \} {N(t)}是强度为 λ \lambda λ的泊松过程,容易计算 E ( N ( t ) ) = λ t E(N(t)) = \lambda t E(N(t))=λt,于是 λ = E ( N ( t ) ) t \lambda = \frac{E(N(t))}{t} λ=tE(N(t))是单位时间内事件发生的次数的平均数(强度)。

为什么实际中有这么多的现象可以用 Poisson 过程来反映呢? 其根据是小概率事件原理。我们在对概率论的学习中已经知道,Bernoulli 试验中每次试验成功的概率很 小,而试验的次数很多时,二项分布会逼近 Poisson 分布。这一想法很自然地推广到随机过程的情况。比如上面提到的事故发生的例子,在很短的时间内发生事故的概率 是很小的,但假如考虑很多个这样很短的时间的连接,事故的发生将会有一个大致稳定的速率,这很类似于 Bernoulli 试验以及二项分布逼近 Poisson 分布时的假定。
- 泊松过程(定义二):设 λ > 0 \lambda>0 λ>0是一个常数,如果计数过程 { N ( t ) } \{N(t) \} {N(t)}满足以下条件,则称他为强度为 λ \lambda λ的泊松过程:
(1) N ( 0 ) = 0 N(0)=0 N(0)=0;
(2) { N ( t ) } \{N(t) \} {N(t)}是独立增量过程,有平稳增量性;
(3)一般性:对任何 t ≥ 0 t\ge 0 t≥0,当正数h->0时,有: P ( N ( h ) = 1 ) = λ h + o ( h ) P(N(h)=1)=\lambda h + o(h) P(N(h)=1)=λh+o(h)与 P ( N ( h ) ≥ 2 ) = o ( h ) P(N(h)\ge 2) = o(h) P(N(h)≥2)=o(h)

(3)呼叫泊松流
- 呼叫流:设 { N ( t ) } \{N(t) \} {N(t)}是强度为 λ \lambda λ的泊松过程,定义 S 0 = 0 S_0=0 S0=0,用 S n S_n Sn表示第n个事件发生的时刻,简称为第n个到达时刻或者第n个呼叫时,由于 S 0 , S 1 , . . . , S n S_0,S_1,...,S_n S0,S1,...,Sn依次到达,所以又称 { S t } \{S_t \} {St}为泊松过程 { N ( t ) } \{N(t) \} {N(t)}的呼叫流。
基本关系:
{ N ( t ) ≥ n } = { S n ≤ t } { N ( t ) = n } = { S n ≤ t < S n + 1 } \{N(t)\ge n \} = \{S_n\le t \}\\ \{N(t)= n \} = \{S_n\le t
-
等待间隔:设 { S n } \{S_n \} {Sn}是泊松过程 { N ( t ) } \{N(t) \} {N(t)}的呼叫流,引入 X n = S n − S n − 1 , n = 1 , 2 , . . . X_n=S_n-S_{n-1},n=1,2,... Xn=Sn−Sn−1,n=1,2,...,则 X n X_n Xn是第n-1个事件之后等待第n个事件发生的等待间隔,称为第n个等待间隔。
-
泊松过程 { N ( t ) } \{N(t) \} {N(t)}的等待间隔 X 1 , . . . , X n , . . . X_1,...,X_n,... X1,...,Xn,...是来自指数总体 ϵ ( λ ) \epsilon(\lambda) ϵ(λ)的随机变量(即等待时间服从一个指数分布)。
证明:首先考虑 X 1 X_{1} X1 的分布,注意到事件 { X 1 > t } \left\{X_{1}>t\right\} {X1>t} 等价于事件 { N ( t ) = 0 } , \{N(t)=0\}, {N(t)=0}, 即 ( 0 , t ] (0, t] (0,t] 时间内没有事件发生。因此
P { X 1 > t } = P { N ( t ) = 0 } = e − λ t P\left\{X_{1}>t\right\}=P\{N(t)=0\}=\mathrm{e}^{-\lambda t} P{X1>t}=P{N(t)=0}=e−λt
从而
P { X 1 ⩽ t } = 1 − e − λ t P\left\{X_{1} \leqslant t\right\}=1-\mathrm{e}^{-\lambda t} P{X1⩽t}=1−e−λt
再来看 X 2 : X_{2}: X2:
P { X 2 > t ∣ X 1 = s } = P { N ( s + t ) − N ( s ) = 0 ∣ X 1 = s } P\left\{X_{2}>t \mid X_{1}=s\right\}=P\left\{N(s+t)-N(s)=0 \mid X_{1}=s\right\} P{X2>t∣X1=s}=P{N(s+t)−N(s)=0∣X1=s}
= P { N ( s + t ) − N ( s ) = 0 } ( =P\{N(s+t)-N(s)=0\}( =P{N(s+t)−N(s)=0}( 独立增量性 ) ) )
= e − λ t =\mathrm{e}^{-\lambda t} =e−λt
所以 X 2 X_{2} X2 与 X 1 X_{1} X1 独立,且都服从参数为 λ \lambda λ 的指数分布。重复同样的推导,可得定理
结论。
%matplotlib inline
import numpy as np
import matplotlib.pyplot as plt
plt.style.use("ggplot")# 模拟泊松过程
def poisson_process(n,lmd,times):## n是模拟的次数,lmd是泊松过程的强度,times是每次模拟发生的次数fin_list = []y_list = []for i in range(n):mid_list = []mid_list_y = []y = 1for time in range(times):mid_ans = np.random.exponential(lmd)mid_list.append(mid_ans)mid_list_y.append(y)y = y+1y_list.append(mid_list_y)for p,mid in enumerate(mid_list):if p == 0:passelse:mid_list[p] = sum(mid_list[0:p+1])fin_list.append(mid_list)for li,y_li in zip(fin_list,y_list):li.insert(0,0)y_li.insert(0,0)plt.step(li,y_li)## 开始模拟,模拟10个泊松分布曲线
poisson_process(10,0.05,10)

(4)泊松过程的汇合和分流
-
泊松过程的汇合:设随机过程 { N 1 ( t ) } \{N_1(t) \} {N1(t)}与 { N 2 ( t ) } \{N_2(t) \} {N2(t)}是相互独立的,强度为 λ 1 \lambda_1 λ1与 λ 2 \lambda_2 λ2的泊松过程,则: N ( t ) = N 1 ( t ) + N 2 ( t ) , t ≥ 0 N(t) = N_1(t) + N_2(t),t \ge 0 N(t)=N1(t)+N2(t),t≥0是强度为 λ = λ 1 + λ 2 \lambda = \lambda_1 + \lambda_2 λ=λ1+λ2的泊松过程。(多个也成立)
-
泊松过程的分流:设{N(t)}是强度为 λ \lambda λ的泊松过程, { Y j } \{Y_j \} {Yj}是独立同分布的随机序列,且 P { Y j = 1 } = p , P { Y j = 0 } = q P\{Y_j = 1 \} = p,P\{Y_j = 0 \} = q P{Yj=1}=p,P{Yj=0}=q(两点分布),计数过程 { N 1 ( t ) } \{N_1(t) \} {N1(t)}与 { N 1 ( t ) } \{N_1(t) \} {N1(t)}分别由 N 1 ( t ) = ∑ j = 1 N ( t ) Y j N_1(t) = \sum\limits_{j=1}^{N(t)}Y_j N1(t)=j=1∑N(t)Yj与 N 2 ( t ) = ∑ j = 1 N ( t ) ( 1 − Y j ) N_2(t) = \sum\limits_{j=1}^{N(t)}(1-Y_j) N2(t)=j=1∑N(t)(1−Yj)定义,若 { Y j } \{Y_j\} {Yj}与 { N 1 ( t ) } \{N_1(t)\} {N1(t)}独立,则 { N 1 ( t ) } \{N_1(t)\} {N1(t)}与 { N 2 ( t ) } \{N_2(t)\} {N2(t)}相互独立,分别为强度 λ 1 = λ p , λ 2 = λ ( 1 − p ) \lambda_1 = \lambda p,\lambda_2 = \lambda (1-p) λ1=λp,λ2=λ(1−p)的泊松过程。
-
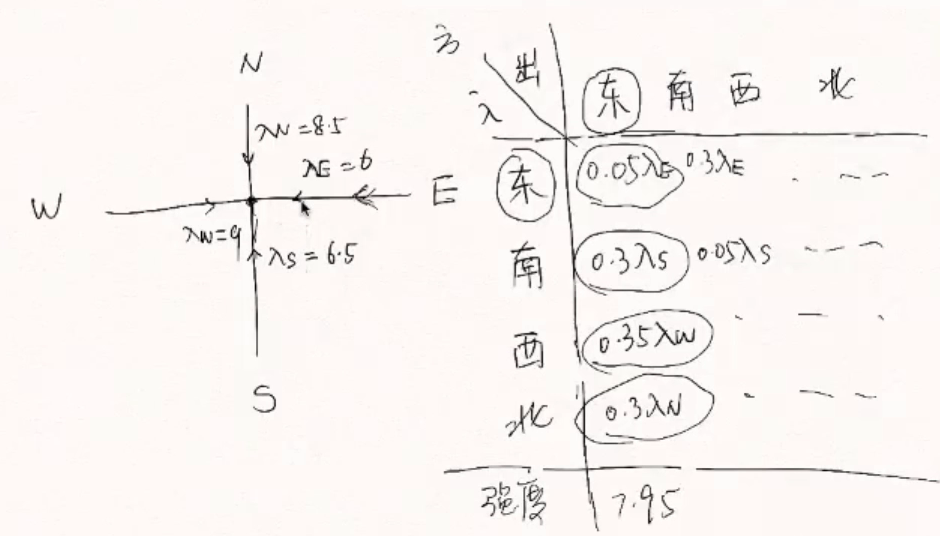
例子:汽车按照泊松流驶入立体交叉桥,经过调查可以知道:由东边每分钟驶入6辆,由南面驶入6.5辆,由西面驶入9辆,由北面驶入8.5辆汽车;在桥上,每辆车向左或者向右行驶的概率是0.3,直行的概率是0.35,掉头的概率是0.05,计算各个方向上的驶出汽车流的强度。(可以试试动态模拟这个立交桥的汽车行驶情况)
1.3 Markov过程(离散时间)
(1)马尔可夫链及其转移概率矩阵
设 { X n ∣ n = 0 , 1 , 2 , . . . } \{X_n|n = 0,1,2,... \} {Xn∣n=0,1,2,...}是随机序列,若每个 X n X_n Xn都在S中取值,那么称S为 { X n ∣ n = 0 , 1 , 2 , . . . } \{X_n|n = 0,1,2,... \} {Xn∣n=0,1,2,...}的状态空间,称S中的元素为状态。
- 马尔可夫链: \quad 随机过程 { X n , n = 0 , 1 , 2 , ⋯ } \left\{X_{n}, n=0,1,2, \cdots\right\} {Xn,n=0,1,2,⋯} 称为 Markov 链,若它只取有限或可 列个值(若不另外说明,以非负整数集 { 0 , 1 , 2 , ⋯ } \{0,1,2, \cdots\} {0,1,2,⋯} 来表示),并且对任意的 n ⩾ 0 n \geqslant 0 n⩾0, 及任意状态 i , j , i 0 , i 1 , ⋯ , i n − 1 , i, j, i_{0}, i_{1}, \cdots, i_{n-1}, i,j,i0,i1,⋯,in−1, 有
P { X n + 1 = j ∣ X n = i , X n − 1 = i n − 1 , ⋯ , X 1 = i 1 , X 0 = i 0 } = P { X n + 1 = j ∣ X n = i } P\left\{X_{n+1}=j \mid X_{n}=i, X_{n-1}=i_{n-1}, \cdots, X_{1}=i_{1}, X_{0}=i_{0}\right\}=P\left\{X_{n+1}=j \mid X_{n}=i\right\} P{Xn+1=j∣Xn=i,Xn−1=in−1,⋯,X1=i1,X0=i0}=P{Xn+1=j∣Xn=i}
式中, X n = i X_{n}=i Xn=i 表示过程在时刻 n n n 处于状态 i , i, i, 称 { 0 , 1 , 2 , ⋯ } \{0,1,2, \cdots\} {0,1,2,⋯} 为该过程的状态空间, 记为 S,式子刻画了 Markov 链的特性,称为 Markov 性。对 Markov 链,给定过去的状态 X 0 , X 1 , ⋯ , X n − 1 X_{0}, X_{1}, \cdots, X_{n-1} X0,X1,⋯,Xn−1 及现在的状态 X n , X_{n}, Xn, 将来的状态 X n + 1 X_{n+1} Xn+1 的条件分布与 过去的状态独立,只依赖于现在的状态。
直观理解:已知现在 B = { X n = i } B = \{X_n = i \} B={Xn=i},将来 A = X n + 1 = j A = X_{n+1} = j A=Xn+1=j与过去 C = { X n − 1 = i n − 1 , . . . , X 0 = i 0 } C = \{X_{n-1}=i_{n-1},...,X_0 = i_0\} C={Xn−1=in−1,...,X0=i0}独立。
-
(一步)转移概率: { X n , n = 0 , 1 , 2 , ⋯ } \left\{X_{n}, n=0,1,2, \cdots\right\} {Xn,n=0,1,2,⋯} 的一步转移概率,简称转移概率,记为 p i j , p_{i j}, pij, 它代表处于状态 i i i 的 过程下一步转移到状态 j j j 的概率。
-
(一步)转移概率矩阵: P = ( p i j ) = ( p i j ) i , j ∈ I P = (p_{ij}) = (p_{ij})_{i,j \in I} P=(pij)=(pij)i,j∈I

