spark sql解析过程中对tree的遍历(源码详解)
静下心来读源码,给想要了解spark sql底层解析原理的小伙伴们!
【本文大纲】
1、执行计划回顾
2、遍历过程概述
3、遍历过程详解
4、思考小问题
执行计划回顾
Spark sql执行计划的生成过程:
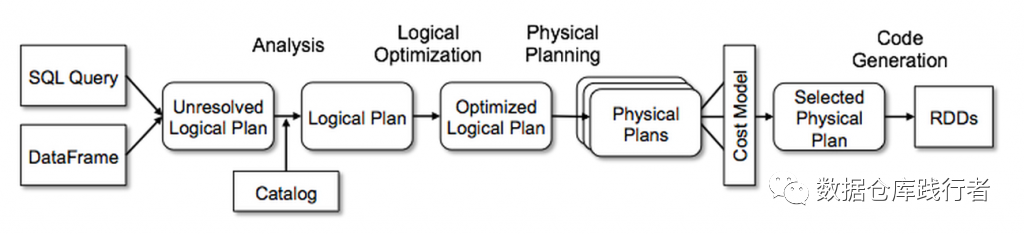
-
接收 sql 语句,初步解析成 logical plan
-
分析上步生成的 logical plan,生成验证后的 logical plan
-
对分析过后的 logical plan,进行优化
-
对优化过后的 logical plan,生成 physical plan
-
根据 physical plan,生成 rdd 的程序,并且提交运行
SELECT A,B FROM TESTDATA2 WHERE A>2结合上图,写测试用例,每一步生成的执行计划如下:

Spark sql解析会生成四种plan:
Parsed Logical Plan, Analyzed Logical Plan, Optimized Logical Plan, Physical Plan
上面这四种plan,无论是 LogicalPlan 还是 PhysicalPlan,都是通过树的形式表示。每一步都是对树进行操作,生成新的树。在这个过程中,对树的遍历非常重要。
遍历过程概述
最常用到的有 后序遍历 和 前序遍历 两种
后序遍历
TreeNode 中的 transformUp方法以及AnalysisHelper 中的 resolveOperatorsUp方法 等
这两个方法类似,以TreeNode 中的 transformUp为例:
def transformUp(rule: PartialFunction[BaseType, BaseType]): BaseType = {// 先遍历子节点,得到叶子节点val afterRuleOnChildren = mapChildren(_.transformUp(rule))//对节点执行规则val newNode = if (this fastEquals afterRuleOnChildren) {CurrentOrigin.withOrigin(origin) {//这里用到了PartialFunction的applyOrElse方法,用来避免undefined的情况发生。如果当前节点应用rule没有匹配的话,则返回默认的当前节点本身rule.applyOrElse(this, identity[BaseType])}} else {CurrentOrigin.withOrigin(origin) {rule.applyOrElse(afterRuleOnChildren, identity[BaseType])}}// If the transform function replaces this node with a new one, carry over the tags.newNode.copyTagsFrom(this)newNode
