大数据平台搭建全过程(VMware+Xshell+Hadoop)
目录
资源地址汇总
JDK下载地址
Hadoop下载地址
VMware下载地址
Xshell下载地址
CentOS 7下载地址
Mysql-connector-java
Hive下载地址
搭建虚拟机
安装VMware
centOS7安装包准备
创建虚拟机
安装centOS 7
centOS 7虚拟机配置
配置网络
关闭防火墙
配置host
给机器改个名(非必要)
设置免密登录
安装软件
安装vim
安装lrzsz
安装Xshell
安装
配置
安装jdk(要java1.8)
安装
配置环境变量
安装Hadoop并配置环境(所有环境配置重启后生效)
下载hadoop安装包
上传文件
设置共享文件夹
共享文件夹不生效方法
解压Hadoop文件
配置环境变量
Hadoop配置
配置hadoop-env.sh
配置hdfs.site.xml
配置core-site
检测Hadoop安装是否成功
Hadoop格式化和启动
格式化
启动
查看节点
hadoop 常用命令
查看Yarn 的Web 页面
使用yarn 执行任务
docker安装
MySQL安装
创建mysql容器(这里最后不带上版本号容易创建失败)
查看mysql 容器
资源地址汇总
JDK下载地址
(注意版本)
Java Downloads | Oracle https://www.oracle.com/java/technologies/downloads/#java8
https://www.oracle.com/java/technologies/downloads/#java8
Hadoop下载地址
(下载Binary格式的)
Apache Hadoophttps://hadoop.apache.org/releases.html
VMware下载地址
(破解密钥可自行百度搜索,很好找)
Download VMware Workstation Pro![]() https://www.vmware.com/products/workstation-pro/workstation-pro-evaluation.html
https://www.vmware.com/products/workstation-pro/workstation-pro-evaluation.html
Xshell下载地址