(2)C-K方程
- C-K方程: \quad Chapman-Kolmogorov 方程,简称 C-K 方程 对一切 n , m ⩾ 0 , i , j ∈ S n, m \geqslant 0, i, j \in S n,m⩾0,i,j∈S 有:
(1) p i j ( m + n ) = ∑ k ∈ S p i k ( m ) p k j ( n ) p_{i j}^{(m+n)}=\sum_{k \in S} p_{i k}^{(m)} p_{k j}^{(n)} pij(m+n)=∑k∈Spik(m)pkj(n)
(2) P ( n ) = P ⋅ P ( n − 1 ) = P ⋅ P ⋅ P ( n − 2 ) = ⋯ = P n \boldsymbol{P}^{(n)}=\boldsymbol{P} \cdot \boldsymbol{P}^{(n-1)}=\boldsymbol{P} \cdot \boldsymbol{P} \cdot \boldsymbol{P}^{(n-2)}=\cdots=\boldsymbol{P}^{n} P(n)=P⋅P(n−1)=P⋅P⋅P(n−2)=⋯=Pn
证明:
p i j ( m + n ) = P { X m + n = j ∣ X 0 = i } = P { X m + n = j , X 0 = i } P { X 0 = i } = ∑ k ∈ S P { X m + n = j , X m = k , X 0 = i } P { X 0 = i } = ∑ k ∈ S P { X m + n = j , X m = k , X 0 = i } P { X 0 = i } ⋅ P { X m = k , X 0 = i } P { X m = k , X 0 = i } = ∑ k ∈ S P { X m + n = j ∣ X m = k , X 0 = i } P { X m = k ∣ X 0 = i } = ∑ k ∈ S p i k ( m ) p k j ( n ) \begin{aligned} p_{i j}^{(m+n)} &=P\left\{X_{m+n}=j \mid X_{0}=i\right\} \\ &=\frac{P\left\{X_{m+n}=j, X_{0}=i\right\}}{P\left\{X_{0}=i\right\}} \\ &=\sum_{k \in S} \frac{P\left\{X_{m+n}=j, X_{m}=k, X_{0}=i\right\}}{P\left\{X_{0}=i\right\}}\\ &=\sum_{k \in S} \frac{P\left\{X_{m+n}=j, X_{m}=k, X_{0}=i\right\}}{P\left\{X_{0}=i\right\}} \cdot \frac{P\left\{X_{m}=k, X_{0}=i\right\}}{P\left\{X_{m}=k, X_{0}=i\right\}} \\ &=\sum_{k \in S} P\left\{X_{m+n}=j \mid X_{m}=k, X_{0}=i\right\} P\left\{X_{m}=k \mid X_{0}=i\right\} \\ &=\sum_{k \in S} p_{i k}^{(m)} p_{k j}^{(n)} \end{aligned} pij(m+n)=P{Xm+n=j∣X0=i}=P{X0=i}P{Xm+n=j,X0=i}=k∈S∑P{X0=i}P{Xm+n=j,Xm=k,X0=i}=k∈S∑P{X0=i}P{Xm+n=j,Xm=k,X0=i}⋅P{Xm=k,X0=i}P{Xm=k,X0=i}=k∈S∑P{Xm+n=j∣Xm=k,X0=i}P{Xm=k∣X0=i}=k∈S∑pik(m)pkj(n)


(3)极限分布和平稳条件
我们举个例子看看什么是极限分布:


- 极限分布:对于遍历的 Markov 链,极限
lim n → ∞ p i j ( n ) = π j , j ∈ S \lim _{n \rightarrow \infty} p_{i j}^{(n)}=\pi_{j}, \quad j \in S n→∞limpij(n)=πj,j∈S
称为 Markov 链的极限分布。

作业:

- 平稳条件(细致平稳条件): π i P i , j = π j P j , i \pi_iP_{i,j} = \pi_jP_{j,i} πiPi,j=πjPj,i(化学反应的动态平衡)
(4)鞅


作业:

(5)高斯过程
首先当随机变量是1维的时候,我们称之为一维高斯分布,概率密度函数 p ( x ) = N ( μ , σ 2 ) , p(x)=N\left(\mu, \sigma^{2}\right), p(x)=N(μ,σ2), 当 随机变量的维度上升到有限的 p p p 维的时候,就称之为高维高斯分布, p ( x ) = N ( μ , Σ p × p ) p(x)=N\left(\mu, \Sigma_{p \times p}\right) p(x)=N(μ,Σp×p) 。而 高斯过程则更进一步,他是一个定义在连续域上的无限多个高斯随机变量所组成的随机过程,换句话说,高斯过程是一个无限维的高斯分布。
- 高斯过程:对于一个连续域 T T \quad T (假设他是一个时间轴),如果我们在连续域上任选 n n n 个时刻: t 1 , t 2 , t 3 , … , t n ∈ T , t_{1}, t_{2}, t_{3}, \ldots, t_{n} \in T, t1,t2,t3,…,tn∈T, 使得获得的一个 n n n 维向量 { ξ 1 , ξ 2 , ξ 3 , … , ξ n } \left\{\xi_{1}, \xi_{2}, \xi_{3}, \ldots, \xi_{n}\right\} {ξ1,ξ2,ξ3,…,ξn} 都满足其是一个 n n n
维高斯分布,那么这个 { ξ t } \left\{\xi_{t}\right\} {ξt} 就是一个高斯过程。