}递归逻辑:
-
递归结束条件:如果是子节点,那么使用该规则执行该节点,并且返回执行规则后的节点
-
递归继续条件:如果有子节点,那么先根据遍历子节点的结果,生成新节点。最后在使用该规则执行新节点
前序遍历
TreeNode 中的 transformDown方法以及AnalysisHelper 中的 resolveOperatorsDown方法 等
TreeNode 中的 transformDown为例:
def transformDown(rule: PartialFunction[BaseType, BaseType]): BaseType = {// 对当前节点,调用rule函数。val afterRule = CurrentOrigin.withOrigin(origin) {// 这里rule函数有可能会生成新的节点,新节点的子节点可能不一样rule.applyOrElse(this, identity[BaseType])}
// Check if unchanged and then possibly return old copy to avoid gc churn.//再遍历子节点 if (this fastEquals afterRule) {
// 如果当前节点没有变化,则继续遍历它的子节点mapChildren(_.transformDown(rule))} else {// 如果当前节点发生改变,需要对改变后的节点进行遍历afterRule.copyTagsFrom(this)afterRule.mapChildren(_.transformDown(rule))}
}递归逻辑:
-
递归结束条件:如果是叶子节点,那么使用规则对该节点操作,并且返回操作后的节点。
-
递归继续条件:如果不是叶子节点,那么先使用该规则对该节点操作。对操作后的该节点,继续遍历其子节点,用子节点的返回结果,来构建成新的节点。
遍历中的通用方法
上面几种方法中,都用到了TreeNode中的mapChildren、mapProductIterator方法
mapChildren
mapChildren 会依次调用函数对子节点操作,根据返回的结果生成一个新的节点。
def mapChildren(f: BaseType => BaseType): BaseType = {
//如果不是叶子节点,那么会执行mapChildren(f, forceCopy = false)方法,遍历构造函数的参数。如果参数是子节点,那么递归遍历
if (containsChild.nonEmpty) {mapChildren(f, forceCopy = false)} else {
//如果是叶子节点,则返回自身节点 this}
}
private def mapChildren(f: BaseType => BaseType,forceCopy: Boolean): BaseType = {var changed = false
