Hadoop 运行模式
文章目录
- 一、本地运行模式(官方 WordCount)
- 1.创建文件写入数据
- 2.执行程序
- 3.查看结果
- 二、完全分布式运行模式(开发重点)
- 配置JDK、Hadoop
- xsync 集群分发脚本
- 1.创建xsync
- 2.添加可执行权限
- 3.所有的hadoop都有sxync
- 4.分发环境变量
- 5.检查
- 6.让环境变量生效
- SSH 无密登录配置
- 集群配置
- 群起集群并测试
- 目录切换
- 历史服务器配置
- 配置日志的聚集
- hadoop集群启停脚本
- 查看三台服务器 Java 进程脚本:jpsall
一、本地运行模式(官方 WordCount)
1.创建文件写入数据
[atjh@hadoop102 hadoop-3.1.3]$
mkdir wcinputcd wcinputvim word.txt
hadoop yarn
hadoop mapreduce
atguigu
atguigu
2.执行程序
回到 Hadoop 目录/opt/module/hadoop-3.1.3
bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-3.1.3.jar wordcount wcinput/ ./wcoutput
3.查看结果
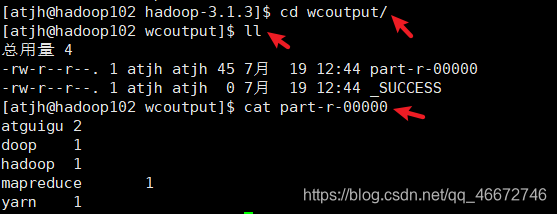
二、完全分布式运行模式(开发重点)
配置JDK、Hadoop
hadoop2上将jdk拷贝到hadoop3
opt/module目录下:
scp -r jdk1.8.0_212/ atjh@hadoop103:/opt/module/
hadoop3上拉取hadoop2上的jdk
opt/module目录下:
scp -r atjh@hadoop102:/opt/module/hadoop-3.1.3 ./
在hadoop3上将hadoop2中的jdk和hadoop拷贝到hadoop4上
scp -r atjh@hadoop102:/opt/module/* atjh@hadoop104:/opt/module/

xsync 集群分发脚本
1.创建xsync
cd /opt/cd /home/atjh/mkdir bincd binvim xsync
在该文件中编写如下代码
#!/bin/bash
#1. 判断参数个数
if [ $# -lt 1 ]
then
echo Not Enough Arguement!
exit;
fi
#2. 遍历集群所有机器
for host in hadoop102 hadoop103 hadoop104
do
echo ==================== $host ====================
#3. 遍历所有目录,挨个发送
for file in $@
do
#4. 判断文件是否存在
if [ -e KaTeX parse error: Expected 'EOF', got '#' at position 15: file ] then #̲5. 获取父目录 pdir=(cd -P $(dirname KaTeX parse error: Expected 'EOF', got '#' at position 14: file); pwd) #̲6. 获取当前文件的名称 f…(basename $file)
ssh $host “mkdir -p $pdir”
rsync -av pdir/pdir/pdir/fname host:host:host:pdir
else
echo $file does not exists!
fi
done
done
2.添加可执行权限
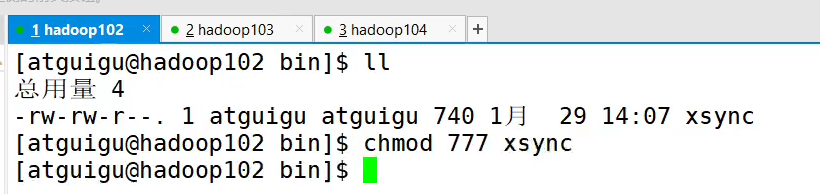
3.所有的hadoop都有sxync
xsync bin/

