纠错码(Error correction code,ECC)中的汉明码,NAND FLASH中的纠错码(第一部分)
纠错码是一种用在不可靠的或者噪音比较大的通信信道中用来控制数据传输错误的技术。这种技术的核心思想是数据的发送方对将要发送的数据进行编码,使得编码之后的数据不仅包含了原有要发送的数据,还包含了一部分额外的冗余数据,接收方可以利用这部分冗余数据检测接收到的数据是否发生了错误,如果发生了错误,还可以利用这部分冗余数据来对部分发生错误的数据进行校正。这样就有可能避免数据的重传,这对于重传代价比较大的应用领域是非常友好的。通常情况下编码过程中引入的冗余信息越多,可以监测和校正的数据位越多,但是同时也意味着传输的有效数据位的比例越低,这个需要根据实际情况做出选择。
主要有两种类型的纠错码,以下只是基本的介绍,因为编码这玩意本身就很复杂,我也不懂,详细的请查看维基百科:
- B l o c k c o d e s : Block\quad codes: Blockcodes: 主要用于大小固定的数据包。
- C o n v o l u t i o n a l c o d e s : Convolutional\quad codes: Convolutionalcodes:对数据包的大小没有限制。
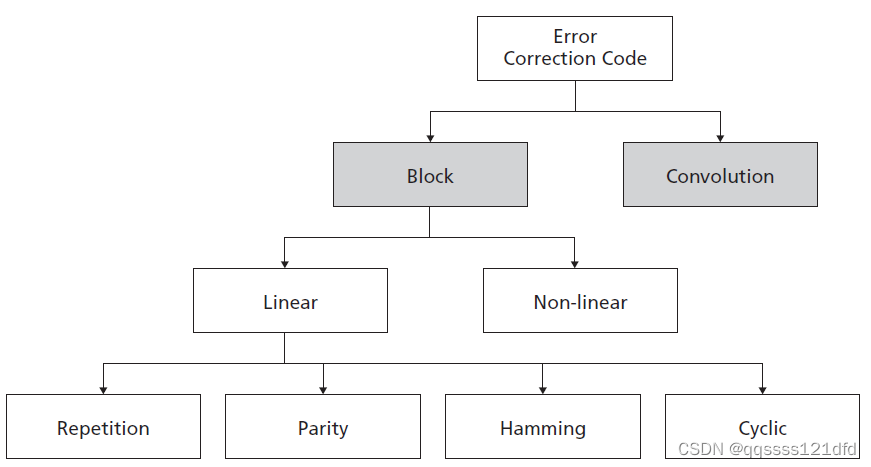
有关纠错码分类的一个简图如图1所示,图1来自于美光科技的一个文档,如图2所示。每一种纠错码也分很多种,汉明码( H a m m i n g c o d e Hamming\quad code Hammingcode)属于 B l o c k c o d e s Block\quad codes Blockcodes的一种。从图1也可以看出,汉明码也是线性码(linear Code)。那什么是线性码,线性码的特性有有效的线性码的码字的线性组合可以生成另外的有效的线性码码字,关于什么是码字,后面会有介绍。至于什么是线性组合,我大概百度了一下,好像是说是加法和数乘,当然这里如果是对二进制数进行操作的话,最后还要对结果进行对2的取模操作。在所有的线性码中,最后编码得到的码字的长度都大于原始要发送的数据的长度。

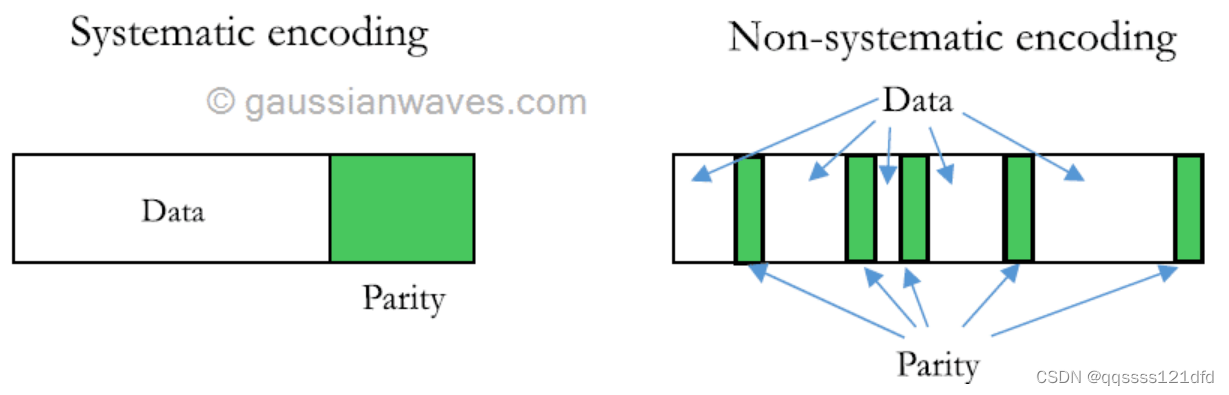
用数学术语来说的话,汉明码是一类 b i n a r y l i n e a r c o d e binary\quad linear\quad code binarylinearcode。对于每一个整数 r , r ≥ 2 , r,r\geq2, r,r≥2,假设加到要传输的数据的冗余的大小为 r r r个比特位,则要传输的数据的实际的比特个数为 2 r − r − 1 2^r-r-1 2r−r−1,因此最后实际要传输的数据额比特位的个数为 2 r − 1 2^r-1 2r−1。最后实际要传输的 2 r − 1 2^r-1 2r−1个比特数据称为原始要传输的数据编码之后的码字。比如当 r = 3 r=3 r=3的时候,要传输的数据的冗余的大小为3个比特位,要传输的实际数据的比特个数为4,要传输的码字数据比特位的个数为7。编码方式根据最后生成的码字的形式可以分为 s y s t e m a t i c systematic systematic和 n o n − s y s t e m a t i c non-systematic non−systematic,对于 s y s t e m a t i c systematic systematic的码字,码字中保留有原有的实际要发送的数据,也就是原始实际要发送的数据和冗余数据在码字中有明确的分界线,没有交错, n o n − s y s t e m a t i c non-systematic non−systematic的码字则不是,如图3所示。图3来自于这里。
对于( 2 r − 1 2^r-1 2r−1, 2 r − r − 1 2^r-r-1 2r−r−1, r r r)=(7,4,3)的汉明码,原始要发送的一个字符由四个比特位组成,那么一共有16种可能的字符,经过编码之后满足要求7个比特的码字也只有16种,尽管7个比特位一共有128种不同的组合,那么剩下的一共112种就是错误的码字,如果在接收方接收到了这些码字,那说明在传输过程中出现了错误。对于汉明码,所有满足要求的码字之间的最小汉明距离 d m i n d_{min} dmin为3,汉明距离是两个码字的二进制表示的情景下,对应的位置上比特位的值不同的比特位的个数。汉明距离可以用来判断一种纠错码的错误检测和纠错能力,在知道最小汉明距离 d m i n d_{min} dmin之后,则可以纠正的错误的最大比特数为 d m i n − 1 2 \frac {{d_{min}-1}}2 2dmin−1,可以检测的错误的最大比特数为 d m i n − 1 d_{min}-1 dmin−1。其实从这里可以看出来汉明码的检测和纠错能力是比较差的,因此汉明码比较适用于错误率比较低的情景,像计算机的存储器就是这样,因此在计算机的存储器中汉明纠错码比较常见。也常用在 s i n g l e l e v e l c e l l N A N D f l a s h single\quad level\quad cell\quad NAND\quad flash singlelevelcellNANDflash存储器。前面说过汉明码可以最多检测到2比特的错误,但是无法区分到底是1比特错误还是2比特错误,如果将2比特错误按照1比特错误来纠正的话会造成错误的结果,为了能够区分到底是1比特错误还是2比特错误,目前又引进了一种改进的汉明码,就是在已有汉明码的基础上再多加一个冗余位,使得汉明距离达到4.这样就可以区分到底是1比特错误还是2比特错误。汉明码的发明者是Richard Hamming,他最开始的发明好像是 r = 3 r=3 r=3的汉明码,其它的好像是后人的扩充。
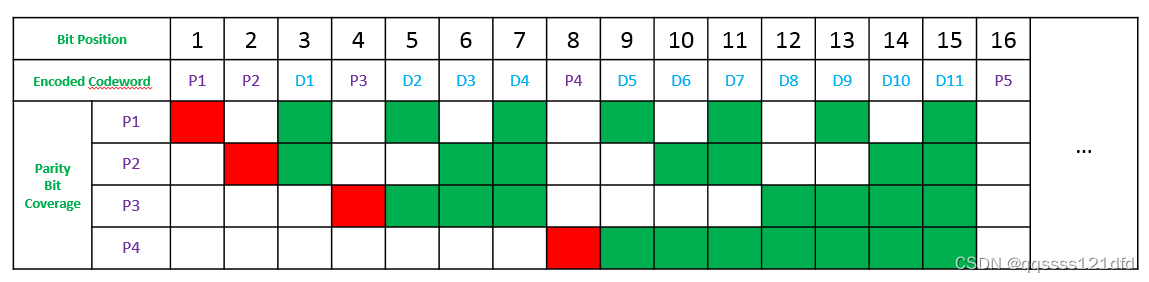
下面来讲一下可以校正1比特错误的汉明码的通用生成算法,首先我们看一下图4。这里图4中的第二行是经过汉明码编码之后的码字,其中 d i ( i ≥ 1 ) d_i(i\geq1) di(i≥1)表示原始要发送的原始数据位, p i ( i ≥ 1 ) p_i(i\geq1) pi(i≥1)表示添加的冗余数据位,这里的冗余数据位的生成其实就是基于奇偶校验位的,只不过这里采用的是偶校验(也就是要使得被校验的二进制数据位和校验位中所有为1的比特位的个数为偶数)。图4中的第1行是原始数据位经过汉明码编码之后的码字的每一个比特位的索引,从1开始。从图中可以看到,冗余数据位的存放位置为码字中索引为 2 0 2^0 20, 2 1 2^1 21, 2 2 2^2 22,…, 2 n 2^n 2n,…,的比特位位置,然后其它的比特位位置就是原始要发送的数据位的位置。现在编码之后的码字中的原始数据位以及其对应的存放位置已经确定了,冗余数据位的存放位置也已经确定,现在的问题是这些冗余数据比特位的值怎么确定。其实这里图4已经比较直观的表示出来了,图4中的 P a r i t y B i t C o v e r a g e Parity\quad Bit\quad Coverage ParityBitCoverage的区域的每一行( p n ( n ≥ 1 ) p_n(n\geq 1) pn(n≥1))说明了每一个冗余数据位( p n ( n ≥ 1 ) p_n(n\geq 1) pn(n≥1))的计算方法,每一行的红色方格表示这一行要计算的是哪一个冗余数据位,这一行的绿色方格表示这一行要计算冗余数据位是基于那些原始要发送的数据位的。比如 P a r i t y B i t C o v e r a g e Parity\quad Bit\quad Coverage ParityBitCoverage区域的 p 1 p_1 p1行( r = 3 r=3 r=3)表示冗余数据位 p 1 p_1 p1位的值为原始要发送的数据位 D 1 D_1 D1, D 2 D_2 D2和 D 4 D_4 D4的奇偶校验位(这里是偶校验)。下面我们直接给出计算公式:
- 冗余数据比特位 p 1 , 1 = 0 + 1 p_1,1=0+1 p1,1=0+1的值为所有的原始数据比特位中满足条件(这里的条件是原始数据比特位在码字中的索引的值和 1 = 2 0 = 0 x 0001 1=2^0=0x0001 1=20=0x0001的与运算的值不为0)的比特位的值的偶检验码。
- 冗余数据比特位 p 2 , 2 = 1 + 1 p_2,2=1+1 p2,2=1+1的值为所有的原始数据比特位中满足条件(这里的条件是原始数据比特位在码字中的索引的值和 2 = 2 1 = 0 x 0002 2=2^1=0x0002 2=21=0x0002的与运算的值不为0)的比特位的值的偶检验码。
- 冗余数据比特位 p 3 , 3 = 2 + 1 p_3,3=2+1 p3,3=2+1的值为所有的原始数据比特位中满足条件(这里的条件是原始数据比特位在码字中的索引的值和 4 = 2 2 = 0 x 0004 4=2^2=0x0004 4=22=0x0004的与运算的值不为0)的比特位的值的偶检验码。
- 冗余数据比特位 p 4 , 4 = 3 + 1 p_4,4=3+1 p4,4=3+1的值为所有的原始数据比特位中满足条件(这里的条件是原始数据比特位在码字中的索引的值和 8 = 2 3 = 0 x 0008 8=2^3=0x0008 8=23=0x0008的与运算的值不为0)的比特位的值的偶检验码。
汉明码的编码,解码,探测以及纠错都是可以用线性代数的操作来进行的,也就是矩阵的操作,所以要详细了解汉明码的话还需要一定的数学知识背景,我现在是没有时间去详细了解了只能根据网络上特别是维基百科上面的介绍来做一个简单的说明。下面我们举一个简单的例子来说明一下,假设现在 r = 3 r=3 r=3,也就是要加入的冗余比特位的个数为3,则原始要发送的数据比特位的个数为4,最后编码之后的码字的长度为7个比特位。在汉明码的编码过程中需要用到 g e n e r a t o r m a t r i x , G generator\quad matrix, G generatormatrix,G,下面是 r = 3 r=3 r=3的时候的 g e n e r a t o r m a t r i x , G generator\quad matrix, G generatormatrix,G,它是一个 4 × 7 4\times 7 4×7的矩阵。
