Spark SQL BI分析
Spark SQL 编程指南
Spark SQL是用于结构化数据处理的一个模块。同Spark RDD 不同地方在于Spark SQL的API可以给Spark计算引擎提供更多地 信息,例如:数据结构、计算算子等。在内部Spark可以通过这些信息有针对对任务做优化和调整。这里有几种方式和Spark SQL进行交互,例如Dataset API和SQL等,这两种API可以混合使用。Spark SQL的一个用途是执行SQL查询。 Spark SQL还可用于从现有Hive安装中读取数据。从其他编程语言中运行SQL时,结果将作为Dataset/DataFrame返回,使用命令 行或JDBC / ODBC与SQL接口进行交互。
Dataset是一个分布式数据集合在Spark 1.6提供一个新的接口,Dataset提供RDD的优势(强类型,使用强大的lambda函 数)以及具备了Spark SQL执行引擎的优点。Dataset可以通过JVM对象构建,然后可以使用转换函数等(例如:map、flatMap、filter等),目前Dataset API支持Scala和Java 目前Python对Dataset支持还不算完备。
DataFrame是命名列的数据集,他在概念是等价于关系型数据库。DataFrames可以从很多地方构建,比如说结构化数据文 件、hive中的表或者外部数据库,使用Dataset[Row]的数据集,可以理解DataFrame就是一个Dataset[Row]–> RDD[Row].
SparkSession
Spark中所有功能的入口点是SparkSession类。要创建基本的SparkSession,只需使用SparkSession.builder():
- 依赖
<dependency><groupId>org.apache.sparkgroupId><artifactId>spark-sql_2.11artifactId><version>2.4.5version>
dependency>
- Drvier程序
//1.创建SparkSession
val spark = SparkSession.builder().appName("hellosql").master("local[10]")
.getOrCreate()//2.引入改隐试转换 主要是 将 RDD 转换为 DataFrame/Dataset
import spark.implicits._
spark.sparkContext.setLogLevel("FATAL") //关闭spark
spark.stop()
创建Dataset/DataFrame
Dataset
Dataset与RDD类似,但是它们不使用Java序列化或Kryo,而是使用专用的Encoder来序列化对象以便通过网络进行处理或传输。虽然Encoder和标准序列化都负责将对象转换为字节,但Encoder是动态生成的代码,并使用一种格式,允许Spark执行许多操作,如过滤,排序和散列,而无需将字节反序列化为对象。
- case-class
case class Person(id:Int,name:String,age:Int,sex:Boolean)val dataset: Dataset[Person] =List(Person(1,"zhangsan",18,true),Person(2,"wangwu",28,true)).toDS()
dataset.select($"id",$"name").show()- Tuple元组
val dataset: Dataset[(Int,String,Int,Boolean)] = List((1,"zhangsan",18,true),(2,"wangwu",28,true)).toDS()
dataset.select($"_1",$"_2").show()//或者
dataset.selectExpr("_1 as id","_2 as name","(_3 * 10) as age").show()
- rdd
元组
val userRDD = spark.sparkContext.makeRDD(List((1,"张三",true,18,15000.0)))
userRDD.toDS().show()
+---+----+----+---+-------+
| _1| _2| _3| _4| _5|
+---+----+----+---+-------+
| 1|张三|true| 18|15000.0|
+---+----+----+---+-------+
case-class
val userRDD = spark.sparkContext.makeRDD(List(User(1,"张三",true,18,15000.0)))
userRDD.toDS().show()
+---+----+----+---+-------+
| id|name| sex|age| salary|
+---+----+----+---+-------+
| 1|张三|true| 18|15000.0|
+---+----+----+---+-------+
DataFrame
Data Frame是命名列的数据集,他在概念是等价于关系型数据库。DataFrames可以从很多地方构建,比如说结构化数据文 件、hive中的表或者外部数据库,使用Dataset[row]的数据集,可以理解DataFrame就是一个Dataset[Row].
- case-class
List(Person("zhangsan",18),Person("王五",20)).toDF("uname","uage").show()
- Tuple元组
List(("zhangsan",18),("王五",20)).toDF("name","age").show()
- RDD转换
Row
val userRDD = spark.sparkContext.makeRDD(List((1,"张三",true,18,15000.0))).map(t=>Row(t._1,t._2,t._3,t._4,t._5))
var schema=new StructType().add("id","int").add("name","string").add("sex","boolean").add("age","int").add("salary","double")spark.createDataFrame(userRDD,schema).show()
+---+----+----+---+-------+
| id|name| sex|age| salary|
+---+----+----+---+-------+
| 1|张三|true| 18|15000.0|
+---+----+----+---+-------+
Javabean
val userRDD = spark.sparkContext.makeRDD(List(new User(1,"张三",true,18,15000.0)))spark.createDataFrame(userRDD,classOf[User]).show()
提示:这里的User须是JavaBean对象。如果是Scala的类,用户需要额外提供getXxx方法(没这个必要)
+---+----+----+---+-------+
| id|name| sex|age| salary|
+---+----+----+---+-------+
| 1|张三|true| 18|15000.0|
+---+----+----+---+-------+
case-class
val userRDD = spark.sparkContext.makeRDD(List(User(1,"张三",true,18,15000.0)))spark.createDataFrame(userRDD).show()
+---+----+----+---+-------+
| id|name| sex|age| salary|
+---+----+----+---+-------+
| 1|张三|true| 18|15000.0|
+---+----+----+---+-------+
tuple元组
val userRDD = spark.sparkContext.makeRDD(List((1,"张三",true,18,15000.0)))spark.createDataFrame(userRDD).show()
+---+----+----+---+-------+
| _1| _2| _3| _4| _5|
+---+----+----+---+-------+
| 1|张三|true| 18|15000.0|
+---+----+----+---+-------+
Dataset/DataFrame API操作
准备数据
1,Michael,false,29,2000
5,Lisa,false,19,1000
3,Justin,true,19,1000
2,Andy,true,30,5000
4,Kaine,false,20,5000
尝试将文本数据转变为DataFrame
var dataframe=spark.sparkContext.textFile("file:///D:/data/user").map(line=> line.split(",")).map(ts=>(ts(0).toInt,ts(1),ts(2).toBoolean,ts(3).toInt,ts(4).toDouble)).toDF("id","name","sex","age","salary")
printSchema
打印创建的表结构信息
dataframe.printSchema()
root|-- id: integer (nullable = false)|-- name: string (nullable = true)|-- sex: boolean (nullable = false)|-- age: integer (nullable = false)|-- salary: double (nullable = false)
show
默认将dataframe或者是dataset中前20行的数据打印在控制台,一般用于测试。
dataframe.show()
+---+-------+-----+---+------+
| id| name| sex|age|salary|
+---+-------+-----+---+------+
| 1|Michael|false| 29|2000.0|
| 2| Andy| true| 30|5000.0|
| 3| Justin| true| 19|1000.0|
| 4| Kaine|false| 20|5000.0|
| 5| Lisa|false| 19|1000.0|
+---+-------+-----+---+------+
例如只查询前2行dataframe.show(2)
+---+-------+-----+---+------+
| id| name| sex|age|salary|
+---+-------+-----+---+------+
| 1|Michael|false| 29|2000.0|
| 2| Andy| true| 30|5000.0|
+---+-------+-----+---+------+
select
等价于sql脚本的select语句,用于过滤、投影出需要的字段信息。用户可以直接给列名,但是不支持计算
dataframe.select("id","name","sex","age","salary").show()
+---+-------+-----+---+------+
| id| name| sex|age|salary|
+---+-------+-----+---+------+
| 1|Michael|false| 29|2000.0|
| 2| Andy| true| 30|5000.0|
| 3| Justin| true| 19|1000.0|
| 4| Kaine|false| 20|5000.0|
| 5| Lisa|false| 19|1000.0|
+---+-------+-----+---+------+
用户可以给select传递Cloumn,这样用户可以针对Column做一些简单的计算
dataframe.select(new Column("id"),new Column("name"),new Column("age"),new Column("salary"),new Column("salary").*(12)).show()
简化写法
dataframe.select($"id",$"name",$"age",$"salary",$"salary" * 12)
.show()
+---+-------+---+------+-------------+
| id| name|age|salary|(salary * 12)|
+---+-------+---+------+-------------+
| 1|Michael| 29|2000.0| 24000.0|
| 2| Andy| 30|5000.0| 60000.0|
| 3| Justin| 19|1000.0| 12000.0|
| 4| Kaine| 20|5000.0| 60000.0|
| 5| Lisa| 19|1000.0| 12000.0|
+---+-------+---+------+-------------+
selectExpr
允许直接给字段名,并且基于字段名指定一些常见字符串SQL运算符。
dataframe.selectExpr("id","name || '用户'","salary * 12 as annal_salary").show()
+---+------------------+------------+
| id|concat(name, 用户)|annal_salary|
+---+------------------+------------+
| 1| Michael用户| 24000.0|
| 2| Andy用户| 60000.0|
| 3| Justin用户| 12000.0|
| 4| Kaine用户| 60000.0|
| 5| Lisa用户| 12000.0|
+---+------------------+------------+
