大数据平台搭建 | Hadoop 集群搭建
1、环境说明
- 基于Apache Hadoop 3.1.3 版本
- 依赖JDK环境
- Hadoop3.1.3下载地址
2、Hadoop架构
- 狭义上的hadoop主要包括三大组件
分布式存储HDFS、分布式计算MapReduce、分布式资源管理和调度YARN
2.1 HDFS架构
-
主要负责数据的存储
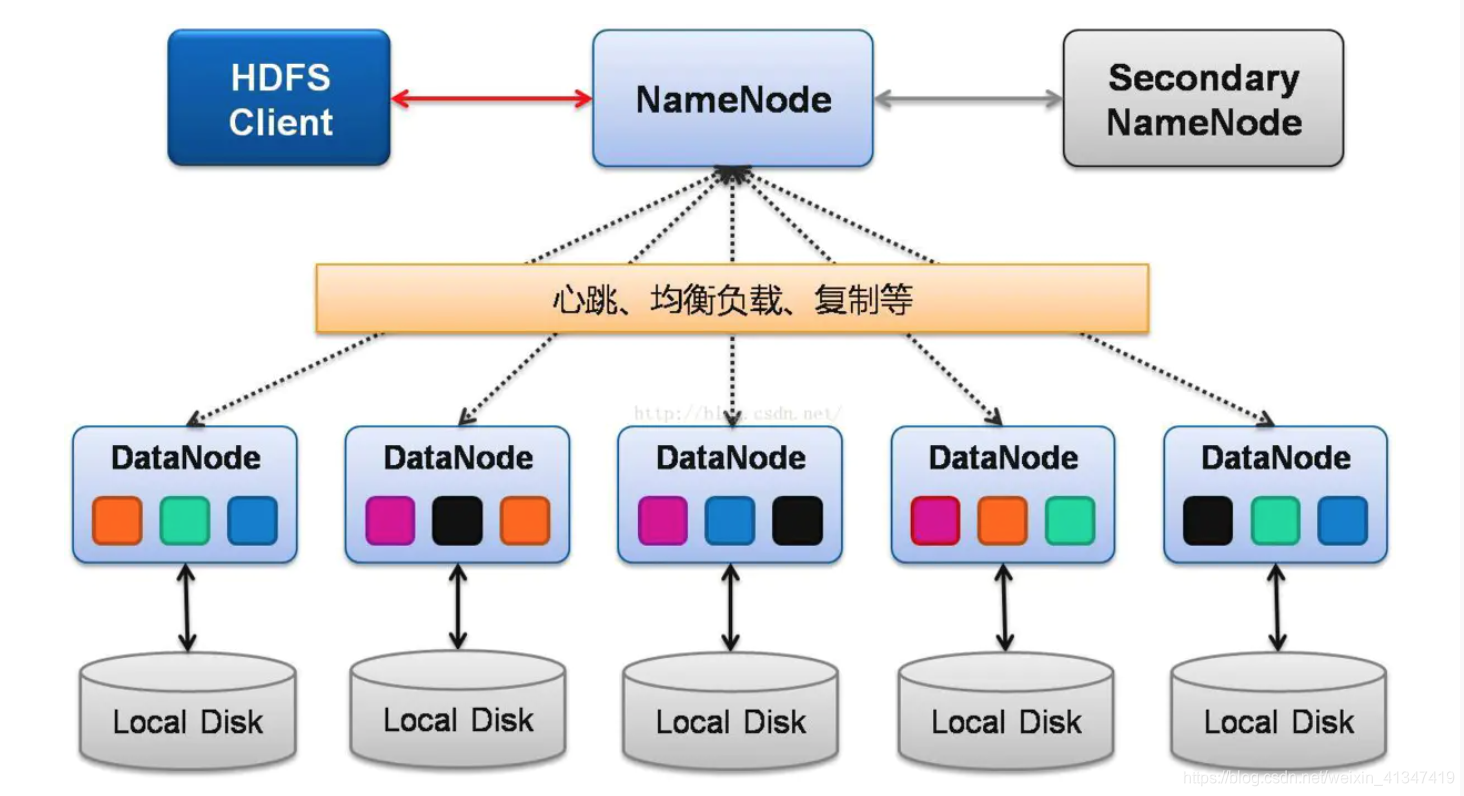
-
NameNode: 管理命名空间、存储数据块映射信息(元数据)、 负责处理客户端对HDFS的访问. -