G = [ 1 1 1 0 0 0 0 1 0 0 1 1 0 0 0 1 0 1 0 1 0 1 1 0 1 0 0 1 ] G=\begin{bmatrix} 1 & 1 & 1 & 0 & 0 & 0 & 0 \\ 1 & 0 & 0 & 1 & 1 & 0 & 0 \\ 0 & 1 & 0 & 1 & 0 & 1 & 0 \\ 1 & 1 & 0 & 1 & 0 & 0 & 1 \end{bmatrix} G= 1101101110000111010000100001
假设现在有一个需要编码的二进制数据流 d = [ d 1 , d 2 , d 3 , d 4 ] d=[d_1,d_2,d_3,d_4] d=[d1,d2,d3,d4],则编码过程如下:
d ∗ G = [ d 1 d 2 d 3 d 4 ] [ 1 1 1 0 0 0 0 1 0 0 1 1 0 0 0 1 0 1 0 1 0 1 1 0 1 0 0 1 ] = [ d 1 + d 2 + d 4 d 1 + d 3 + d 4 d 1 d 2 + d 3 + d 4 d 2 d 3 d 4 ] d*G=\begin{bmatrix} d_1 & d_2 & d_3 & d_4 \end{bmatrix}\begin{bmatrix} 1 & 1 & 1 & 0 & 0 & 0 & 0 \\ 1 & 0 & 0 & 1 & 1 & 0 & 0 \\ 0 & 1 & 0 & 1 & 0 & 1 & 0 \\ 1 & 1 & 0 & 1 & 0 & 0 & 1 \end{bmatrix}=\begin{bmatrix} d_1 + d_2+d_4 \\ d_1 + d_3+d_4 \\ d_1 \\ d_2 + d_3+d_4 \\ d_2 \\ d_3 \\ d_4 \end{bmatrix} d∗G=[d1d2d3d4] 1101101110000111010000100001 = d1+d2+d4d1+d3+d4d1d2+d3+d4d2d3d4
我们将上面通过矩阵运算得到的编码之后的码字和前面介绍的通用算法对比的话就可以知道这里通过矩阵的形式得到的编码的码值是满足上面描述的通用算法的。通过图4,其实 g e n e r a t o r m a t r i x , G generator\quad matrix, G generatormatrix,G的构建也是比较简单的, g e n e r a t o r m a t r i x , G generator\quad matrix, G generatormatrix,G的每一列对应于编码之后的码字的每一个码字位。如果当前列对应于码字中的冗余数据位,则 g e n e r a t o r m a t r i x , G generator\quad matrix, G generatormatrix,G的该列确定原始要编码的数据流的那些数据位用来生成当前码字位的值(偶校验运算)。比如 g e n e r a t o r m a t r i x , G generator\quad matrix, G generatormatrix,G的第一列对应于编码之后的码字的第一位,也就是冗余数据位 p 1 p_1 p1,如果 r = 3 r=3 r=3的话,这里 g e n e r a t o r m a t r i x , G generator\quad matrix, G generatormatrix,G的第一列为 [ 1 , 1 , 0 , 1 ] [1,1,0,1] [1,1,0,1],则表示原始要发送的数据比特流的第1,2,4个比特位用来生成码字的第一个比特位。如果当前列对应于码字中的原始要发送的数据位,则 g e n e r a t o r m a t r i x , G generator\quad matrix, G generatormatrix,G的该列确定原始要发送的比特数据流的哪一位作为当前的码字的该位。比如 g e n e r a t o r m a t r i x , G generator\quad matrix, G generatormatrix,G的第3列对应于编码之后的码字的第3位,也就是原始要发送的数据位 D 1 D_1 D1,如果 r = 3 r=3 r=3的话,这里 g e n e r a t o r m a t r i x , G generator\quad matrix, G generatormatrix,G的第3列为 [ 1 , 0 , 0 , 0 ] [1,0,0,0] [1,0,0,0],则表示原始要发送的数据比特流的第1个比特位 D 1 D_1 D1用来为当前的码字的该位
在汉明码的探测和纠错过程中需要用到 p a r i t y c h e c k m a t r i x , H parity\quad check\quad matrix, H paritycheckmatrix,H,下面是 r = 3 r=3 r=3的时候的 p a r i t y c h e c k m a t r i x , H parity\quad check\quad matrix, H paritycheckmatrix,H,它是一个 3 × 7 3\times 7 3×7的矩阵。这个矩阵也是很容易得到的,我们看一下图4中的 B i t P o s i t i o n Bit\quad Position BitPosition的值为1到7的所有列中 P a r i t y B i t C o v e r a g e Parity\quad Bit\quad Coverage ParityBitCoverage的区域( p 1 − > p 3 p_1->p_3 p1−>p3),这也是一个 3 × 7 3\times 7 3×7的区域,这个区域的每一个方块和 p a r i t y c h e c k m a t r i x , H parity\quad check\quad matrix, H paritycheckmatrix,H的每一个值一 一对应,绿色的方块对应 p a r i t y c h e c k m a t r i x , H parity\quad check\quad matrix, H paritycheckmatrix,H中的值为1,红色的方块也对应 p a r i t y c h e c k m a t r i x , H parity\quad check\quad matrix, H paritycheckmatrix,H中的值为1,只不过 3 × 7 3\times 7 3×7的区域
的每一行的红色方格表示当前是哪一个冗余数据位,绿色区域表示当前的冗余数据位基于计算所需要的原始数据位。这个白色的方块对应 p a r i t y c h e c k m a t r i x , H parity\quad check\quad matrix, H paritycheckmatrix,H中的值为0。
H = [ 1 0 1 0 1 0 1 0 1 1 0 0 1 1 0 0 0 1 1 1 1 ] H=\begin{bmatrix} 1 & 0 & 1 & 0 &1 & 0 & 1 \\ 0 & 1 & 1 & 0 & 0 & 1 & 1 \\ 0 & 0 & 0 & 1 & 1 & 1 & 1 \end{bmatrix} H= 100010110001101011111
当我们收到一个经过 g e n e r a t o r m a t r i x , G generator\quad matrix, G generatormatrix,G编码之后的码字 c c c之后,我们可以通过如下操作 H ∗ c H*c H∗c来判断收到的码字是否有出现错误。
c = [ d 1 + d 2 + d 4 d 1 + d 3 + d 4 d 1 d 2 + d 3 + d 4 d 2 d 3 d 4 ] = [ p 1 p 2 d 1 p 3 d 2 d 3 d 4 ] c=\begin{bmatrix} d_1 + d_2+d_4 \\ d_1 + d_3+d_4 \\ d_1 \\ d_2 + d_3+d_4 \\ d_2 \\ d_3 \\ d_4 \end{bmatrix}=\begin{bmatrix} p_1 \\ p_2 \\ d_1 \\ p_3 \\ d_2 \\ d_3 \\ d_4 \end{bmatrix} c= d1+d2+d4d1+d3+d4d1d2+d3+d4d2d3d4 = p1p2d1p3d2d3d4
H ∗ c = [ 1 0 1 0 1 0 1 0 1 1 0 0 1 1 0 0 0 1 1 1 1 ] [ p 1 p 2 d 1 p 3 d 2 d 3 d 4 ] = [ p 1 + d 1 + d 2 + d 4 p 2 + d 1 + d 3 + d 4 p 3 + d 2 + d 3 + d 4 ] H*c=\begin{bmatrix} 1 & 0 & 1 & 0 &1 & 0 & 1 \\ 0 & 1 & 1 & 0 & 0 & 1 & 1 \\ 0 & 0 & 0 & 1 & 1 & 1 & 1 \end{bmatrix}\begin{bmatrix} p_1 \\ p_2 \\ d_1 \\ p_3 \\ d_2 \\ d_3 \\ d_4 \end{bmatrix}=\begin{bmatrix} p_1+d_1 + d_2+d_4 \\ p_2+d_1 + d_3+d_4 \\ p_3+d_2 + d_3+d_4 \end{bmatrix} H∗c= 100010110001101011111 p1p2d1p3d2d3d4 = p1+d1+d2+d4p2+d1+d3+d4p3+d2+d3+d4