def mapChild(child: Any): Any = child match {case arg: TreeNode[_] if containsChild(arg) =>val newChild = f(arg.asInstanceOf[BaseType])if (forceCopy || !(newChild fastEquals arg)) {changed = truenewChild} else {arg}case tuple @ (arg1: TreeNode[_], arg2: TreeNode[_]) =>val newChild1 = if (containsChild(arg1)) {f(arg1.asInstanceOf[BaseType])} else {arg1.asInstanceOf[BaseType]}
val newChild2 = if (containsChild(arg2)) {f(arg2.asInstanceOf[BaseType])} else {arg2.asInstanceOf[BaseType]}
if (forceCopy || !(newChild1 fastEquals arg1) || !(newChild2 fastEquals arg2)) {changed = true(newChild1, newChild2)} else {tuple}case other => other}
// 调用了mapProductIterator方法,遍历构造函数的参数,返回新的构造参数val newArgs = mapProductIterator {
// 如果参数是TreeNode子类,并且是当前节点的子节点case arg: TreeNode[_] if containsChild(arg) =>
// 递归调用函数遍历 这里的f可能是 transformUp or transformDownval newChild = f(arg.asInstanceOf[BaseType])
// 如果子节点发生变化了,则更改changed标识if (forceCopy || !(newChild fastEquals arg)) {changed = truenewChild} else {arg}case Some(arg: TreeNode[_]) if containsChild(arg) =>val newChild = f(arg.asInstanceOf[BaseType])if (forceCopy || !(newChild fastEquals arg)) {changed = trueSome(newChild)} else {Some(arg)}case m: Map[_, _] => m.mapValues {case arg: TreeNode[_] if containsChild(arg) =>val newChild = f(arg.asInstanceOf[BaseType])if (forceCopy || !