SecondaryNameNode: NameNode 的热备, 会定期合并命名空间镜像 fsimage和命名空间镜像的编辑日志fsedits, 在主NameNode发生故障时, 可以 快速切换为新的 Active NameNode -
DataNode: 负责实际文件数据的存储、文件会被拆分成多个块, 以多副本方式存储在不同的DataNode
2.2 Yarn 架构
- 主要负责作业的调度 和 资源的管理
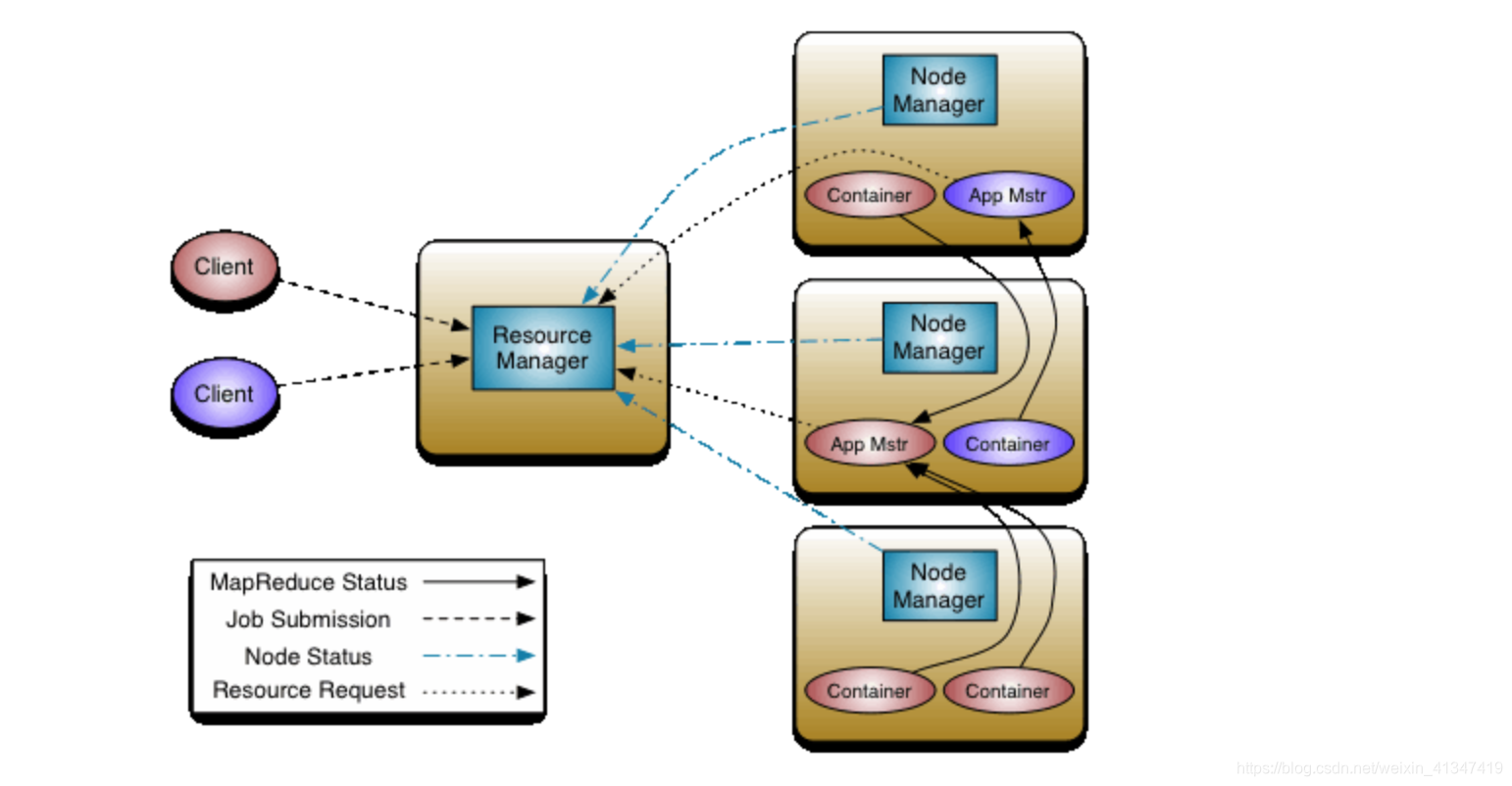
ResourceManager(RM):- 处理提交的作业请求, 资源申请请求.