4.分发环境变量
sudo ./bin/xsync /etc/profile.d/my_env.sh

5.检查
sudo vim /etc/profile.d/my_env.sh

6.让环境变量生效
source /etc/profile

SSH 无密登录配置
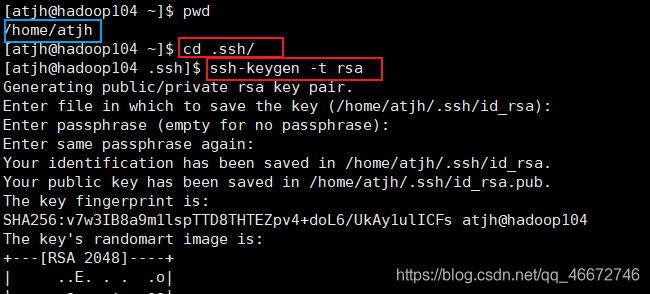
/home/atjh目录下
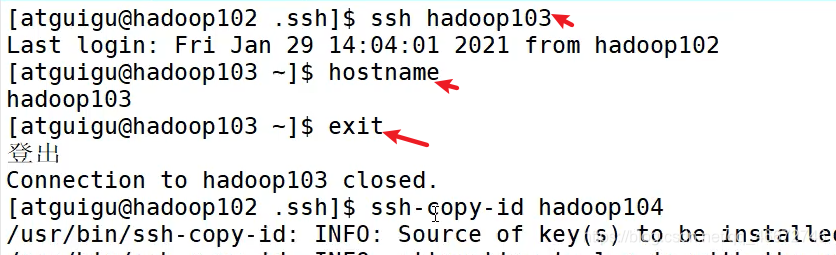
ls -alcd .ssh/ssh-keygen -t rsassh-copy-id hadoop102

检查
换用户的话需要再次配置一下(方法相同)
test一下



成功!!over
集群配置


群起集群并测试
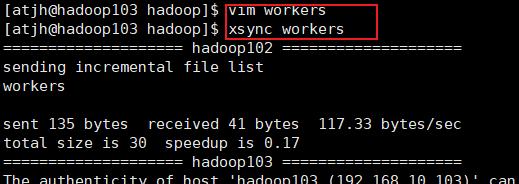
hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-3.1.3.jar wordcount /wcinput /wcoutput
目录切换
/opt/module/hadoop-3.1.3/etc/hadoop

历史服务器配置
配置 mapred-site.xml
vim mapred-site.xml
写入内容
<!-- 历史服务器端地址 -->
<property><name>mapreduce.jobhistory.address</name><value>hadoop102:10020</value>
</property>
<!-- 历史服务器 web 端地址 -->
<property><name>mapreduce.jobhistory.webapp.address</name><value>hadoop102:19888</value>
</property>
分发配置
xsync mapred-site.xml
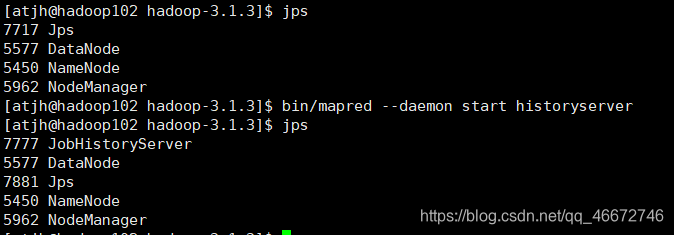
启动历史服务器
bin/mapred --daemon start historyserver
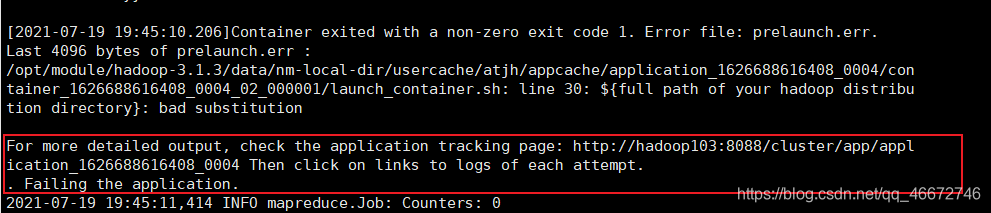
hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-3.1.3.jar wordcount /input /output