(newChild fastEquals arg)) {changed = truenewChild} else {arg}case other => other}.view.force // `mapValues` is lazy and we need to force it to materializecase d: DataType => d // Avoid unpacking Structscase args: Stream[_] => args.map(mapChild).force // Force materialization on streamcase args: Iterable[_] => args.map(mapChild)case nonChild: AnyRef => nonChildcase null => null}// 如果子节点发生变化,则利用新的构造参数,实例化新的节点if (forceCopy || changed) makeCopy(newArgs, forceCopy) else this
}mapProductIterator
TreeNode 继承了 Product 接口,TreeNode 的子类实现了 Product 接口,所以支持访问构造方法的参数。TreeNode 的 mapProductIterator 方法,接收一个函数用来遍历当前节点的构造参数
这里有一个知识点(ClassTag用法):https://dzone.com/articles/scala-classtag-a-simple-use-case
//ClassTag用法def mapProductIterator[B: ClassTag](f: Any => B): Array[B] = {
// protected def mapProductIterator[B: ClassTag](f: Any => B): Array[B] = {val arr = Array.ofDim[B](productArity)var i = 0while (i < arr.length) {arr(i) = f(productElement(i))i += 1}arr
}遍历过程详解
下面以Parsed Logical Plan --> Analyzed Logical Plan的过程中 ,某个规则为例,详细跟踪一下这两种遍历方式。
分析一下当前的Parsed Logical Plan
当前sql
SELECT A,B FROM TESTDATA2 WHERE A>2生成的Parsed Logical Plan:
== Parsed Logical Plan =='Project ['A, 'B]+- 'Filter ('A > 2)+- 'UnresolvedRelation [TESTDATA2]
上面执行计划涉及到 三个类(Project、Filter、UnresolvedRelation):
case class Project(projectList: Seq[NamedExpression], child: LogicalPlan)