XShell - DownloadXShell, free and safe download. XShell latest version: An easy-to-use terminal emulator!. XShell is a popular and straightforward network program desi https://xshell.en.softonic.com/
https://xshell.en.softonic.com/
CentOS 7下载地址
(原网址下载太慢了,这里用阿里镜像,选择后缀为ISO的DVD文件)
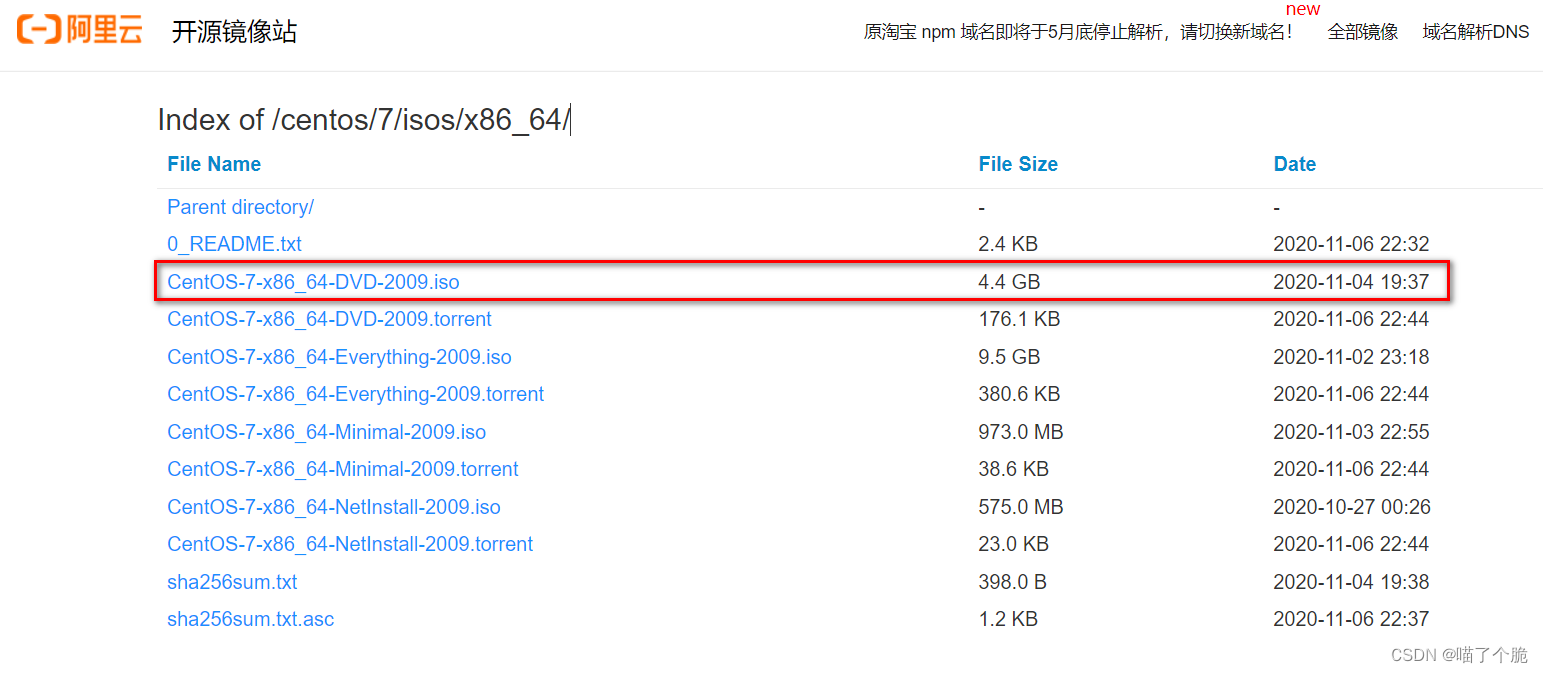
centos-7-isos-x86_64安装包下载_开源镜像站-阿里云centos-7-isos-x86_64安装包是阿里云官方提供的开源镜像免费下载服务,每天下载量过亿,阿里巴巴开源镜像站为包含centos-7-isos-x86_64安装包的几百个操作系统镜像和依赖包镜像进行免费CDN加速,更新频率高、稳定安全。![]() http://mirrors.aliyun.com/centos/7/isos/x86_64/
http://mirrors.aliyun.com/centos/7/isos/x86_64/
Mysql-connector-java
(这个链接有很多版本可以选择)
https://mvnrepository.com/artifact/mysql/mysql-connector-java![]() https://mvnrepository.com/artifact/mysql/mysql-connector-java(下面是mysql官网下载地址)
https://mvnrepository.com/artifact/mysql/mysql-connector-java(下面是mysql官网下载地址)
MySQL :: Download MySQL Installerhttps://dev.mysql.com/downloads/installer/
Hive下载地址
Index of /dist/hive![]() http://archive.apache.org/dist/hive/
http://archive.apache.org/dist/hive/
搭建虚拟机