假设码字在传输过程中没有出现错误的话,因为 p 1 p_1 p1是基于 d 1 d_1 d1 , d 2 d_2 d2和 d 4 d_4 d4计算得到的奇偶校验位, p 2 p_2 p2是基于 d 1 d_1 d1 , d 3 d_3 d3和 d 4 d_4 d4计算得到的奇偶校验位, p 3 p_3 p3是基于 d 2 d_2 d2 , d 3 d_3 d3和 d 4 d_4 d4计算得到的奇偶校验位,则 p 1 + d 1 + d 2 + d 4 p_1+d_1 + d_2+d_4 p1+d1+d2+d4, p 2 + d 1 + d 3 + d 4 p_2+d_1 + d_3+d_4 p2+d1+d3+d4和 p 3 + d 2 + d 3 + d 4 p_3+d_2 + d_3+d_4 p3+d2+d3+d4运算得到的值均为0(需要对计算结果进行对2取模运算),因此最后得到的是一个 3 × 1 3\times1 3×1的0向量。从这里我们也可以看到,如果是发送的某一个数据位 d 1 d_1 d1, d 2 d_2 d2或 d 3 d_3 d3发生翻转的话,通过接收到的码字重新计算冗余数据位会得到两个冗余数据位翻转,如果是发送的数据位 d 4 d_4 d4发生翻转的话,通过接收到的码字重新计算冗余数据位会得到三个冗余数据位翻转,如果是发送的某一个冗余位 p 1 p_1 p1, p 2 p_2 p2或 p 3 p_3 p3发生翻转的话,通过接收到的码字重新计算冗余数据位会得到1个冗余数据位翻转
假设码字在传输过程中由某一个比特位发生了错误,即比特位的值翻转了,因此我们可以假设这个出现了一个比特翻转的码字为 c ′ = c + e i c^{'}=c+e_i c′=c+ei,这里 c c c为原始没有发生比特位翻转的码字,这里 e i e_i ei为何 c c c大小相同的单位向量, e i e_i ei除了第i个位置上的值为1,其它位置上的值为0,也就是相当于原始码字中第 i i i个位置上发生了比特位翻转。这时我们将 c ′ c^{'} c′和 p a r i t y c h e c k m a t r i x , H parity\quad check\quad matrix, H paritycheckmatrix,H相乘之后可以得到 H ∗ c ′ = H ∗ c + H ∗ e i = H ∗ e i H*c^{'}=H*c+H*e_i=H*e_i H∗c′=H∗c+H∗ei=H∗ei,这时我们可以发现如果码字在传输过程中由某一个比特位(第 i i i个)发生了错误,接收到的码字 c ′ c^{'} c′和 p a r i t y c h e c k m a t r i x , H parity\quad check\quad matrix, H paritycheckmatrix,H相乘之后的结果为 p a r i t y c h e c k m a t r i x , H parity\quad check\quad matrix, H paritycheckmatrix,H的第 i i i行。
如果是数据位 d 2 d_2 d2发生了翻转,则 H ∗ c ′ = H ∗ c + H ∗ e i = H ∗ e i = [ 1 , 0 , 1 ] T H*c^{'}=H*c+H*e_i=H*e_i={[1,0,1]}^{T} H∗c′=H∗c+H∗ei=H∗ei=[1,0,1]T,从上面绿色字体的描述我们可以知道数据位 d 2 d_2 d2发生翻转会造成接收到的码字重新计算的冗余位 p 1 p_1 p1和 p 3 p_3 p3发生翻转,数据位 d 2 d_2 d2在码字中的索引为5,冗余位 p 1 p_1 p1在码字中的索引为 1 = 2 0 1=2^0 1=20,冗余位 p 3 p_3 p3在码字中的索引为 4 = 2 2 4=2^2 4=22,而这里计算得到的这个 3 × 1 3\times1 3×1的向量的第1和第3个元素刚好为1,第2个元素刚好为0, 1 × 2 0 + 0 × 2 1 + 1 × 2 2 = 5 1×2^0+0×2^1+1×2^2=5 1×20+0×21+1×22=5。
如果是冗余位 p 3 p_3 p3发生了翻转,则 H ∗ c ′ = H ∗ c + H ∗ e i = H ∗ e i = [ 0 , 0 , 1 ] T H*c^{'}=H*c+H*e_i=H*e_i={[0,0,1]}^{T} H∗c′=H∗c+H∗ei=H∗ei=[0,0,1]T,从上面绿色字体的描述我们可以知道冗余位 p 3 p_3 p3发生翻转仅仅会造成接收到的码字重新计算的冗余位 p 3 p_3 p3发生翻转,冗余位 p 3 p_3 p3在码字中的索引为4,而这里计算得到的这个 3 × 1 3\times1 3×1的向量的第1和第2个元素刚好为0,第3个元素刚好为1, 0 × 2 0 + 0 × 2 1 + 1 × 2 2 = 4 0×2^0+0×2^1+1×2^2=4 0×20+0×21+1×22=4。
以上两种情况不是巧合,这正是汉明码的巧妙之处,就是我们可以根据 H ∗ c ′ = H ∗ c + H ∗ e i = H ∗ e i = [ a , b , c ] T H*c^{'}=H*c+H*e_i=H*e_i=[a,b,c]^T H∗c′=H∗c+H∗ei=H∗ei=[a,b,c]T的结果是否为0向量来判断经过汉明码编码的码字在发送过程中是否发生了一个比特位的错误。如果为0则没有发生错误。如果不为0则发生了一个比特位的翻转错误。如果 H ∗ c ′ = H ∗ c + H ∗ e i = H ∗ e i = [ a , b , c ] T H*c^{'}=H*c+H*e_i=H*e_i=[a,b,c]^T H∗c′=H∗c+H∗ei=H∗ei=[a,b,c]T的结果向量中只有一个数据位为1则是某个冗余数据位发生了翻转错误,如果 H ∗ c ′ = H ∗ c + H ∗ e i = H ∗ e i = [ a , b , c ] T H*c^{'}=H*c+H*e_i=H*e_i=[a,b,c]^T H∗c′=H∗c+H∗ei=H∗ei=[a,b,c]T的结果向量中有多于一个数据位为1则是某个数据位发生了翻转错误。发错误的比特位在码字中的索引为 a × 2 0 + b × 2 1 + c × 2 2 a×2^0+b×2^1+c×2^2 a×20+b×21+c×22,假设此时 r = 3 r=3 r=3, r r r为其它值的情况类似。这里既然已经知道了具体是哪个数据位发生了翻转,那么纠错就很简单了,把对应额哪个发生翻转的位翻转回来就可以了。
那其实解码也是很简单的,根据图4中数据位的存放位置,把对应的数据位取出来就可以了。
可以看到用这种方式编码得到的汉明码属于 n o n − s y s t e m a t i c non-systematic non−systematic,那如果要得到 s y s t e m a t i c systematic systematic类型的应该怎么做。 r = 3 r=3 r=3的时候 n o n − s y s t e m a t i c non-systematic non−systematic类型的 g e n e r a t o r m a t r i x , G generator\quad matrix, G generatormatrix,G为。我们可以知道这个矩阵的每一列对应的码字中的元素为 [ p 1 , p 2 , d 1 , p 3 , d 2 , d 3 , d 4 ] [p_1,p_2,d_1,p_3,d_2,d_3,d_4] [p1,p2,d1,p3,d2,d3,d4]。
G = [ 1 1 1 0 0 0 0 1 0 0 1 1 0 0 0 1 0 1 0 1 0 1 1 0 1 0 0 1 ] G=\begin{bmatrix} 1 & 1 & 1 & 0 & 0 & 0 & 0 \\ 1 & 0 & 0 & 1 & 1 & 0 & 0 \\ 0 & 1 & 0 & 1 & 0 & 1 & 0 \\ 1 & 1 & 0 & 1 & 0 & 0 & 1 \end{bmatrix} G= 1101101110000111010000100001
假设我们现将以前码字中的元素的位置调整一下,假设将以前的码字 [ p 1 , p 2 , d 1 , p 3 , d 2 , d 3 , d 4 ] [p_1,p_2,d_1,p_3,d_2,d_3,d_4] [p1,p2,d1,p3,d2,d3,d4]中的元素的位置调整为 [ d 1 , d 2 , d 3 , d 4 , p 1 , p 2 , p 3 ] [d_1,d_2,d_3,d_4,p_1,p_2,p_3] [d1,d2,d3,d4,p1,p2,p3],相应的也将 g e n e r a t o r m a t r i x , G generator\quad matrix, G generatormatrix,G中的对应列的位置做调整,则调整后的码字对应的编码矩阵 g e n e r a t o r m a t r i x , G generator\quad matrix, G generatormatrix,G为:
G = [ 1 0 0 0 1 1 0 0 1 0 0 1 0 1 0 0 1 0 0 1 1 0 0 0 1 1 1 1 ] G=\begin{bmatrix} 1 & 0 & 0 & 0 & 1 & 1 & 0 \\ 0 & 1 & 0 & 0 & 1 & 0 & 1 \\ 0 & 0 & 1 & 0 & 0 & 1 & 1 \\ 0 & 0 & 0 & 1 & 1 & 1 & 1 \end{bmatrix} G= 1000010000100001110110110111
那么经过该编码矩阵 g e n e r a t o r m a t r i x , G generator\quad matrix, G generatormatrix,G编码后的码字就属于是 s y s t e m a t i c systematic systematic类型的。
根据前面的描述我们知道,在汉明码的探测和纠错过程中需要用到 p a r i t y c h e c k m a t r i x , H parity\quad check\quad matrix, H paritycheckmatrix,H,那么基于现在的 s y s t e m a t i c systematic systematic类型的的编码,又该如何得到对应的 p a r i t y c h e c k m a t r i x , H parity\quad check\quad matrix, H paritycheckmatrix,H。我们知道前面的 n o n − s y s t e m a t i c non-systematic non−systematic类型的的编码的 p a r i t y c h e c k m a t r i x , H parity\quad check\quad matrix, H paritycheckmatrix,H是基于图4得到的,那其实这里我们也可以基于这样的方式来得到 s y s t e m a t i c systematic systematic类型的的编码的 p a r i t y c h e c k m a t r i x , H parity\quad check\quad matrix, H paritycheckmatrix,H,只不过这里要对图4做一点小小的改变,如图5所示。