- 监控NodeManager的状态
- 启动和监控ApplicationMaster
NodeManager(NM):- 管理每个节点上运行的资源
- 定时向 RM 汇报本节点上的资源使用情况和各个 Container 的运行状态
- 处理来自AM 对 各个Container 启动/停止等请求
Container:- 即是任务运行的容器又是Yarn对资源的抽象, 封装了某个节点上的多维度资源,如内存、CPU、磁盘、网络等. RM 为 AM 返回的资源便是用 Container 表示的。 YARN 会为每个任务分配一个 Container 且该任务只能使用该 Container 中描述的资源
ApplicationMaster(AM):- 每个作业会在NM中启动一个AM, 然后由AM去负责发送MapTask、ReduceTask任务的启动请求给NM, 以及向RM申请任务执行所需要的资源
- 与RM交互去申请资源Container(比如作业执行的资源, 任务执行的资源)
- 负责启动、停止任务, 并且监控所有任务的运行状态,当任务Task有失败时,重新为任务申请资源并重启任务
3、集群规划
如无特别说明,每台服务器要保持一样的配置
| Hadoop300 | Hadoop301 | Hadoop302 | |
|---|---|---|---|
| NameNode | V | ||
| DataNode | V | V | V |
| SecondaryNameNode | V | ||
| ResourceManger | V | ||
| NodeManger | V | V | V |
4、下载解压
4.1 安装包放置
- 将下载的
hadoop3.1.3解压并创建快捷方式到~/app目录下, hadoop301,hadoop302同理
[hadoop@hadoop300 app]$ pwd
/home/hadoop/app
[hadoop@hadoop300 app]$ ll
lrwxrwxrwx 1 hadoop hadoop 47 2月 21 12:33 hadoop -> /home/hadoop/app/manager/hadoop_mg/hadoop-3.1.34.2 配置Hadoop环境变量
vim ~/.bash_profile
# ============ java =========================
export JAVA_HOME=/home/hadoop/app/jdk
export PATH=$PATH:$JAVA_HOME/bin# ======================= Hadoop ============================
export HADOOP_HOME=/home/hadoop/app/hadoop
export PATH=$PATH:$HADOOP_HOME/bin
export PATH=$PATH:$HADOOP_HOME/sbin
5、hadoop配置
5.1 env文件
- 修改
${HADOOP_HOME}/etc/hadoop下的hadoop-env.sh, mapred-env.sh、yarn-env.sh这三个文件都添加JDK的环境变量