1.4 随机采样与随机模拟
在高维空间中,拒绝采样和重要性采样的效率随空间维数的增加而指数降低。马尔科夫链蒙特卡洛方法MCMC是一种更好的采样方法(容易对高维变量进行采样)。
# MCMC方法之Metropolis-Hastings算法import numpy as np
import random
import matplotlib.pyplot as plt## 设置参数
mu = 0.5
sigma = 0.1
skip = 700 ## 设置收敛步长
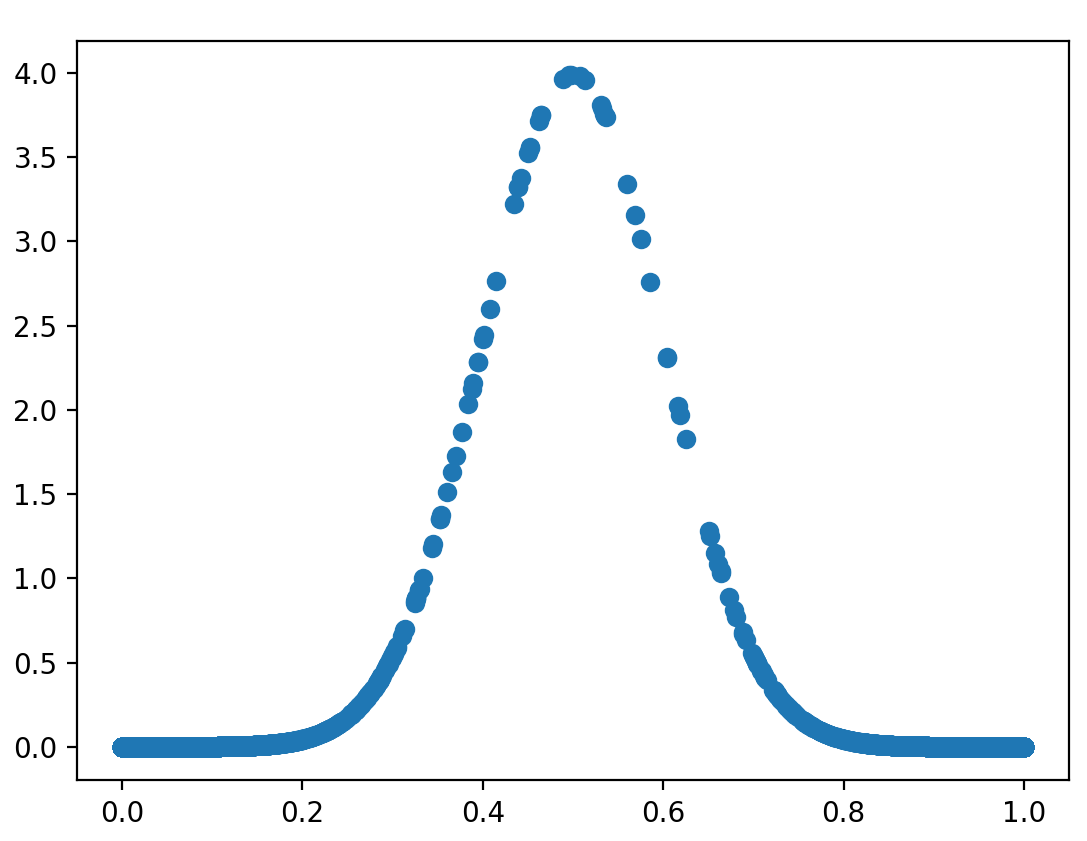
num = 100000 ##采样点数def Gussian(x,mu,sigma):return 1/(np.sqrt(2*np.pi)*sigma)*np.exp(-np.square((x-mu))/(2*np.square(sigma)))def M_H(num):x_0 = 0samples = []j = 1while(len(samples) <= num):while True:x_1 = random.random() # 转移函数(转移矩阵)q_i = Gussian(x_0,mu,sigma)q_j = Gussian(x_1,mu,sigma)alpha = min(1,q_i/q_j)u = random.random()if u <= alpha:x_0 = x_1if j >= skip:samples.append(x_1)j = j + 1breakreturn samplesnorm_samples = M_H(num)X = np.array(norm_samples)
px = Gussian(X,mu,sigma)
plt.scatter(X,px)
plt.show()
二、高等数学
2.1 梯度
梯度的本意是一个向量(矢量),表示某一函数在该点处的方向导数沿着该方向取得最大值,即函数在该点处沿着该方向(此梯度的方向)变化最快,变化率最大(为该梯度的模)。
定义:设二元函数 z = f ( x , y ) z=f(x, y) z=f(x,y) 在平面区域D上具有一阶连续偏导数,则对于每一个点P(x, y)都可定出一个向量 { ∂ f ∂ x , ∂ f ∂ y } = f x ( x , y ) i ˉ + f y ( x , y ) j ˉ , \left\{\frac{\partial f}{\partial x}, \frac{\partial f}{\partial y}\right\}=f_{x}(x, y) \bar{i}+f_{y}(x, y) \bar{j}, {∂x∂f,∂y∂f}=fx(x,y)iˉ+fy(x,y)jˉ, 该函数就称为函数 z = f ( x , y ) z=f(x, y) z=f(x,y) 在点P ( x , y ) (\mathrm{x}, \mathrm{y}) (x,y) 的梯度,记作gradf ( x , y ) (\mathrm{x}, \mathrm{y}) (x,y) 或
∇ f ( x , y ) \nabla f(x, y) ∇f(x,y),即有:
gradf ( x , y ) = ∇ f ( x , y ) = { ∂ f ∂ x , ∂ f ∂ y } = f x ( x , y ) i ˉ + f y ( x , y ) j ˉ \operatorname{gradf}(\mathrm{x}, \mathrm{y})=\nabla f(x, y)=\left\{\frac{\partial f}{\partial x}, \frac{\partial f}{\partial y}\right\}=f_{x}(x, y) \bar{i}+f_{y}(x, y) \bar{j} gradf(x,y)=∇f(x,y)={∂x∂f,∂y∂f}=fx(x,y)iˉ+fy(x,y)jˉ
其中 ∇ = ∂ ∂ x i ˉ + ∂ ∂ y j ˉ \nabla=\frac{\partial}{\partial x} \bar{i}+\frac{\partial}{\partial y} \bar{j} ∇=∂x∂iˉ+∂y∂jˉ 称为(二维的)向量微分算子或Nabla算子, ∇ f = ∂ f ∂ x i ˉ + ∂ f ∂ y j ˉ \nabla f=\frac{\partial f}{\partial x} \bar{i}+\frac{\partial f}{\partial y} \bar{j} ∇f=∂x∂fiˉ+∂y∂fjˉ 。
例子:请你计算 f ( x , y ) = x 2 + y 2 f(x,y) = x^2 + y^2 f(x,y)=x2+y2的梯度向量。
2.2 雅克比矩阵
梯度向量是雅克比矩阵的特例!
假设 F : R n → R m F: \mathbb{R}_{n} \rightarrow \mathbb{R}_{m} F:Rn→Rm 是一个从n维欧氏空间映射到到m维欧氏空间的函数。
这个函数由m个实函数组成:
y 1 ( x 1 , ⋯ , x n ) , ⋯ , y m ( x 1 , ⋯ , x n ) y_{1}\left(x_{1}, \cdots, x_{n}\right), \cdots, y_{m}\left(x_{1}, \cdots, x_{n}\right) y1(x1,⋯,xn),⋯,ym(x1,⋯,xn) 。这些函数的偏导数(如果存在)可以组成一个m行n列的矩阵,这个矩阵就是所谓的雅可 比矩阵:
[ ∂ y 1 ∂ x 1 ⋯ ∂ y 1 ∂ x n ⋮ ⋱ ⋮ ∂ y m ∂ x 1 ⋯ ∂ y m ∂ x n ] \left[\begin{array}{ccc} \frac{\partial y_{1}}{\partial x_{1}} & \cdots & \frac{\partial y_{1}}{\partial x_{n}} \\ \vdots & \ddots & \vdots \\ \frac{\partial y_{m}}{\partial x_{1}} & \cdots & \frac{\partial y_{m}}{\partial x_{n}} \end{array}\right] ⎣⎢⎡∂x1∂y1⋮∂x1∂ym⋯⋱⋯∂xn∂y1⋮∂xn∂ym⎦⎥⎤
例子:求 F = ( f 1 ( x , y ) , f ( x , y ) ) T F=(f_1(x,y),f_(x,y))^T F=(f1(x,y),f(x,y))T的雅克比矩阵,其中 f 1 ( x , y ) = 2 x 2 + y 2 , f 2 ( x , y ) = x 2 + 3 y 2 f_1(x,y) = 2x^2 + y^2,f_2(x,y) = x^2 + 3y^2 f1(x,y)=2x2+y2,f2(x,y)=x2+3y2。
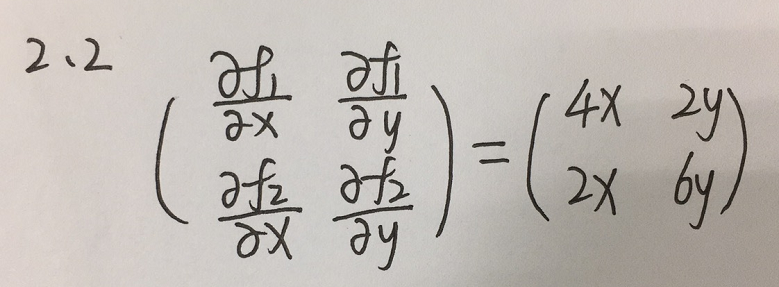
2.3 黑塞矩阵
黑塞矩阵(Hessian Matrix),又译作海森矩阵、海瑟矩阵、海塞矩阵等,是一个多元函数的二阶偏导数构成的方阵,描述了函数的局部曲率。 在数学中,海森矩阵(Hessian matrix 或 Hessian)是一个自变量为向量的实值函数的二阶偏导数组成的方块矩阵。
假設有一实数函数:
f ( x 1 , x 2 , … , x n ) f\left(x_{1}, x_{2}, \ldots, x_{n}\right) f(x1,x2,…,xn)如果 f f f 所有的二阶偏导数都存在,那么 f f f 的海森矩阵的第 i j i j ij 项,即:
H ( f ) i j ( x ) = D i D j f ( x ) H(f)_{i j}(x)=D_{i} D_{j} f(x) H(f)ij(x)=DiDjf(x) 其中 x = ( x 1 , x 2 , … , x n ) , x=\left(x_{1}, x_{2}, \ldots, x_{n}\right), x=(x1,x2,…,xn), 即
H ( f ) = [ ∂ 2 f ∂ x 1 2 ∂ 2 f ∂ x 1 ∂ x 2 ⋯ ∂ 2 f ∂ x 1 ∂ x n ∂ 2 f ∂ x 2 ∂ x 1 ∂ 2 f ∂ x 2 2 ⋯ ∂ 2 f ∂ x 2 ∂ x n ⋮ ⋮ ⋱ ⋮ ∂ 2 f ∂ x n ∂ x 1 ∂ 2 f ∂ x n ∂ x 2 ⋯ ∂ 2 f ∂ x n 2 ] H(f)=\left[\begin{array}{cccc} \frac{\partial^{2} f}{\partial x_{1}^{2}} & \frac{\partial^{2} f}{\partial x_{1} \partial x_{2}} & \cdots & \frac{\partial^{2} f}{\partial x_{1} \partial x_{n}} \\ \frac{\partial^{2} f}{\partial x_{2} \partial x_{1}} & \frac{\partial^{2} f}{\partial x_{2}^{2}} & \cdots & \frac{\partial^{2} f}{\partial x_{2} \partial x_{n}} \\ \vdots & \vdots & \ddots & \vdots \\ \frac{\partial^{2} f}{\partial x_{n} \partial x_{1}} & \frac{\partial^{2} f}{\partial x_{n} \partial x_{2}} & \cdots & \frac{\partial^{2} f}{\partial x_{n}^{2}} \end{array}\right] H(f)=⎣⎢⎢⎢⎢⎢⎡∂x12∂2f∂x2∂x1∂2f⋮∂xn∂x1∂2f∂x1∂x2∂2f∂x22∂2f⋮∂xn∂x2∂2f⋯⋯⋱⋯∂x1∂xn∂2f∂x2∂xn∂2f⋮∂xn2∂2f⎦⎥⎥⎥⎥⎥⎤ 实际上,Hessian矩阵是梯度向量g(x)对自变量x的Jacobian矩阵。
例子:求 f ( x , y ) = 2 x 2 + y 2 f(x,y)=2x^2+y^2 f(x,y)=2x2+y2的海森矩阵。