where
类似SQL中的where,主要用于过滤查询结果。该算子可以传递Conditiion或者ConditionExp
dataframe.select($"id",$"name",$"age",$"salary",$"salary" * 12).where($"name" like "%a%").show()
等价写法
userDataFrame.select($"id",$"name",$"age",$"salary",$"salary" * 12).where("name like '%a%'").show()
注意spark中别名不要出现中文,如果出现中文,在
where表达式中存在bug
userDataFrame.select($"id",$"name",$"age",$"salary",$"salary" * 12 as "annal_salary").where("(name like '%a%') and (annal_salary > 12000)" ).show() //正常
userDataFrame.select($"id",$"name",$"age",$"salary",$"salary" * 12 as "年薪").where("(name like '%a%') and ('年薪' > 12000)" ).show()//错误
userDataFrame.select($"id",$"name",$"age",$"salary",$"salary" * 12 as "年薪").where($"name" like "%a%" and $"年薪" > 12000 ).show() //正常
withColumn
可以给dataframe添加一个字段信息
userDataFrame.select($"id",$"name",$"age",$"salary",$"sex").withColumn("年薪",$"salary" * 12).show()
+---+-------+---+------+-----+-------+
| id| name|age|salary| sex| 年薪|
+---+-------+---+------+-----+-------+
| 1|Michael| 29|2000.0|false|24000.0|
| 2| Andy| 30|5000.0| true|60000.0|
| 3| Justin| 19|1000.0| true|12000.0|
| 4| Kaine| 20|5000.0|false|60000.0|
| 5| Lisa| 19|1000.0|false|12000.0|
+---+-------+---+------+-----+-------+
withColumnRenamed
修改现有字段名字
userDataFrame.select($"id",$"name",$"age",$"salary",$"sex").withColumn("年薪",$"salary" * 12).withColumnRenamed("年薪","annal_salary").withColumnRenamed("id","uid").show()
+---+-------+---+------+-----+------------+
|uid| name|age|salary| sex|annal_salary|
+---+-------+---+------+-----+------------+
| 1|Michael| 29|2000.0|false| 24000.0|
| 2| Andy| 30|5000.0| true| 60000.0|
| 3| Justin| 19|1000.0| true| 12000.0|
| 4| Kaine| 20|5000.0|false| 60000.0|
| 5| Lisa| 19|1000.0|false| 12000.0|
+---+-------+---+------+-----+------------+
groupBy
和SQL中的group by用法一直,通常和一些聚合函数一起使用。
userDataFrame.select($"id",$"name",$"age",$"salary",$"sex")
.groupBy($"sex")
.mean("salary")//计算平均值等价avg
.show()
+-----+------------------+
| sex| avg(salary)|
+-----+------------------+
| true| 3000.0|
|false|2666.6666666666665|
+-----+------------------+
类似还有max、min、sum、avg算子,但是如果使用算子,后面跟一个聚合函数。一般来讲用户可以使用agg算子实现多个聚合操作。
agg
必须跟在groupBy后面,调用多个聚合函数,实现对某些字段的求和、最大值、最小值、平均值等。
import org.apache.spark.sql.functions._
userDataFrame.select($"id",$"name",$"age",$"salary",$"sex")
.groupBy($"sex")
.agg(sum("salary") as "sum", avg("salary") as "avg",max("salary") as "max",min("salary") as "min")
.show()
+-----+------+------------------+------+------+
| sex| sum| avg| max| min|
+-----+------+------------------+------+------+
| true|6000.0| 3000.0|5000.0|1000.0|
|false|8000.0|2666.6666666666665|5000.0|1000.0|
+-----+------+------------------+------+------+
或者
userDataFrame.select($"id",$"name",$"age",$"salary",$"sex").groupBy($"sex").agg("salary"->"sum","salary"->"avg","salary"->"max","salary"->"min").show()
开窗函数
使用over完成开窗,操作。
import org.apache.spark.sql.functions._
val w = Window.partitionBy("sex").orderBy($"salary" desc).rowsBetween(Window.unboundedPreceding,Window.currentRow)userDataFrame.select($"id",$"name",$"age",$"salary",$"sex")
.withColumn("salary_rank",dense_rank() over (w ))
.show()
select id,name,...,dense_rank() over(partition by sex order by salary desc rows between unbounded preceding and current row) from t_user
cube
实现多维度分析计算
import org.apache.spark.sql.functions._
spark.sparkContext.makeRDD(List((110,50,80),(120,60,95),(120,50,96)))
.toDF("height","weight","score")
.cube($"height",$"weight")
.agg(avg("score"),max("score"))
.show()
+------+------+-----------------+----------+
|height|weight| avg(score)|max(score)|
+------+------+-----------------+----------+
| 110| 50| 80.0| 80|
| 120| null| 95.5| 96|
| 120| 60| 95.0| 95|
| null| 60| 95.0| 95|
| null| null|90.33333333333333| 96|
| 120| 50| 96.0| 96|
| 110| null| 80.0| 80|
| null| 50| 88.0| 96|
+------+------+-----------------+----------+
pivot
该算子引自于SqlServer,主要用于实现行转列操作。
case class UserCost(id:Int,category:String,cost:Double)var userCostRDD=spark.sparkContext.parallelize(List(UserCost(1,"电子类",100),UserCost(1,"电子类",20),UserCost(1,"母婴类",100),UserCost(1,"生活用品",100),UserCost(2,"美食",79),UserCost(2,"电子类",80),UserCost(2,"生活用品",100)
))
var categories=userCostRDD.map(uc=>uc.category).distinct.collect()userCostRDD.toDF("id","category","cost")
.groupBy("id")
.pivot($"category",categories)
.sum("cost")
.show()
+---+------+--------+------+----+
| id|母婴类|生活用品|电子类|美食|
+---+------+--------+------+----+
| 1| 100.0| 100.0| 120.0|null|
| 2| null| 100.0| 80.0|79.0|
+---+------+--------+------+----+
na
提供了对null值字段数据的自动填充技术。
case class User01(id:Int,name:String,sex:Boolean,age:Int,salary:Double)
case class UserCost(id:Int,category:String,cost:Double)var userCostRDD=spark.sparkContext.parallelize(List(UserCost(1,"电子类",100),UserCost(1,"电子类",20),UserCost(1,"母婴类",100),UserCost(1,"生活用品",100),UserCost(2,"美食",79),UserCost(2,"电子类",80),UserCost(2,"生活用品",100)
))
var categories=userCostRDD.map(uc=>uc.category).distinct.collect()userCostRDD.toDF("id","category","cost")
.groupBy("id")
.pivot($"category",categories)
.sum("cost")
.na.fill(0.0)
.show()
+---+------+--------+------+----+
| id|母婴类|生活用品|电子类|美食|
+---+------+--------+------+----+
| 1| 100.0| 100.0| 120.0| 0.0|
| 2| 0.0| 100.0| 80.0|79.0|
+---+------+--------+------+----+
其中fill表示填充。
var userCostRDD=spark.sparkContext.parallelize(List(UserCost(1,"电子类",100),UserCost(1,"电子类",20),UserCost(1,"母婴类",100),UserCost(1,"生活用品",100),UserCost(2,"美食",79),UserCost(2,"电子类",80),UserCost(2,"生活用品",100)
))
var categories=userCostRDD.map(uc=>uc.category).distinct.collect()userCostRDD.toDF("id","category","cost")
.groupBy("id")
.pivot($"category",categories)
.sum("cost")
.na.fill(Map("美食"-> -1,"母婴类"-> 1000))
.show()
+---+------+--------+------+----+
| id|母婴类|生活用品|电子类|美食|
+---+------+--------+------+----+
| 1| 100.0| 100.0| 120.0|-1.0|
| 2|1000.0| 100.0| 80.0|79.0|
+---+------+--------+------+----+
一般na后面还可以跟drop算子,可以删除一些null值的行
var userCostRDD=spark.sparkContext.parallelize(List(UserCost(1,"电子类",100),UserCost(1,"电子类",20),UserCost(1,"母婴类",100),UserCost(1,"生活用品",100),UserCost(2,"美食",79),UserCost(2,"电子类",80),UserCost(2,"生活用品",100)
))
var categories=userCostRDD.map(uc=>uc.category).distinct.collect()userCostRDD.toDF("id","category","cost")
.groupBy("id")
.pivot($"category",categories)
.sum("cost")
//.na.drop(4)//如果少于四个非空,删除