安装VMware
centOS7安装包准备
下载 centOS7进入阿里云镜像网站,选择
创建虚拟机
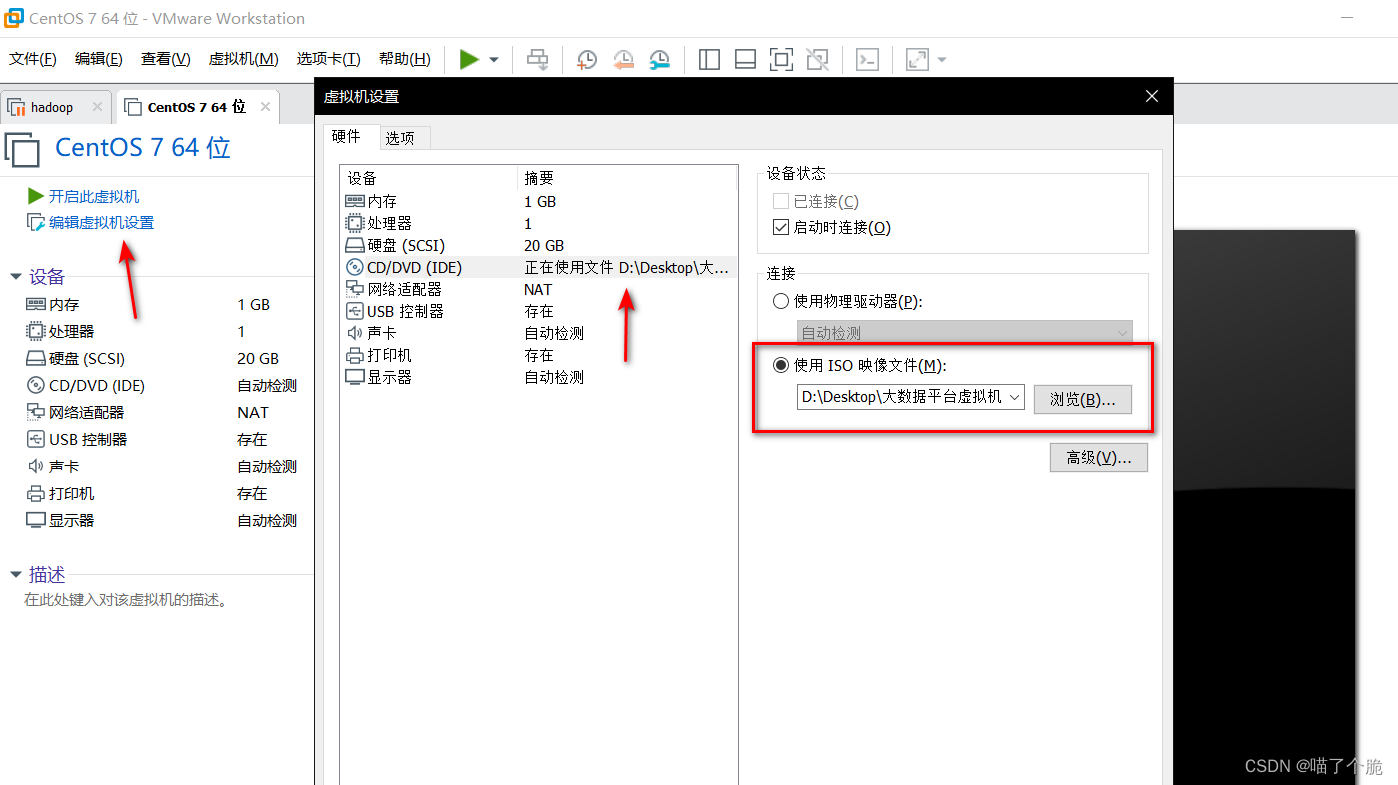
按照网上教程新建一个虚拟机,点击编辑虚拟机设置,点击CD/DVD,选择使用ISO印象文件,把刚才的centOS.ios加载进去
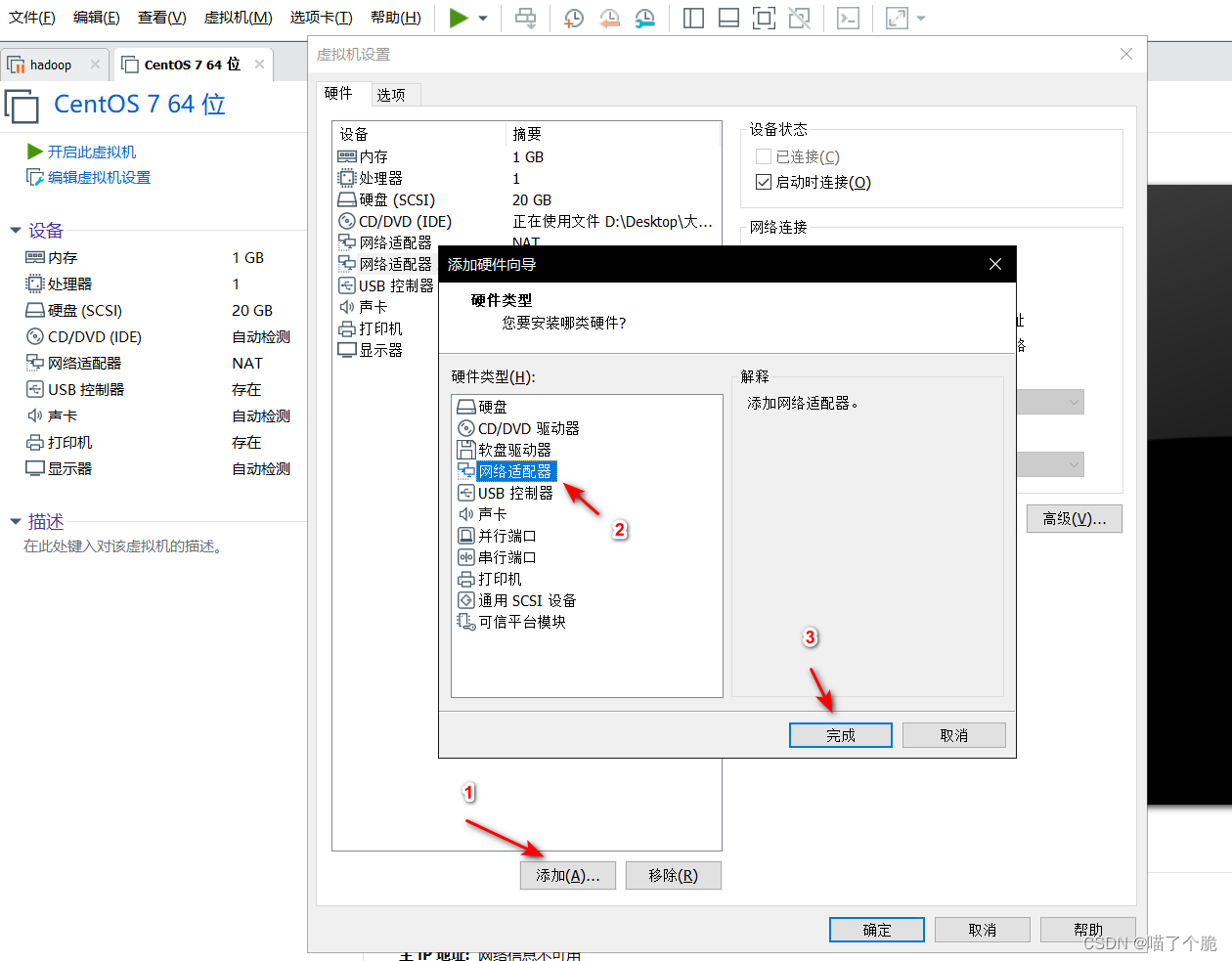
再点击添加,选择网络适配器
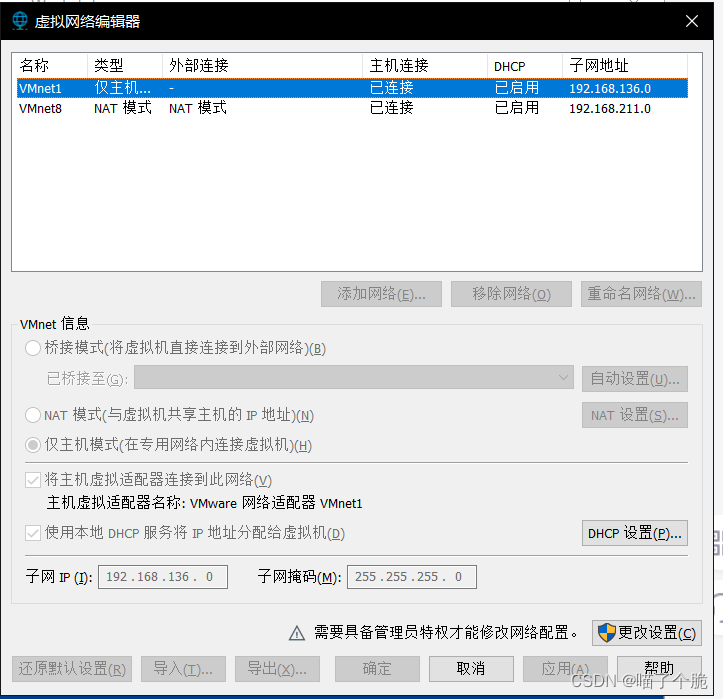
将新添加的网络适配器设置为仅主机模式

再点击编辑->虚拟网络编辑器,记住仅主机模式的网络的子网IP,后面要用
安装centOS 7
虚拟机开机,选择第一个
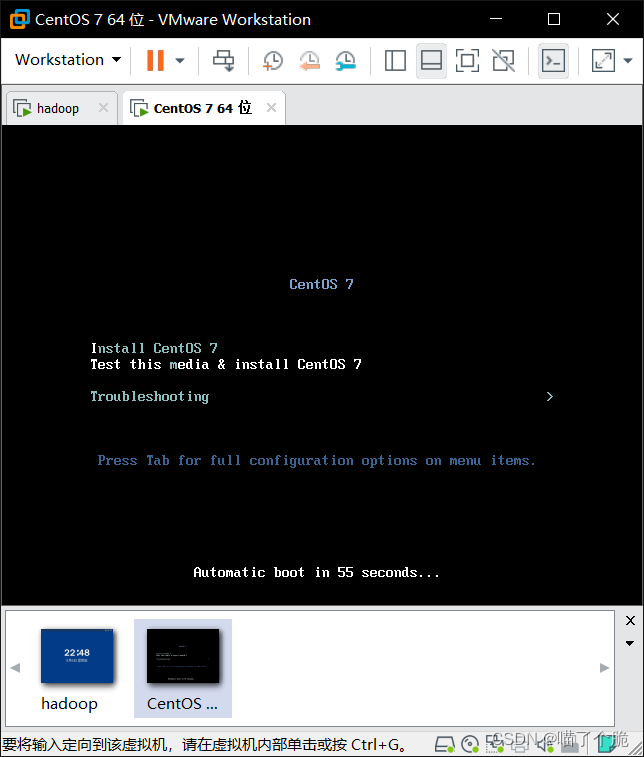
语言根据自己的喜好来,点继续
注意 这里软件选择带GUI的服务器
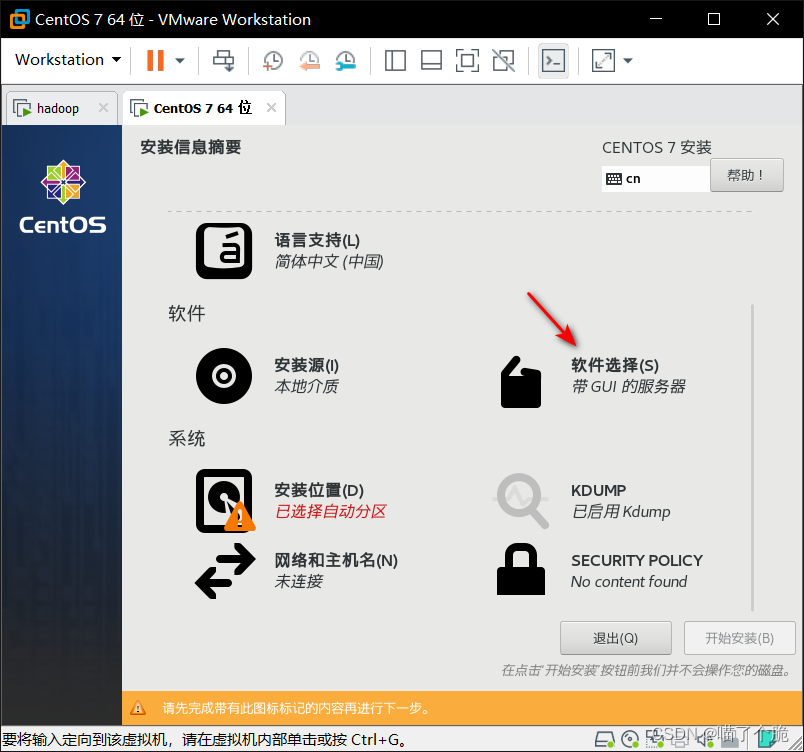
具体选择为

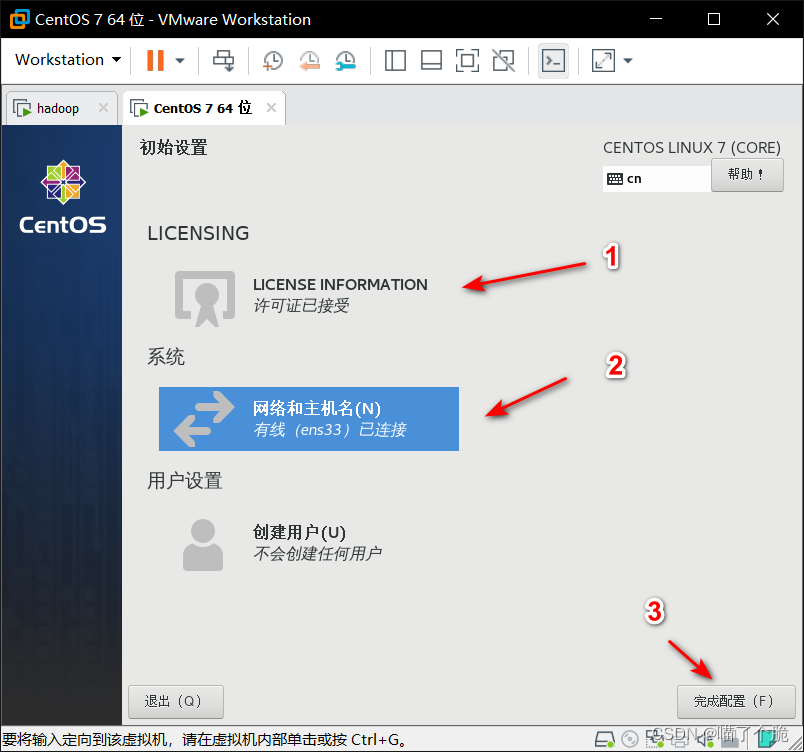
日期和时间选择亚洲上海,安装位置点进去直接确定即可,其他选项默认即可,都选择完后点击开始安装,自行设置ROOT密码,创建一个用户,等待安装完成,会比较慢,慢慢等,完成后重启,接受许可,网络和主机名中把以太网打开,点完成配置。
进入系统后点击未列出,账号为root,密码为你设置的密码
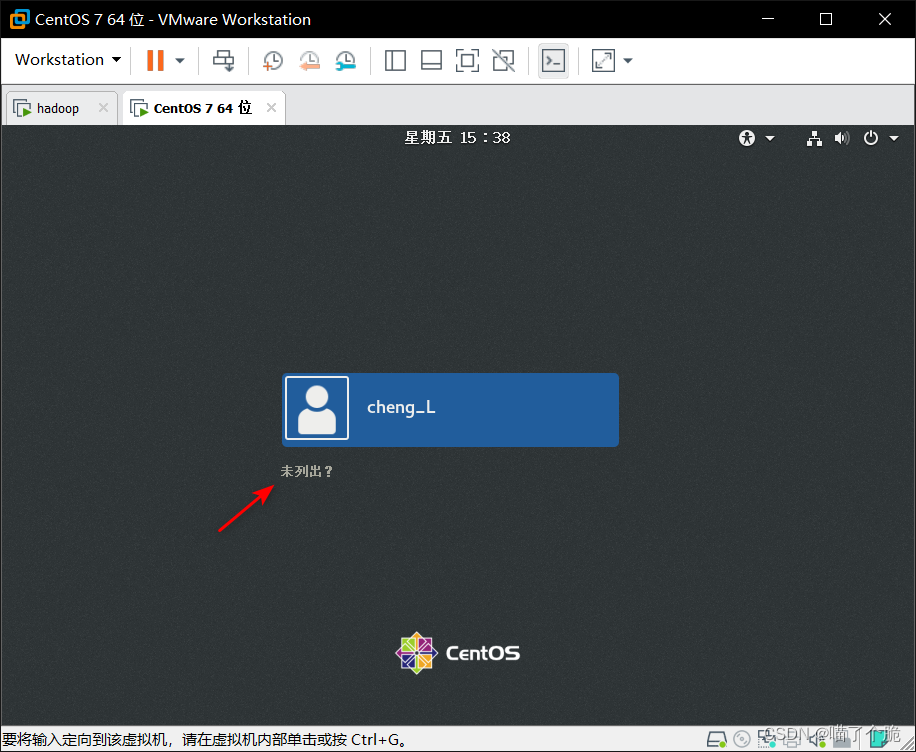
有一些默认配置,一路向前即可,成功进入系统
centOS 7虚拟机配置
配置网络
点击主文件夹,选择其他位置,找到并打开 etc->sysconfig->network-scripts 文件夹,修改其中的
ifcfg-ens33,ifcfg-ens34文件
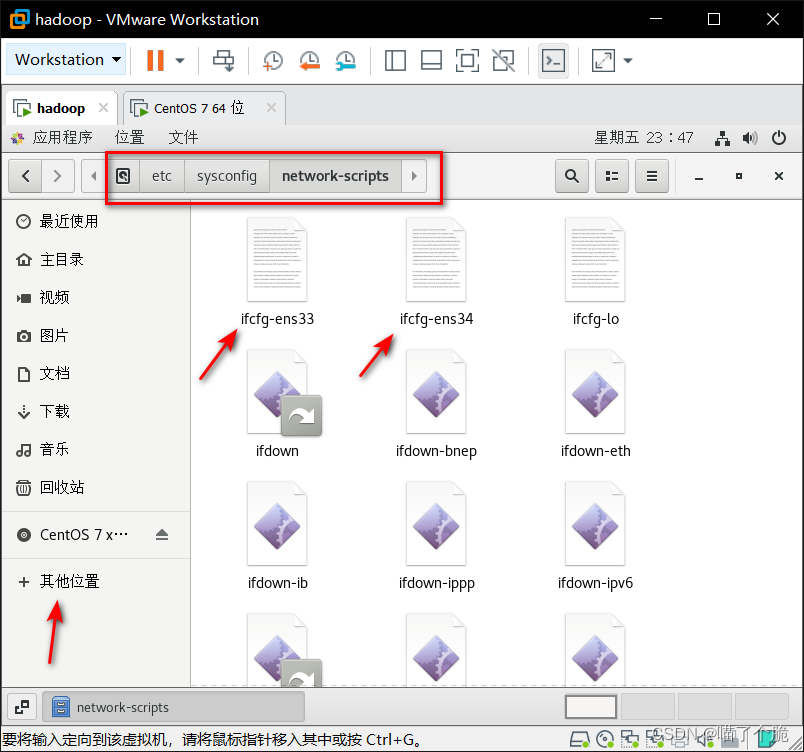
ifcfg-ens33如下修改
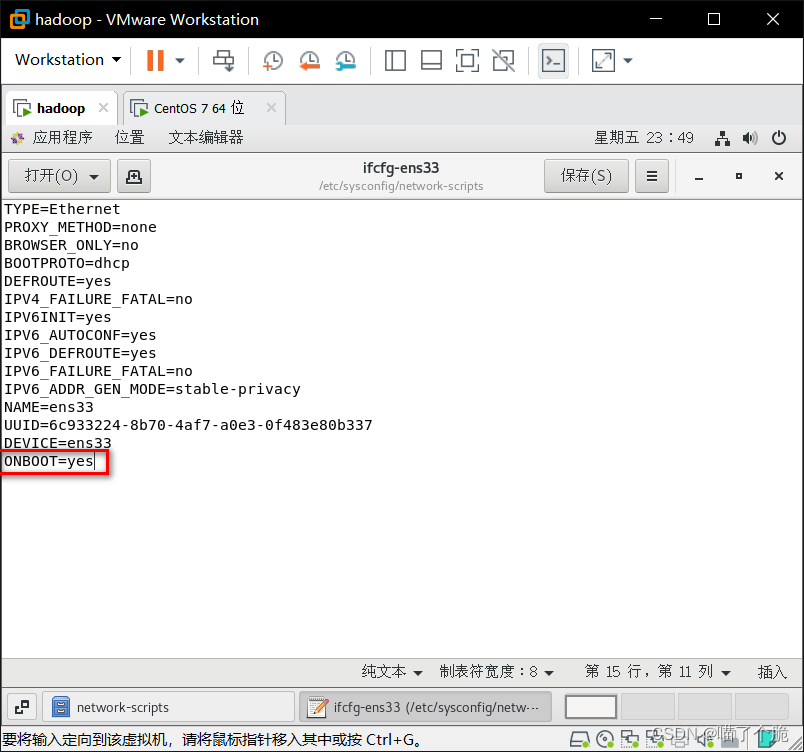
ifcfg-ens34如下修改,这里的IPADDR就是之前记下的子网IP,最后的101是我随便设置的,可以修改,只要不是1就行,这个就是虚拟机的IP地址

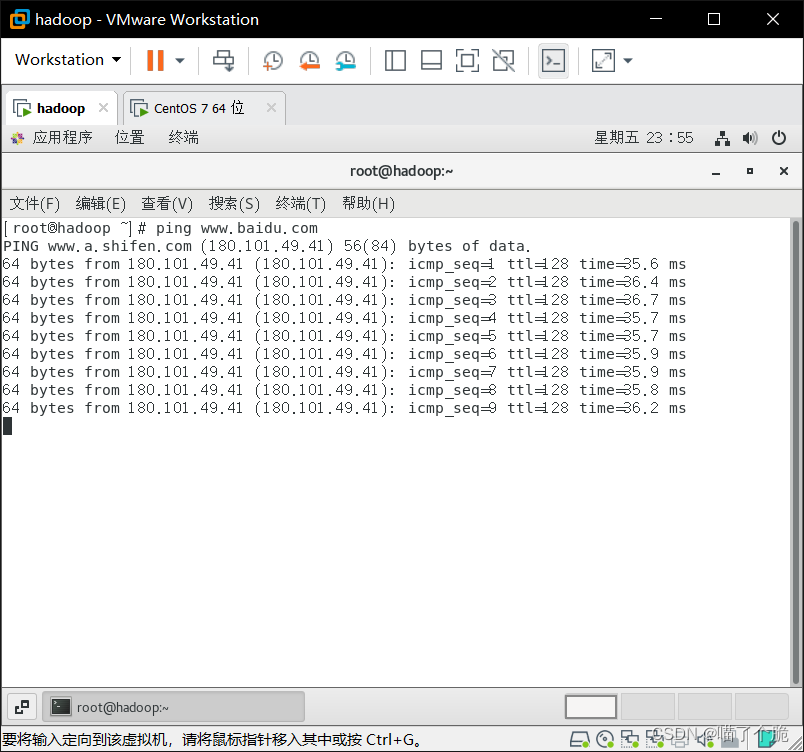