两个参数:
-
Project-projectList: Seq['A, 'B]
-
Project-child(LogicalPlan):
-
'Filter ('A > 2)
-
+- 'UnresolvedRelation [TESTDATA2]
Project有一个子节点Filter
case class Filter(condition: Expression, child: LogicalPlan)
两个参数:
-
Filter-condition:('A > 2)
-
Filter--child(LogicalPlan):
'UnresolvedRelation [TESTDATA2]
Filter有一个子节点UnresolvedRelation
case class UnresolvedRelation( multipartIdentifier: Seq[String])
一个参数:
-
UnresolvedRelation-multipartIdentifier: Seq[TESTDATA2]
UnresolvedRelation无子节点
Project、Filter、UnresolvedRelation与 LogicalPlan、 TreeNode的继承关系如下:
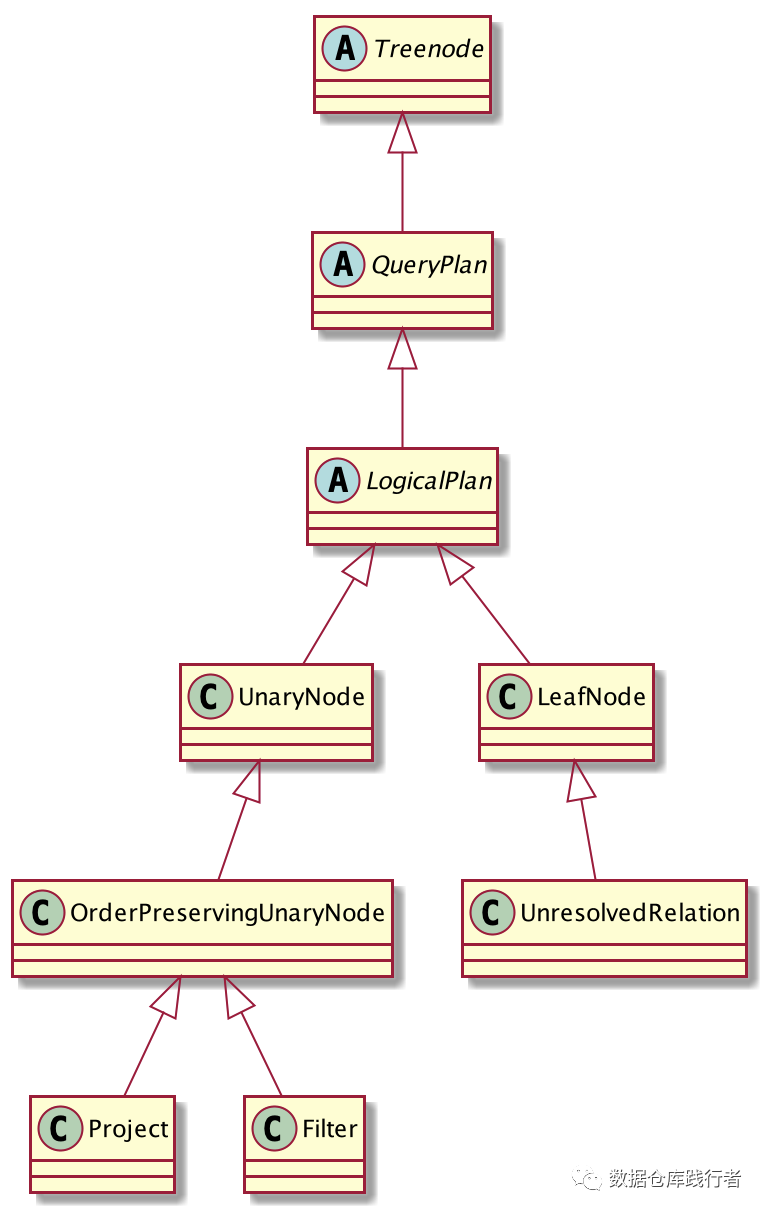
Project、Filter、UnresolvedRelation本身是Logical Plan 、TreeNode。
后序遍历(AnalysisHelper.resolveOperatorsUp)
Parsed Logical Plan 需要 通过Analyzer类中的一系列rule 转换生成Analyzed Logical Plan。
下图是Analyzer类中rule,会提前初始化在batches里:
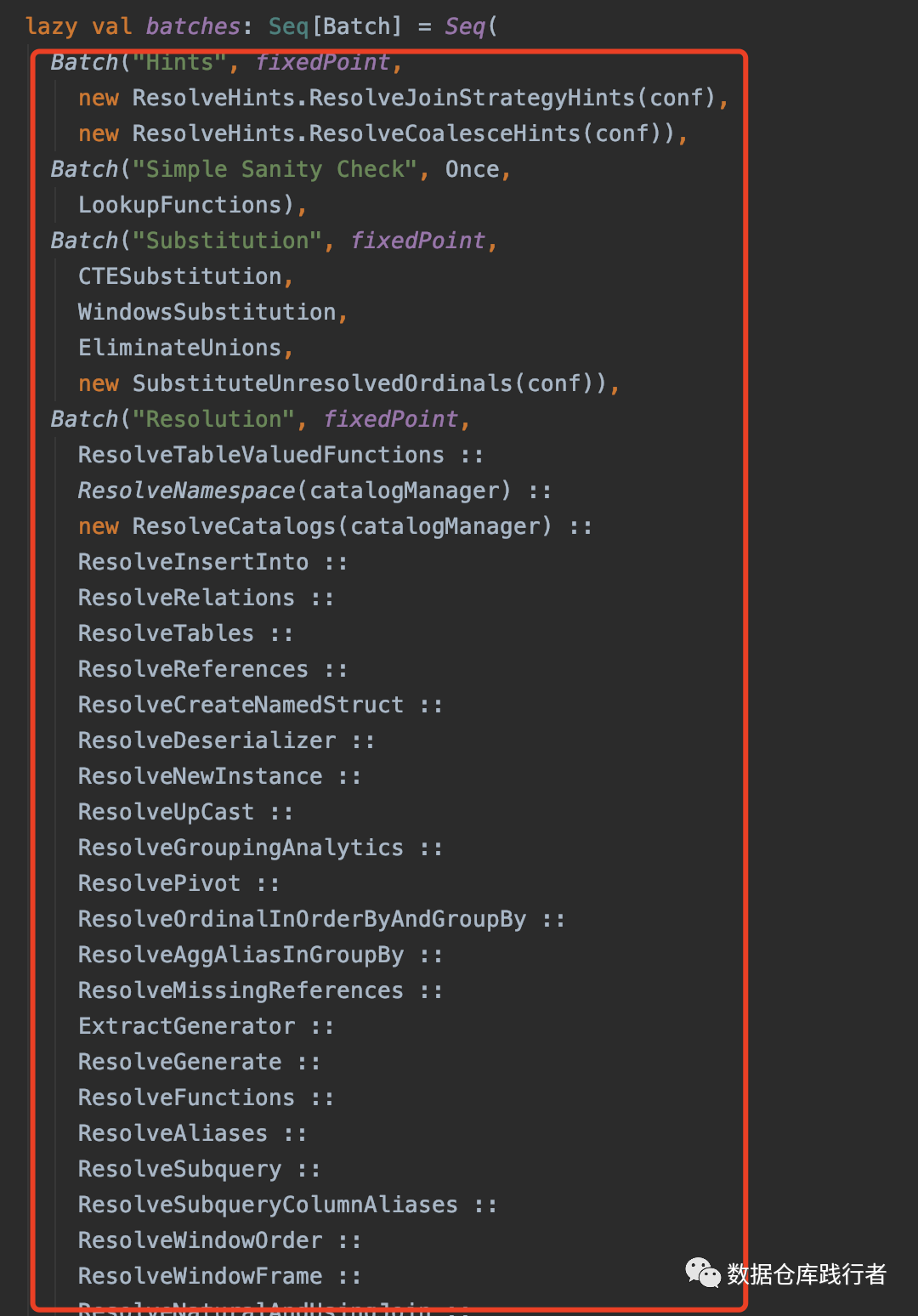
这里的rule通过apply方法遍历Parsed Logical Plan 的每个节点,依据定好的规则生成Analyzed Logical Plan,以 ResolveHints.ResolveJoinStrategyHint为例:
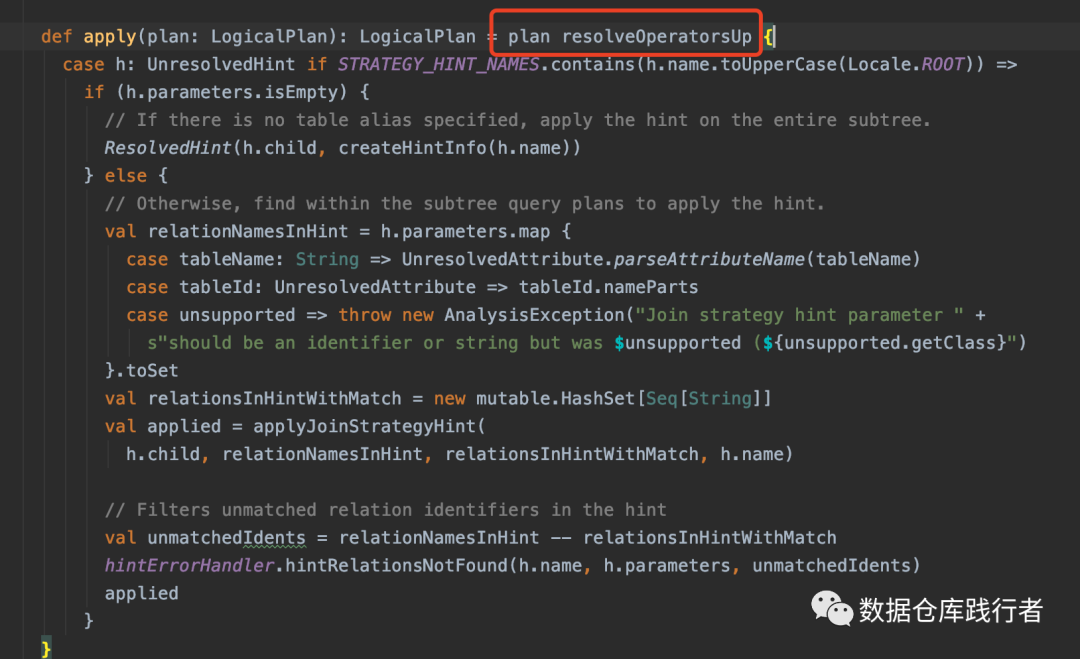
主要通过AnalysisHelper 中的 resolveOperatorsUp(后序遍历的)方法:
// 入参为rule,偏函数
def resolveOperatorsUp(rule: PartialFunction[LogicalPlan, LogicalPlan]): LogicalPlan = {if (!analyzed) {AnalysisHelper.allowInvokingTransformsInAnalyzer {// 1、先遍历子节点,得到叶子节点val afterRuleOnChildren = mapChildren(_.resolveOperatorsUp(rule))//2、为节点执行规则if (self fastEquals afterRuleOnChildren) {CurrentOrigin.withOrigin(origin) {// 如果遍历后当前节点没有发生变化,对当前的plan执行rule规则rule.applyOrElse(self, identity[LogicalPlan])}} else {CurrentOrigin.withOrigin(origin) {// 如果遍历后 当前 节点发 生了变化,则新负值的afterRuleOnChildren执行rule规则rule.applyOrElse(afterRuleOnChildren, identity[LogicalPlan])}}}} else {self}
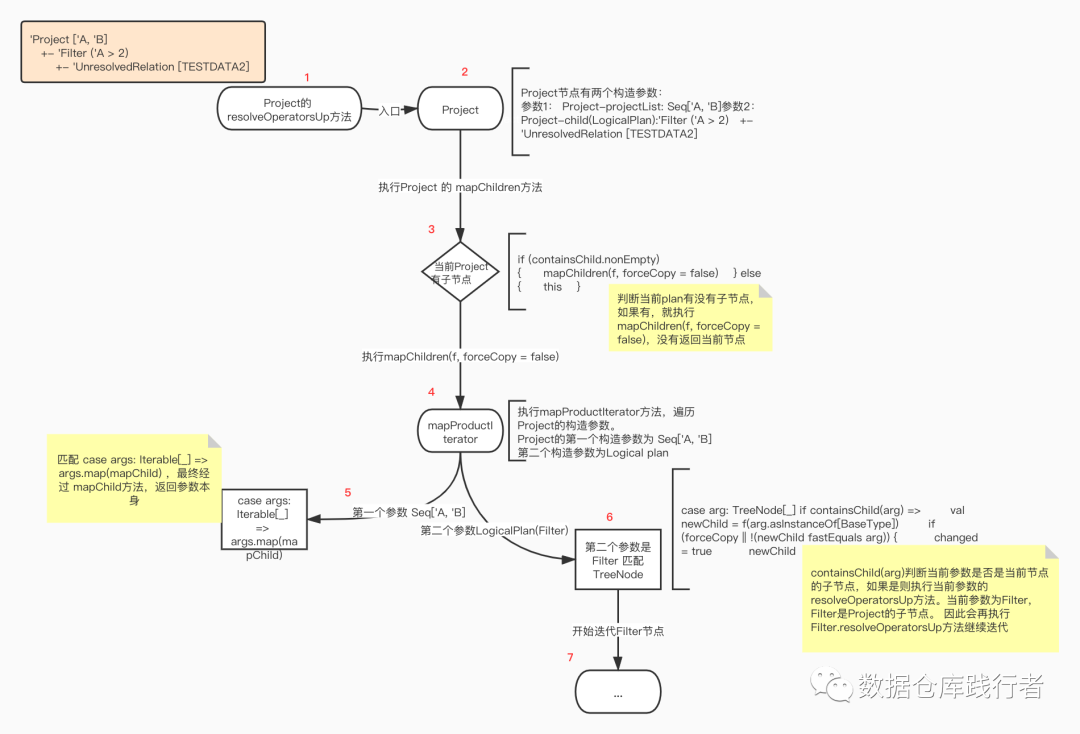
}当前的节点为Project,执行Project 的 resolveOperatorsUp 方法,该方法会先遍历Project的子节点。
第一层遍历:
执行Project 的 mapChildren方法
第二层遍历:
执行Filter 的 mapChildren方法
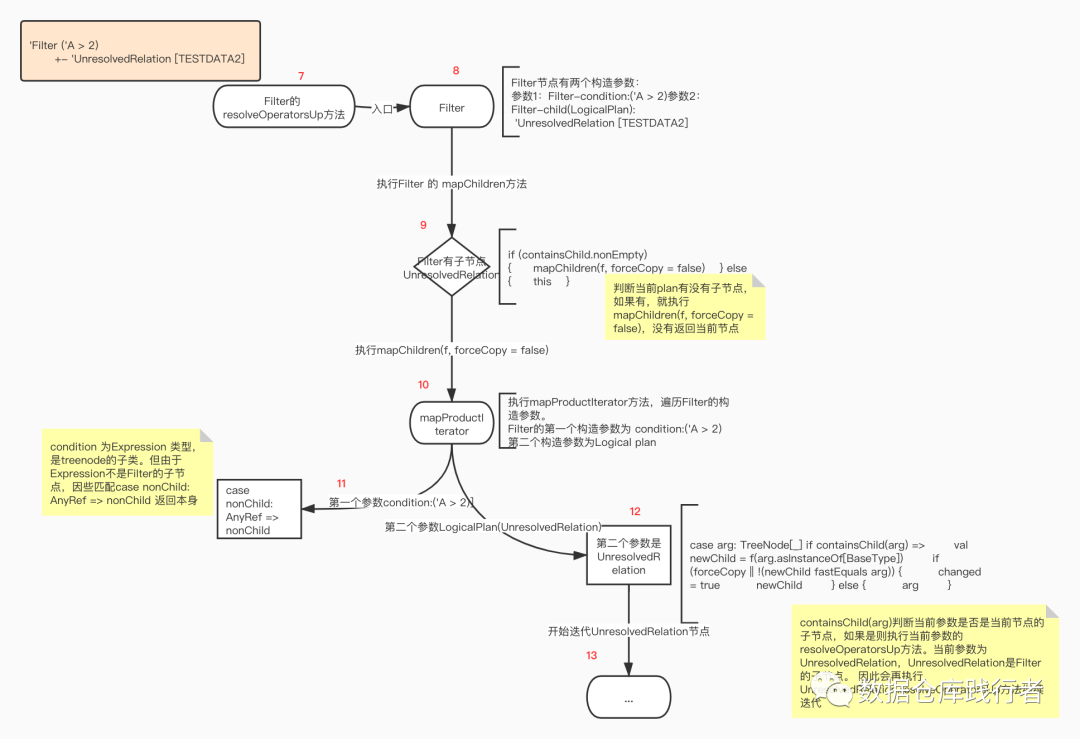
第三层遍历:
执行UnresolvedRelation 的 mapChildren方法
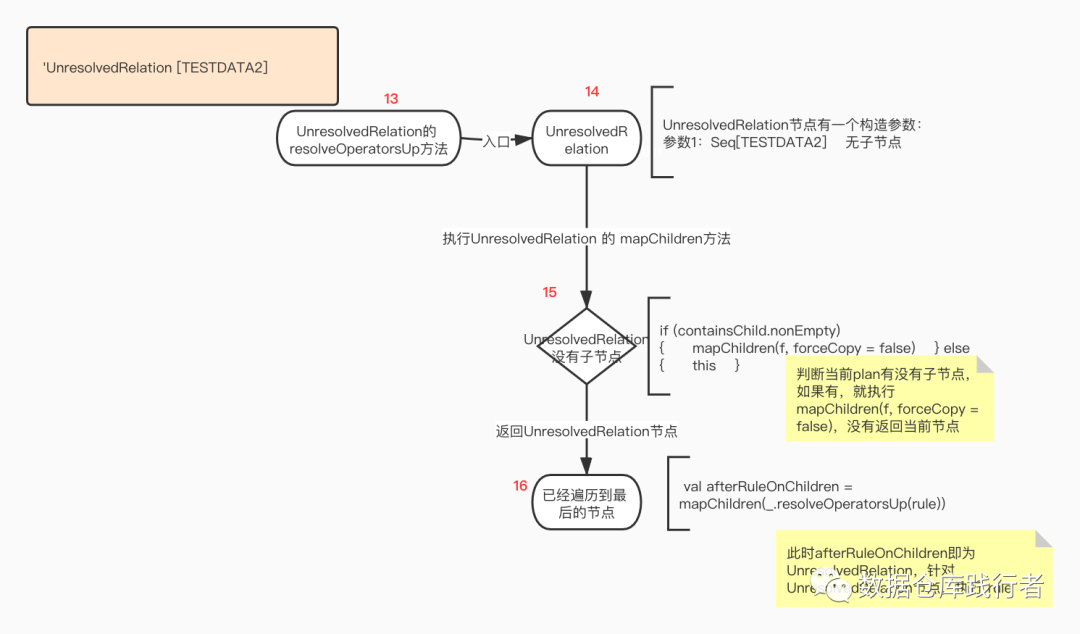
由 于 UnresolvedRelation为子节点,返回节点本 身,为UnresolvedRelation执行rule。
为UnresolvedRelation节点执行ResolveJoinStrategyHint的apply方法:
// 该规则主要是针对Hint节点起作用 ,目前是UnresolvedRelation节点
def apply(plan: LogicalPlan): LogicalPlan = plan resolveOperatorsUp {case h: UnresolvedHint if STRATEGY_HINT_NAMES.contains(h.name.toUpperCase(Locale.ROOT)) =>if (h.parameters.isEmpty) {// If there is no table alias specified, apply the hint on the entire subtree.ResolvedHint(h.child, createHintInfo(h.name))} else {// Otherwise, find within the subtree query plans to apply the hint.val relationNamesInHint = h.parameters.map {case tableName: String => UnresolvedAttribute.parseAttributeName(tableName)case tableId: UnresolvedAttribute => tableId.namePartscase unsupported => throw new AnalysisException("Join strategy hint parameter " +s"should be an identifier or string but was $unsupported (${unsupported.getClass}")}.toSetval relationsInHintWithMatch = new mutable.HashSet[Seq[String]]val applied = applyJoinStrategyHint(h.child, relationNamesInHint, relationsInHintWithMatch, h.name)
// Filters unmatched relation identifiers in the hintval unmatchedIdents = relationNamesInHint -- relationsInHintWithMatchhintErrorHandler.hintRelationsNotFound(h.name, h.parameters, unmatchedIdents)applied}
}这个规则主要是 对Hint节点起作用,但目前是UnresolvedRelation节点,不能匹配的上。因此通过
rule.applyOrElse(self, identity[LogicalPlan])之后,返回UnresolvedRelation本身。
UnresolvedRelation返回后,就会接着先后为Filter-->Project执行ResolveJoinStrategyHint规则,最后返回Project本身。
到此,整个ResolveJoinStrategyHint对Logical plan的 遍历及执行规则的 过 程 就结束了。
前序遍历(AnalysisHelper.resolveOperatorsDown)
Analyzer 中的 ExtractWindowExpressions规则
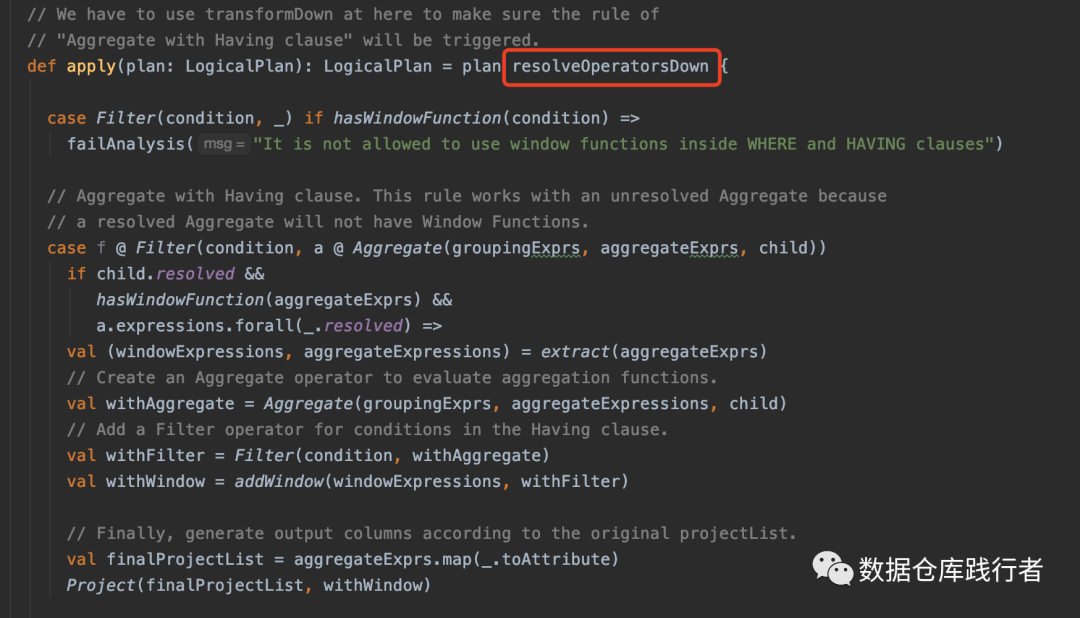
主要通过AnalysisHelper 中的 resolveOperatorsDown方法:
/** Similar to [[resolveOperatorsUp]], but does it top-down. */
def resolveOperatorsDown(rule: PartialFunction[LogicalPlan, LogicalPlan]): LogicalPlan = {if (!analyzed) {AnalysisHelper.allowInvokingTransformsInAnalyzer { val afterRule = CurrentOrigin.withOrigin(origin) {// 1、为当前节点执行规则rule.applyOrElse(self, identity[LogicalPlan])}