// .na.drop("any")//只要有一个为null,就删除,`all`都为null才删除
.na.drop(List("美食","母婴类"))//如果指定列出null、删除
.show()
join
和数据的join类似。
case class User01(id:Int,name:String,sex:Boolean,age:Int,salary:Double)
case class UserCost(id:Int,category:String,cost:Double)var userCostRDD=spark.sparkContext.parallelize(List(UserCost(1,"电脑配件",100),UserCost(1,"母婴用品",100),UserCost(1,"生活用品",100),UserCost(2,"居家美食",79),UserCost(2,"消费电子",80),UserCost(2,"生活用品",100)
))var userRDD=spark.sparkContext.parallelize(List(User01(1,"张晓三",true,18,15000),User01(2,"李晓四",true,18,18000),User01(3,"王晓五",false,18,10000)
))val categories = userCostRDD.map(_.category).distinct().collect()
userCostRDD.toDF("id","category","cost").groupBy("id")
.pivot($"category",categories)
.sum("cost")
.join(userRDD.toDF("id","name","sex","age","salary"),"id")
.na.fill(0.0)
.show()
userCostRDD.toDF("id","category","cost").as("c").groupBy("id").pivot($"category",categories).sum("cost").join(userRDD.toDF("id","name","sex","age","salary").as("u"),$"c.id"===$"u.id","LEFT_OUTER").na.fill(0.0).show()
dropDuplicates
删除记录中的重复记录,类似sql中distinct关键字
var userCostDF=spark.sparkContext.parallelize(List(UserCost(1,"电脑配件",100),UserCost(1,"母婴用品",100),UserCost(1,"生活用品",100),UserCost(2,"居家美食",79),UserCost(2,"消费电子",80),UserCost(2,"生活用品",100)
)).toDF()userCostDF.dropDuplicates().show()
必须所有字段出现重复,才会删除重复记录。
+---+--------+-----+
| id|category| cost|
+---+--------+-----+
| 2|居家美食| 79.0|
| 1|电脑配件|100.0|
| 1|生活用品|100.0|
| 2|生活用品|100.0|
| 1|母婴用品|100.0|
| 2|消费电子| 80.0|
+---+--------+-----+
例如针对于category去重
userCostDF.dropDuplicates("category").show()
+---+--------+-----+
| id|category| cost|
+---+--------+-----+
| 2|居家美食| 79.0|
| 1|母婴用品|100.0|
| 1|生活用品|100.0|
| 2|消费电子| 80.0|
| 1|电脑配件|100.0|
+---+--------+-----+
drop
删除指定列信息
var userCostDF=spark.sparkContext.parallelize(List(UserCost(1,"电脑配件",100),UserCost(1,"母婴用品",100),UserCost(1,"生活用品",100),UserCost(2,"居家美食",79),UserCost(2,"消费电子",80),UserCost(2,"生活用品",100)
)).toDF()userCostDF.drop("cost","id").dropDuplicates().show()
+--------+
|category|
+--------+
|居家美食|
|母婴用品|
|生活用品|
|消费电子|
|电脑配件|
+--------+
orderBy
类似SQL中的orderBy用于指定排序字段
val df=spark.sparkContext.parallelize(List((1,"TV,GAME"),(2,"SLEEP,FOOTBALL"))).toDF("id","hobbies")
df.orderBy($"id" asc)
.show()
+---+--------------+
| id| hobbies|
+---+--------------+
| 1| TV,GAME|
| 2|SLEEP,FOOTBALL|
+---+--------------+
limit
类似于数据库的分页语句,但是只能限定条数,类似RDD中take(n)
var userCostDF=spark.sparkContext.parallelize(List(UserCost(1,"电脑配件",100),UserCost(1,"母婴用品",100),UserCost(1,"生活用品",100),UserCost(2,"居家美食",79),UserCost(2,"消费电子",80),UserCost(2,"生活用品",100)
)).toDF()userCostDF.orderBy($"id" asc).limit(3).show()
+---+--------+-----+
| id|category| cost|
+---+--------+-----+
| 1|电脑配件|100.0|
| 1|母婴用品|100.0|
| 1|生活用品|100.0|
+---+--------+-----+
filter
类似于where,过滤掉一些不符合要求的数据集,用户可以给表达式、过滤条件、或者是函数
var userCostDF=spark.sparkContext.parallelize(List(UserCost(1,"电脑配件",100),UserCost(1,"母婴用品",100),UserCost(1,"生活用品",100),UserCost(2,"居家美食",79),UserCost(2,"消费电子",80),UserCost(2,"生活用品",100)
)).toDF()userCostDF.orderBy($"id" asc).limit(3).filter("category != '母婴用品' ").show()
+---+--------+-----+
| id|category| cost|
+---+--------+-----+
| 1|电脑配件|100.0|
| 1|生活用品|100.0|
+---+--------+-----+
等价1
userCostDF.orderBy($"id" asc).limit(3).filter($"category" =!="母婴用品").show()
等价2
userCostDF.orderBy($"id" asc).limit(3).filter(row=> ! row.getAs[String]("category").equals("母婴用品")).show()
map
类似RDD中map、处理DataFrame中的Row类型。
var userDF=spark.sparkContext.parallelize(List(User01(1,"张晓三",true,18,15000),User01(2,"李晓四",true,18,18000),User01(3,"王晓五",false,18,10000)
)).toDF()val dataset:Dataset[(Int,String,Double)] = userDF.map(row => (row.getAs[Int]("id"), row.getAs[String]("name"), row.getAs[Double]("salary")))
dataset.toDF("id","name","salary")
.show()
+---+------+-------+
| _1| _2| _3|
+---+------+-------+
| 1|张晓三|15000.0|
| 2|李晓四|18000.0|
| 3|王晓五|10000.0|
+---+------+-------+
rdd
可以将Dataset[T]或者DataFrame类型的数据变成RDD[T]或者是RDD[Row]
var userDF=spark.sparkContext.parallelize(List(User01(1,"张晓三",true,18,15000),User01(2,"李晓四",true,18,18000),User01(3,"王晓五",false,18,10000)
)).toDF()val dataset:Dataset[(Int,String,Double)] = userDF.map(row => (row.getAs[Int]("id"), row.getAs[String]("name"), row.getAs[Double]("salary")))
dataset.rdd.foreach(t=>println(t._1+" "+t._2+" "+t._3))
Dataset/DataFrame SQL
数据准备
t_user
Michael,29,20000,true,MANAGER,1
Andy,30,15000,true,SALESMAN,1
Justin,19,8000,true,CLERK,1
Kaine,20,20000,true,MANAGER,2
Lisa,19,18000,false,SALESMAN,2
t_dept
1,研发
2,设计
3,产品
将以上数据上传到HDFS文件系统
//1.创建SparkSession
val spark = SparkSession.builder()
.appName("hellosql")
.master("local[10]")
.getOrCreate()//引入改隐试转换 主要是 将 集合、RDD 转换为 DataFrame/Dataset
import spark.implicits._
spark.sparkContext.setLogLevel("FATAL")val userDF = spark.sparkContext.textFile("hdfs://CentOS:9000/demo/user")
.map(line => line.split(","))
.map(ts => User(ts(0), ts(1).toInt, ts(2).toDouble, ts(3).toBoolean, ts(4), ts(5).toInt))
.toDF()val deptDF = spark.sparkContext.textFile("hdfs://CentOS:9000/demo/dept")
.map(line => line.split(","))
.map(ts => Dept(ts(0).toInt, ts(1)))
.toDF()userDF.show()
deptDF.show()//关闭SparkSession
spark.close()
注册视图
userDF.createOrReplaceTempView("t_user")
deptDF.createOrReplaceTempView("t_dept")
执行SQL
var sql=
"""select *, salary * 12 as annual_salary from t_user
"""spark.sql(sql).show()
单表查询
select *, salary * 12 as annual_salary from t_user
+-------+---+-------+-----+--------+------+-------------+
| name|age| salary| sex| job|deptNo|annual_salary|
+-------+---+-------+-----+--------+------+-------------+
|Michael| 29|20000.0| true| MANAGER| 1| 240000.0|
| Andy| 30|15000.0| true|SALESMAN| 1| 180000.0|
| Justin| 19| 8000.0| true| CLERK| 1| 96000.0|
| Kaine| 20|20000.0| true| MANAGER| 2| 240000.0|
| Lisa| 19|18000.0|false|SALESMAN| 2| 216000.0|
+-------+---+-------+-----+--------+------+-------------+
like模糊
select *, salary * 12 as annual_salary from t_user where name like '%a%'
+-------+---+-------+-----+--------+------+-------------+
| name|age| salary| sex| job|deptNo|annual_salary|
+-------+---+-------+-----+--------+------+-------------+
|Michael| 29|20000.0| true| MANAGER| 1| 240000.0|
| Kaine| 20|20000.0| true| MANAGER| 2| 240000.0|
| Lisa| 19|18000.0|false|SALESMAN| 2| 216000.0|