小bug
配置日志的聚集
xsync $HADOOP_HOME/etc/hadoop/yarn_site.xml
sbin/stop-yarn.shmapred --daemon stop historyserver
hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-3.1.3.jar wordcount /input /output
hadoop集群启停脚本
基本命令
myhadoop.sh stopmyhadoop.sh start
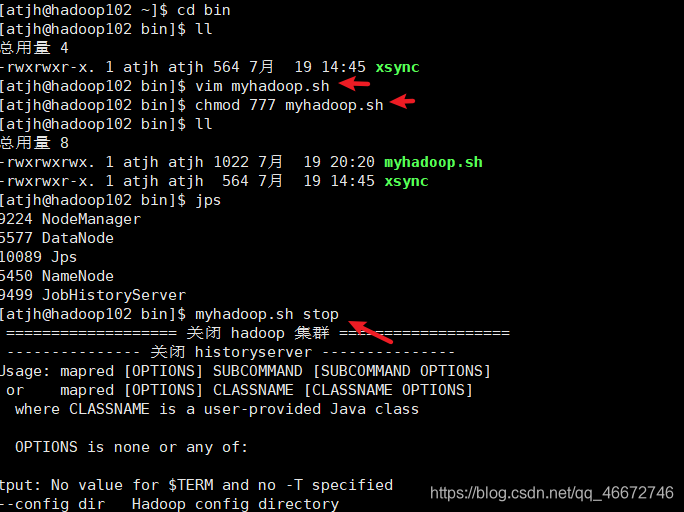
#!/bin/bash
if [ $# -lt 1 ]
thenecho "No Args Input..."exit ;
fi
case $1 in
"start")echo " =================== 启动 hadoop 集群 ==================="echo " --------------- 启动 hdfs ---------------"ssh hadoop102 "/opt/module/hadoop-3.1.3/sbin/start-dfs.sh"echo " --------------- 启动 yarn ---------------"ssh hadoop103 "/opt/module/hadoop-3.1.3/sbin/start-yarn.sh"echo " --------------- 启动 historyserver ---------------"ssh hadoop102 "/opt/module/hadoop-3.1.3/bin/mapred --daemon start
historyserver"
;;
"stop")echo " =================== 关闭 hadoop 集群 ==================="echo " --------------- 关闭 historyserver ---------------"ssh hadoop102 "/opt/module/hadoop-3.1.3/bin/mapred --daemon stop
historyserver"echo " --------------- 关闭 yarn ---------------"ssh hadoop103 "/opt/module/hadoop-3.1.3/sbin/stop-yarn.sh"echo " --------------- 关闭 hdfs ---------------"ssh hadoop102 "/opt/module/hadoop-3.1.3/sbin/stop-dfs.sh"
;;
*)echo "Input Args Error..."
;;
esac
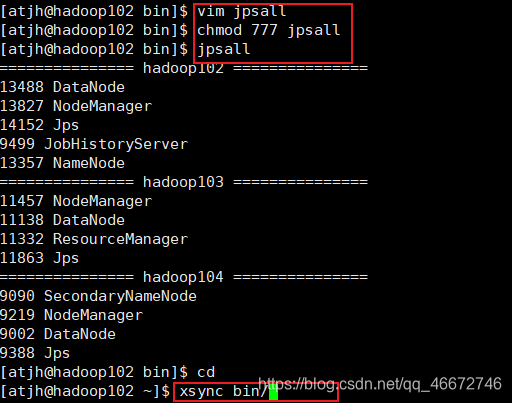
查看三台服务器 Java 进程脚本:jpsall
本文来自互联网用户投稿,文章观点仅代表作者本人,不代表本站立场,不承担相关法律责任。如若转载,请注明出处。 如若内容造成侵权/违法违规/事实不符,请点击【内容举报】进行投诉反馈!