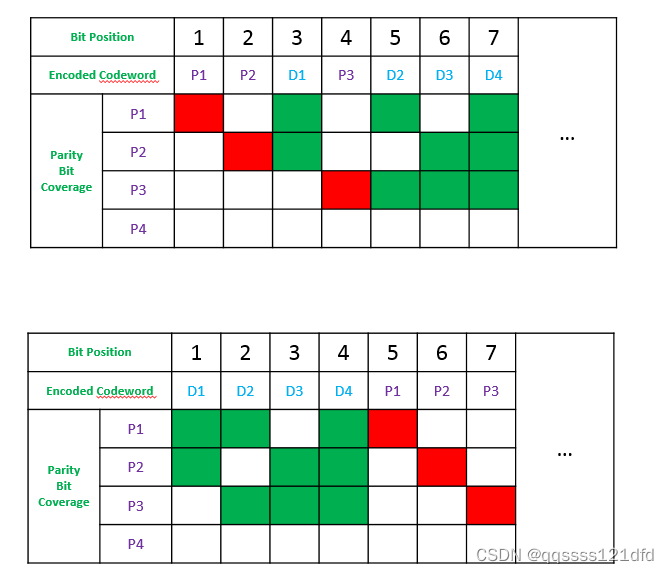
在图5中的上半部分是图4一样的,下半部分是按照前面同样的方式调整了码字中的元素的位置之后对应于图4的图。接下来按照前面的 n o n − s y s t e m a t i c non-systematic non−systematic类型的编码生成 p a r i t y c h e c k m a t r i x , H parity\quad check\quad matrix, H paritycheckmatrix,H的方式生成的 s y s t e m a t i c systematic systematic类型的编码的 p a r i t y c h e c k m a t r i x , H parity\quad check\quad matrix, H paritycheckmatrix,H为:
H = [ 1 1 0 1 1 0 0 1 0 1 1 0 1 0 0 1 1 1 0 0 1 ] H=\begin{bmatrix} 1 & 1 & 0 & 1 &1 & 0 & 0 \\ 1 & 0 & 1 & 1 & 0 & 1 & 0\\ 0 & 1 & 1 & 1 & 0 & 0 & 1 \end{bmatrix} H= 110101011111100010001
其实 n o n − s y s t e m a t i c non-systematic non−systematic类型的编码对应的 p a r i t y c h e c k m a t r i x , H parity\quad check\quad matrix, H paritycheckmatrix,H也可以和 n o n − s y s t e m a t i c non-systematic non−systematic类型的编码的 g e n e r a t o r m a t r i x , G generator\quad matrix, G generatormatrix,G一样,通过对 n o n − s y s t e m a t i c non-systematic non−systematic类型的编码对应的 p a r i t y c h e c k m a t r i x , H parity\quad check\quad matrix, H paritycheckmatrix,H的列做调整来得到 s y s t e m a t i c systematic systematic类型的编码对应的 p a r i t y c h e c k m a t r i x , H parity\quad check\quad matrix, H paritycheckmatrix,H。
我们知道 n o n − s y s t e m a t i c non-systematic non−systematic类型的编码对应的 p a r i t y c h e c k m a t r i x , H parity\quad check\quad matrix, H paritycheckmatrix,H是通过图4得到的,那么这个 n o n − s y s t e m a t i c non-systematic non−systematic类型的编码对应的 p a r i t y c h e c k m a t r i x , H parity\quad check\quad matrix, H paritycheckmatrix,H究竟代表什么意思?
其实我们最开始在描述汉明码的通用算法的时候已经说明了。图4中的 P a r i t y B i t C o v e r a g e Parity\quad Bit\quad Coverage ParityBitCoverage的区域的每一行( p n ( n ≥ 1 ) p_n(n\geq 1) pn(n≥1))说明了每一个冗余数据位( p n ( n ≥ 1 ) p_n(n\geq 1) pn(n≥1))的计算方法,每一行的红色方格表示这一行要计算的是哪一个冗余数据位,这一行的绿色方格表示这一行要计算冗余数据位是基于那些原始要发送的数据位的。比如 P a r i t y B i t C o v e r a g e Parity\quad Bit\quad Coverage ParityBitCoverage区域的 p 1 p_1 p1行( r = 3 r=3 r=3)表示冗余数据位 p 1 p_1 p1位的值为原始要发送的数据位 D 1 D_1 D1, D 2 D_2 D2和 D 4 D_4 D4的奇偶校验位(这里是偶校验)。那么这里从图4中也可以看出来 p a r i t y c h e c k m a t r i x , H parity\quad check\quad matrix, H paritycheckmatrix,H的每一列也对应于编码的码字中的每一个数据位,比如下面是 n o n − s y s t e m a t i c non-systematic non−systematic类型的编码对应的 p a r i t y c h e c k m a t r i x , H parity\quad check\quad matrix, H paritycheckmatrix,H,我们也可以说这个矩阵的每一列分别对应的码字中的数据为为 [ p 1 , p 2 , d 1 , p 3 , d 2 , d 3 , d 4 ] [p_1,p_2,d_1,p_3,d_2,d_3,d_4] [p1,p2,d1,p3,d2,d3,d4],那这种对应到底是什么关系呢?比如这里的第3列对应了数据位 d 1 d_1 d1,而 n o n − s y s t e m a t i c non-systematic non−systematic类型的编码对应的 p a r i t y c h e c k m a t r i x , H parity\quad check\quad matrix, H paritycheckmatrix,H的第三列的第一行和第二行不为0,第三行为0,0对应了图4中 P a r i t y B i t C o v e r a g e Parity\quad Bit\quad Coverage ParityBitCoverage区域的白色方块,1对应了图4中 P a r i t y B i t C o v e r a g e Parity\quad Bit\quad Coverage ParityBitCoverage区域的白色方块。其实这里的对应关系就是 p a r i t y c h e c k m a t r i x , H parity\quad check\quad matrix, H paritycheckmatrix,H的每一行分别表示了每一个冗余数据位,比如第一行代表第一个冗余数据位 p 1 p_1 p1,每一列就表示该数据位会用于那些冗余数据位的计算。比如下面的 n o n − s y s t e m a t i c non-systematic non−systematic类型的编码对应的 p a r i t y c h e c k m a t r i x , H parity\quad check\quad matrix, H paritycheckmatrix,H的第三列的第一行和第二行不为0,第三行为0,则表示数据位 d 1 d_1 d1会参与冗余数据位 p 1 p_1 p1和 p 2 p_2 p2的计算,但是不会参与冗余数据位 p 3 p_3 p3的计算。如果 p a r i t y c h e c k m a t r i x , H parity\quad check\quad matrix, H paritycheckmatrix,H的某一列只有一个不为0的数据,则该列代表码字中的某个冗余数据位。因此可以通过对 n o n − s y s t e m a t i c non-systematic non−systematic类型的编码对应的 p a r i t y c h e c k m a t r i x , H parity\quad check\quad matrix, H paritycheckmatrix,H的列做调整来得到 s y s t e m a t i c systematic systematic类型的编码对应的 p a r i t y c h e c k m a t r i x , H parity\quad check\quad matrix, H paritycheckmatrix,H。
H = [ 1 0 1 0 1 0 1 0 1 1 0 0 1 1 0 0 0 1 1 1 1 ] H=\begin{bmatrix} 1 & 0 & 1 & 0 &1 & 0 & 1 \\ 0 & 1 & 1 & 0 & 0 & 1 & 1 \\ 0 & 0 & 0 & 1 & 1 & 1 & 1 \end{bmatrix} H= 100010110001101011111
到这里 s y s t e m a t i c systematic systematic类型编码的 g e n e r a t o r m a t r i x , G generator\quad matrix, G generatormatrix,G和 p a r i t y c h e c k m a t r i x , H parity\quad check\quad matrix, H paritycheckmatrix,H都已经得到了,那 s y s t e m a t i c systematic systematic类型编码的数据编码,校验,纠错以及解码和 n o n − s y s t e m a t i c non-systematic non−systematic类型编码一样,这里就不再累述了。