+-------+---+-------+-----+--------+------+-------------+
排序查询
select * from t_user order by deptNo asc,salary desc
+-------+---+-------+-----+--------+------+
| name|age| salary| sex| job|deptNo|
+-------+---+-------+-----+--------+------+
|Michael| 29|20000.0| true| MANAGER| 1|
| Andy| 30|15000.0| true|SALESMAN| 1|
| Justin| 19| 8000.0| true| CLERK| 1|
| Kaine| 20|20000.0| true| MANAGER| 2|
| Lisa| 19|18000.0|false|SALESMAN| 2|
+-------+---+-------+-----+--------+------+
limit查询
select * from t_user order by deptNo asc,salary desc limit 3
+-------+---+-------+----+--------+------+
| name|age| salary| sex| job|deptNo|
+-------+---+-------+----+--------+------+
|Michael| 29|20000.0|true| MANAGER| 1|
| Andy| 30|15000.0|true|SALESMAN| 1|
| Justin| 19| 8000.0|true| CLERK| 1|
+-------+---+-------+----+--------+------+
分组查询
select deptNo,avg(salary) avg from t_user group by deptNo
+------+------------------+
|deptNo| avg|
+------+------------------+
| 1|14333.333333333334|
| 2| 19000.0|
+------+------------------+
Having过滤
select deptNo,avg(salary) avg from t_user group by deptNo having avg > 15000
+------+-------+
|deptNo| avg|
+------+-------+
| 2|19000.0|
+------+-------+
case-when
select deptNo,name,salary,sex,(case sex when true then '男' else '女' end ) as user_sex,(case when salary >= 20000 then '高' when salary >= 15000 then '中' else '低' end ) as levelfrom t_user
+------+-------+-------+-----+--------+-----+
|deptNo| name| salary| sex|user_sex|level|
+------+-------+-------+-----+--------+-----+
| 1|Michael|20000.0| true| 男| 高|
| 1| Andy|15000.0| true| 男| 中|
| 1| Justin| 8000.0| true| 男| 低|
| 2| Kaine|20000.0| true| 男| 高|
| 2| Lisa|18000.0|false| 女| 中|
+------+-------+-------+-----+--------+-----+
行专列
val coursedf = spark.sparkContext.parallelize(List((1, "语文", 100),(1, "数学", 100),(1, "英语", 100),(2, "数学", 79),(2, "语文", 80),(2, "英语", 100))).toDF("id","course","score")coursedf.createOrReplaceTempView("t_course")
select id,sum(case course when '语文' then score else 0 end) as chinese,sum(case course when '数学' then score else 0 end) as math,sum(case course when '英语' then score else 0 end) as englishfrom t_coursegroup by id
+---+-------+----+-------+
| id|chinese|math|english|
+---+-------+----+-------+
| 1| 100| 100| 100|
| 2| 80| 79| 100|
+---+-------+----+-------+
使用pivot实现行转列
select * from t_course pivot(max(score) for course in ('数学','语文','英语'))
+---+----+----+----+
| id|数学|语文|英语|
+---+----+----+----+
| 1| 100| 100| 100|
| 2| 79| 80| 100|
+---+----+----+----+
表连接
select u.*,d.dname from t_user u left join t_dept d on u.deptNo=d.deptNo
+-------+---+-------+-----+--------+------+-----+
| name|age| salary| sex| job|deptNo|dname|
+-------+---+-------+-----+--------+------+-----+
|Michael| 29|20000.0| true| MANAGER| 1| 研发|
| Andy| 30|15000.0| true|SALESMAN| 1| 研发|
| Justin| 19| 8000.0| true| CLERK| 1| 研发|
| Kaine| 20|20000.0| true| MANAGER| 2| 设计|
| Lisa| 19|18000.0|false|SALESMAN| 2| 设计|
+-------+---+-------+-----+--------+------+-----+
子查询
select t1.*,t2.avg_sal from (select id,name,salary,deptno from t_user) t1 left join (select deptno,avg(salary) avg_sal from t_user group by deptno) t2 on t1.deptno=t2.deptnoselect id,name,salary,deptno, (select deptno ,avg(salary) from t_user t2 where t2.deptno=t1.deptno group by t2.deptno ) from t_user t1select id,name,salary,deptno, (select avg(salary) from t_user t2 group by t2.deptno having t2.deptno=t1.deptno) from t_user t1+---+-------+-------+------+----------------------+
| id| name| salary|deptno|scalarsubquery(deptno)|
+---+-------+-------+------+----------------------+
| 29|Michael|20000.0| 1| 14333.333333333334|
| 30| Andy|15000.0| 1| 14333.333333333334|
| 19| Justin| 8000.0| 1| 14333.333333333334|
| 20| Kaine|20000.0| 2| 19000.0|
| 19| Lisa|18000.0| 2| 19000.0|
+---+-------+-------+------+----------------------+
开窗函数
select id,name,salary,deptno, avg(salary) over(partition by deptno order by salary desc rows between unbounded preceding and unbounded following ) as avg_sal from t_user
+---+-------+-------+------+------------------+
| id| name| salary|deptno| avg_sal|
+---+-------+-------+------+------------------+
| 29|Michael|20000.0| 1|14333.333333333334|
| 30| Andy|15000.0| 1|14333.333333333334|
| 19| Justin| 8000.0| 1|14333.333333333334|
| 20| Kaine|20000.0| 2| 19000.0|
| 19| Lisa|18000.0| 2| 19000.0|
+---+-------+-------+------+------------------+
cube分析
select deptno ,job,max(salary),min(salary),avg(salary) from t_user group by deptno,job with cube
+------+--------+-----------+-----------+------------------+
|deptno| job|max(salary)|min(salary)| avg(salary)|
+------+--------+-----------+-----------+------------------+
| 1|SALESMAN| 15000.0| 15000.0| 15000.0|
| 1| null| 20000.0| 8000.0|14333.333333333334|
| null| null| 20000.0| 8000.0| 16200.0|
| null|SALESMAN| 18000.0| 15000.0| 16500.0|
| 1| CLERK| 8000.0| 8000.0| 8000.0|
| 2| MANAGER| 20000.0| 20000.0| 20000.0|
| 2| null| 20000.0| 18000.0| 19000.0|
| null| MANAGER| 20000.0| 20000.0| 20000.0|
| null| CLERK| 8000.0| 8000.0| 8000.0|
| 2|SALESMAN| 18000.0| 18000.0| 18000.0|
| 1| MANAGER| 20000.0| 20000.0| 20000.0|
+------+--------+-----------+-----------+------------------+
等价写法
select deptno ,job,max(salary),min(salary),avg(salary) from t_user group by cube(deptno,job)
+------+--------+-----------+-----------+------------------+
|deptno| job|max(salary)|min(salary)| avg(salary)|
+------+--------+-----------+-----------+------------------+
| 1|SALESMAN| 15000.0| 15000.0| 15000.0|
| 1| null| 20000.0| 8000.0|14333.333333333334|
| null| null| 20000.0| 8000.0| 16200.0|
| null|SALESMAN| 18000.0| 15000.0| 16500.0|
| 1| CLERK| 8000.0| 8000.0| 8000.0|
| 2| MANAGER| 20000.0| 20000.0| 20000.0|
| 2| null| 20000.0| 18000.0| 19000.0|
| null| MANAGER| 20000.0| 20000.0| 20000.0|
| null| CLERK| 8000.0| 8000.0| 8000.0|
| 2|SALESMAN| 18000.0| 18000.0| 18000.0|
| 1| MANAGER| 20000.0| 20000.0| 20000.0|
+------+--------+-----------+-----------+------------------+
自定义函数
spark内置很多函数都定义在org.apache.spark.sql.functions单例对象中,如果不满足实际需求,大家可以考虑对Spark函数库进行扩展。
√单行函数
1、定义函数
val sexFunction=(sex:Boolean)=> sex match {case true => "男"case false => "女"case default => "unkonwn"
}
val commFunction=(age:Int,salary:Double)=> {if(age>=30){salary+500}else{salary}
}
2、注册用户的函数