export JAVA_HOME=/home/hadoop/app/jdk
5.2 core-site.xml
- 修改
${HADOOP_HOME}/etc/hadoop/core-site.xml文件 - 关于代理用户的配置见官网 Proxy User
<property><name>fs.defaultFSname><value>hdfs://hadoop300:8020value>
property>
<property><name>hadoop.http.staticuser.username><value>hadoopvalue>property><property><name>hadoop.proxyuser.hadoop.hostsname><value>*value>property><property><name>hadoop.proxyuser.hadoop.groupsname><value>*value>property><property><name>hadoop.proxyuser.hadoop.usersname><value>*value>property>
5.3 hdfs-site.xml 文件 (hdfs配置)
- 配置HDFS相关属性
<property><name>dfs.replicationname><value>2value>
property>
<property><name>dfs.namenode.secondary.http-addressname><value>hadoop302:9868value>
property>
5.4 yarn-site.xml (yarn配置)
- 配置yarn相关属性
<property><name>yarn.nodemanager.aux-servicesname><value>mapreduce_shufflevalue>
property>
<property><name>yarn.resourcemanager.hostnamename><value>hadoop301value>
property>
<property><name>yarn.scheduler.minimum-allocation-mbname><value>200value>
property>
<property><name>yarn.scheduler.maximum-allocation-mbname><value>2048value>
property>
<property><name>yarn.nodemanager.resource.memory-mbname><value>4096value>
property>
<property><name>yarn.nodemanager.pmem-check-enabledname><value>falsevalue>
property>
<property><name>yarn.nodemanager.vmem-check-enabledname><value>falsevalue>
property>