2.4 多元函数的极值
定理:(二元函数取得极值的充分条件)如果函数 z = f ( x , y ) z=f(x, y) z=f(x,y) 在点 ( x 0 , y 0 ) \left(x_{0}, y_{0}\right) (x0,y0) 的某邻域内具有连续的二阶偏导数, ( x 0 , y 0 ) \left(x_{0}, y_{0}\right) (x0,y0) 是它的驻点,令:
A = f x x ( x 0 , y 0 ) , B = f x y ( x 0 , y 0 ) , C = f y y ( x 0 , y 0 ) Δ = B 2 − A C \begin{array}{c} A=f_{x x}\left(x_{0}, y_{0}\right), B=f_{x y}\left(x_{0}, y_{0}\right), C=f_{y y}\left(x_{0}, y_{0}\right) \\ \Delta=B^{2}-A C \end{array} A=fxx(x0,y0),B=fxy(x0,y0),C=fyy(x0,y0)Δ=B2−AC
则:
(1)当 Δ < 0 \Delta<0 Δ<0 时, f ( x , y ) f(x, y) f(x,y) 在 ( x 0 , y 0 ) \left(x_{0}, y_{0}\right) (x0,y0) 取得极值. 其中 A > 0 A>0 A>0 时取极小值, A < 0 A<0 A<0 时取极大值.
(2)当 Δ > 0 \Delta>0 Δ>0 时, f ( x 0 , y 0 ) f\left(x_{0}, y_{0}\right) f(x0,y0) 不是极值.
(3)当 Δ = 0 \Delta=0 Δ=0 时, 不能确定,需进一步判断.
更加严谨的表述:
设n多元实函数 f ( x 1 , x 2 , ⋯ , x n ) f\left(x_{1}, x_{2}, \cdots, x_{n}\right) f(x1,x2,⋯,xn) 在点 M 0 ( a 1 , a 2 , … , a n ) M_{0}\left(a_{1}, a_{2}, \ldots, a_{n}\right) M0(a1,a2,…,an) 的邻域内有二阶连续偏导,若有:
∂ f ∂ x j ∣ ( a 1 , a 2 , … , a n ) = 0 , j = 1 , 2 , … , n \left.\frac{\partial f}{\partial x_{j}}\right|_{\left(a_{1}, a_{2}, \ldots, a_{n}\right)}=0, j=1,2, \ldots, n ∂xj∂f∣∣∣∣(a1,a2,…,an)=0,j=1,2,…,n
并且
A = [ ∂ 2 f ∂ x 1 2 ∂ 2 f ∂ x 1 ∂ x 2 ⋯ ∂ 2 f ∂ x 1 ∂ x n ∂ 2 f ∂ x 2 ∂ x 1 ∂ 2 f ∂ x 2 2 ⋯ ∂ 2 f ∂ x 2 ∂ x n ⋮ ⋮ ⋱ ⋮ ∂ 2 f ∂ x n ∂ x 1 ∂ 2 f ∂ x n ∂ x 2 ⋯ ∂ 2 f ∂ x n 2 ] A=\left[\begin{array}{cccc} \frac{\partial^{2} f}{\partial x_{1}^{2}} & \frac{\partial^{2} f}{\partial x_{1} \partial x_{2}} & \cdots & \frac{\partial^{2} f}{\partial x_{1} \partial x_{n}} \\ \frac{\partial^{2} f}{\partial x_{2} \partial x_{1}} & \frac{\partial^{2} f}{\partial x_{2}^{2}} & \cdots & \frac{\partial^{2} f}{\partial x_{2} \partial x_{n}} \\ \vdots & \vdots & \ddots & \vdots \\ \frac{\partial^{2} f}{\partial x_{n} \partial x_{1}} & \frac{\partial^{2} f}{\partial x_{n} \partial x_{2}} & \cdots & \frac{\partial^{2} f}{\partial x_{n}^{2}} \end{array}\right] A=⎣⎢⎢⎢⎢⎢⎡∂x12∂2f∂x2∂x1∂2f⋮∂xn∂x1∂2f∂x1∂x2∂2f∂x22∂2f⋮∂xn∂x2∂2f⋯⋯⋱⋯∂x1∂xn∂2f∂x2∂xn∂2f⋮∂xn2∂2f⎦⎥⎥⎥⎥⎥⎤
则有如下结果:
(1) 当A正定矩阵时, f ( x 1 , x 2 , ⋯ , x n ) f\left(x_{1}, x_{2}, \cdots, x_{n}\right) f(x1,x2,⋯,xn) 在 M 0 ( a 1 , a 2 , … , a n ) M_{0}\left(a_{1}, a_{2}, \ldots, a_{n}\right) M0(a1,a2,…,an) 处是极小值;
(2) 当A负定矩阵时, f ( x 1 , x 2 , ⋯ , x n ) f\left(x_{1}, x_{2}, \cdots, x_{n}\right) f(x1,x2,⋯,xn) 在 M 0 ( a 1 , a 2 , … , a n ) M_{0}\left(a_{1}, a_{2}, \ldots, a_{n}\right) M0(a1,a2,…,an) 处是极大值;
(3) 当A不定矩阵时, M 0 ( a 1 , a 2 , … , a n ) M_{0}\left(a_{1}, a_{2}, \ldots, a_{n}\right) M0(a1,a2,…,an) 不是极值点。
(4) 当A为半正定矩阵或半负定矩阵时, M 0 ( a 1 , a 2 , … , a n ) M_{0}\left(a_{1}, a_{2}, \ldots, a_{n}\right) M0(a1,a2,…,an) 是“可疑"极值点,尚需要利用其他方法来判定。
例子:求三元函数 f ( x , y , z ) = x 2 + y 2 + z 2 + 2 x + 4 y − 6 z f(x, y, z)=x^{2}+y^{2}+z^{2}+2 x+4 y-6 z f(x,y,z)=x2+y2+z2+2x+4y−6z 的极值。
解: 因为 ∂ f ∂ x = 2 x + 2 , ∂ f ∂ y = 2 y + 4 , ∂ f ∂ z = 2 z − 6 , \frac{\partial f}{\partial x}=2 x+2, \frac{\partial f}{\partial y}=2 y+4, \frac{\partial f}{\partial z}=2 z-6, ∂x∂f=2x+2,∂y∂f=2y+4,∂z∂f=2z−6, 故该三元函数的驻点是 (-1,-2,3) 。
又因为 ∂ 2 f ∂ x 2 = 2 , ∂ 2 f ∂ y 2 = 2 , ∂ 2 f ∂ z 2 = 2 , ∂ 2 f ∂ x ∂ y = 0 , ∂ 2 f ∂ x ∂ z = 0 , ∂ 2 f ∂ y ∂ z = 0 \frac{\partial^{2} f}{\partial x^{2}}=2, \frac{\partial^{2} f}{\partial y^{2}}=2, \frac{\partial^{2} f}{\partial z^{2}}=2, \frac{\partial^{2} f}{\partial x \partial y}=0, \frac{\partial^{2} f}{\partial x \partial z}=0, \frac{\partial^{2} f}{\partial y \partial z}=0 ∂x2∂2f=2,∂y2∂2f=2,∂z2∂2f=2,∂x∂y∂2f=0,∂x∂z∂2f=0,∂y∂z∂2f=0
故有: A = ( 2 0 0 0 2 0 0 0 2 ) A=\left(\begin{array}{ccc}2 & 0 & 0 \\ 0 & 2 & 0 \\ 0 & 0 & 2\end{array}\right) A=⎝⎛200020002⎠⎞
因为A是正定矩阵,故 (-1,-2,3) 是极小值点,且极小值 f ( − 1 , − 2 , 3 ) = − 14 f(-1,-2,3)=-14 f(−1,−2,3)=−14 。
2.5 求带等式约束的优化问题(拉格朗日乘子法)
引例:
求表面积为 a 2 a^{2} a2 市体积最大的长方体的体积。
方法(1):化为无条件约束的优化问题,再使用4.2节的方法
设长方体的三棱的长为 x , y , z , x, y, z, x,y,z, 则体积
V = x y z V=x y z V=xyz
又因假定表面积为 a 2 , a^{2}, a2, 所以自变量 x , y , z x, \quad y, \quad z x,y,z 还必须满足附加条件
2 ( x y + y z + x z ) = a 2 2(x y+y z+x z)=a^{2} 2(xy+yz+xz)=a2
像这种对自变量有附加条件的极值问题称为条件极值。而没有附加条件的问题就叫无条件极值。 有条件极值可以化为无条件极值,例如上述问题,可将条件2 2 ( x y + y z + x z ) = a 2 , 2(x y+y z+x z)=a^{2}, 2(xy+yz+xz)=a2, 用 z z z 表成 x , y x, \quad y x,y 的函数
z = a 2 − 2 x y 2 ( x + y ) z=\frac{a^{2}-2 x y}{2(x+y)} z=2(x+y)a2−2xy
再把它代人 V = x y z V=x y z V=xyz 中,于是问题就化为求
V = x y 2 ( a 2 − 2 x y x + y ) V=\frac{x y}{2}\left(\frac{a^{2}-2 x y}{x+y}\right) V=2xy(x+ya2−2xy)
方法(2):拉格朗日乘子法
问题:求函数 z = f ( x , y ) z=f(x, y) z=f(x,y) 在条件 φ ( x , y ) = 0 \varphi(x, y)=0 φ(x,y)=0 下的极值。
引入拉格朗日函数 L ( x , y ) = f ( x , y ) + λ φ ( x , y ) L(x, y)=f(x, y)+\lambda \varphi(x, y) L(x,y)=f(x,y)+λφ(x,y)
则极值点满足: { L x ( x 0 , y 0 ) = 0 L y ( x 0 , y 0 ) = 0 φ ( x 0 , y 0 ) = 0 \left\{\begin{array}{l}L_{x}\left(x_{0}, y_{0}\right)=0 \\ L_{y}\left(x_{0}, y_{0}\right)=0 \\ \varphi\left(x_{0}, y_{0}\right)=0\end{array}\right. ⎩⎨⎧Lx(x0,y0)=0Ly(x0,y0)=0φ(x0,y0)=0
回到之前求体积的例子,已知
2 ( x y + y z + x z ) = a 2 2(x y+{y} z+x z)=a^{2} 2(xy+yz+xz)=a2
拉格朗日函数可以写成
L ( x , y , z ) = x y z + λ ( 2 x y + 2 y z + 2 x z − a 2 ) L(x, y, z)=x y z+\lambda\left(2 x y+2 y z+2 x z-a^{2}\right) L(x,y,z)=xyz+λ(2xy+2yz+2xz−a2)
求其对 x , y , z x, y, z x,y,z 的偏导数,并使之为零,得到
y z + 2 λ ( y + z ) = 0 x z + 2 λ ( x + z ) = 0 x y + 2 λ ( y + x ) = 0 \begin{array}{l} y z+2 \lambda(y+z)=0 \\ x z+2 \lambda(x+z)=0 \\ x y+2 \lambda(y+x)=0 \end{array} yz+2λ(y+z)=0xz+2λ(x+z)=0xy+2λ(y+x)=0
上面三个式子在与条件等式联立,可得
x y = x + z y + z , y z = x + y x + z \frac{x}{y}=\frac{x+z}{y+z}, \frac{y}{z}=\frac{x+y}{x+z} yx=y+zx+z,zy=x+zx+y
解得: x = y = z = V 0 3 x=y=z=\sqrt[3]{V_{0}} x=y=z=3V0
2.6 泰勒公式
泰勒公式就是用一个多项式函数去逼近一个给定的函数(即尽量使多项式函数图像拟合给定的函数图像)。如果一个非常复杂函数,想求其某点的值,直接求无法实现,这时候可以使用泰勒公式去近似的求该值,这是泰勒公式的应用之一。泰勒公式在机器学习中主要应用于梯度迭代。
定义:设 n n n 是一个正整数。如果定义在一个包含a的区间上的函数 f f f 在 a a a 点处 n + 1 n+1 n+1 次可导,那么对于这个区间上的任意 x x x 都有:
f ( x ) = f ( a ) 0 ! + f ′ ( a ) 1 ! ( x − a ) + f ′ ′ ( a ) 2 ! ( x − a ) 2 + ⋯ + f ( n ) ( a ) n ! ( x − a ) n + R n ( x ) = ∑ n = 0 N f ( n ) ( a ) n ! ( x − a ) n + R n ( x ) \begin{array}{c} f(x)=\frac{f(a)}{0 !}+\frac{f^{\prime}(a)}{1 !}(x-a)+\frac{f^{\prime \prime}(a)}{2 !}(x-a)^{2}+\cdots+\frac{f^{(n)}(a)}{n !}(x-a)^{n}+R_{n}(x) \\ =\sum_{n=0}^{N} \frac{f^{(n)}(a)}{n !}(x-a)^{n}+R_{n}(x) \end{array} f(x)=0!f(a)+1!f′(a)(x−a)+2!f′′(a)(x−a)2+⋯+n!f(n)(a)(x−a)n+Rn(x)=∑n=0Nn!f(n)(a)(x−a)n+Rn(x)
其中的多项式称为函数在a处的泰勒展开式, R n ( x ) R_{n}(x) Rn(x) 是泰勒公式的余项。
三、高数代码部分
3.1 基于梯度的优化方法–梯度下降法
作业:使用梯度下降法求函数 𝑦=𝑐𝑜𝑠(𝑥) 在区间 𝑥∈[0,2𝜋] 的极小值点。
import numpy as np
import matplotlib.pyplot as pltdef f(x):return np.power(x, 2)def d_f_1(x):'''求导数的方式1'''return 2.0 * xdef d_f_2(f, x, delta=1e-4):'''求导数的第二种方法'''return (f(x+delta) - f(x-delta)) / (2 * delta)# plot the function
xs = np.arange(-10, 11)
plt.plot(xs, f(xs))learning_rate = 0.1
max_loop = 30x_init = 10.0
x = x_init
lr = 0.1
x_list = []
for i in range(max_loop):#d_f_x = d_f_1(x)d_f_x = d_f_2(f, x)x = x - learning_rate * d_f_xx_list.append(x)
x_list = np.array(x_list)
plt.scatter(x_list,f(x_list),c="r")
plt.show()print('initial x =', x_init)
print('arg min f(x) of x =', x)
print('f(x) =', f(x))
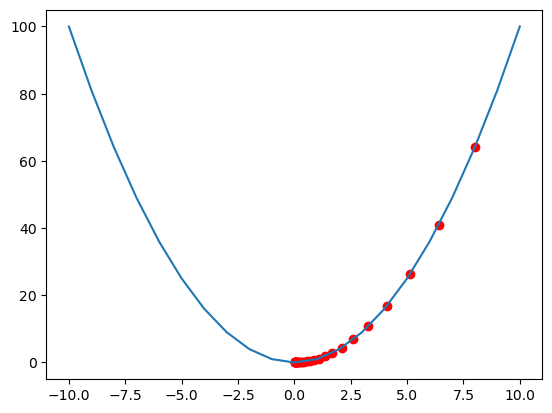
initial x = 10.0
arg min f(x) of x = 0.012379400392859128
f(x) = 0.00015324955408672073
3.2 基于梯度的优化方法–牛顿迭代法
作业:使用牛顿迭代法求函数 y = c o s ( x ) y=cos(x) y=cos(x)在区间 x ∈ [ 0 , 2 π ] x \in [0,2\pi] x∈[0,2π]的极小值点。
牛顿法:
首先牛顿法是求解函数值为0时的自变量取值的方法。
利用牛顿法求解目标函数的最小值其实是转化成求使目标函数的一阶导为0的参数值。这一转换的理论依据是,函数的极值点处的一阶导数为0.
其迭代过程是在当前位置x0求该函数的切线,该切线和x轴的交点x1,作为新的x0,重复这个过程,直到交点和函数的零点重合。此时的参数值就是使得目标函数取得极值的参数值。
其迭代过程如下:

迭代的公式如下:
θ : = θ − α ℓ ′ ( θ ) ℓ ′ ′ ( θ ) \theta:=\theta-\alpha \frac{\ell^{\prime}(\theta)}{\ell^{\prime \prime}(\theta)} θ:=θ−αℓ′′(θ)ℓ′(θ)
当 θ \theta θ是向量时, 牛顿法可以使用下面式子表示:
θ : = θ − α H − 1 ∇ θ ℓ ( θ ) \theta:=\theta-\alpha H^{-1} \nabla_{\theta} \ell(\theta) θ:=θ−αH−1∇θℓ(θ)其中 H H H叫做海森矩阵(目标函数对参数 θ \theta θ的二阶导数)。
牛顿法和梯度下降法的比较
1.牛顿法:是通过求解目标函数的一阶导数为0时的参数,进而求出目标函数最小值时的参数。
优点:收敛速度很快。海森矩阵的逆在迭代过程中不断减小,可以起到逐步减小步长的效果。
缺点:海森矩阵的逆计算复杂,代价比较大,因此有了拟牛顿法。
2.梯度下降法:是通过梯度方向和步长,直接求解目标函数的最小值时的参数。
越接近最优值时,步长应该不断减小,否则会在最优值附近来回震荡。
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import time
%matplotlib inline
from mpl_toolkits.mplot3d import Axes3D
class Rosenbrock():def __init__(self):self.x1 = np.arange(-100, 100, 0.0001)self.x2 = np.arange(-100, 100, 0.0001)#self.x1, self.x2 = np.meshgrid(self.x1, self.x2)self.a = 1self.b = 1self.newton_times = 1000self.answers = []self.min_answer_z = []# 准备数据def data(self):z = np.square(self.a - self.x1) + self.b * np.square(self.x2 - np.square(self.x1))#print(z.shape)return z# 随机牛顿def snt(self,x1,x2,z,alpha):rand_init = np.random.randint(0,z.shape[0])x1_init,x2_init,z_init = x1[rand_init],x2[rand_init],z[rand_init]x_0 =np.array([x1_init,x2_init]).reshape((-1,1))#print(x_0)for i in range(self.newton_times):x_i = x_0 - np.matmul(np.linalg.inv(np.array([[12*x2_init**2-4*x2_init+2,-4*x1_init],[-4*x1_init,2]])),np.array([4*x1_init**3-4*x1_init*x2_init+2*x1_init-2,-2*x1_init**2+2*x2_init]).reshape((-1,1)))x_0 = x_ix1_init = x_0[0,0]x2_init = x_0[1,0]answer = x_0return answer# 绘图def plot_data(self,min_x1,min_x2,min_z):x1 = np.arange(-100, 100, 0.1)x2 = np.arange(-100, 100, 0.1)x1, x2 = np.meshgrid(x1, x2)a = 1b = 1z = np.square(a - x1) + b * np.square(x2 - np.square(x1))fig4 = plt.figure()ax4 = plt.axes(projection='3d')ax4.plot_surface(x1, x2, z, alpha=0.3, cmap='winter') # 生成表面, alpha 用于控制透明度ax4.contour(x1, x2, z, zdir='z', offset=-3, cmap="rainbow") # 生成z方向投影,投到x-y平面ax4.contour(x1, x2, z, zdir='x', offset=-6, cmap="rainbow") # 生成x方向投影,投到y-z平面ax4.contour(x1, x2, z, zdir='y', offset=6, cmap="rainbow") # 生成y方向投影,投到x-z平面ax4.contourf(x1, x2, z, zdir='y', offset=6, cmap="rainbow") # 生成y方向投影填充,投到x-z平面,contourf()函数ax4.scatter(min_x1,min_x2,min_z,c='r')# 设定显示范围ax4.set_xlabel('X')ax4.set_ylabel('Y')ax4.set_zlabel('Z')plt.show()# 开始def start(self):times = int(input("请输入需要随机优化的次数:"))alpha = float(input("请输入随机优化的步长"))z = self.data()start_time = time.time()for i in range(times):answer = self.snt(self.x1,self.x2,z,alpha)self.answers.append(answer)min_answer = np.array(self.answers)for i in range(times):self.min_answer_z.append((1-min_answer[i,0,0])**2+(min_answer[i,1,0]-min_answer[i,0,0]**2)**2)optimal_z = np.min(np.array(self.min_answer_z))optimal_z_index = np.argmin(np.array(self.min_answer_z))optimal_x1,optimal_x2 = min_answer[optimal_z_index,0,0],min_answer[optimal_z_index,1,0]end_time = time.time()running_time = end_time-start_timeprint("优化的时间:%.2f秒!" % running_time)self.plot_data(optimal_x1,optimal_x2,optimal_z)
if __name__ == '__main__':snt = Rosenbrock()snt.start()
输入初始值:
请输入需要随机优化的次数:10
请输入随机优化的步长5
优化的时间:0.32秒!

