使用隐马尔科夫模型标记词性
文章目录
- 使用隐马尔科夫模型标记词性
- 一、数据预处理
- 二、主要方法
- 三、代码实现
- 实验结果
使用隐马尔科夫模型标记词性
一、数据预处理
读入数据集后,将语料中的单词,如:中国/ns,中的‘中国’存入矩阵v=[],‘ns’存入矩阵c=[],并输入词性矩阵cx:
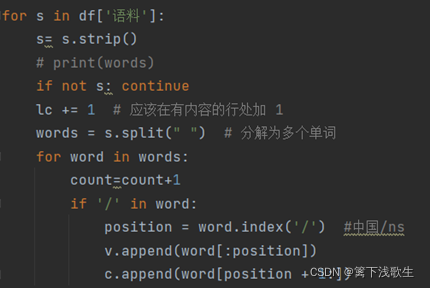
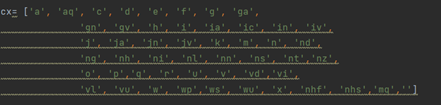
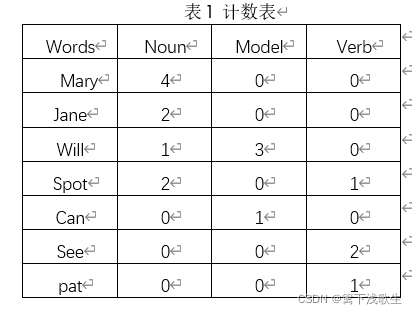
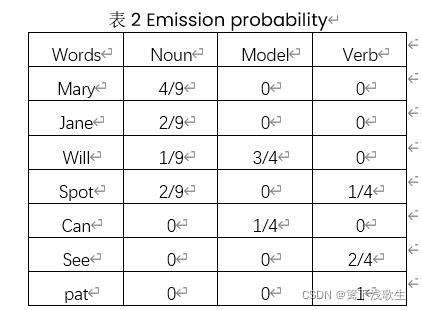
二、主要方法


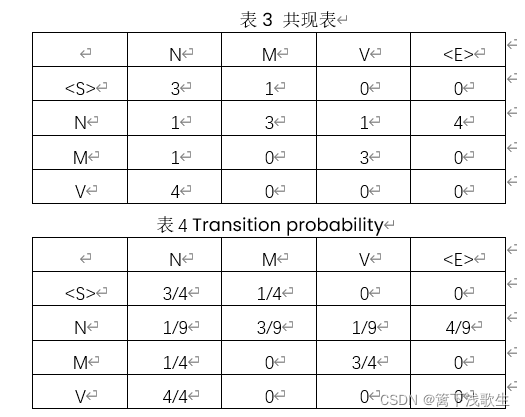


三、代码实现
数据集下载链接:https://wss1.cn/f/73kvwy7bhu6
train.py
import pandas as pdcx= ['a', 'aq', 'c', 'd', 'e', 'f', 'g', 'ga','gn', 'gv', 'h', 'i', 'ia', 'ic', 'in', 'iv','j', 'ja', 'jn', 'jv', 'k', 'm', 'n', 'nd','ng', 'nh', 'ni', 'nl', 'nn', 'ns', 'nt','nz','o', 'p','q', 'r', 'u', 'v', 'vd','vi','vl', 'vu', 'w', 'wp','ws', 'wu', 'x', 'nhf', 'nhs','mq','']df = pd.read_table("corpus_你_20211101164534.txt")
# print(df)
Count_dic = {}
sp={}#开始概率
tp={}#转移概率
ep={}#发射概率
v=[]#单词
c=[]#词性
class_count={}
count=0
lc=-1#句子总数
for state0 in cx:tp[state0]={}for state1 in cx:tp[state0][state1]=0.0ep[state0]={}sp[state0]=0.0
for state in cx:class_count[state]=0.0000000000000000000000000001for s in df['语料']:s= s.strip()# print(words)if not s: continuelc += 1 # 应该在有内容的行处加 1words = s.split(" ") # 分解为多个单词for word in words:count=count+1if '/' in word:position = word.index('/') #中国/nsv.append(word[:position])c.append(word[position + 1:])# if count==100:# break# print(c)for n in range(0, len(v)):class_count[c[n]] += 1.0if v[n] in ep[c[n]]:ep[c[n]][v[n]] += 1.0else:ep[c[n]][v[n]] = 1.0if n == 0:sp[c[n]] += 1.0else:tp[c[n - 1]][c[n]] += 1.0v = []c = []
for state in cx:sp[state]=sp[state]*1.0/lcfor li in ep[state]:ep[state][li]=ep[state][li]/class_count[state]for li in tp[state]:tp[state][li]=tp[state][li]/class_count[state]
start=open('start.txt','w',encoding='utf8')
start.write(str(sp))
transition=open('transition.txt','w',encoding='utf8')
transition.write(str(tp))
emission=open('emission.txt','w',encoding='utf8')
emission.write(str(ep))
start.close()
transition.close()
emission.close()
train.py
def viterbi(obs, states, start_p, trans_p, emit_p):path = {}V = [{}] # 记录第几次的概率for state in states:V[0][state] = start_p[state] * emit_p[state].get(obs[0], 0)path[state] = [state]for n in range(1, len(obs)):V.append({})newpath = {}for k in states:pp,pat=max([(V[n - 1][j] * trans_p[j].get(k,0) * emit_p[k].get(obs[n], 0) ,j )for j in states])V[n][k] = ppnewpath[k] = path[pat] + [k]# path[k] = path[pat] + [k]#不能提起变,,后面迭代好会用到!path=newpath(prob, state) = max([(V[len(obs) - 1][y], y) for y in states])return prob, path[state]
cx = ['a', 'aq', 'c', 'd', 'e', 'f', 'g', 'ga','gn', 'gv', 'h', 'i', 'ia', 'ic', 'in', 'iv','j', 'ja', 'jn', 'jv', 'k', 'm', 'n', 'nd','ng', 'nh', 'ni', 'nl', 'nn', 'ns', 'nt','nz','o', 'p','q', 'r', 'u', 'v', 'vd','vi','vl', 'vu', 'w', 'wp','ws', 'wu', 'x', 'nhf', 'nhs','mq','']start=open('start.txt','r')
sp=eval(start.read())
emission=open('emission.txt','r',encoding='utf8')
ep=eval(emission.read())
transition=open('transition.txt.','r',encoding='utf8')
tp=eval(transition.read())test_strs=[u"中国 政府 好 我们 应该 支持 它"]for li in range(0,len(test_strs)):test_strs[li]=test_strs[li].split()
for li in test_strs:p,out_list=viterbi(li,cx,sp,tp,ep)for i in range(0,len(li)):print(li[i],out_list[i])实验结果

本文来自互联网用户投稿,文章观点仅代表作者本人,不代表本站立场,不承担相关法律责任。如若转载,请注明出处。 如若内容造成侵权/违法违规/事实不符,请点击【内容举报】进行投诉反馈!