spark.udf.register("sexFunction",sexFunction)
spark.udf.register("commFunction",commFunction)
3、测试使用函数
select name,sexFunction(sex),age,salary,job,commFunction(age,salary) as comm from t_user
+-------+--------------------+---+-------+--------+-------+
| name|UDF:sexFunction(sex)|age| salary| job| comm|
+-------+--------------------+---+-------+--------+-------+
|Michael| 男| 29|20000.0| MANAGER|20000.0|
| Andy| 男| 30|15000.0|SALESMAN|15500.0|
| Justin| 男| 19| 8000.0| CLERK| 8000.0|
| Kaine| 男| 20|20000.0| MANAGER|20000.0|
| Lisa| 女| 19|18000.0|SALESMAN|18000.0|
+-------+--------------------+---+-------+--------+-------+
聚合函数-了解
Untyped
1、定义聚合函数
import org.apache.spark.sql.Row
import org.apache.spark.sql.expressions.{MutableAggregationBuffer, UserDefinedAggregateFunction}
import org.apache.spark.sql.types.{DataType, DoubleType, IntegerType, StructField, StructType}object CustomUserDefinedAggregateFunction extends UserDefinedAggregateFunction{//接收数据类型是什么override def inputSchema: StructType = {StructType(StructField("inputColumn", DoubleType) :: Nil)}//用于作为缓冲中间结果类型override def bufferSchema: StructType = {StructType(StructField("count", IntegerType) ::StructField("total", DoubleType):: Nil)}//最终返回值类型override def dataType: DataType = DoubleType//表示函数输出结果类型是否一致override def deterministic: Boolean = true//设置聚合初始化状态override def initialize(buffer: MutableAggregationBuffer): Unit = {buffer(0)=0 //总计数buffer(1)=0.0 //总和}//将row中结果累加到buffer中override def update(buffer: MutableAggregationBuffer, input: Row): Unit = {var historyCount = buffer.getInt(0)var historyTotal = buffer.getDouble(1)if(!input.isNullAt(0)){historyTotal += input.getDouble(0)historyCount += 1buffer(0)= historyCountbuffer(1) = historyTotal}}//做最终汇总操作override def merge(buffer1: MutableAggregationBuffer, buffer2: Row): Unit = {buffer1(0)=buffer1.getInt(0) + buffer2.getInt(0)buffer1(1)=buffer1.getDouble(1) + buffer2.getDouble(1)}//计算最终结果override def evaluate(buffer: Row): Any = {buffer.getDouble(1) / buffer.getInt(0)}
}
2、注册聚合函数
spark.udf.register("custom_avg",CustomUserDefinedAggregateFunction)
3、测试使用聚合函数
select deptNo,custom_avg(salary) from t_user group by deptNo
+------+-------------------------------------------+
|deptNo|customuserdefinedaggregatefunction$(salary)|
+------+-------------------------------------------+
| 1| 14333.333333333334|
| 2| 19000.0|
+------+-------------------------------------------+
Type-Safe
1、定义聚合函数
case class Average(total:Double,count:Int)
object CustomAggregator extends Aggregator[GenericRowWithSchema,Average,Double]{//初始化值override def zero: Average = Average(0.0,0)//计算局部结果override def reduce(b: Average, a: GenericRowWithSchema): Average = {Average(b.total+a.getAs[Double]("salary"),b.count+1)}//将局部结果合并override def merge(b1: Average, b2: Average): Average = {Average(b1.total+b2.total,b1.count+b2.count)}//计算总结果override def finish(reduction: Average): Double = {reduction.total/reduction.count}//指定中间结果类型的Encodersoverride def bufferEncoder: Encoder[Average] = Encoders.product[Average]//指定最终结果类型的Encodersoverride def outputEncoder: Encoder[Double] = Encoders.scalaDouble
}
2、注册声明聚合函数
val averageSalary = CustomAggregator.toColumn.name("average_salary")
3、测试使用聚合
import org.apache.spark.sql.functions._
userDF.select("deptNo","salary").groupBy("deptNo").agg(averageSalary,avg("salary")).show()
+------+------------------+------------------+
|deptNo| average_salary| avg(salary)|
+------+------------------+------------------+
| 1|14333.333333333334|14333.333333333334|
| 2| 19000.0| 19000.0|
+------+------------------+------------------+
Load&Save
paquet文件
save
Parquet仅仅是一种存储格式,它是语言、平台无关的,并且不需要和任何一种数据处理框架绑定.
var sql="""select * from t_user"""
val result: DataFrame = spark.sql(sql)
result.write.save("hdfs://CentOS:9000/results/paquet")
load
val dataFrame = spark.read.load("hdfs://CentOS:9000/results/paquet")
dataFrame.printSchema()
dataFrame.show()
root|-- name: string (nullable = true)|-- age: integer (nullable = true)|-- salary: double (nullable = true)|-- sex: boolean (nullable = true)|-- job: string (nullable = true)|-- deptNo: integer (nullable = true)+-------+---+-------+-----+--------+------+
| name|age| salary| sex| job|deptNo|
+-------+---+-------+-----+--------+------+
|Michael| 29|20000.0| true| MANAGER| 1|
| Andy| 30|15000.0| true|SALESMAN| 1|
| Justin| 19| 8000.0| true| CLERK| 1|
| Kaine| 20|20000.0| true| MANAGER| 2|
| Lisa| 19|18000.0|false|SALESMAN| 2|
+-------+---+-------+-----+--------+------+
等价写法:
spark.read.parquet("hdfs://CentOS:9000/results/paquet")
Json格式
save
var sql="""select * from t_user"""val result: DataFrame = spark.sql(sql)result.write.format("json").mode(SaveMode.Overwrite).save("hdfs://CentOS:9000/results/json")
load
val dataFrame = spark.read.format("json").load("hdfs://CentOS:9000/results/json")dataFrame.printSchema()dataFrame.show()
root|-- age: long (nullable = true)|-- deptNo: long (nullable = true)|-- job: string (nullable = true)|-- name: string (nullable = true)|-- salary: double (nullable = true)|-- sex: boolean (nullable = true)+---+------+--------+-------+-------+-----+
|age|deptNo| job| name| salary| sex|
+---+------+--------+-------+-------+-----+
| 29| 1| MANAGER|Michael|20000.0| true|
| 30| 1|SALESMAN| Andy|15000.0| true|
| 19| 1| CLERK| Justin| 8000.0| true|
| 20| 2| MANAGER| Kaine|20000.0| true|
| 19| 2|SALESMAN| Lisa|18000.0|false|
+---+------+--------+-------+-------+-----+
用户也可以j简单写
spark.read.json("hdfs://CentOS:9000/results/json")
csv格式
save
var sql="""select * from t_user"""val result: DataFrame = spark.sql(sql)result.write.format("csv").mode(SaveMode.Overwrite).option("sep", ",")//指定分隔符.option("inferSchema", "true")//参照表schema信息.option("header", "true")//是否产生表头信息.save("hdfs://CentOS:9000/results/csv")
load
val dataFrame = spark.read.format("csv").option("sep", ",")//指定分隔符.option("inferSchema", "true")//参照表schema信息.option("header", "true")//是否产生表头信息.load("hdfs://CentOS:9000/results/csv")
root|-- name: string (nullable = true)|-- age: integer (nullable = true)|-- salary: double (nullable = true)|-- sex: boolean (nullable = true)|-- job: string (nullable = true)|-- deptNo: integer (nullable = true)+-------+---+-------+-----+--------+------+
| name|age| salary| sex| job|deptNo|
+-------+---+-------+-----+--------+------+