// 2、对执行完规则后的新节点遍历迭代if (self fastEquals afterRule) {//如果执行完规则后的节点没有变化(即规则没有起到作用),则对节点遍历迭代mapChildren(_.resolveOperatorsDown(rule))} else {//如果执行完规则后的节点发生变化,则对新节点遍历迭代afterRule.mapChildren(_.resolveOperatorsDown(rule))}}} else {self}
}先为Project节点执行ExtractWindowExpressions.apply方法:
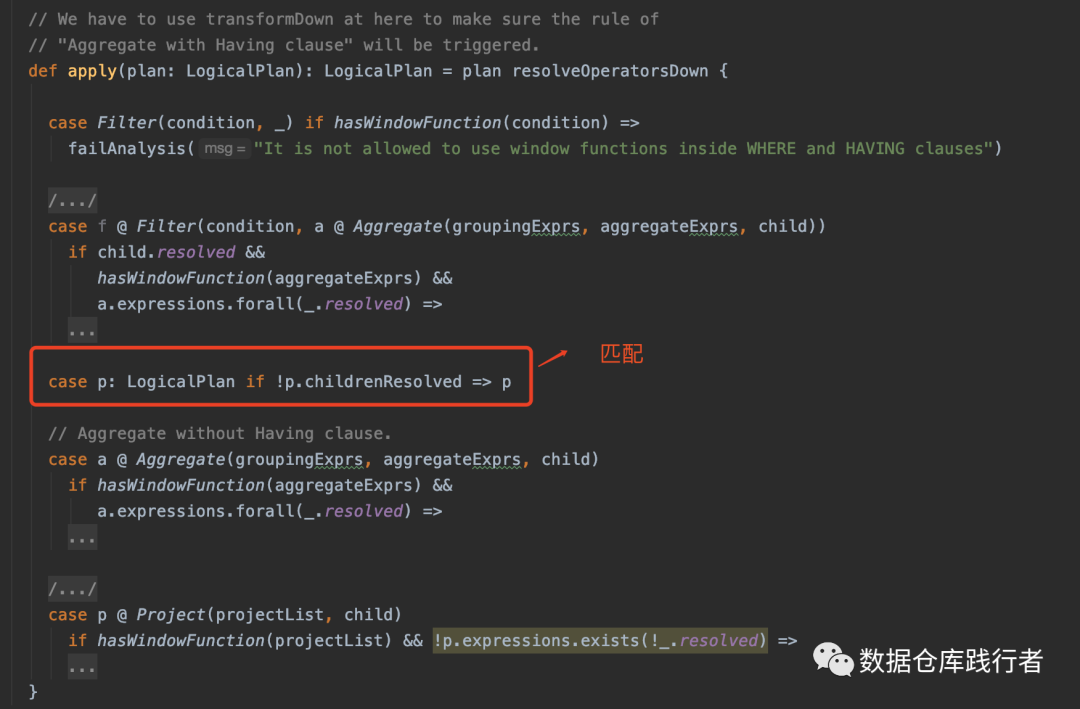
Project节点模式匹配case p: LogicalPlan if !p.childrenResolved => p 返回Project节点本身
第一层遍历:
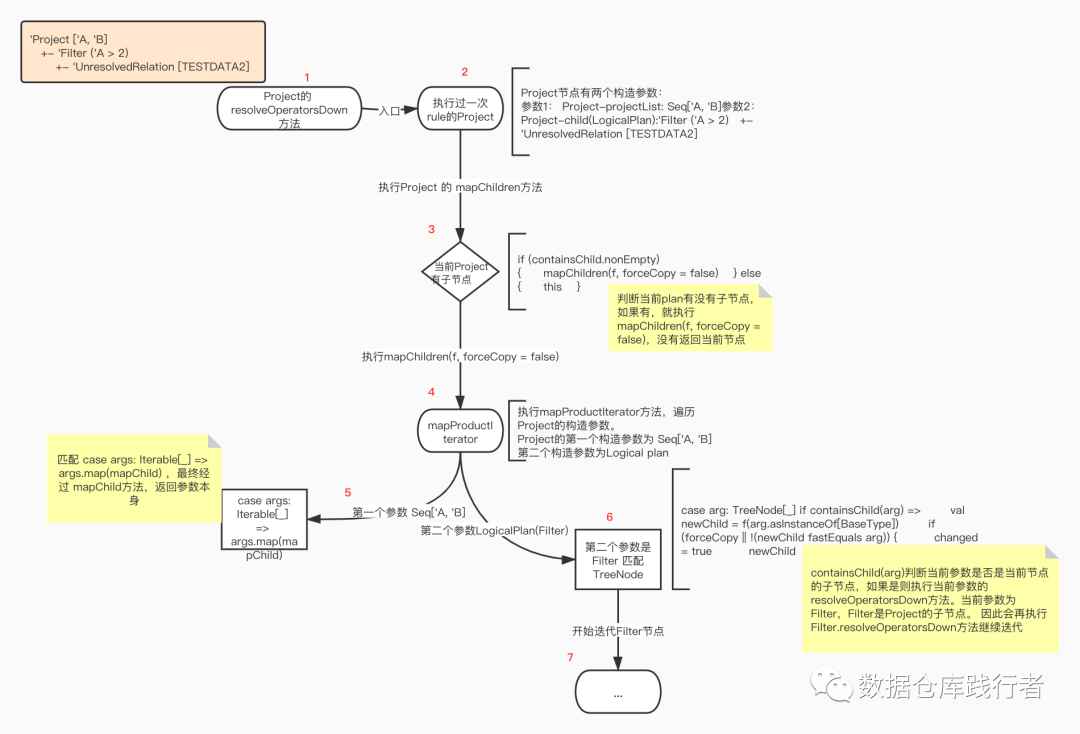
得到Project的子节点Filter,执行Filter.resolveOperatorsDown方法,先对Filter节点执行ExtractWindowExpressions.apply方法,跑一遍规则,最后由于sql没有用到window相关函数,返回Filter节点本身,开始对Filter节点进行遍历
第二层遍历:
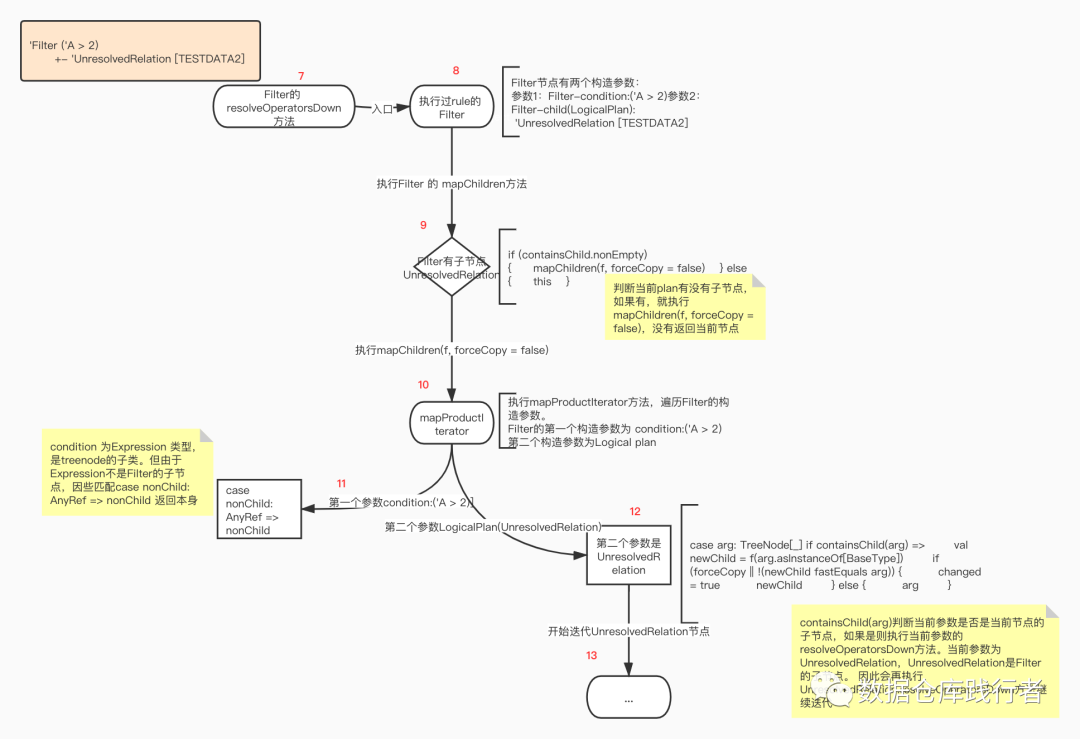
得到Filter的子节点UnresolvedRelation,执行UnresolvedRelation.resolveOperatorsDown方法,先对UnresolvedRelation节点执行ExtractWindowExpressions.apply方法,跑一遍规则,返回UnresolvedRelation节点本身,开始对UnresolvedRelation节点进行遍历
第三层遍历:
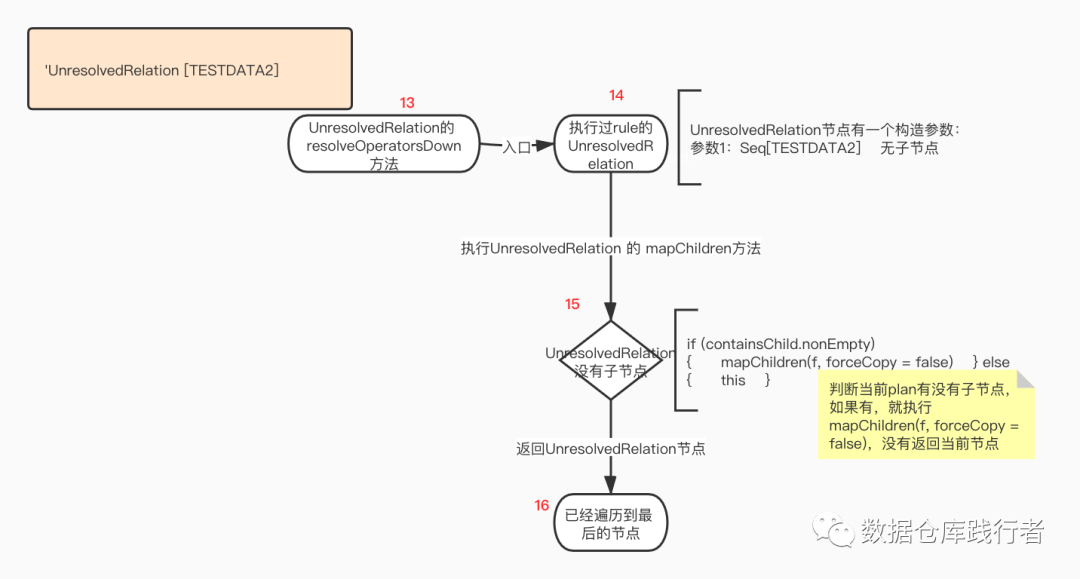
UnresolvedRelation没有子节点,在mapChildren方法被返回。
最终 返回Project节点,ExtractWindowExpressions执行完成。
思考
什么rule适合用后序遍历?什么rule适合前序遍历?
当我们自己开发规则时,该怎么选呢?
推荐阅读--
SparkSql源码成神之路
sparksql源码系列 | 最全的logical plan优化规则整理(spark2.3)
Sparksql源码系列 | 读源码必须掌握的scala基础语法
澄清 | snappy压缩到底支持不支持split? 为啥?
以后的事谁也说不准
转型【数仓开发】该怎么学
大数据开发轻量级入门方案
OLAP | 基础知识梳理
本文来自互联网用户投稿,文章观点仅代表作者本人,不代表本站立场,不承担相关法律责任。如若转载,请注明出处。 如若内容造成侵权/违法违规/事实不符,请点击【内容举报】进行投诉反馈!