<property><name>yarn.log.server.urlname><value>http://hadoop300:19888/jobhistory/logs/value>
property>
<property><name>yarn.log-aggregation-enablename><value>truevalue>
property>
<property><name>yarn.log-aggregation.retain-secondsname><value>604800value>
property>5.5 mapred-site.xml (MapReduce配置)
- 配置MapReduce相关设置
<property><name>mapreduce.framework.namename><value>yarnvalue>
property><property><name>mapreduce.jobhistory.addressname><value>hadoop300:10020value>property><property><name>mapreduce.jobhistory.webapp.addressname><value>hadoop300:19888value>property>
<property><name>yarn.app.mapreduce.am.envname><value>HADOOP_MAPRED_HOME=${HADOOP_HOME}value>
property>
<property><name>mapreduce.map.envname><value>HADOOP_MAPRED_HOME=${HADOOP_HOME}value>
property>
<property><name>mapreduce.reduce.envname><value>HADOOP_MAPRED_HOME=${HADOOP_HOME}value>
property>5.6 workers 文件配置
- 修改
${HADOOP_HOME}/etc/hadoop/workers文件, 设置Hadoop集群节点列表tip: 注意不要出现空行和空格
hadoop300
hadoop301
hadoop302
6、启动测试
6.1 格式化NameNode
- 在hadoop300执行
[hadoop@hadoop300 app]$ hdfs namenode -format
6.2 启动Hdfs
- 在hadoop300启动
[hadoop@hadoop300 ~]$ start-dfs.sh
Starting namenodes on [hadoop300]
Starting datanodes
Starting secondary namenodes [hadoop302]
6.3 启动Yarn
- 在hadoop301启动
[hadoop@hadoop301 ~]$ start-yarn.sh
Starting resourcemanager
Starting nodemanagers
6.4 启动JobHistory
[hadoop@hadoop300 hadoop]$ mapred --daemon start historyserver