前面说过汉明码可以最多检测到2比特的错误,但是无法区分到底是1比特错误还是2比特错误,如果将2比特错误按照1比特错误来纠正的话会造成错误的结果,为了能够区分到底是1比特错误还是2比特错误,目前又引进了一种改进的汉明码,就是在已有汉明码的基础上再多加一个冗余位,使得汉明距离达到4.这样就可以区分到底是1比特错误还是2比特错误。下面我们来简单介绍一下这种改进的汉明码。
下面我们直接给出 r = 3 r=3 r=3的时候这种改进的汉明码的 g e n e r a t o r m a t r i x , G generator\quad matrix, G generatormatrix,G和 p a r i t y c h e c k m a t r i x , H parity\quad check\quad matrix, H paritycheckmatrix,H,这里是 n o n − s y s t e m a t i c non-systematic non−systematic类型的。改进的汉明码的码字为 [ p 1 , p 2 , d 1 , p 3 , d 2 , d 3 , d 4 , p 4 ] [p_1,p_2,d_1,p_3,d_2,d_3,d_4,p_4] [p1,p2,d1,p3,d2,d3,d4,p4]
G = [ 1 1 1 0 0 0 0 1 1 0 0 1 1 0 0 1 0 1 0 1 0 1 0 1 1 1 0 1 0 0 1 0 ] G=\begin{bmatrix} 1 & 1 & 1 & 0 & 0 & 0 & 0 & 1\\ 1 & 0 & 0 & 1 & 1 & 0 & 0 & 1\\ 0 & 1 & 0 & 1 & 0 & 1 & 0 & 1\\ 1 & 1 & 0 & 1 & 0 & 0 & 1 & 0 \end{bmatrix} G= 11011011100001110100001000011110
H = [ 1 0 1 0 1 0 1 0 0 1 1 0 0 1 1 0 0 0 0 1 1 1 1 0 1 1 1 1 1 1 1 1 ] H=\begin{bmatrix} 1 & 0 & 1 & 0 &1 & 0 & 1 & 0\\ 0 & 1 & 1 & 0 & 0 & 1 & 1 & 0\\ 0 & 0 & 0 & 1 & 1 & 1 & 1 & 0\\ 1 & 1 & 1 & 1 &1 & 1 & 1& 1 \end{bmatrix} H= 10010101110100111011011111110001
这里最明显的变化是 g e n e r a t o r m a t r i x , G generator\quad matrix, G generatormatrix,G和 p a r i t y c h e c k m a t r i x , H parity\quad check\quad matrix, H paritycheckmatrix,H都变成了 4 × 8 4\times8 4×8矩阵,而不是以前的 3 × 7 3\times7 3×7矩阵。因此额外添加的冗余数据位为原始要发送的数据位(假设原始要发送的数据位有n个: d 1 d_1 d1, d 2 d_2 d2,…, d n − 1 d_{n-1} dn−1, d n d_n dn) d 1 d_1 d1, d 2 d_2 d2,…, d n − 1 d_{n-1} dn−1计算得到的偶校验值,这里 r = 3 r=3 r=3的时候额外添加的冗余数据位 p 4 p_4 p4为原始要发送的数据位 d 1 d_1 d1, d 2 d_2 d2, d 3 d_{3} d3计算得到的偶校验值。还有就是改进的汉明码的 p a r i t y c h e c k m a t r i x , H parity\quad check\quad matrix, H paritycheckmatrix,H的最后一行会将接收到的码字的所有位都拿来进行奇偶校验。
这里的改进的汉明码的 g e n e r a t o r m a t r i x , G generator\quad matrix, G generatormatrix,G和 p a r i t y c h e c k m a t r i x , H parity\quad check\quad matrix, H paritycheckmatrix,H都是 n o n − s y s t e m a t i c non-systematic non−systematic类型的,当然这里我们也可以和前面一样通过简单的矩阵中的列的互换来转换成 s y s t e m a t i c systematic systematic类型的,如下所示:
G = [ 1 0 0 0 1 1 0 1 0 1 0 0 1 0 1 1 0 0 1 0 0 1 1 1 0 0 0 1 1 1 1 0 ] G=\begin{bmatrix} 1 & 0 & 0 & 0 & 1 & 1 & 0 & 1\\ 0 & 1 & 0 & 0 & 1 & 0 & 1 & 1\\ 0 & 0 & 1 & 0 & 0 & 1 & 1 & 1\\ 0 & 0 & 0 & 1 & 1 & 1 & 1 & 0 \end{bmatrix} G= 10000100001000011101101101111110
H = [ 1 1 0 1 1 0 0 0 1 0 1 1 0 1 0 0 0 1 1 1 0 0 1 0 1 1 1 1 1 1 1 1 ] H=\begin{bmatrix} 1 & 1 & 0 & 1 &1 & 0 & 0 & 0\\ 1 & 0 & 1 & 1 & 0 & 1 & 0& 0\\ 0 & 1 & 1 & 1 & 0 & 0 & 1 & 0\\ 1 & 1 & 1 & 1 &1 & 1 & 1& 1 \end{bmatrix} H= 11011011011111111001010100110001
没有改进的汉明码的 n o n − s y s t e m a t i c non-systematic non−systematic类型的 g e n e r a t o r m a t r i x , G generator\quad matrix, G generatormatrix,G和 p a r i t y c h e c k m a t r i x , H parity\quad check\quad matrix, H paritycheckmatrix,H如下所示:
G = [ 1 0 0 0 1 1 0 0 1 0 0 1 0 1 0 0 1 0 0 1 1 0 0 0 1 1 1 1 ] G=\begin{bmatrix} 1 & 0 & 0 & 0 & 1 & 1 & 0 \\ 0 & 1 & 0 & 0 & 1 & 0 & 1 \\ 0 & 0 & 1 & 0 & 0 & 1 & 1 \\ 0 & 0 & 0 & 1 & 1 & 1 & 1 \end{bmatrix} G= 1000010000100001110110110111
H = [ 1 1 0 1 1 0 0 1 0 1 1 0 1 0 0 1 1 1 0 0 1 ] H=\begin{bmatrix} 1 & 1 & 0 & 1 &1 & 0 & 0 \\ 1 & 0 & 1 & 1 & 0 & 1 & 0\\ 0 & 1 & 1 & 1 & 0 & 0 & 1 \end{bmatrix} H= 110101011111100010001
我们可以看到没有改进的汉明码的 n o n − s y s t e m a t i c non-systematic non−systematic类型的 g e n e r a t o r m a t r i x , G generator\quad matrix, G generatormatrix,G可以写为 [ I k , P ] [I_k,P] [Ik,P],其中 I k I_k Ik为行和列都有 k k k个元素的单位矩阵, P P P为 k × ( n − k ) k\times(n-k) k×(n−k)的矩阵,这里n为编码后的码字中的位的个数,k为原始要发送的数据位的个数。那么改进的汉明码的 n o n − s y s t e m a t i c non-systematic non−systematic类型的 p a r i t y c h e c k m a t r i x , H parity\quad check\quad matrix, H paritycheckmatrix,H为 [ − P T , I n − k ] [-P^T,I_{n-k}] [−PT,In−k]= [ P T , I n − k ] [P^T,I_{n-k}] [PT,In−k]。还有这里 g e n e r a t o r m a t r i x , G generator\quad matrix, G generatormatrix,G和 p a r i t y c h e c k m a t r i x , H parity\quad check\quad matrix, H paritycheckmatrix,H满足 G ∗ H T G*H^T G∗HT为0矩阵(这里 n o n − s y s t e m a t i c non-systematic non−systematic类型和 s y s t e m a t i c systematic systematic类型都满足,普通型肯定满足,改进型我这里有待确认,但是我认为是可以的)。
这里就是汉明码的巧妙,也是数学的巧妙,没想到转换为矩阵的操作之后可以有这样的效果。但是前面也说过了,我目前没有这方面的积累以及足够的时间,因此这里涉及到数学方面的我就不讲了,自己感兴趣的可以自己去查询相关的资料。