四、概率论与数理统计
4.1 基础概念回顾
搞懂样本空间、条件概率、全概率公式、贝叶斯公式、随机变量、概率分布、随机变量的数学期望、方差等概念和公式。
五、概率论相关代码
5.1 随机模拟:π的估值
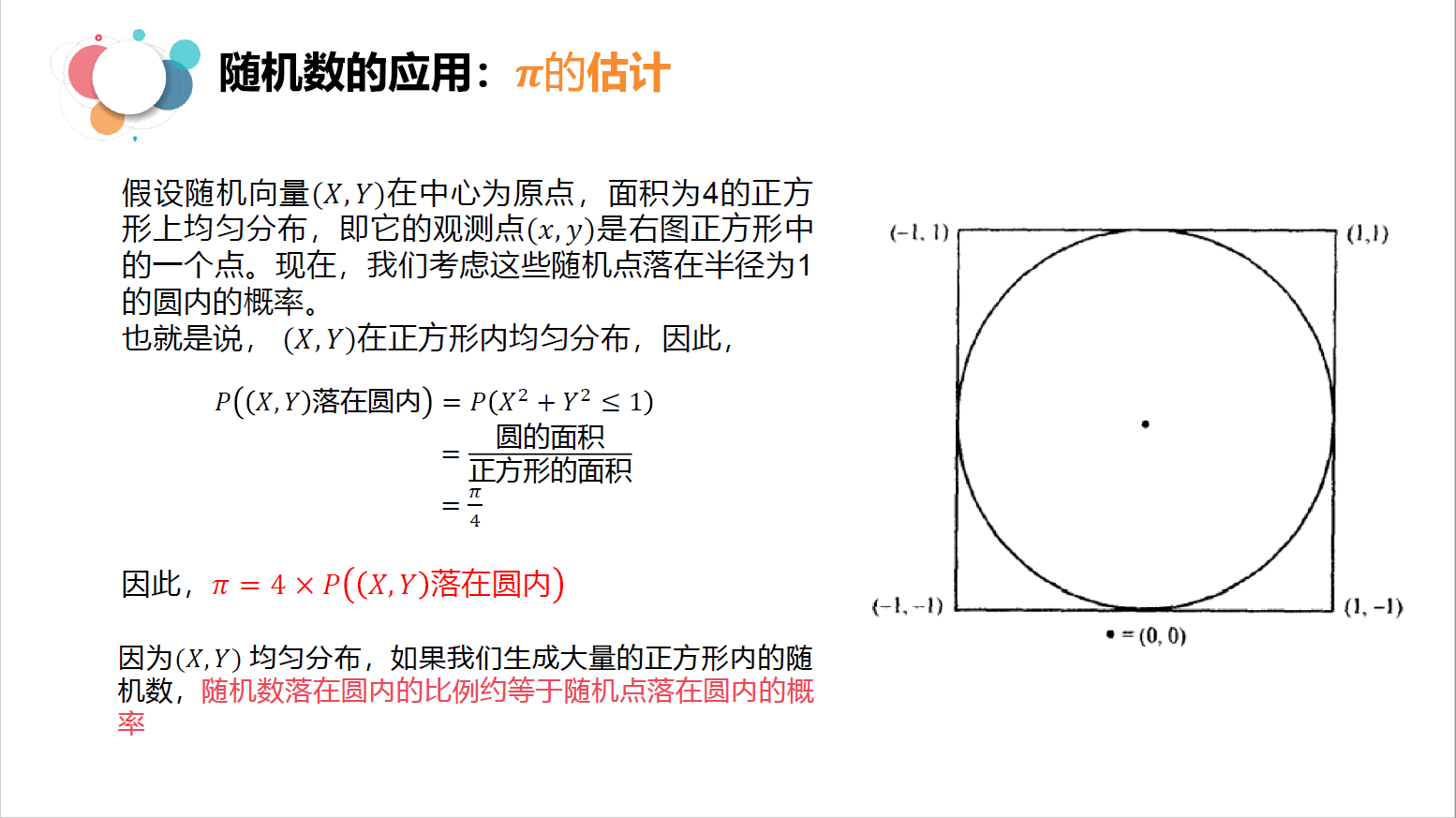

# pi的估计问题
import numpy as np
def pi_estimate(n):'''n为投点的数量'''n_rand_X = np.random.uniform(-1.0,1.0,n)n_rand_Y = np.random.uniform(-1.0,1.0,n)## 判断是否在圆内distance = np.sqrt(n_rand_X**2 + n_rand_Y**2)dis_n = float(len(distance[distance<=1.0]))return 4 * (dis_n / n)for i in [10,50,100,500,1000,5000,10000,50000,100000,500000,10000000]:print("pi的估计值为",pi_estimate(i))
估计的值为:
pi的估计值为 3.2
pi的估计值为 3.2
pi的估计值为 3.12
pi的估计值为 3.04
pi的估计值为 3.18
pi的估计值为 3.1384
pi的估计值为 3.14
pi的估计值为 3.13256
pi的估计值为 3.14856
pi的估计值为 3.143728
pi的估计值为 3.1403992
np.random.uniform
5.2 电子元件寿命问题


# 电子元件寿命问题
import numpy as np def ele_life(n,c,h,t,lamb):"""参数n:模拟实验的次数参数c:每次试验中的c个元件参数t:每c个元件中规定的合格品数量参数h:小时数"""times = 0.0for i in range(n):c_rand = np.random.exponential(1/lamb,c)c_rand_t = len(c_rand[c_rand>h])if c_rand_t > t:times = times + 1return times / n ele_life(10000,1000,18,20,0.2)
# 0.9119
np.random.exponential
5.3 三门问题
蒙提霍尔问题:假如你参与一个有主持人的游戏,你会看见三扇关闭了的门,其中一扇的后面有一辆汽车,另外2扇门后面各是一只山羊,你看不见门后面的情况,但主持人知道一切。你被主持人要求在三扇门中选择一扇,但不能打开,在你选定之后主持人开启了另一扇后面有山羊的门,然后你可以坚持原来选定的门,也可以改主意重新选择。问题是:改与不改对选中汽车的概率有影响吗?请使用模拟实验的方法回答该问题。
# 三门问题
import numpy.random as random
def MontyHallProblem(n_test):#测试次数winning_door = random.randint(0,3,n_test)first_get = 0change_get = 0for winning_doors in winning_door:act_door = random.randint(0,3)if winning_doors == act_door:first_get += 1else :change_get += 1first_pro = first_get / n_testchange_pro = change_get / n_testcompar1 = round(change_get / first_get,2)print ("在%d次测试中,坚持原则第一次就选中的次数是%d,改变决定选择另一扇门中奖的次数是%d"% (n_test,first_get,change_get))print ("概率分别是{0}和{1},改变决定选择另一扇门中奖几率是坚持选择的{2}倍".format(first_pro,change_pro,compar1))
MontyHallProblem(100000)
结果为:
在100000次测试中,坚持原则第一次就选中的次数是33063,改变决定选择另一扇门中奖的次数是66937
概率分别是0.33063和0.66937,改变决定选择另一扇门中奖几率是坚持选择的2.02倍
六、线性代数
6.1 向量空间
举例:正如我们所生活的三维空间,它就是一个向量空间。
定义:令F是一个数域,对于一个集合V,对于任意的a,b∈F,α,β,γ∈V,我们称V为一个向量空间,则它必须满足以下条件:
(1)α+β=β+α;
(2)(α+β)+γ=α+(β+γ);
(3)∃0∈V,它具有以下性质:∀α∈V,都有0+α=α;
(4)对于V中的每一个向量α,在V中存在一个向量α′,使得α+α′=0。这样的α′叫做α的负向量;
(5)a(α+β)=aα+aβ:
(6)(a+b)α=aα+bβ;
(7)(ab)α=a(bα);
(8)1α=α。
6.2 向量及其内积
我们称向量空间中的元素为为向量,向量空间中的向量满足向量的加法及数量乘法,向量的加法满足平行四边形法则;而向量的内积则是指在向量空间中所定义的一种运算,内积也称为点积,其结果是一个实数。对于向量空间中的两个向量a,b,它们的内积为:
a⋅b=|a|⋅|b|cosθ
其中θ是a,b的夹角。
向量内积满足:
⟨α,β⟩=⟨β,α⟩
k⟨α,β⟩=⟨kα,β⟩=⟨α,kβ⟩
⟨α+β,γ⟩=⟨α,β⟩+⟨β,γ⟩
⟨α,α⟩⩾0,等号成立当且仅当α=0
用numpy写一个向量a⃗ =(a1,a2,⋯,an),代码为:
import numpy
a=array([a1,a2,⋯,an]) 用代码表示两向量a⃗ ,b⃗ 的内积:
c=dot(numpy.transpose(a),b)
或
c=dot(a.T,b)
线性相关、线性无关概念:对于n维向量α1,α2,⋯,αs,如果存在不全为零的数k1,k2,⋯,ks使得
k1α1+k2α2+⋯+ksαs=0,则称向量组α1,α2,⋯,αs线性相关,否则称它线性无关。