打开终端输入systemctl restart network重启网络,输入ping www.baidu.com测试外网连接,能收到百度发回来的报文就是成功了
关闭防火墙
打开终端输入
systemctl stop firewalld (关闭)systemctl disable firewalld (禁用)
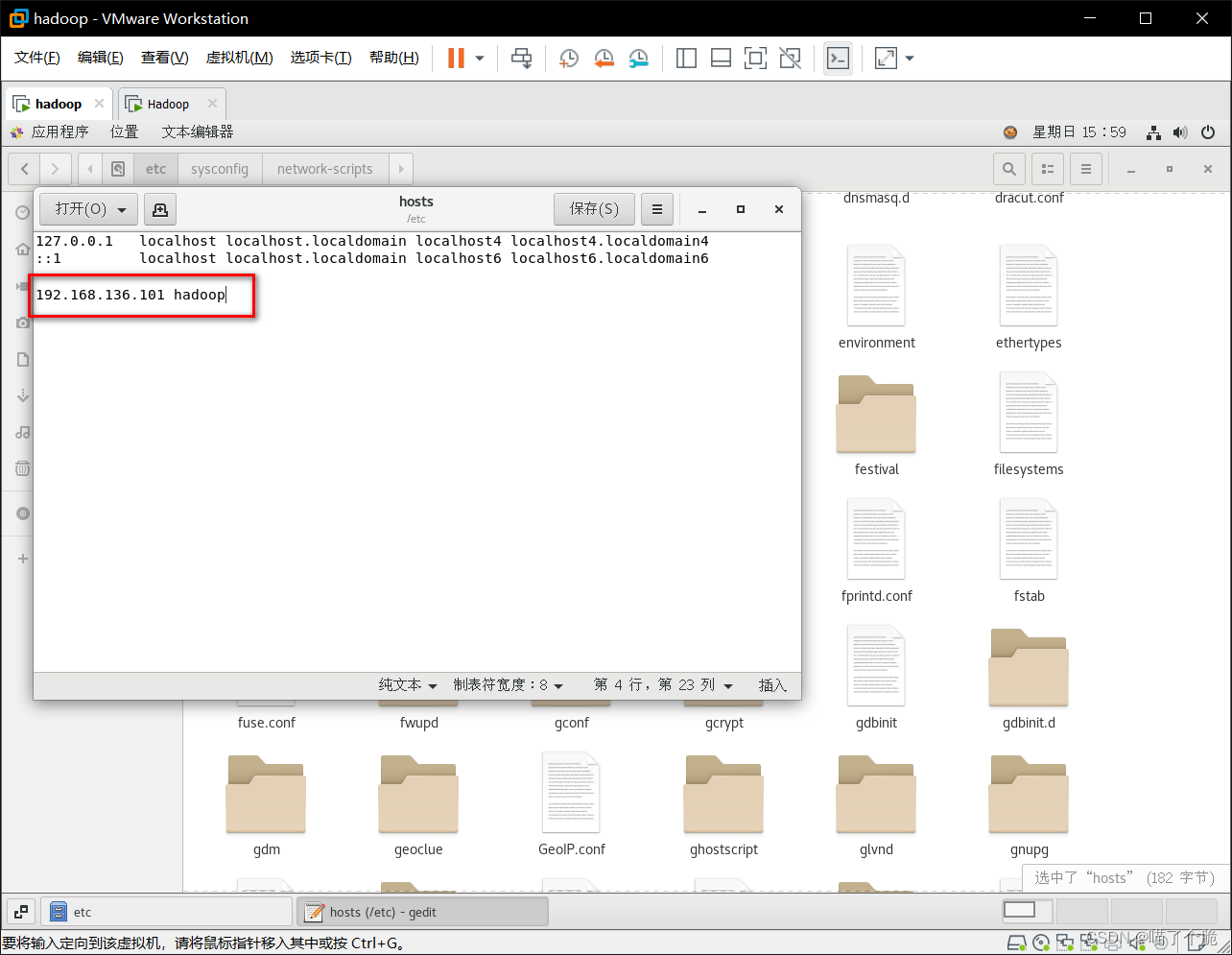
配置host
etc->hosts,在最后加上
给机器改个名(非必要)
etc->hostname文件,画圈的位置改成你想要的名字,重启生效。

设置免密登录
打开终端,输入下面代码一路回车
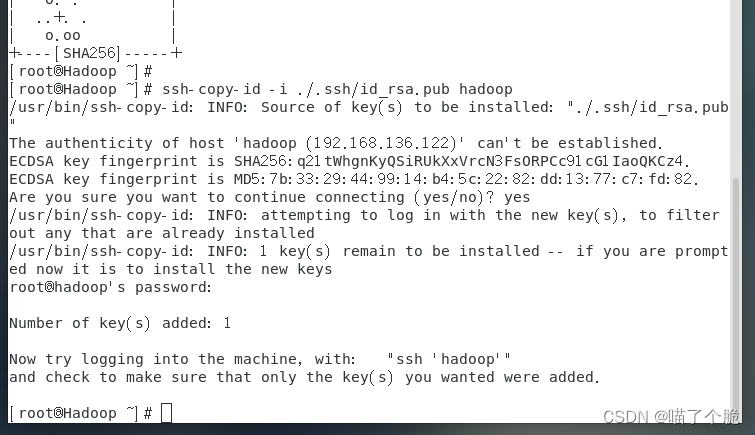
ssh-keygen -t rsa完成后再执行
ssh-copy-id -i ./.ssh/id_rsa.pub hadoop 选择yes,然后输入root账户的密码,会输出如下结果
安装软件
安装vim
yum install -y vim安装lrzsz
yum install -y lrzsz安装Xshell
安装
百度即可,安装简单
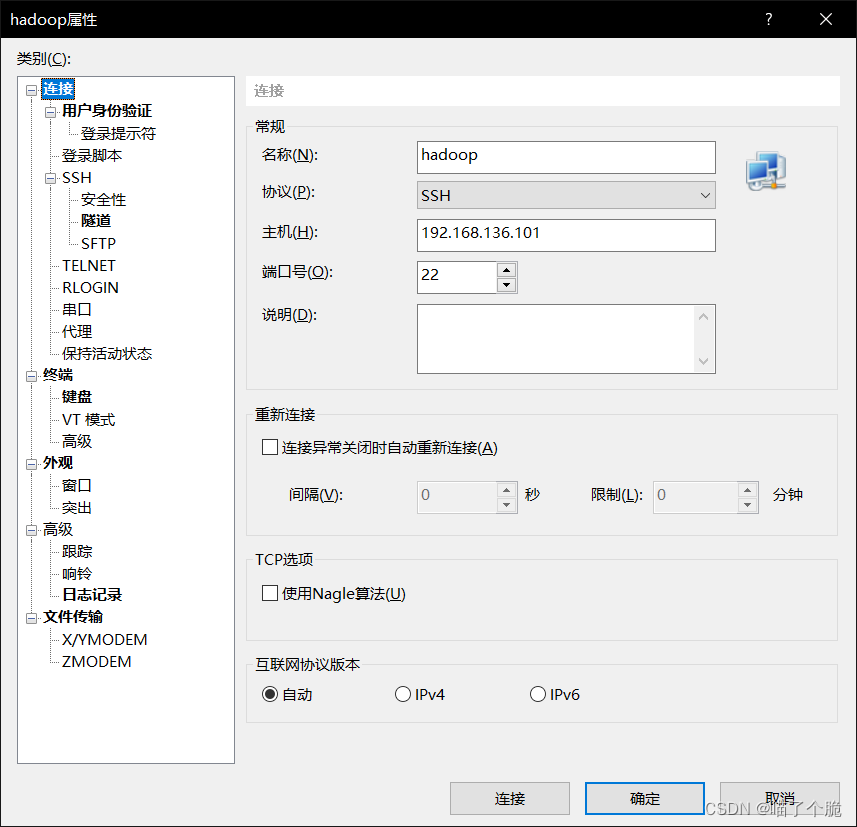
配置
点击新建,名称:任意;主机:填入虚拟机ip ;端口号:默认22
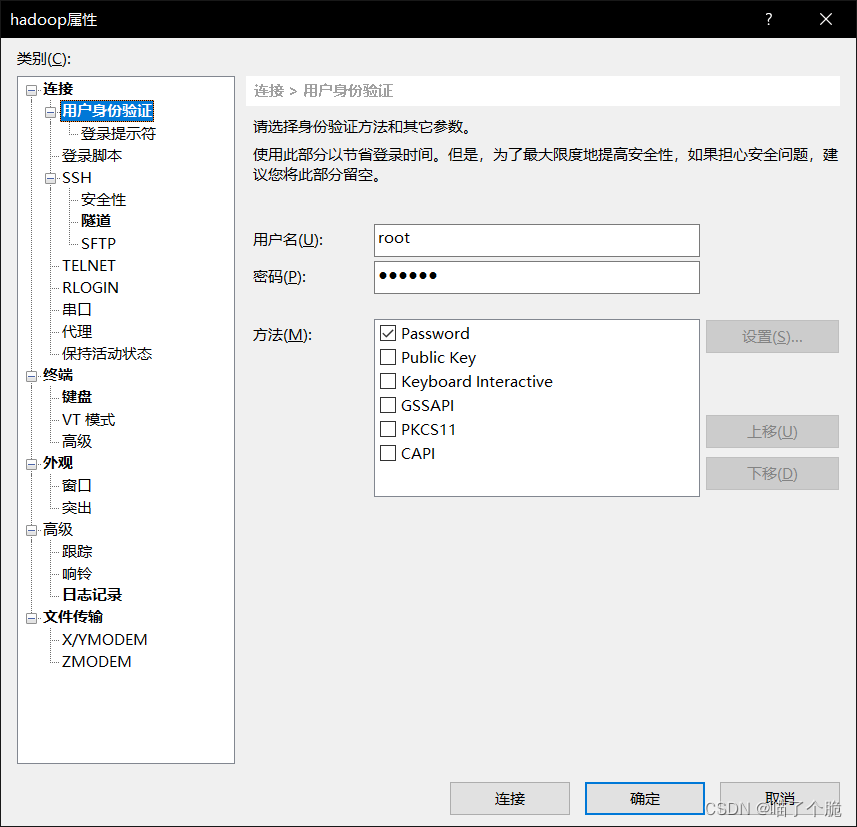
用户身份验证填写root 和123456,也就是账号和密码
完成后点击连接,这样就是成功了
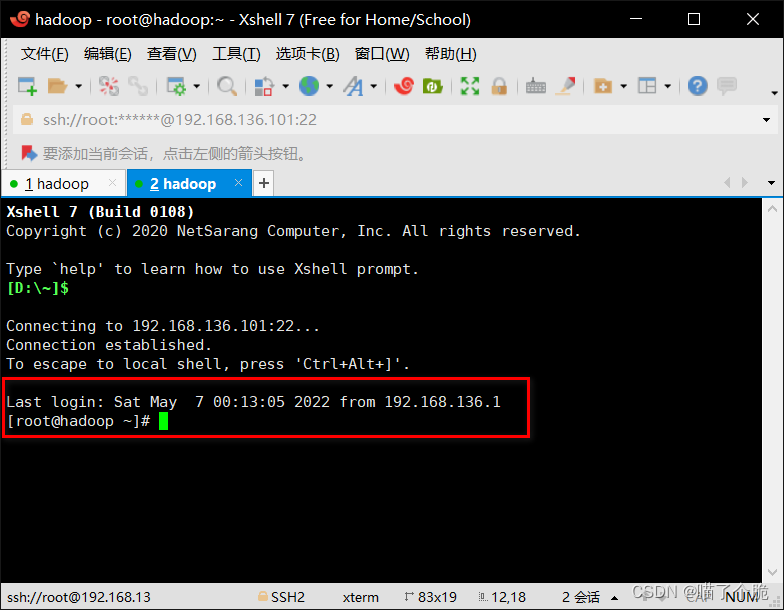
安装jdk(要java 8)
安装
(除以下方法,也可通过将安装包上传到虚拟机进行安装)
//查看当前JDK版本
java -version
如果版本不对,重新安装(卸载方式自行百度)
//安装JDK1.8
yum install -y java-1.8.0-openjdk-devel.x86_64配置环境变量
JDK默认安装路径/usr/lib/jvm,在/etc/profile文件添加如下命令
//这里的java_home内容根据你自己的版本来,可能会不一样
export JAVA_HOME=/usr/lib/jvm/java-1.8.0.322.x86_64
export JRE_HOME=$JAVA_HOME/jre