6.5 效果
- 启动成功后jps查看进程
- 这时hdfs的nn、dn、sn都启动起来了,
- 而yarn的RM、NM也启动起来了
- mr的JobHistory也启动起来了
[hadoop@hadoop300 hadoop]$ xcall jps
--------- hadoop300 ----------
16276 JobHistoryServer
30597 DataNode
19641 Jps
30378 NameNode
3242 NodeManager
--------- hadoop301 ----------
24596 DataNode
19976 Jps
27133 ResourceManager
27343 NodeManager
--------- hadoop302 ----------
24786 SecondaryNameNode
27160 NodeManager
24554 DataNode
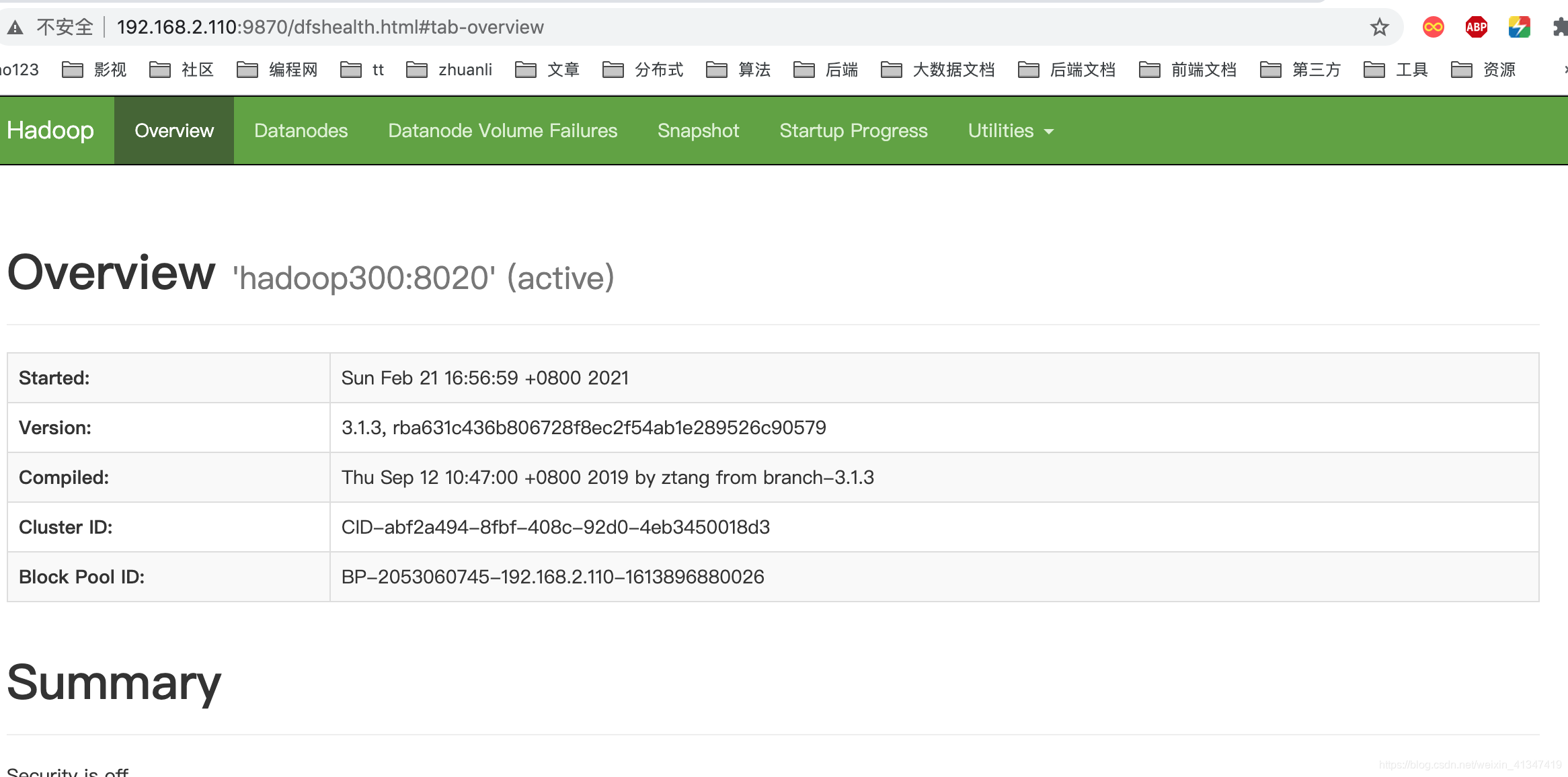
19676 Jps访问HDFS的NameNode界面 在hadoop300:9870
访问HDFS的SecondaryNameNode界面 在hadoop300:9868

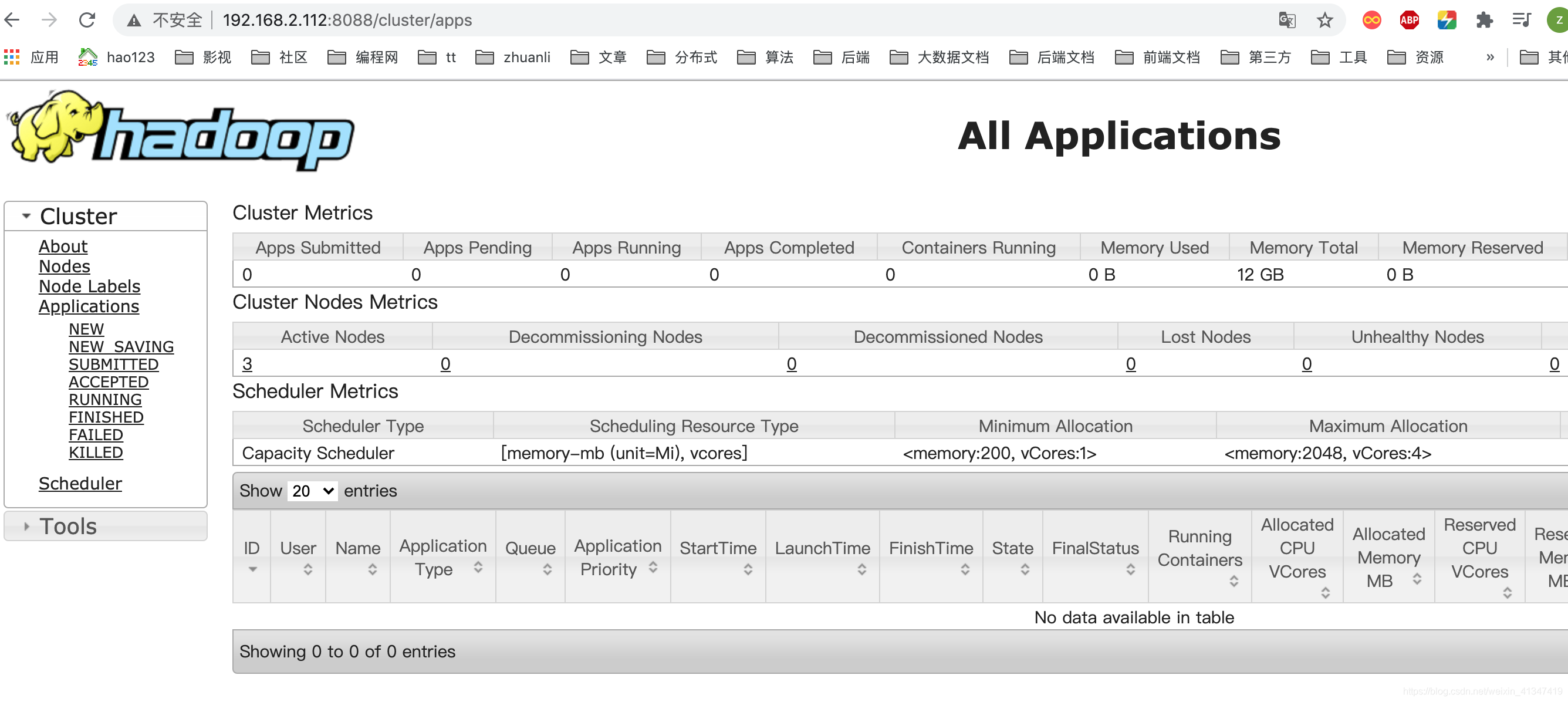
访问Yarn管理界面: 在hadoop301:8088
访问JobHistory的界面, 在hadoop300:19888
7、hadoop集群统一启动脚本
vim hadoop.sh
#!/bin/bashcase $1 in
"start"){echo ---------- Hadoop 集群启动 ------------echo "启动Hdfs"ssh hadoop300 "source ~/.bash_profile;start-dfs.sh"echo "启动Yarn"ssh hadoop300 "source ~/.bash_profile;mapred --daemon start historyserver"echo "启动JobHistory"ssh hadoop301 "source ~/.bash_profile;start-yarn.sh"
};;
"stop"){echo ---------- Hadoop 集群停止 ------------echo "关闭Hdfs"ssh hadoop300 "source ~/.bash_profile;stop-dfs.sh"echo "关闭Yarn"ssh hadoop300 "source ~/.bash_profile;mapred --daemon stop historyserver"echo "关闭JobHistory"ssh hadoop301 "source ~/.bash_profile;stop-yarn.sh"
};;
esac
10、打赏

本文来自互联网用户投稿,文章观点仅代表作者本人,不代表本站立场,不承担相关法律责任。如若转载,请注明出处。 如若内容造成侵权/违法违规/事实不符,请点击【内容举报】进行投诉反馈!