我们可以看到经过交换改进的汉明码的 n o n − s y s t e m a t i c non-systematic non−systematic类型的 g e n e r a t o r m a t r i x , G generator\quad matrix, G generatormatrix,G而得到的改进的汉明码的 s y s t e m a t i c systematic systematic类型的 g e n e r a t o r m a t r i x , G generator\quad matrix, G generatormatrix,G满足 [ I k , P ] [I_k,P] [Ik,P],但是经过交换改进的汉明码的 n o n − s y s t e m a t i c non-systematic non−systematic类型的 p a r i t y c h e c k m a t r i x , H parity\quad check\quad matrix, H paritycheckmatrix,H而得到的改进的汉明码的 s y s t e m a t i c systematic systematic类型的 p a r i t y c h e c k m a t r i x , H parity\quad check\quad matrix, H paritycheckmatrix,H不满足 [ P T , I n − k ] [P^T,I_{n-k}] [PT,In−k],因为这里的 p a r i t y c h e c k m a t r i x , H parity\quad check\quad matrix, H paritycheckmatrix,H最后一行的所有元素都为1,但是这里可以通过的线性运算(数乘和加法)来将改进的汉明码的 p a r i t y c h e c k m a t r i x , H parity\quad check\quad matrix, H paritycheckmatrix,H转换为符合 [ P T , I n − k ] [P^T,I_{n-k}] [PT,In−k]的 s y s t e m a t i c systematic systematic类型。但是这里又是数学运算的问题了,因此这里涉及到数学方面的我就不讲了,自己感兴趣的可以自己去查询相关的资料。至于这里改进的汉明码能不能满足 [ I k , P ] [I_k,P] [Ik,P]到 [ P T , I n − k ] [P^T,I_{n-k}] [PT,In−k]的对应关系我就不是太清楚了,但是我认为是满足的,只是有待查资料确认。
至于改进的汉明码的的编码解码就没什么好说的了。至于探测和纠错,我们看一下下面改进的汉明码的 n o n − s y s t e m a t i c non-systematic non−systematic类型的 p a r i t y c h e c k m a t r i x , H parity\quad check\quad matrix, H paritycheckmatrix,H和接收到的码字的乘法的结果。
H ∗ c = [ 1 0 1 0 1 0 1 0 0 1 1 0 0 1 1 0 0 0 0 1 1 1 1 0 1 1 1 1 1 1 1 1 ] [ p 1 p 2 d 1 p 3 d 2 d 3 d 4 p 4 ] = [ p 1 + d 1 + d 2 + d 4 p 2 + d 1 + d 3 + d 4 p 3 + d 2 + d 3 + d 4 p 1 + p 2 + p 3 + p 4 + d 1 + d 2 + d 3 + d 4 ] H*c=\begin{bmatrix} 1 & 0 & 1 & 0 &1 & 0 & 1 & 0\\ 0 & 1 & 1 & 0 & 0 & 1 & 1 & 0\\ 0 & 0 & 0 & 1 & 1 & 1 & 1 & 0\\ 1 & 1 & 1 & 1 & 1 & 1 & 1 & 1 \end{bmatrix}\begin{bmatrix} p_1 \\ p_2 \\ d_1 \\ p_3 \\ d_2 \\ d_3 \\ d_4\\ p_4 \end{bmatrix}=\begin{bmatrix} p_1+d_1 + d_2+d_4 \\ p_2+d_1 + d_3+d_4 \\ p_3+d_2 + d_3+d_4 \\ p_1+p_2+p_3+p_4+d_1 + d_2+d_3+d_4 \end{bmatrix} H∗c= 10010101110100111011011111110001 p1p2d1p3d2d3d4p4 = p1+d1+d2+d4p2+d1+d3+d4p3+d2+d3+d4p1+p2+p3+p4+d1+d2+d3+d4
结果的前三个没什么好说的,和没有改进的汉明码一样,如果码字在传输过程中没有出错的话,这三个值肯定都是0。如果码字在传输过程中没有出错的话,最后一个值 p 1 + p 2 + p 3 + p 4 + d 1 + d 2 + d 3 + d 4 p_1+p_2+p_3+p_4+d_1 + d_2+d_3+d_4 p1+p2+p3+p4+d1+d2+d3+d4肯定也是0。这是因为:
- p 1 p_1 p1是基于 d 1 d_1 d1, d 2 d_2 d2和 d 4 d_4 d4计算得到的偶校验码,因此 p 1 p_1 p1可以写为 p 1 = d 1 + d 2 + d 4 p_1=d_1+d_2+d_4 p1=d1+d2+d4
- p 2 p_2 p2是基于 d 1 d_1 d1, d 3 d_3 d3和 d 4 d_4 d4计算得到的偶校验码,因此 p 2 p_2 p2可以写为 p 2 = d 1 + d 3 + d 4 p_2=d_1+d_3+d_4 p2=d1+d3+d4
- p 3 p_3 p3是基于 d 2 d_2 d2, d 3 d_3 d3和 d 4 d_4 d4计算得到的偶校验码,因此 p 3 p_3 p3可以写为 p 3 = d 2 + d 3 + d 4 p_3=d_2+d_3+d_4 p3=d2+d3+d4
- p 4 p_4 p4是基于 d 1 d_1 d1, d 2 d_2 d2和 d 3 d_3 d3计算得到的偶校验码,因此 p 4 p_4 p4可以写为 p 3 = d 1 + d 2 + d 3 p_3=d_1+d_2+d_3 p3=d1+d2+d3
因此 p 1 + p 2 + p 3 + p 4 + d 1 + d 2 + d 3 + d 4 p_1+p_2+p_3+p_4+d_1 + d_2+d_3+d_4 p1+p2+p3+p4+d1+d2+d3+d4= 4 ∗ d 1 + 4 ∗ d 2 + 4 ∗ d 3 + 4 ∗ d 4 = 0 4*d_1 + 4*d_2+4*d_3+4*d_4=0 4∗d1+4∗d2+4∗d3+4∗d4=0(偶校验运算)。前面我们说过汉明码可以最多检测到2比特的错误,但是无法区分到底是1比特错误还是2比特错误,如果将2比特错误按照1比特错误来纠正的话会造成错误的结果。但是改进的汉明码可以区分到底是1比特错误还是2比特错误。下面我直接给结论,至于原理需要一定的数学背景,我也不会,我也没时间,大家有空的话自己去查一下相关的资料。
我这里的结论来自于图6的文档,文档在这里。

图6这里描述到,如果对于改进的汉明码,如果接收到的码字和 p a r i t y c h e c k m a t r i x , H parity\quad check\quad matrix, H paritycheckmatrix,H乘积为:
[ s p ] \begin{bmatrix} s \\ p \end{bmatrix} [sp]
其中 s s s对应于没有改进的汉明码,接收到的码字和 p a r i t y c h e c k m a t r i x , H parity\quad check\quad matrix, H paritycheckmatrix,H乘积,如果 r = 3 r=3 r=3的话,这里的 s s s中有3个元素。 p p p对应于改进的汉明码中接收到的码字中的所有元素的偶校验位。结论为:
- 如果 s = 0 s=0 s=0且 p = 0 p=0 p=0,则接收到的码字中没有任何错误。
- 如果 s ≠ 0 s\neq0 s=0且 p = 0 p=0 p=0,则接收到的码字中有两个比特错误且无法进行纠错。
- 如果 s = 0 s=0 s=0且 p = 1 p=1 p=1,则接收到的码字只有一个比特错误且这个错误的比特位是奇偶校验位。
- 如果 s ≠ 0 s\neq0 s=0且 p = 1 p=1 p=1,则接收到的码字只有一个比特错误且这个错误的比特位是数据位,且数据位的值可以根据 s s s的值来确定,和没有改进的汉明码的探测和纠错一样。
因此改进的汉明码的探测和纠错和没有改进的汉明码基本大致一样。 最后再强调一下使用汉明码的纠错码只能纠错一位出错的数据,所以在使用之前需要确保使用的场景中最多只会出现一位的错误,否则最后纠错的结果就不是正确的结果,这一点一定要注意。
前面已经提到汉明码最常用在 s i n g l e l e v e l c e l l N A N D f l a s h single\quad level\quad cell\quad NAND\quad flash singlelevelcellNANDflash存储器的纠错。我看了几个 N A N D f l a s h NAND\quad flash NANDflash存储器厂商的文档,文档在这里:NAND FLASH ECC,这些文档都一致的说明了,在256个字节数据上的冗余 E C C ECC ECC数据位为22比特,在512个字节数据上的冗余 E C C ECC ECC数据位为24比特但是这个数字很难和前面介绍的汉明码的通用算法公式对应起来:对于每一个整数 r , r ≥ 2 , r,r\geq2, r,r≥2,假设加到要传输的数据的冗余的大小为 r r r个比特位,则要传输的数据的实际的比特个数为 2 r − r − 1 2^r-r-1 2r−r−1,因此最后实际要传输的数据额比特位的个数为 2 r − 1 2^r-1 2r−1。这里 2 22 = 4194304 b i t s = 524288 b y t e s 2^{22}=4194304bits=524288bytes 222=4194304bits=524288bytes,远远不是描述的256字节。还有就是厂商文档里面描述的冗余 E C C ECC ECC数据的算法我也很难和前面描述的汉明算法的通用算法联系起来,唯一相同的就是它们都利用了奇偶校验的这个原理。是不是它们采用的是一种变种算法。