export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
export PATH=$JAVA_HOME/bin:$PATH更新环境变量,桌面打开终端,输入
source /etc/profile检测java 环境是否配置成功,有输出代表成功了,此处注意,如果命令行输入javac不能识别命令也需要重新安装 ,否则后面会出错。
[root@hadoop ~]# java -version
openjdk version "1.8.0_322"
OpenJDK Runtime Environment (build 1.8.0_322-b06)
OpenJDK 64-Bit Server VM (build 25.322-b06, mixed mode)安装Hadoop并配置环境(所有环境配置重启后生效)
下载hadoop安装包
注意下载Binary(二进制)文件
Apache Hadoophttps://hadoop.apache.org/releases.html
上传文件
下载好之后是一个后缀为 .tar.gz 的文件,需要将这个文件上传到虚拟机内,具体方法为共享文件
设置共享文件夹
在计算机本地任意一个位置创建文件夹,作为共享文件夹,回到虚拟机中,虚拟机安装好VMware Tools,找到设置

选择选项->共享文件夹->总是启用->添加,选择刚才那个文件夹。

在虚拟机中,共享文件夹位置为mnt->hgfs,只需要将文件拖进这个文件夹就可以实现共享。
共享文件夹不生效方法
登录root用户执行命令
vmhgfs-fuse .host:/ /mnt/hgfs解压Hadoop文件
先把hadoop文件拖拽到想要的文件夹,在当前文件夹点击鼠标右键,选择在终端打开,输入下面代码解压hadoop文件
tar zxvf hadoop-3.3.2.tar.gz//没有指定路径,解压的文件就在当前文件夹配置环境变量
etc->profile
export HADOOP_HOME=/usr/local/hadoop-3.3.2
export PATH=$HADOOP_HOME/bin:$PATH 更新环境变量
source /etc/profile Hadoop配置
配置hadoop-env.sh
usr-> local->hadoop3.3.2->etc->hadoop,找到hadoop-env.sh文件,修改