|Michael| 29|20000.0| true| MANAGER| 1|
| Andy| 30|15000.0| true|SALESMAN| 1|
| Justin| 19| 8000.0| true| CLERK| 1|
| Kaine| 20|20000.0| true| MANAGER| 2|
| Lisa| 19|18000.0|false|SALESMAN| 2|
+-------+---+-------+-----+--------+------+
ORC格式
ORC的全称是(Optimized Row Columnar),ORC文件格式是一种Hadoop生态圈中的列式存储格式,它的产生早在2013年初,最初产生自Apache Hive,用于降低Hadoop数据存储空间和加速Hive查询速度。
save
var sql="""select * from t_user"""val result: DataFrame = spark.sql(sql)result.write.format("orc").mode(SaveMode.Overwrite).save("hdfs://CentOS:9000/results/orc")
load
val dataFrame = spark.read.orc("hdfs://CentOS:9000/results/orc")dataFrame.printSchema()dataFrame.show()
root|-- name: string (nullable = true)|-- age: integer (nullable = true)|-- salary: double (nullable = true)|-- sex: boolean (nullable = true)|-- job: string (nullable = true)|-- deptNo: integer (nullable = true)+-------+---+-------+-----+--------+------+
| name|age| salary| sex| job|deptNo|
+-------+---+-------+-----+--------+------+
|Michael| 29|20000.0| true| MANAGER| 1|
| Andy| 30|15000.0| true|SALESMAN| 1|
| Justin| 19| 8000.0| true| CLERK| 1|
| Kaine| 20|20000.0| true| MANAGER| 2|
| Lisa| 19|18000.0|false|SALESMAN| 2|
+-------+---+-------+-----+--------+------+
SQL读取文件
val parqeutDF = spark.sql("SELECT * FROM parquet.`hdfs://CentOS:9000/results/paquet`")
val jsonDF = spark.sql("SELECT * FROM json.`hdfs://CentOS:9000/results/json`")
val orcDF = spark.sql("SELECT * FROM orc.`hdfs://CentOS:9000/results/orc/`")//val csvDF = spark.sql("SELECT * FROM csv.`hdfs://CentOS:9000/results/csv/`")
parqeutDF.show()
jsonDF.show()
orcDF.show()
// csvDF.show()
JDBC数据读取
load
<dependency><groupId>mysqlgroupId><artifactId>mysql-connector-javaartifactId><version>5.1.48version>
dependency>
val dataFrame = spark.read.format("jdbc").option("url", "jdbc:mysql://CentOS:3306/test").option("dbtable", "t_user").option("user", "root").option("password", "root").load()dataFrame.show()
+---+--------+-----+---+----------+
| id| name| sex|age| birthDay|
+---+--------+-----+---+----------+
| 0|zhangsan| true| 20|2020-01-11|
| 1| lisi|false| 25|2020-01-10|
| 3| wangwu| true| 36|2020-01-17|
| 4| zhao6|false| 50|1990-02-08|
| 5| win7| true| 20|1991-02-08|
| 6| win8|false| 28|2000-01-01|
+---+--------+-----+---+----------+
save
val props = new Properties()props.put("user", "root")props.put("password", "root")result .write.mode(SaveMode.Overwrite).jdbc("jdbc:mysql://CentOS:3306/test","t_user",props)
系统会自动创建t_user表
√Spark & Hive集成
代码
- 修改hive-site.xml
<property><name>javax.jdo.option.ConnectionURLname><value>jdbc:mysql://CentOS:3306/hive?createDatabaseIfNotExist=truevalue>
property><property><name>javax.jdo.option.ConnectionDriverNamename><value>com.mysql.jdbc.Drivervalue>
property><property><name>javax.jdo.option.ConnectionUserNamename><value>rootvalue>
property><property><name>javax.jdo.option.ConnectionPasswordname><value>rootvalue>
property>
<property><name>hive.metastore.urisname><value>thrift://CentOS:9083value>
property>
<property><name>hive.metastore.localname><value>falsevalue>
property><property><name>hive.metastore.schema.verificationname><value>falsevalue>
property>- 启动metastore服务
[root@CentOS apache-hive-1.2.2-bin]# ./bin/hive --service metastore >/dev/null 2>&1 &
[1] 55017
- 导入以下依赖
<dependency><groupId>org.apache.sparkgroupId><artifactId>spark-sql_2.11artifactId><version>2.4.5version>
dependency>
<dependency><groupId>org.apache.sparkgroupId><artifactId>spark-hive_2.11artifactId><version>2.4.5version>
dependency>
- 编写如下代码
//配置spark
val spark = SparkSession.builder().appName("Spark Hive Example").master("local[*]").config("hive.metastore.uris", "thrift://CentOS:9083").enableHiveSupport() //启动hive支持.getOrCreate()spark.sql("show databases").show()spark.sql("use baizhi")spark.sql("select * from t_emp").na.fill(0.0).show()spark.close()
+-----+------+---------+----+-------------------+-------+-------+------+
|empno| ename| job| mgr| hiredate| sal| comm|deptno|
+-----+------+---------+----+-------------------+-------+-------+------+
| 7369| SMITH| CLERK|7902|1980-12-17 00:00:00| 800.00| 0.00| 20|
| 7499| ALLEN| SALESMAN|7698|1981-02-20 00:00:00|1600.00| 300.00| 30|
| 7521| WARD| SALESMAN|7698|1981-02-22 00:00:00|1250.00| 500.00| 30|
| 7566| JONES| MANAGER|7839|1981-04-02 00:00:00|2975.00| 0.00| 20|
| 7654|MARTIN| SALESMAN|7698|1981-09-28 00:00:00|1250.00|1400.00| 30|
| 7698| BLAKE| MANAGER|7839|1981-05-01 00:00:00|2850.00| 0.00| 30|
| 7782| CLARK| MANAGER|7839|1981-06-09 00:00:00|2450.00| 0.00| 10|
| 7788| SCOTT| ANALYST|7566|1987-04-19 00:00:00|1500.00| 0.00| 20|
| 7839| KING|PRESIDENT| 0|1981-11-17 00:00:00|5000.00| 0.00| 10|
| 7844|TURNER| SALESMAN|7698|1981-09-08 00:00:00|1500.00| 0.00| 30|
| 7876| ADAMS| CLERK|7788|1987-05-23 00:00:00|1100.00| 0.00| 20|
| 7900| JAMES| CLERK|7698|1981-12-03 00:00:00| 950.00| 0.00| 30|
| 7902| FORD| ANALYST|7566|1981-12-03 00:00:00|3000.00| 0.00| 20|
| 7934|MILLER| CLERK|7782|1982-01-23 00:00:00|1300.00| 0.00| 10|
+-----+------+---------+----+-------------------+-------+-------+------+
交互
1、需要将spark-hive_2.11-2.4.5.jar、spark-hive-thriftserver_2.11-2.4.5.jar拷贝到spark的jar目录,重启spark
2、将hive-site.xml文件拷贝到spark的conf目录下
3、需要将Hive的jar的类路径配置到hadoop的类路径下
SPARK_HOME=/usr/spark-2.4.5
KE_HOME=/usr/kafka-eagle
M2_HOME=/usr/apache-maven-3.6.3
SQOOP_HOME=/usr/sqoop-1.4.7
HIVE_HOME=/usr/apache-hive-1.2.2-bin
JAVA_HOME=/usr/java/latest
HADOOP_HOME=/usr/hadoop-2.9.2/
HBASE_HOME=/usr/hbase-1.2.4/
ZOOKEEPER_HOME=/usr/zookeeper-3.4.6
PATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$HBASE_HOME/bin:$M2_HOME/bin:$HIVE_HOME/bin:$SQOOP_HOME/bin:$ZOOKEEPER_HOME/bin:$KE_HOME/bin:$SPARK_HOME/bin:$SPARK_HOME/sbin
CLASSPATH=.
export JAVA_HOME
export PATH
export CLASSPATH
export HADOOP_HOME
export HBASE_HOME
HBASE_CLASSPATH=$(/usr/hbase-1.2.4/bin/hbase classpath)
HADOOP_CLASSPATH=/root/mysql-connector-java-5.1.49.jar:/usr/spark-2.4.5/jars/spark-hive_2.11-2.4.5.jar:/usr/spark-2.4.5/jars/spark-hive-thriftserver_2.11-2.4.5.jar:$HIVE_HOME/lib/*
export HADOOP_CLASSPATH
export M2_HOME
export HIVE_HOME
export SQOOP_HOME
export ZOOKEEPER_HOME
export KE_HOME
export SPARK_HOME
4、执行如下指令
[root@CentOS spark-2.4.5]# ./bin/spark-sql --master spark://CentOS:7077 --total-executor-cores 6 --packages org.apache.spark:spark-hive-thriftserver_2.11:2.4.5
...