下面我将会对 N A N D F L A S H NAND\quad FLASH NANDFLASH厂商的文档(如图7,图8和图9所示)中描述的所谓的汉明码 E C C ECC ECC算法做一个简单的介绍,一般的通用 M C U MCU MCU上面的 F S M C , F l e x i b l e s t a t i c m e m o r y c o n t r o l l e r FSMC,Flexible\quad static\quad memory\quad controller FSMC,Flexiblestaticmemorycontroller模块,也就是外部存储器控制器接口的 N A N D F L A S H NAND\quad FLASH NANDFLASH接口的硬件 E C C ECC ECC算法好像也是采用的这种算法。一般该汉明码 E C C ECC ECC算法在256个字节数据上的冗余 E C C ECC ECC数据位为22比特,在512个字节数据上的冗余 E C C ECC ECC数据位为24比特。下面的介绍先基于图7中的文档
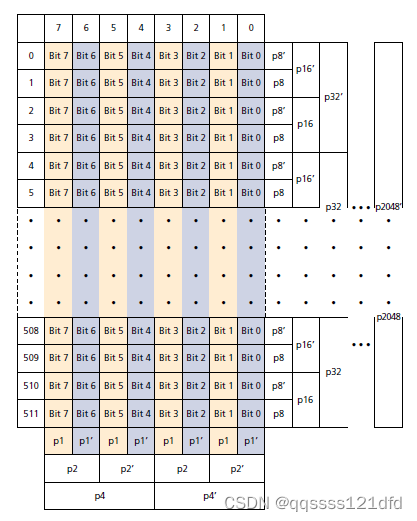
图10 是512个字节的数据块的24位冗余 E C C ECC ECC数据的算法。这24位的冗余 E C C ECC ECC数据可以分为两部分:行冗余数据:16位, p 8 , p 8 ′ , p 16 , p 16 ′ , . . . , p 2048 , p 2048 ′ p_8,p_{8^{'}},p_{16},p_{{16}^{'}},...,p_{2048},p_{{2048}^{'}} p8,p8′,p16,p16′,...,p2048,p2048′和列冗余数据:6位, p 1 , p 1 ′ , p 2 , p 2 ′ , p 4 , p 4 ′ p_1,p_{1^{'}},p_2,p_{2^{'}},p_4,p_{4^{'}} p1,p1′,p2,p2′,p4,p4′。其中 ⊕ \oplus ⊕表示异或运算。下面是当 E C C ECC ECC冗余数据计算模块读入512个字节的数据块的第一个字节数据的时候列冗余数据的计算方法。
- p 1 = B i t 7 ⊕ B i t 5 ⊕ B i t 3 ⊕ B i t 1 p_1=Bit\ 7\oplus Bit\ 5\oplus Bit\ 3\oplus Bit\ 1 p1=Bit 7⊕Bit 5⊕Bit 3⊕Bit 1
- p 1 ′ = B i t 6 ⊕ B i t 4 ⊕ B i t 2 ⊕ B i t 0 p_{1^{'}}=Bit\ 6\oplus Bit\ 4\oplus Bit\ 2\oplus Bit\ 0 p1′=Bit 6⊕Bit 4⊕Bit 2⊕Bit 0
- p 2 = B i t 7 ⊕ B i t 6 ⊕ B i t 3 ⊕ B i t 2 p_2=Bit\ 7\oplus Bit\ 6\oplus Bit\ 3\oplus Bit\ 2 p2=Bit 7⊕Bit 6⊕Bit 3⊕Bit 2
- p 2 ′ = B i t 5 ⊕ B i t 4 ⊕ B i t 1 ⊕ B i t 0 p_{2^{'}}=Bit\ 5\oplus Bit\ 4\oplus Bit\ 1\oplus Bit\ 0 p2′=Bit 5⊕Bit 4⊕Bit 1⊕Bit 0
- p 4 = B i t 7 ⊕ B i t 6 ⊕ B i t 5 ⊕ B i t 4 p_4=Bit\ 7\oplus Bit\ 6\oplus Bit\ 5\oplus Bit\ 4 p4=Bit 7⊕Bit 6⊕Bit 5⊕Bit 4
- p 4 ′ = B i t 3 ⊕ B i t 2 ⊕ B i t 1 ⊕ B i t 0 p_{4^{'}}=Bit\ 3\oplus Bit\ 2\oplus Bit\ 1\oplus Bit\ 0 p4′=Bit 3⊕Bit 2⊕Bit 1⊕Bit 0
当读入512个字节的数据块的后续字节数据的时候列冗余数据的计算方法如下,也就是冗余数据位本身现在也要参与运算:
- p 1 = B i t 7 ⊕ B i t 5 ⊕ B i t 3 ⊕ B i t 1 ⊕ p 1 p_1=Bit\ 7\oplus Bit\ 5\oplus Bit\ 3\oplus Bit\ 1\oplus p_1 p1=Bit 7⊕Bit 5⊕Bit 3⊕Bit 1⊕p1
- p 1 ′ = B i t 6 ⊕ B i t 4 ⊕ B i t 2 ⊕ B i t 0 ⊕ p 1 ′ p_{1^{'}}=Bit\ 6\oplus Bit\ 4\oplus Bit\ 2\oplus Bit\ 0\oplus p_{1^{'}} p1′=Bit 6⊕Bit 4⊕Bit 2⊕Bit 0⊕p1′
- p 2 = B i t 7 ⊕ B i t 6 ⊕ B i t 3 ⊕ B i t 2 ⊕ p 2 p_2=Bit\ 7\oplus Bit\ 6\oplus Bit\ 3\oplus Bit\ 2\oplus p_2 p2=Bit 7⊕Bit 6⊕Bit 3⊕Bit 2⊕p2
- p 2 ′ = B i t 5 ⊕ B i t 4 ⊕ B i t 1 ⊕ B i t 0 ⊕ p 2 ′ p_{2^{'}}=Bit\ 5\oplus Bit\ 4\oplus Bit\ 1\oplus Bit\ 0\oplus p_{2^{'}} p2′=Bit 5⊕Bit 4⊕Bit 1⊕Bit 0⊕p2′
- p 4 = B i t 7 ⊕ B i t 6 ⊕ B i t 5 ⊕ B i t 4 ⊕ p 4 p_4=Bit\ 7\oplus Bit\ 6\oplus Bit\ 5\oplus Bit\ 4\oplus p_4 p4=Bit 7⊕Bit 6⊕Bit 5⊕Bit 4⊕p4
- p 4 ′ = B i t 3 ⊕ B i t 2 ⊕ B i t 1 ⊕ B i t 0 ⊕ p 4 ′ p_{4^{'}}=Bit\ 3\oplus Bit\ 2\oplus Bit\ 1\oplus Bit\ 0\oplus p_{4^{'}} p4′=Bit 3⊕Bit 2⊕Bit 1⊕Bit 0⊕p4′
E C C ECC ECC冗余数据的行冗余数据的计算就要特殊一点,但是相对也简单一点。当读入512个字节的数据块的每一个字节数据的时候,该字节的素有位都会参与行冗余数据位的计算,不像列冗余数据位计算的时候那样会对读入的字节数据的部分位来进行计算。但是比较特别是对于读入的这512(索引, i n d e x index index,为0到511)个字节的数据:
-
如果 i n d e x & ( 0 x 0001 ) ≠ 0 index\ \&\ (0x0001)\neq0 index & (0x0001)=0,那么该字节的所有比特位异或的结果得到 p 8 p_8 p8,如果这里先前已经有512个字节的数据中的某一个数据用来计算得到 p 8 p_8 p8的话,那么 p 8 p_8 p8本身也得参与计算得到 p 8 p_8 p8。也就是:
- p 8 = B i t 7 ⊕ B i t 6 ⊕ B i t 5 ⊕ B i t 4 ⊕ B i t 3 ⊕ B i t 2 ⊕ B i t 1 ⊕ B i t 0 p_8=Bit\ 7\oplus Bit\ 6\oplus Bit\ 5\oplus Bit\ 4\oplus Bit\ 3\oplus Bit\ 2\oplus Bit\ 1\oplus Bit\ 0 p8=Bit 7⊕Bit 6⊕Bit 5⊕Bit 4⊕Bit 3⊕Bit 2⊕Bit 1⊕Bit 0
- 或
- p 8 = B i t 7 ⊕ B i t 6 ⊕ B i t 5 ⊕ B i t 4 ⊕ B i t 3 ⊕ B i t 2 ⊕ B i t 1 ⊕ B i t 0 ⊕ p 8 p_8=Bit\ 7\oplus Bit\ 6\oplus Bit\ 5\oplus Bit\ 4\oplus Bit\ 3\oplus Bit\ 2\oplus Bit\ 1\oplus Bit\ 0\oplus p_8 p8=Bit 7⊕Bit 6⊕Bit 5⊕Bit 4⊕Bit 3⊕Bit 2⊕Bit 1⊕Bit 0⊕p8
-
如果 i n d e x & ( 0 x 0001 ) = 0 index\ \&\ (0x0001)=0 index & (0x0001)=0,那么该字节的所有比特位异或的结果得到 p 8 ′ p_{8^{'}} p8′,如果这里先前已经有512个字节的数据中的某一个数据用来计算得到 p 8 ′ p_{8^{'}} p8′的话,那么 p 8 ′ p_{8^{'}} p8′本身也得参与计算得到 p 8 ′ p_{8^{'}} p8′。
-
如果 i n d e x & ( 0 x 0002 ) ≠ 0 index\ \&\ (0x0002)\neq0 index & (0x0002)=0,那么该字节的所有比特位异或的结果得到 p 16 p_{16} p16,如果这里先前已经有512个字节的数据中的某一个数据用来计算得到 p 16 p_{16} p16的话,那么 p 16 p_{16} p16本身也得参与计算得到 p 16 p_{16} p16。
-
如果 i n d e x & ( 0 x 0002 ) = 0 index\ \&\ (0x0002)=0 index & (0x0002)=0,那么该字节的所有比特位异或的结果得到 p 16 ′ p_{{16}^{'}} p16′,如果这里先前已经有512个字节的数据中的某一个数据用来计算得到 p 16 ′ p_{{16}^{'}} p16′的话,那么 p 16 ′ p_{{16}^{'}} p16′本身也得参与计算得到 p 16 ′ p_{{16}^{'}} p16′。
-
如果 i n d e x & ( 0 x 0004 ) ≠ 0 index\ \&\ (0x0004)\neq0 index & (0x0004)=0,那么该字节的所有比特位异或的结果得到 p 32 p_{32} p32,如果这里先前已经有512个字节的数据中的某一个数据用来计算得到 p 32 p_{32} p32的话,那么 p 32 p_{32} p32本身也得参与计算得到 p 32 p_{32} p32。也就是:
-
如果 i n d e x & ( 0 x 0004 ) = 0 index\ \&\ (0x0004)=0 index & (0x0004)=0,那么该字节的所有比特位异或的结果得到 p 32 ′ p_{{32}^{'}} p32′,如果这里先前已经有512个字节的数据中的某一个数据用来计算得到 p 32 ′ p_{{32}^{'}} p32′的话,那么 p 32 ′ p_{{32}^{'}} p32′本身也得参与计算得到 p 32 ′ p_{{32}^{'}} p32′。