配置hdfs.site.xml
同目录下找到hdfs-site.xml文件,修改
dfs.namenode.name.dir
file:/home/hadoop/hadoop_data/dfs/name
dfs.datanode.data.dir
file:/home/hadoop/hadoop_data/dfs/data
dfs.replication
1
#下面是说明,非代码
dfs.replication # 为文件保存副本的数量
dfs.namenode.name.dir # 为hadoop namenode 数据目录
dfs.datanode.data.dir # 为hadoop datanode 数据目录
配置core-site
同目录下找到core-site.xml文件,修改
hadoop.tmp.dir file:/home/hadoop/hadoop_data
fs.default.name
hdfs://hadoop:9000
#下面是说明,非代码
hadoop.tmp.dir # hadoop 缓存目录,更改为自己的目录(不存在需创建)
fs.defaultFS # hadoop fs 监听端口配置同目录下找到mapred-site.xml文件,先复制一份再修改
mapreduce.framework.name yarn 同目录下找到yarn.site.xml 文件,修改
yarn.nodemanager.aux-services
mapreduce_shuffle
检测Hadoop安装是否成功
修改完配置后需要先重启系统,输入hadoop version,输出版本号代表配置成功
[root@hadoop ~]# hadoop version
Hadoop 3.3.2
Source code repository git@github.com:apache/hadoop.git -r 0bcb014209e219273cb6fd4152df7df713cbac61
Compiled by chao on 2022-02-21T18:39Z
Compiled with protoc 3.7.1
From source with checksum 4b40fff8bb27201ba07b6fa5651217fb