6.3 向量的范数
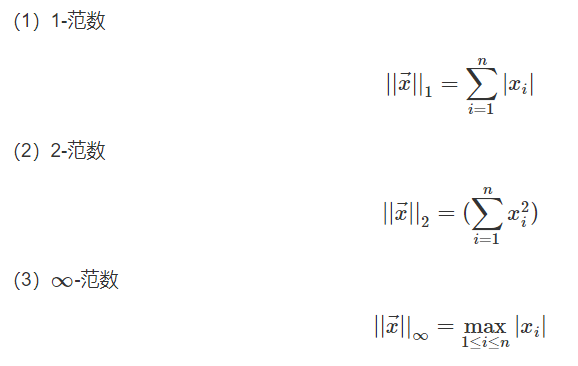
向量范数的基本性质:
(1)正定性:对所有x∈Rn有||x||⩾0,且||x||=0⇔x=0
(2)齐次性:对所有x∈Rn和常数a有||ax||=|a|||x||
(3)三角不等式:对所有x,y∈Rn有||x+y||⩽||x||+||y||
6.4 矩阵及其秩
import numpy
A=array([(a11,a12,⋯,a1n),(a21,a22,⋯,a2n),⋯,(am1,am2,⋯,amn)])
# 一个全零矩阵的写法是:
zeros((m,n))
# 矩阵元素全为1的写法是:
ones((m,n))
A + B = [ a 11 + b 11 ⋯ a 1 n + b 1 n ⋮ ⋱ ⋮ a m 1 + b m 1 ⋯ a m n + b m n ] A+B=\left[\begin{array}{ccc} a_{11}+b_{11} & \cdots & a_{1 n}+b_{1 n} \\ \vdots & \ddots & \vdots \\ a_{m 1}+b_{m 1} & \cdots & a_{m n}+b_{m n} \end{array}\right] A+B=⎣⎢⎡a11+b11⋮am1+bm1⋯⋱⋯a1n+b1n⋮amn+bmn⎦⎥⎤
import numpy
A=array([(a11,a12,⋯,a1n),(a21,a22,⋯,a2n),⋯,(am1,am2,⋯,amn)])
B=array([(b11,b12,⋯,b1n),(b21,a22,⋯,b2n),⋯,(bm1,bm2,⋯,bmn)])
C=A+B
矩阵A和实数k相乘:
k A = [ k a 11 ⋯ k a 1 n ⋮ ⋱ ⋮ k a m 1 ⋯ k a m n ] k A=\left[\begin{array}{ccc} k a_{11} & \cdots & k a_{1 n} \\ \vdots & \ddots & \vdots \\ k a_{m 1} & \cdots & k a_{m n} \end{array}\right] kA=⎣⎢⎡ka11⋮kam1⋯⋱⋯ka1n⋮kamn⎦⎥⎤
import numpy
A = numpy.mat(’a11 ⋯ a1n;⋯;an1 ⋯ ann’)
C=k*A
伴随矩阵:由矩阵A的行列式|A|所有的代数余子式所构成的形如
[ A 11 A 21 ⋯ A n 1 A 21 A 22 ⋯ A n 2 ⋮ ⋮ ⋮ A 1 n A 2 n ⋯ A n n ] \left[\begin{array}{cccc} A_{11} & A_{21} & \cdots & A_{n 1} \\ A_{21} & A_{22} & \cdots & A_{n 2} \\ \vdots & \vdots & & \vdots \\ A_{1 n} & A_{2 n} & \cdots & A_{n n} \end{array}\right] ⎣⎢⎢⎢⎡A11A21⋮A1nA21A22⋮A2n⋯⋯⋯An1An2⋮Ann⎦⎥⎥⎥⎤
的矩阵称为矩阵A的伴随矩阵,记为A∗。
有关伴随矩阵的定理: A A ∗ = A ∗ A = ∣ A ∣ E \mathbf{A} \mathbf{A}^{*}=\mathbf{A}^{*} \mathbf{A}=|\mathbf{A}| \mathbf{E} AA∗=A∗A=∣A∣E
可逆矩阵:设A是n阶矩阵,如果存在n阶矩阵B使得
AB=BA=E(单位矩阵)
成立,则称A是可逆矩阵或非奇异矩阵,B是A的逆矩阵,记成A−1=B。
正交矩阵:设A是n阶矩阵,满足AAT=ATA=E,则A是正交矩阵。
A是正交矩阵⇔AT=A−1 ⇔A的列(行)向量组是正交规范向量组。
6.5 矩阵范数