-
如果 i n d e x & ( 0 x 0008 ) ≠ 0 index\ \&\ (0x0008)\neq0 index & (0x0008)=0,那么该字节的所有比特位异或的结果得到 p 64 p_{64} p64,如果这里先前已经有512个字节的数据中的某一个数据用来计算得到 p 64 p_{64} p64的话,那么 p 64 p_{64} p64本身也得参与计算得到 p 64 p_{64} p64。也就是:
-
如果 i n d e x & ( 0 x 0008 ) = 0 index\ \&\ (0x0008)=0 index & (0x0008)=0,那么该字节的所有比特位异或的结果得到 p 64 ′ p_{{64}^{'}} p64′,如果这里先前已经有512个字节的数据中的某一个数据用来计算得到 p 64 ′ p_{{64}^{'}} p64′的话,那么 p 64 ′ p_{{64}^{'}} p64′本身也得参与计算得到 p 64 ′ p_{{64}^{'}} p64′。
-
如果 i n d e x & ( 0 x 0010 ) ≠ 0 index\ \&\ (0x0010)\neq0 index & (0x0010)=0,那么该字节的所有比特位异或的结果得到 p 128 p_{128} p128,如果这里先前已经有512个字节的数据中的某一个数据用来计算得到 p 128 p_{128} p128的话,那么 p 128 p_{128} p128本身也得参与计算得到 p 128 p_{128} p128。也就是:
-
如果 i n d e x & ( 0 x 0010 ) = 0 index\ \&\ (0x0010)=0 index & (0x0010)=0,那么该字节的所有比特位异或的结果得到 p 128 ′ p_{{128}^{'}} p128′,如果这里先前已经有512个字节的数据中的某一个数据用来计算得到 p 128 ′ p_{{128}^{'}} p128′的话,那么 p 128 ′ p_{{128}^{'}} p128′本身也得参与计算得到 p 128 ′ p_{{128}^{'}} p128′。
-
如果 i n d e x & ( 0 x 0020 ) ≠ 0 index\ \&\ (0x0020)\neq0 index & (0x0020)=0,那么该字节的所有比特位异或的结果得到 p 256 p_{256} p256,如果这里先前已经有512个字节的数据中的某一个数据用来计算得到 p 256 p_{256} p256的话,那么 p 256 p_{256} p256本身也得参与计算得到 p 256 p_{256} p256。也就是:
-
如果 i n d e x & ( 0 x 0020 ) = 0 index\ \&\ (0x0020)=0 index & (0x0020)=0,那么该字节的所有比特位异或的结果得到 p 256 ′ p_{{256}^{'}} p256′,如果这里先前已经有512个字节的数据中的某一个数据用来计算得到 p 256 ′ p_{{256}^{'}} p256′的话,那么 p 256 ′ p_{{256}^{'}} p256′本身也得参与计算得到 p 256 ′ p_{{256}^{'}} p256′。
-
如果 i n d e x & ( 0 x 0040 ) ≠ 0 index\ \&\ (0x0040)\neq0 index & (0x0040)=0,那么该字节的所有比特位异或的结果得到 p 512 p_{512} p512,如果这里先前已经有512个字节的数据中的某一个数据用来计算得到 p 512 p_{512} p512的话,那么 p 512 p_{512} p512本身也得参与计算得到 p 512 p_{512} p512。也就是:
-
如果 i n d e x & ( 0 x 0040 ) = 0 index\ \&\ (0x0040)=0 index & (0x0040)=0,那么该字节的所有比特位异或的结果得到 p 512 ′ p_{{512}^{'}} p512′,如果这里先前已经有512个字节的数据中的某一个数据用来计算得到 p 512 ′ p_{{512}^{'}} p512′的话,那么 p 512 ′ p_{{512}^{'}} p512′本身也得参与计算得到 p 512 ′ p_{{512}^{'}} p512′。
-
如果 i n d e x & ( 0 x 0080 ) ≠ 0 index\ \&\ (0x0080)\neq0 index & (0x0080)=0,那么该字节的所有比特位异或的结果得到 p 1024 p_{1024} p1024,如果这里先前已经有1024个字节的数据中的某一个数据用来计算得到 p 1024 p_{1024} p1024的话,那么 p 1024 p_{1024} p1024本身也得参与计算得到 p 1024 p_{1024} p1024。也就是:
-
如果 i n d e x & ( 0 x 0080 ) = 0 index\ \&\ (0x0080)=0 index & (0x0080)=0,那么该字节的所有比特位异或的结果得到 p 1024 ′ p_{{1024}^{'}} p1024′,如果这里先前已经有1024个字节的数据中的某一个数据用来计算得到 p 1024 ′ p_{{1024}^{'}} p1024′的话,那么 p 1024 ′ p_{{1024}^{'}} p1024′本身也得参与计算得到 p 1024 ′ p_{{1024}^{'}} p1024′。
-
如果 i n d e x & ( 0 x 0100 ) ≠ 0 index\ \&\ (0x0100)\neq0 index & (0x0100)=0,那么该字节的所有比特位异或的结果得到 p 2048 p_{2048} p2048,如果这里先前已经有2048个字节的数据中的某一个数据用来计算得到 p 2048 p_{2048} p2048的话,那么 p 2048 p_{2048} p2048本身也得参与计算得到 p 2048 p_{2048} p2048。也就是:
-
如果 i n d e x & ( 0 x 0100 ) = 0 index\ \&\ (0x0100)=0 index & (0x0100)=0,那么该字节的所有比特位异或的结果得到 p 2048 ′ p_{{2048}^{'}} p2048′,如果这里先前已经有2048个字节的数据中的某一个数据用来计算得到 p 2048 ′ p_{{2048}^{'}} p2048′的话,那么 p 2048 ′ p_{{2048}^{'}} p2048′本身也得参与计算得到 p 2048 ′ p_{{2048}^{'}} p2048′。
所有 E C C ECC ECC冗余数据计算完成之后的排布图11所示:

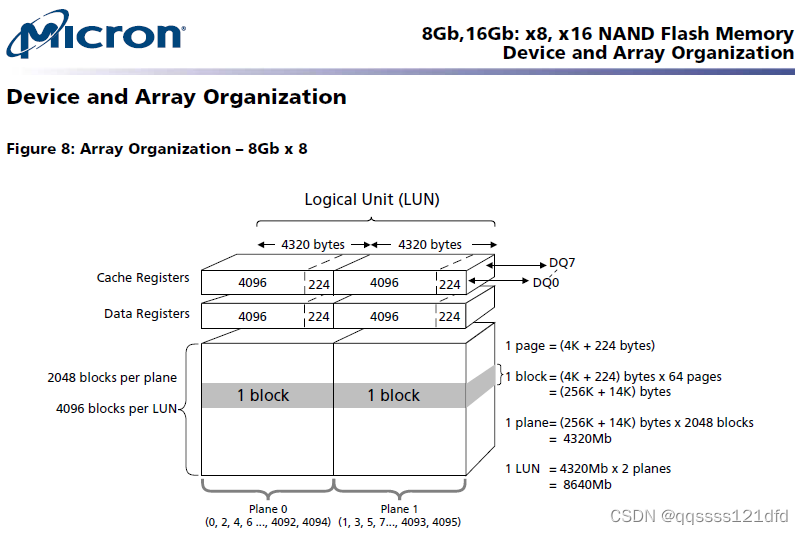
N A N D F L A S H NAND\quad FLASH NANDFLASH相比起 N O R F L A S H NOR\quad FLASH NORFLASH的一点区别是, N A N D F L A S H NAND\quad FLASH NANDFLASH的每一页存储空间都有对应的 s p a r e spare spare区域,如图12所示。这里是在网上随便找的一款 N A N D F L A S H NAND\quad FLASH NANDFLASH的数据手册里面对该 N A N D F L A S H NAND\quad FLASH NANDFLASH的存储空间的图示,从图中我们可以看到该 N A N D F L A S H NAND\quad FLASH NANDFLASH的每一页的大小为4096字节,每一页的 s p a r e spare spare区域的大小为224字节。如果访问 N A N D F L A S H NAND\quad FLASH NANDFLASH的通用 M C U MCU MCU的 F S M C FSMC FSMC模块有使能 E C C ECC ECC功能的话,那么每次向 N A N D F L A S H NAND\quad FLASH NANDFLASH写入一定的数据后(一般是512字节) F S M C FSMC FSMC模块会计算写入的数据(发送的命令不会参与运算)的冗余 E C C ECC ECC数据,如果是按照前面的算法计算的话就应该是24比特位。用户可以将该计算的冗余 E C C ECC ECC数据放在该页对应的 s p a r e spare spare区域。下次去读这一块数据的时候, F S M C FSMC FSMC模块也会计算读出数据(发送的命令不会参与运算)的冗余 E C C ECC ECC数据,这样通过对比读出的时候计算出的冗余 E C C ECC ECC数据和保存在 s p a r e spare spare区域的上次写入的时候计算的冗余 E C C ECC ECC数据就可以判断是否发生了错误。
假设这里读写的数据块的大小为512字节,则按照上面的算法计算得到的冗余 E C C ECC ECC数据的大小为24个比特位。将读出的时候计算出的冗余 E C C ECC ECC数据和保存在 s p a r e spare spare区域的上次写入的时候计算的冗余 E C C ECC ECC数据进行异或运算:
- 如果异或的结果为全0则说明没有错误
- 如果异或的结果只有一个比特位为1,则说明数据本身没有错误而是该位对应的冗余 E C C ECC ECC数据翻转出错了。这里和我们前面介绍的标准汉明码的检测和纠错结果是一样的
- 如果 < p n , p n ′ > , n = 1 , 2 , 4 , 8 , . . . , 1024 , 2048
- 对于以上情况的其它情况可能是出现了两个或多个比特错误且是无法更正的。
因为篇幅有限,接下来接续到:纠错码(Error correction code,ECC)中的汉明码,NAND FLASH中的纠错码(第二部分)
本文来自互联网用户投稿,文章观点仅代表作者本人,不代表本站立场,不承担相关法律责任。如若转载,请注明出处。 如若内容造成侵权/违法违规/事实不符,请点击【内容举报】进行投诉反馈!