This command was run using /usr/local/hadoop-3.3.2/share/hadoop/common/hadoop-common-3.3.2.jar
[root@hadoop ~]#
Hadoop格式化和启动
格式化
cd /usr/local/hadoop-3.3.2/bin //这是你的hadoop路径下的bin文件
hdfs namenode -format会输出一大堆东西,要有这个successfully

启动
cd /usr/local/hadoop-3.2.2/sbin
./start-dfs.sh # 启动HDFS
./start-yarn.sh # 启动YARN运行 ./start-dfs.sh 可能会出现如下报错
[root@Hadoop sbin]# ./start-dfs.sh
Starting namenodes on [hadoop]
ERROR: Attempting to operate on hdfs namenode as root
ERROR: but there is no HDFS_NAMENODE_USER defined. Aborting operation.
Starting datanodes
ERROR: Attempting to operate on hdfs datanode as root
ERROR: but there is no HDFS_DATANODE_USER defined. Aborting operation.
Starting secondary namenodes [Hadoop.localdomain]
ERROR: Attempting to operate on hdfs secondarynamenode as root
ERROR: but there is no HDFS_SECONDARYNAMENODE_USER defined. Aborting operation.解决方案:在etc->profile文件中加入下列代码
export HDFS_NAMENODE_USER=root
export HDFS_DATANODE_USER=root
export HDFS_SECONDARYNAMENODE_USER=root
export YARN_RESOURCEMANAGER_USER=root
export YARN_NODEMANAGER_USER=root桌面打开终端运行下列代码更新配置
