12-权重衰减
定义:
权重衰减是指在深度学习中使用的一种正则化技术,旨在限制模型的复杂度。正则化通常是在训练机器学习模型时使用的技术,旨在防止过拟合。正则化通常是通过向模型的损失函数中添加一个正则项来实现的。正则项的形式因模型而异,常见的正则化方法包括权重衰减、Dropout以及批归一化。
使用均方范数作为硬性限制

l(w,b) 表示损失函数。subject to 表示限定条件。表示在w的均方范数小于的限定条件下使得损失函数的值最小。
均方范数——向量中的所有元素的平方和开根号(2元素向量参考 勾股定理),在这里加了平方,不再开根号。
使用均方范数作为柔性限制

所谓柔性,就是 没有了对于W的硬性限制(硬性限制中,向量W中的每一项都要小于,才能满足均方小于
),而是通过添加一个
作为正则项。计算损失函数加上这个正则项之后的式子的最小值。引入了超参数
和均方范数组成的一项正则项。添加的这个正则项称为——罚
对于最优解的影响
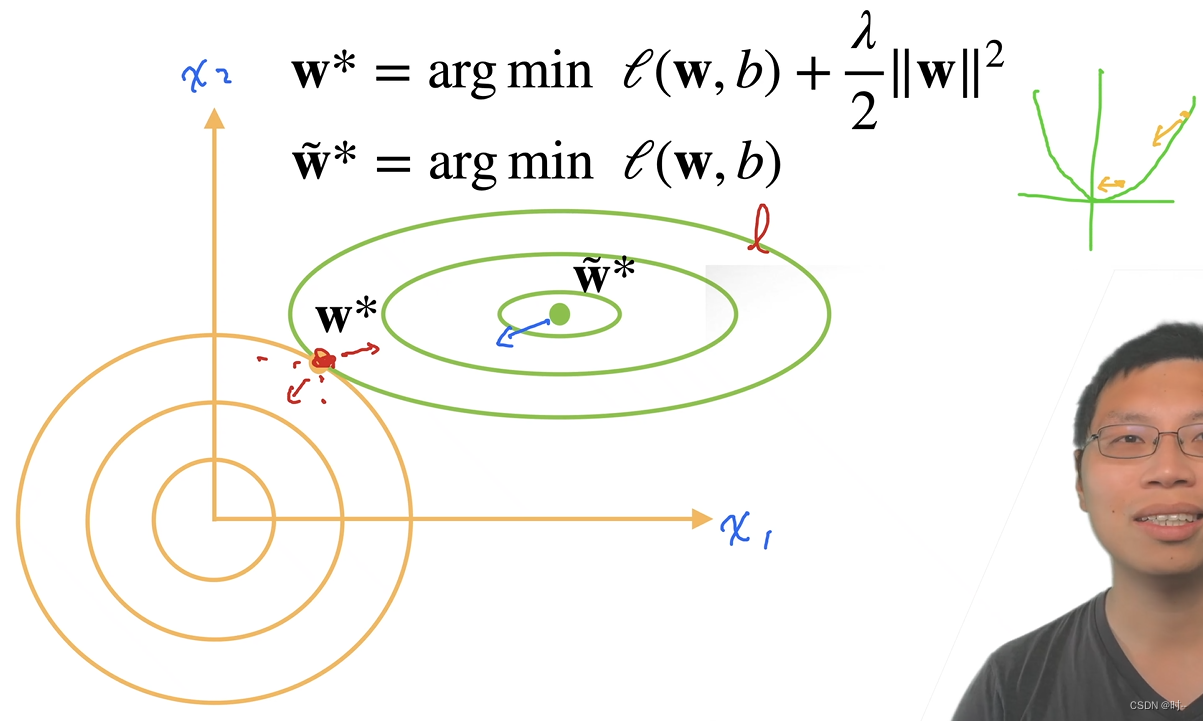
使用两个元素的在此举的例子比较容易理解,在由两个元素为横纵坐标构成的平面中,平方损失函数离最优解(无正则项影响)的距离越近,梯度的绝对值越小,对整个W*项的影响越小。
形象的比喻——拉力的大小,正则项(罚)和损失函数项(l)在整个平面对于整个式子的影响大小不同。梯度较大的那一项对于整个式子的影响大,拉力就大,起到主要作用。加上正则项的影响后,整个W*的最优解会向着原点偏移。权重向量W中每一项的大小会变小,导致模型容量下降。
参数更新法则

为学习率
为什么叫权重衰退——在进行权重更新之前,首先将当前的权重放小了一些,乘以了一个小于1的项()。权重衰退的原因就是因为引入的正则项。
小总结

这里提到的正则项超参数就是上面用到的。
代码实现—— weight-decay jupyter
本文来自互联网用户投稿,文章观点仅代表作者本人,不代表本站立场,不承担相关法律责任。如若转载,请注明出处。 如若内容造成侵权/违法违规/事实不符,请点击【内容举报】进行投诉反馈!