6.6 矩阵的秩 齐次线性方程组及其解空间
伪代码:
用代码求齐次线性方程组AX=0的解空间:
import numpy
A=numpy.mat(’a11 ⋯ a1n;⋯;am1 ⋯ amn’)
b=zeros(1,n)
x=numpy.linalg.solve(A,b)
print(x)
6.7 特征值与特征向量及矩阵的迹
代码计算矩阵的特征值及特征向量:
import numpy as np
A=np.mat(’a11 ⋯ a1n;⋯;an1 ⋯ ann’)
[λ1,⋯,λn],[η1,⋯,ηn→→]=np.linalg.eig(A)
其中λ1,λ2,⋯,λn为矩阵的特征值,η1→,η2→,⋯,ηn→为矩阵的特征向量。
代码实现求矩阵的迹:
import numpy as np
trA = 0 A = array([(a11,⋯,a1n),⋯,(an1,⋯,ann)])
for i in range(0,n):
trA = A[i,1] + trA
print(trA)
6.8 二次型
定义:设F是一个数域,F上n元二次齐次多项式
q ( x 1 , x 2 , ⋯ , x n ) = a 11 x 1 2 + a 22 x 2 2 + ⋯ + a n n x n 2 + 2 a 12 x 1 x 2 + 2 a 13 x 1 x 3 + ⋯ + 2 a n − 1 , n x n − 1 x n \begin{gathered} q\left(x_{1}, x_{2}, \cdots, x_{n}\right)=a_{11} x_{1}^{2}+a_{22} x_{2}^{2}+\cdots+a_{n n} x_{n}^{2} \\ +2 a_{12} x_{1} x_{2}+2 a_{13} x_{1} x_{3}+\cdots \\ +2 a_{n-1, n} x_{n-1} x_{n} \end{gathered} q(x1,x2,⋯,xn)=a11x12+a22x22+⋯+annxn2+2a12x1x2+2a13x1x3+⋯+2an−1,nxn−1xn
叫做F上一个n二次型。
矩阵的合同:设A,B是数域F上两个阶矩阵。如果存在F上一个非奇异矩阵P,使得
P T A P = B \mathbf{P}^{\mathbf{T}} \mathbf{A} \mathbf{P}=\mathbf{B} PTAP=B那么就称A与A合同。
正定二次型与Hesse矩阵(黑赛矩阵)
定义:R上一个元二次型q(x1,x2,⋯,xn)可以看成定义在实数域上n个变量的实函数。如果对于变量x1,x2,⋯,xn的每一组不全为零的值,函数值q(x1,x2,⋯,xn)都是正数,那么就称q(x1,x2,⋯,xn)是一个正定二次型。
类似地,如果对于变量x1,x2,⋯,xn的每一组不全为零的值,q(x1,x2,⋯,xn)都是负数,就称q(x1,x2,⋯,xn)是负定的。
黑赛矩阵:若f具有二阶连续偏导,并记 H f ( P 0 ) = ( f x x ( P 0 ) f x y ( P 0 ) f y x ( P 0 ) f y y ( P 0 ) ) = ( f x x f x y f y x f y y ) P 0 \mathbf{H}_{f}\left(P_{0}\right)=\left(\begin{array}{ll} f_{x x}\left(P_{0}\right) & f_{x y}\left(P_{0}\right) \\ f_{y x}\left(P_{0}\right) & f_{y y}\left(P_{0}\right) \end{array}\right)=\left(\begin{array}{ll} f_{x x} & f_{x y} \\ f_{y x} & f_{y y} \end{array}\right)_{P_{0}} Hf(P0)=(fxx(P0)fyx(P0)fxy(P0)fyy(P0))=(fxxfyxfxyfyy)P0它称为在的黑赛矩阵。
(极值条件)设二元函数f在点P0(x0,y0)的某领域U(P0)上具有二阶连续偏导数,且P0是f的稳定点。则:
(1)当Hf(P0)是正定矩阵时,f在点P0取得极小值;
(2)当Hf(P0)是负定矩阵时,f在P0点取得极大值;
(3)当Hf(P0)是不定矩阵时,f在点P0不取极值。
七、作业:最小解发现
7.1 实验目的
1、理解等高线的几何含义、如何发现一个函数的最小解;
掌握一门绘制函数图形的编程工具;
7.2 实验环境
1、Python或Java或Matlab或Mathematica
2、如用Python,绘图工具可采用matplotlib或者plotly等。
7.3 实验内容-第一问
#!/usr/bin/python
## -*- coding=utf-8 -*-
#%matplotlib inline
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
# import time
from mpl_toolkits.mplot3d import Axes3Dx = np.arange(-50, 50, 1)
y = np.arange(-50, 50, 1)
x, y = np.meshgrid(x, y)fig = plt.figure() # 画布
ax = Axes3D(fig)a = 1
b = -100
z = np.square(a - x) + b * np.square(y - x**2)
# alpha用于控制通明度
surf = ax.plot_surface(x, y, z, rstride = 1, cstride = 1, alpha = 0.6, cmap = 'rainbow')
# 设置图形上方的title
plt.title('a=' + str(a) + ',' +'b=' + str(b))
# 设置颜色条colorbar
fig.colorbar(surf, shrink = 0.5, aspect = 5)
# 设置坐标轴的标签
ax.set_xlabel('X')
ax.set_xlabel('Y')
ax.set_xlabel('Z')
plt.show()
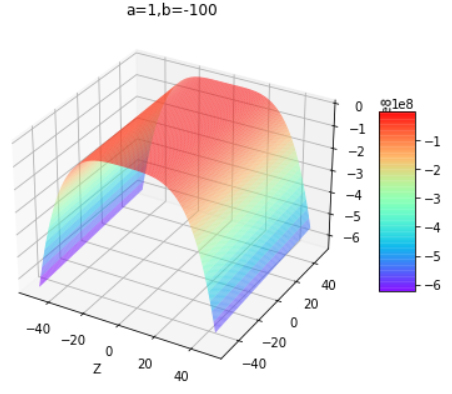
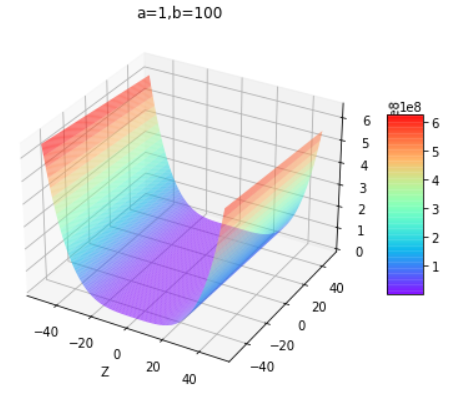
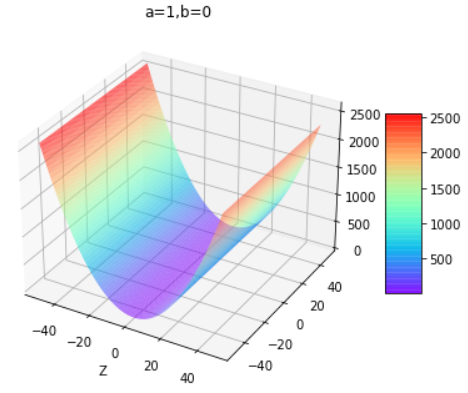
通过改变上面代码的a和b值即可得到下组图片,第一行为改变b值,第二行为改变a值:
 |  |  |
|---|---|---|
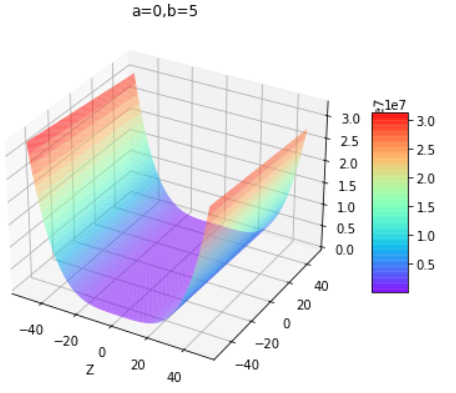 | 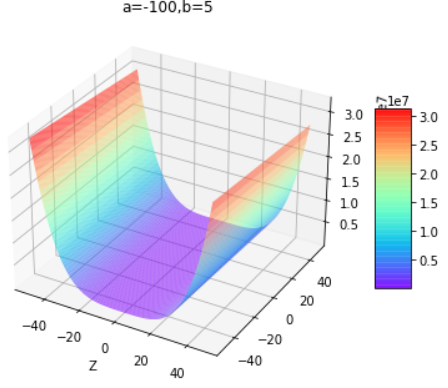 |  |
通过控制不同的a和b值,得出结论:
| b小于0 | b大于等于0 | |
|---|---|---|
| a为任意值 | 开口向下的曲面 | 开口向上的曲面 |
7.4 实验内容-第二小问
编写一个算法来找到它的全局最小值及相应的最小解,并在3D图中标出。分析一下你的算法时空效率、给出运行时间。
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import time
%matplotlib inline
from mpl_toolkits.mplot3d import Axes3D
class Rosenbrock():def __init__(self):self.x1 = np.arange(-100, 100, 0.0001)self.x2 = np.arange(-100, 100, 0.0001)#self.x1, self.x2 = np.meshgrid(self.x1, self.x2)self.a = 1self.b = 1self.newton_times = 1000 # 随机牛顿self.grad_times = 1000self.answers = []self.min_answer_z = []# 准备数据def data(self):z = np.square(self.a - self.x1) + self.b * np.square(self.x2 - np.square(self.x1))#print(z.shape)return z# 梯度下降def grad(self,x1,x2,z,alpha):rand_init = np.random.randint(0,z.shape[0])x1_init,x2_init,z_init = x1[rand_init],x2[rand_init],z[rand_init]x_0 =np.array([x1_init,x2_init]).reshape((-1,1))#print(x_0)for i in range(self.grad_times): x_i = x_0 - alpha*np.array([4*x1_init**3-4*x1_init*x2_init+2*x1_init-2,-2*x1_init**2+2*x2_init]).reshape((-1,1))dis=x_0-x_iif np.all(dis<=np.array([1e-4,1e-4]).reshape((-1,1))):breakx_0 = x_ix1_init = x_0[0,0]x2_init = x_0[1,0] answer = x_0return answer# 随机牛顿def snt(self,x1,x2,z,alpha):rand_init = np.random.randint(0,z.shape[0])x1_init,x2_init,z_init = x1[rand_init],x2[rand_init],z[rand_init]x_0 =np.array([x1_init,x2_init]).reshape((-1,1))#print(x_0)for i in range(self.newton_times):x_i = x_0 - np.matmul(np.linalg.inv(np.array([[12*x2_init**2-4*x2_init+2,-4*x1_init],[-4*x1_init,2]])),np.array([4*x1_init**3-4*x1_init*x2_init+2*x1_init-2,-2*x1_init**2+2*x2_init]).reshape((-1,1)))x_0 = x_ix1_init = x_0[0,0]x2_init = x_0[1,0]answer = x_0return answer# 绘图def plot_data(self,min_x1,min_x2,min_z):x1 = np.arange(-100, 100, 0.1)x2 = np.arange(-100, 100, 0.1)x1, x2 = np.meshgrid(x1, x2)a = 1b = 1z = np.square(a - x1) + b * np.square(x2 - np.square(x1))fig4 = plt.figure()ax4 = plt.axes(projection='3d')ax4.plot_surface(x1, x2, z, alpha=0.3, cmap='winter') # 生成表面, alpha 用于控制透明度ax4.contour(x1, x2, z, zdir='z', offset=-3, cmap="rainbow") # 生成z方向投影,投到x-y平面ax4.contour(x1, x2, z, zdir='x', offset=-6, cmap="rainbow") # 生成x方向投影,投到y-z平面ax4.contour(x1, x2, z, zdir='y', offset=6, cmap="rainbow") # 生成y方向投影,投到x-z平面ax4.contourf(x1, x2, z, zdir='y', offset=6, cmap="rainbow") # 生成y方向投影填充,投到x-z平面,contourf()函数ax4.scatter(min_x1,min_x2,min_z,c='r')# 设定显示范围ax4.set_xlabel('X')ax4.set_ylabel('Y')ax4.set_zlabel('Z')plt.show()# 开始def start(self):times = int(input("请输入需要随机优化的次数:"))alpha = float(input("请输入随机优化的步长"))z = self.data()start_time = time.time()for i in range(times):# answer = self.snt(self.x1,self.x2,z,alpha)answer = self.grad(self.x1, self.x2, z, alpha)self.answers.append(answer)min_answer = np.array(self.answers)for i in range(times):self.min_answer_z.append((1-min_answer[i,0,0])**2+(min_answer[i,1,0]-min_answer[i,0,0]**2)**2)optimal_z = np.min(np.array(self.min_answer_z))optimal_z_index = np.argmin(np.array(self.min_answer_z))optimal_x1,optimal_x2 = min_answer[optimal_z_index,0,0],min_answer[optimal_z_index,1,0]end_time = time.time()running_time = end_time-start_timeprint("优化的时间:%.2f秒!" % running_time)self.plot_data(optimal_x1,optimal_x2,optimal_z)
if __name__ == '__main__':snt = Rosenbrock()snt.start()
根据提示,输入要求的变量值后即可。
(1)如果是使用随机牛顿的方法:
请输入需要随机优化的次数:1000
请输入随机优化的步长0.01
优化的时间:26.00秒!

(2)如果是使用梯度下降的方法(可以和上面对比,优化的时间是大大降低的):
请输入需要随机优化的次数:1000
请输入随机优化的步长0.01
优化的时间:0.31秒!
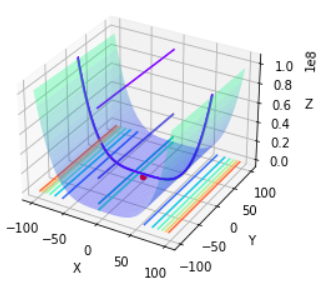
附:学习大纲
ps:其中前两章为【集成学习(上)】的部分。
-
第一章:机器学习数学基础
-
高等数学微分学
-
线性代数
-
概率论与数理统计
-
随机过程与抽样原理
-
-
第二章:机器学习基础
- 机器学习的三大主要任务
- 基本的回归模型
- 偏差与方差理论
- 回归模型的评估及超参数调优
- 基本的分类模型
- 分类问题的评估及超参数调优
-
第三章:集成学习之投票法与Bagging
- 投票法的思路
- 投票法的原理分析
- 投票法的案例分析(基于sklearn,介绍pipe管道的使用以及voting的使用)
- Bagging的思路
- Bagging的原理分析
- Bagging的案例分析(基于sklearn,介绍随机森林的相关理论以及实例)
-
第四章:集成学习之Boosting提升法
- Boosting的思路与Adaboost算法
- 前向分步算法与梯度提升决策树(GBDT)
- XGBoost算法与xgboost库的使用
- Xgboost算法案例与调参实例
- LightGBM算法的基本介绍
-
第五章:集成学习之Blending与Stacking
- Blending集成学习算法
- Stacking集成学习算法
- Blending集成学习算法与Stacking集成学习算法的案例分享
-
第六章:集成学习之案例分析
- 集成学习案例一 (幸福感预测)
- 集成学习案例二 (蒸汽量预测)
Reference
(1)datawhale notebook:https://github.com/datawhalechina/ensemble-learning
(2)wiki百科
(3)集成学习——萌弟b站视频;机器学习的数学基础——b站视频;数学推理部分可以参考:b站白板推导和3b1b。
本文来自互联网用户投稿,文章观点仅代表作者本人,不代表本站立场,不承担相关法律责任。如若转载,请注明出处。 如若内容造成侵权/违法违规/事实不符,请点击【内容举报】进行投诉反馈!