source /etc/profile查看节点
[root@hadoop sbin]# jps
3634 ResourceManager
4147 Jps
3221 DataNode
3769 NodeManager
3098 NameNodehadoop 常用命令
hdfs dfs -ls /
hdfs dfs -put
hdfs dfs -cat
hdfs dfs -mkdir
hdfs dfs -mv 移动/改名
hdfs dfs -rm
hdfs dfs -rmdir
hdfs dfs -rm -r查看Yarn 的Web 页面
http://192.168.136.101:8088使用yarn 执行任务
usr->local->hadoop-2.8.5->share->hadoop->mapreduce,在此目录下打开终端,输入下列代码
hadoop jar hadoop-mapreduce-examples-3.2.2.jar pi 3 4docker安装
获取安装docker 的脚本
curl -fsSL get.docker.com -o get-docker.sh执行安装脚本
sh get-docker.sh --mirror Aliyun启动docker
systemctl start docker MySQL安装
创建mysql容器(这里最后不带上版本号容易创建失败)
docker run -itd --name mysql-dev -p 3306:3306 -e MYSQL_ROOT_PASSWORD=123456 mysql:5.7.32查看mysql 容器
[root@hadoop ~]# docker ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
281be28dfa4a mysql:5.7.32 "docker-entrypoint.s…" About a minute ago Up About a minute 0.0.0.0:3306->3306/tcp, :::3306->3306/tcp, 33060/tcp mysql-dev本文来自互联网用户投稿,文章观点仅代表作者本人,不代表本站立场,不承担相关法律责任。如若转载,请注明出处。 如若内容造成侵权/违法违规/事实不符,请点击【内容举报】进行投诉反馈!