ES查询score问题解析
ES查询score问题解析
现象
测试环境,同样的查询条件,返回的结果,命中数量相同,但是排序有变化。
现象可看用例。
{"from": 0,"size": 10,"query": {"function_score": {"query": {"bool": {"must": [{"exists": {"field": "dbName","boost": 1}},{"bool": {"should": [{"match_phrase": {"group": {"query": "XX租户","slop": 0,"zero_terms_query": "NONE","boost": 1}}},{"term": {"group": {"value": "XX租户","boost": 1}}}],"adjust_pure_negative": true,"boost": 1}},{"bool": {"should": [{"terms": {"groupId": [1,2,7,9,14,85,87,88,93,181,193,194,195,198,199,201,202,204,205,207,208,210,211,212,213,218,10007,10018,10070],"boost": 1}},{"bool": {"must_not": [{"exists": {"field": "group","boost": 1}}],"adjust_pure_negative": true,"boost": 1}},{"term": {"group": {"value": "","boost": 1}}}],"adjust_pure_negative": true,"boost": 1}}],"must_not": [{"term": {"level": {"value": "STG","boost": 1}}},{"term": {"level": {"value": "STG","boost": 1}}}],"adjust_pure_negative": true,"boost": 1}},"functions": [{"filter": {"term": {"level": {"value": "DWD","boost": 1}}},"weight": 100},{"filter": {"term": {"level": {"value": "DWS","boost": 1}}},"weight": 100}],"score_mode": "multiply","max_boost": 3.4028235e+38,"boost": 1}},"sort": [{"_score": {"order": "desc"}},{"dbName": {"order": "asc"}}],"track_total_hits": 2147483647}返回结果略,就是同样的文档打分_score不同,同时前后两次查询文档顺序可能不一样。
现象分析:
mysql肯定不会出现这样的问题,而ES相比之下是一个分布式搜索引擎。
我们是不是可以猜测
ES是以shard作为最小计算单元的的,有没有可能是shard之间的差异导致的
原因解析:
查询过程
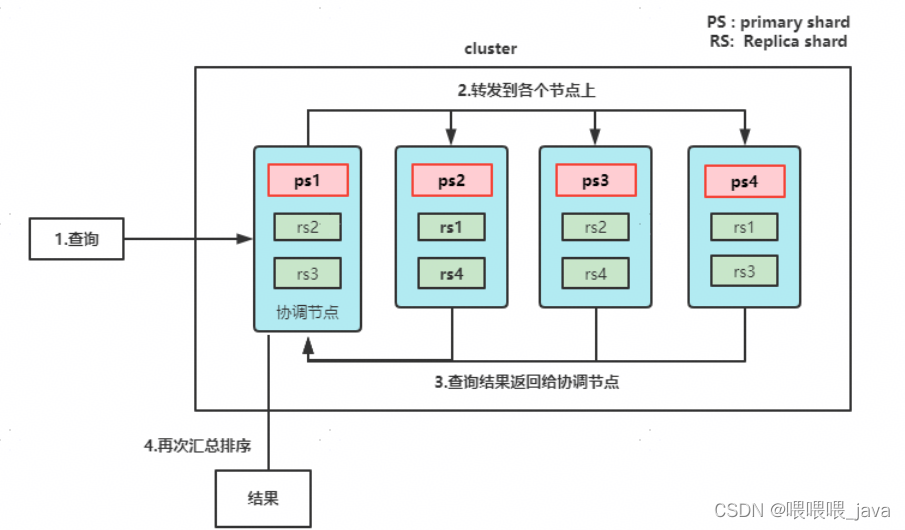
在elasticsearch搜索时,默认使用QUERY_THEN_FETCH
根据官方文档,QUERY_THEN_FETCH模式搜索步骤如下:
1.发送查询到每个shard
2.找到所有匹配的文档,当然,使用本地的TF/IDF信息进行打分
3.对结果构建一个优先队列(排序,标页等)
4.返回关于结果的足够的元数据到请求节点。注意,不包含文档内容
5.来自所有shard的数据合并起来,并在请求节点上按进行排序,获得要求的分页和数量的文档
最终,实际文档从他们各自所在的独立的shard上检索出来(此时包含文档内容)
本地的TF/IDF信息
每一个shard都是一个Lucene实例,Lucene使用TF/IDF计算相关度算法。而每个Lucene实例只保存了自身的TF和IDF统计信息,所以一个shard只知道term(词条)在其自身中出现的次数,而非整个cluster
TF: Term Frequency的缩写,表示该term在当前document出现的频率
IDF: Inverse Document Frequency缩写,表示该term在所有文档中出现的频率
从TF/IDF算法可以看出,该term在当前文档出现次数越高,那么分值越大;如果该term在所有文档出现的频率越小,那么分值越大。这样term分数,不仅和此篇命中的文档有关,还和该shard的文档数量、文档内容量有关
ES主副shard
es会随机(负载均衡)访问主副分片。
官方文档中,提到分片中存在标记为已删除的文档,这些文档只有在下一次旧文档所属的段合并时才会从磁盘中删除。但是出于实际原因,这些已删除的文档会被考虑用于索引统计。因此,假设主分片刚刚完成了一个大型合并,删除了大量已删除的文档,那么它可能具有与副本(仍有大量已删除文档)完全不同的索引统计信息,因此分数也不同。
https://www.elastic.co/guide/en/elasticsearch/reference/current/consistent-scoring.html
结论1:
不同分片之间计算score的算法是以每个shard本地存储的TF/IDF信息计算出来的,而本地存储的TF/IDF是以该shard中的所有数据算出来的。那么会出现这样的现象,一个内容相同的doc,因为id不同被放到了不同的shard中,那么他们算出来的分数可能不一样,但不是造成两次查询排序结果不一致的原因。
Lucene根据哈希算法分配文档到不同shard,当文档数据量比较大时,哈希结果会使不同shard文档数量趋于一致,默认的方式也能取得相当理想的结果。
结论2:
主副分片中存在数据不一致(软删除数据),导致同一条查询语句,分配到不同的shard中计算出来的score不一样,最终按照score排序后,发现前后两次查询的顺序不一致。
本文来自互联网用户投稿,文章观点仅代表作者本人,不代表本站立场,不承担相关法律责任。如若转载,请注明出处。 如若内容造成侵权/违法违规/事实不符,请点击【内容举报】进行投诉反馈!