spark-sql> show databases;
20/11/04 12:06:33 INFO codegen.CodeGenerator: Code generated in 748.341192 ms
baizhi
default
test
Time taken: 5.818 seconds, Fetched 3 row(s)
Spark Catalyst(面试)
最近想来,大数据相关技术与传统型数据库技术很多都是相互融合、互相借鉴的。传统型数据库强势在于其久经考验的SQL优化器经验,弱势在于分布式领域的高可用性、容错性、扩展性等,假以时日,让其经过一定的改造,比如引入Paxos、raft等,强化自己在分布式领域的能力,相信一定会在大数据系统中占有一席之地。相反,大数据相关技术优势在于其天生的扩展性、可用性、容错性等,但其SQL优化器经验却基本全部来自于传统型数据库,当然,针对列式存储大数据SQL优化器会有一定的优化策略。
本文主要介绍SparkSQL的优化器系统Catalyst,上文讲到其设计思路基本都来自于传统型数据库,而且和大多数当前的大数据SQL处理引擎设计基本相同(Impala、Presto、Hive(Calcite)等),因此通过本文的学习也可以基本了解所有其他SQL处理引擎的工作原理。
SQL优化器核心执行策略主要分为两个大的方向:基于规则优化(RBO)以及基于代价优化(CBO),基于规则优化是一种经验式、启发式地优化思路,更多地依靠前辈总结出来的优化规则,简单易行且能够覆盖到大部分优化逻辑,但是对于核心优化算子Join却显得有点力不从心。举个简单的例子,两个表执行Join到底应该使用BroadcastHashJoin还是SortMergeJoin?当前SparkSQL的方式是通过手工设定参数来确定,如果一个表的数据量小于这个值就使用BroadcastHashJoin,但是这种方案显得很不优雅,很不灵活。基于代价优化就是为了解决这类问题,它会针对每个Join评估当前两张表使用每种Join策略的代价,根据代价估算确定一种代价最小的方案。
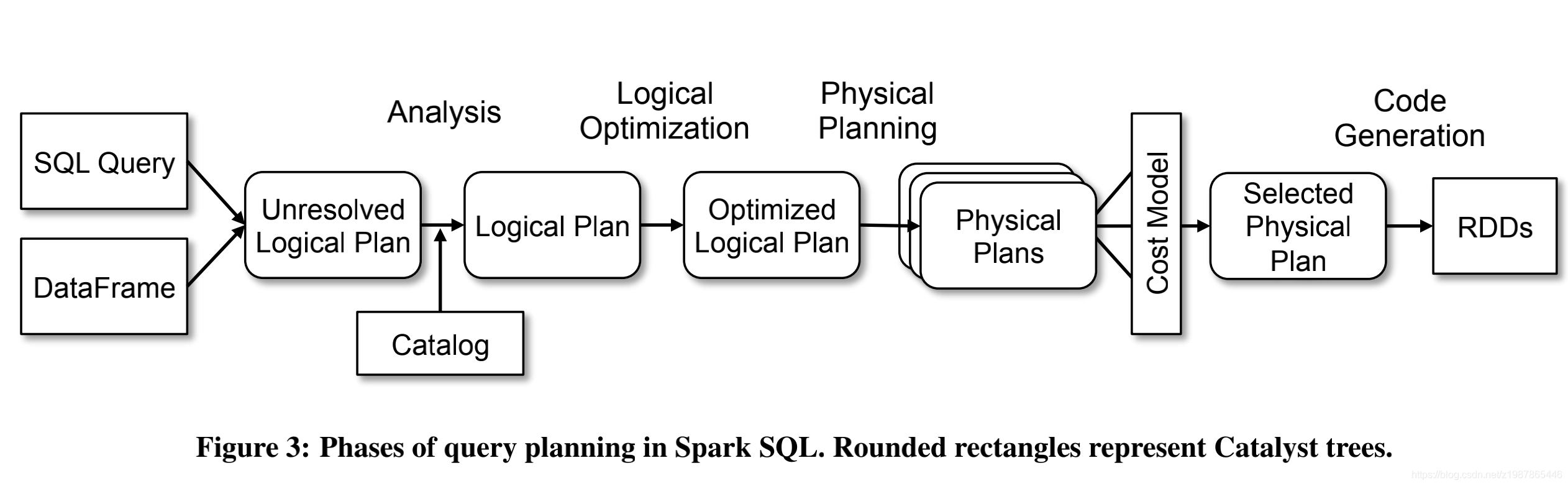
本文将会重点介绍基于规则的优化策略,后续文章会详细介绍基于代价的优化策略。下图中红色框框部分将是本文的介绍重点:
Tree&Rule
在介绍SQL优化器工作原理之前,有必要首先介绍两个重要的数据结构:Tree和Rule。相信无论对SQL优化器有无了解,都肯定知道SQL语法树这个概念,不错,SQL语法树就是SQL语句通过编译器之后会被解析成一棵树状结构。这棵树会包含很多节点对象,每个节点都拥有特定的数据类型,同时会有0个或多个孩子节点(节点对象在代码中定义为TreeNode对象),下图是个简单的示例:
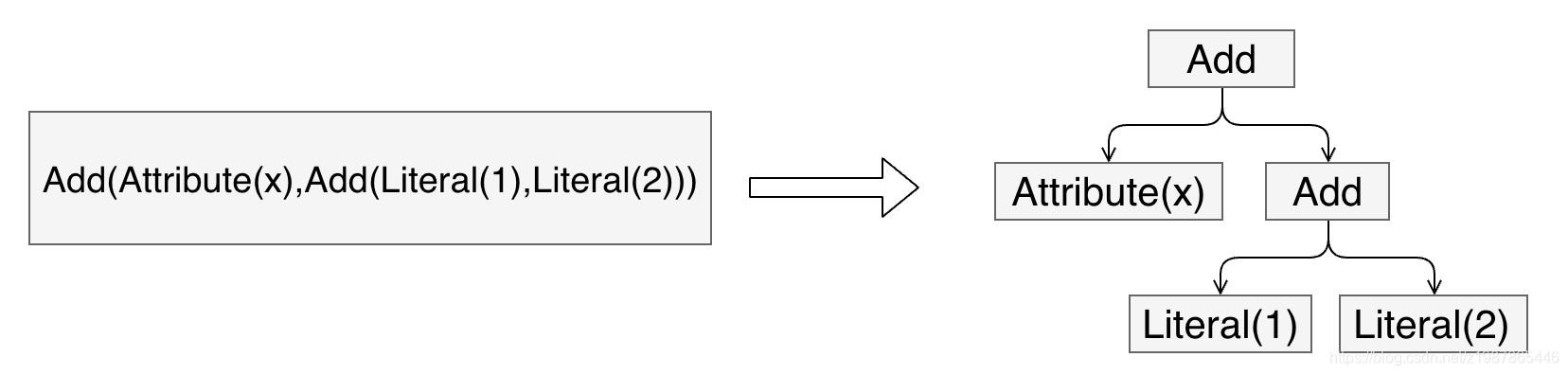
如上图所示,箭头左边表达式有3种数据类型(Literal表示常量、Attribute表示变量、Add表示动作),表示x+(1+2)。映射到右边树状结构后,每一种数据类型就会变成一个节点。另外,Tree还有一个非常重要的特性,可以通过一定的规则进行等价变换,如下图:
expression.transform{case Add(Literal(x,IntegerType),Literal(y,IntegerType)) => Literal(x+y)
}

上图定义了一个等价变换规则(Rule):两个Integer类型的常量相加可以等价转换为一个Integer常量,这个规则其实很简单,对于上文中提到的表达式x+(1+2)来说就可以转变为x+3。对于程序来讲,如何找到两个Integer常量呢?其实就是简单的二叉树遍历算法,每遍历到一个节点,就模式匹配当前节点为Add、左右子节点是Integer常量的结构,定位到之后将此三个节点替换为一个Literal类型的节点。上面用一个最简单的示例来说明等价变换规则以及如何将规则应用于语法树。在任何一个SQL优化器中,通常会定义大量的Rule(后面会讲到),SQL优化器会遍历语法树中每个节点,针对遍历到的节点模式匹配所有给定规则(Rule),如果有匹配成功的,就进行相应转换,如果所有规则都匹配失败,就继续遍历下一个节点。
Catalyst工作流程
任何一个优化器工作原理都大同小异:SQL语句首先通过Parser模块被解析为语法树,此棵树称为Unresolved Logical Plan;Unresolved Logical Plan通过Analyzer模块借助于数据元数据解析为Logical Plan;此时再通过各种基于规则的优化策略进行深入优化,得到Optimized Logical Plan;优化后的逻辑执行计划依然是逻辑的,并不能被Spark系统理解,此时需要将此逻辑执行计划转换为Physical Plan;为了更好的对整个过程进行理解,下文通过一个简单示例进行解释。
Parser
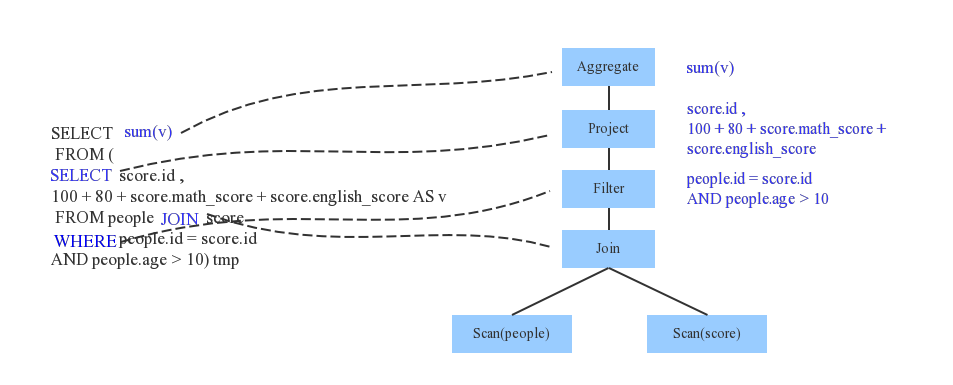
Parser简单来说是将SQL字符串切分成一个一个Token,再根据一定语义规则解析为一棵语法树。Parser模块目前基本都使用第三方类库ANTLR进行实现,比如Hive、 Presto、SparkSQL等。下图是一个示例性的SQL语句(有两张表,其中people表主要存储用户基本信息,score表存储用户的各种成绩),通过Parser解析后的AST语法树如右图所示:
Analyzer
通过解析后的逻辑执行计划基本有了骨架,但是系统并不知道score、sum这些都是些什么鬼,此时需要基本的元数据信息来表达这些词素,最重要的元数据信息主要包括两部分:表的Scheme和基本函数信息,表的scheme主要包括表的基本定义(列名、数据类型)、表的数据格式(Json、Text)、表的物理位置等,基本函数信息主要指类信息。
