kmeans设置中心_数据科学实战:KMeans 广告效果聚类分析
关注上方“Python数据科学”,选择星标,
关键时间,第一时间送达!
☞500g+超全学习资源免费领取

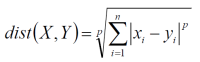 当p为1的时候是曼哈顿距离(Manhattan) 当p为2的时候是欧式距离(Euclidean) 当p为无穷大的时候是切比雪夫距离(Chebyshev)
当p为1的时候是曼哈顿距离(Manhattan) 当p为2的时候是欧式距离(Euclidean) 当p为无穷大的时候是切比雪夫距离(Chebyshev) 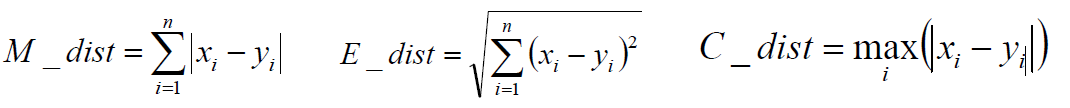 算法思想(步骤): a、选择初始化的k个类别中心a1,a2,...ak; b、计算每个样本Xi到类别中心aj的距离,设定最近的类别j c、将每个类别的中心点aj,替换为隶属该类别的所有样本的均值,作为新的质心。 d、重复上面两步操作,直到达到某个中止条件 中止条件为:组内最小平方误差MSE最小,或者达到迭代次数,或者簇中心点不再变化。
算法思想(步骤): a、选择初始化的k个类别中心a1,a2,...ak; b、计算每个样本Xi到类别中心aj的距离,设定最近的类别j c、将每个类别的中心点aj,替换为隶属该类别的所有样本的均值,作为新的质心。 d、重复上面两步操作,直到达到某个中止条件 中止条件为:组内最小平方误差MSE最小,或者达到迭代次数,或者簇中心点不再变化。 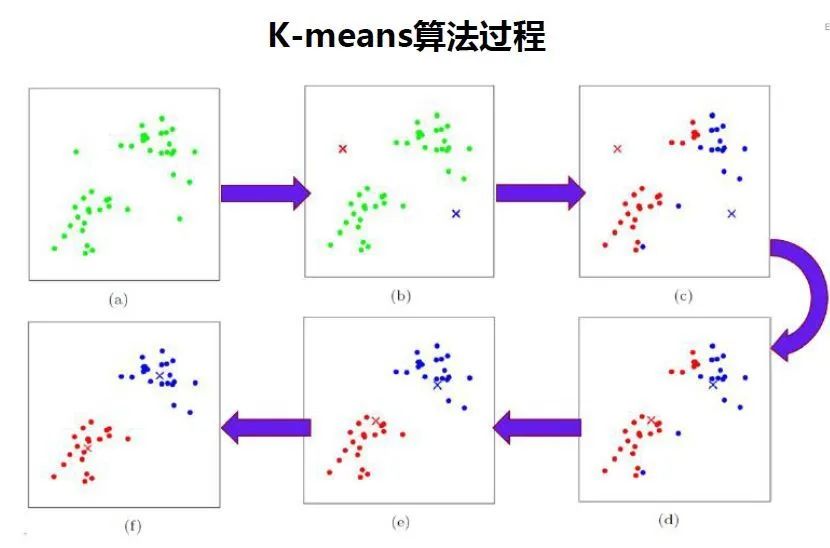 03、聚类评估——轮廓系数 如何基于最优的数据尺度确定K-Means算法中的K值? 轮廓系数的思想: 最佳的聚类类别划分从数据特征上看,类内距离最小化且类别间距离最大化,直观的理解就是“物以类聚”:同类的“聚集”“抱团”,不同类的离得远。轮廓系数通过枚举每个K计算平均轮廓系数得到最佳值。
03、聚类评估——轮廓系数 如何基于最优的数据尺度确定K-Means算法中的K值? 轮廓系数的思想: 最佳的聚类类别划分从数据特征上看,类内距离最小化且类别间距离最大化,直观的理解就是“物以类聚”:同类的“聚集”“抱团”,不同类的离得远。轮廓系数通过枚举每个K计算平均轮廓系数得到最佳值。 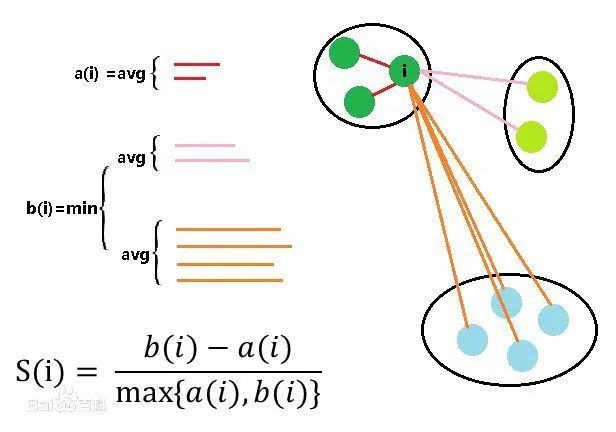 a(i) :i向量到同一簇内其他点不相似程度的平均值 b(i) :i向量到其他簇的平均不相似程度的最小值 轮廓系数的值是介于 [-1,1] ,越趋近于1代表内聚度和分离度都相对较优。 将所有点的轮廓系数求平均,就是该聚类结果总的轮廓系数。
a(i) :i向量到同一簇内其他点不相似程度的平均值 b(i) :i向量到其他簇的平均不相似程度的最小值 轮廓系数的值是介于 [-1,1] ,越趋近于1代表内聚度和分离度都相对较优。 将所有点的轮廓系数求平均,就是该聚类结果总的轮廓系数。 二、数据介绍
01 数据维度概况 除了渠道唯一标识,共12个维度,889行,有缺失值,有异常值。 02 数据13个维度介绍 1、渠道代号:渠道唯一标识 2、日均UV:每天的独立访问量 3、平均注册率=日均注册用户数/平均每日访问量 4、平均搜索量:每个访问的搜索量 5、访问深度:总页面浏览量/平均每天的访问量 6、平均停留时长=总停留时长/平均每天的访问量 7、订单转化率=总订单数量/平均每天的访客量 8、投放时间:每个广告在外投放的天数 9、素材类型:'jpg' 'swf' 'gif' 'sp' 10、广告类型:banner、tips、不确定、横幅、暂停 11、合作方式:'roi' 'cpc' 'cpm' 'cpd' 12、广告尺寸:'140*40' '308*388' '450*300' '600*90' '480*360' '960*126' '900*120' '390*270' 13、广告卖点:打折、满减、满赠、秒杀、直降、满返三、导入库,加载数据
import pandas as pdimport numpy as npimport matplotlib as mplimport matplotlib.pyplot as pltfrom sklearn.preprocessing import MinMaxScaler,OneHotEncoderfrom sklearn.metrics import silhouette_score # 导入轮廓系数指标from sklearn.cluster import KMeans # KMeans模块
%matplotlib inline## 设置属性防止中文乱码
mpl.rcParams['font.sans-serif'] = [u'SimHei']
mpl.rcParams[本文来自互联网用户投稿,文章观点仅代表作者本人,不代表本站立场,不承担相关法律责任。如若转载,请注明出处。 如若内容造成侵权/违法违规/事实不符,请点击【内容举报】进行投诉反馈!