Analyzer会再次遍历整个语法树,对树上的每个节点进行数据类型绑定以及函数绑定,比如people词素会根据元数据表信息解析为包含age、id以及name三列的表,people.age会被解析为数据类型为int的变量,sum会被解析为特定的聚合函数,如下图所示:

SparkSQL中Analyzer定义了各种解析规则,有兴趣深入了解的童鞋可以查看Analyzer类,其中定义了基本的解析规则,如下:

Optimizer
优化器是整个Catalyst的核心,上文提到优化器分为基于规则优化和基于代价优化两种,当前SparkSQL 2.1依然没有很好的支持基于代价优化(下文细讲),此处只介绍基于规则的优化策略,基于规则的优化策略实际上就是对语法树进行一次遍历,模式匹配能够满足特定规则的节点,再进行相应的等价转换。因此,基于规则优化说到底就是一棵树等价地转换为另一棵树。SQL中经典的优化规则有很多,下文结合示例介绍三种比较常见的规则:谓词下推(Predicate Pushdown)、常量累加(Constant Folding)和列值裁剪(Column Pruning)。

上图左边是经过Analyzer解析后的语法树,语法树中两个表先做join,之后再使用age>10对结果进行过滤。大家知道join算子通常是一个非常耗时的算子,耗时多少一般取决于参与join的两个表的大小,如果能够减少参与join两表的大小,就可以大大降低join算子所需时间。谓词下推就是这样一种功能,它会将过滤操作下推到join之前进行,上图中过滤条件age>0以及id!=null两个条件就分别下推到了join之前。这样,系统在扫描数据的时候就对数据进行了过滤,参与join的数据量将会得到显著的减少,join耗时必然也会降低。
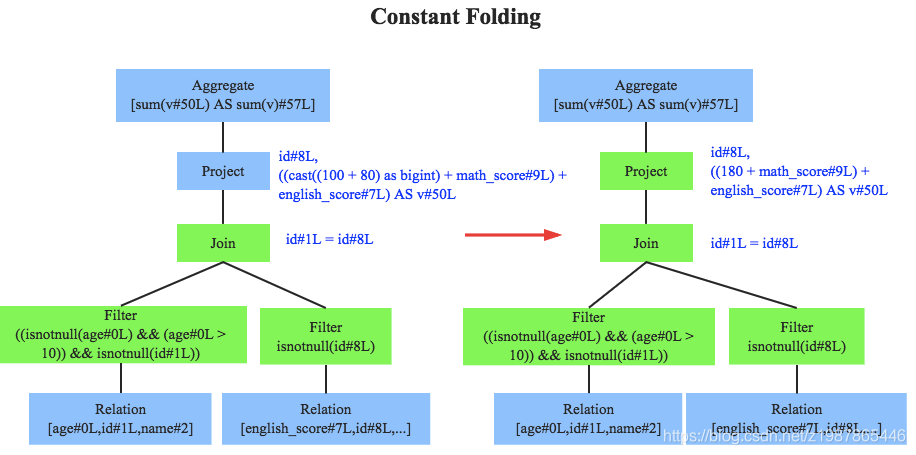
常量累加其实很简单,就是上文中提到的规则 x+(1+2) -> x+3,虽然是一个很小的改动,但是意义巨大。示例如果没有进行优化的话,每一条结果都需要执行一次100+80的操作,然后再与变量math_score以及english_score相加,而优化后就不需要再执行100+80操作。

列值裁剪是另一个经典的规则,示例中对于people表来说,并不需要扫描它的所有列值,而只需要列值id,所以在扫描people之后需要将其他列进行裁剪,只留下列id。这个优化一方面大幅度减少了网络、内存数据量消耗,另一方面对于列存数据库(Parquet)来说大大提高了扫描效率。除此之外,Catalyst还定义了很多其他优化规则,有兴趣深入了解的童鞋可以查看Optimizer类,下图简单的截取一部分规则:

至此,逻辑执行计划已经得到了比较完善的优化,然而,逻辑执行计划依然没办法真正执行,他们只是逻辑上可行,实际上Spark并不知道如何去执行这个东西。比如Join只是一个抽象概念,代表两个表根据相同的id进行合并,然而具体怎么实现这个合并,逻辑执行计划并没有说明。
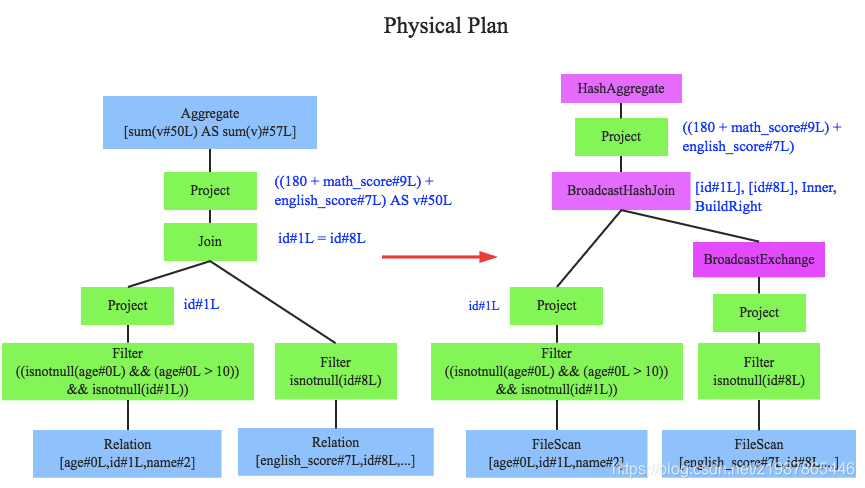
此时就需要将逻辑执行计划转换为物理执行计划,将逻辑上可行的执行计划变为Spark可以真正执行的计划。比如Join算子,Spark根据不同场景为该算子制定了不同的算法策略,有BroadcastHashJoin、ShuffleHashJoin以及SortMergeJoin等(可以将Join理解为一个接口,BroadcastHashJoin是其中一个具体实现),物理执行计划实际上就是在这些具体实现中挑选一个耗时最小的算法实现,这个过程涉及到基于代价优化策略,后续文章细讲。
SparkSQL执行计划
至此,笔者通过一个简单的示例完整的介绍了Catalyst的整个工作流程,包括Parser阶段、Analyzer阶段、Optimize阶段以及Physical Planning阶段。有同学可能会比较感兴趣Spark环境下如何查看一条具体的SQL的整个过程,在此介绍两种方法:
- 使用queryExecution方法查看逻辑执行计划,使用explain方法查看物理执行计划,分别如下所示:


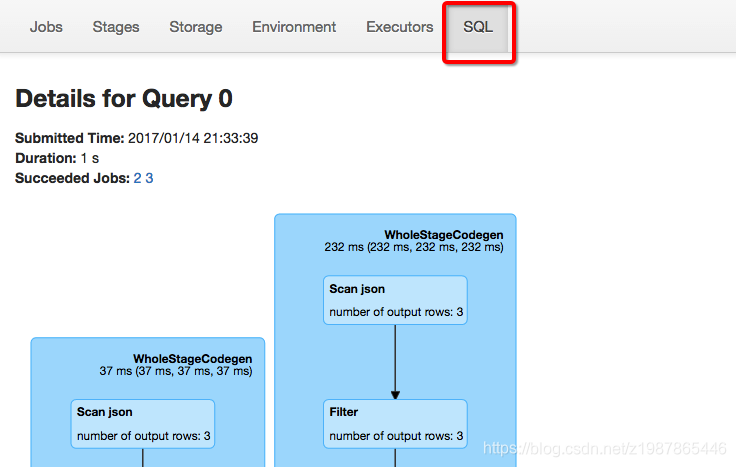
- 使用Spark WebUI进行查看,如下图所示:
参考文章
- Deep Dive into Spark SQL’s Catalyst Optimizer:https://databricks.com/blog/2015/04/13/deep-dive-into-spark-sqls-catalyst-optimizer.html
- A Deep Dive into Spark SQL’s Catalyst Optimiser:https://www.youtube.com/watch?v=GDeePbbCz2g&index=4&list=PL-x35fyliRwheCVvliBZNm1VFwltr5b6B
- Spark SQL: Relational Data Processing in Spark:http://people.csail.mit.edu/matei/papers/2015/sigmod_spark_sql.pdf
- 一个Spark SQL作业的一生:http://www.bitstech.net/2015/12/08/sparksql-introduction/
本文来自互联网用户投稿,文章观点仅代表作者本人,不代表本站立场,不承担相关法律责任。如若转载,请注明出处。 如若内容造成侵权/违法违规/事实不符,请点击【内容举报】进行投诉反馈!