No Fine-Tuning, Only Prefix-Tuning
说起fine-tuning,大家再熟悉不过了,NLP和CV领域基本都是各种预训练模型了。
使用预训练模型最重要的一步就是fine-tuning,因为下游任务是多种多样的,所以每种下游任务都要有个副本,并且finetune会改变所有的参数。这篇论文

问题定义
生成式任务就是给个上下文x,然后输出一个序列的tokens.这篇论文就聚焦两个任务,一个是table-to-text,x就是一个表格的数据,y就是文本描述.在总结任务中,x就是一篇文章,y就是一小段总结。


假设我们有自回归模型GPT(transformer的结构,12层),让z = [x;y],聚合x和y,Xidx是x的索引,Yidx是y的索引,hi(j)是transformer第j步的输出,hi = [hi(1),...,hi(n)],生成hi的输入是zi和h hi用来计算下一个token的概率分布: p(zi+1 | h <=i) = softmax(Whi(n)) 还有一种生成式架构是encoder-decoder,就是BART,大家也很熟不赘述,同GPT比就是BART的encoder是双向的,decoder是单向的。如下图所示: prefix-tuning在生成式任务中可以替代fine-tuning,方法就是在自回归模型前加个prefix,z=[PREFIX;x;y]或者再encoder和decoder前都加prefix,z=[PREFIX;x;PREFIX';y],如问题描述中的图所示。Pidx表示prefix中的索引,hi由下式所示: 这里我们固定GPT的参数,只会训练prefix中的参数,很明显,对于非prefix的token,都会依赖prefix的hi。论文中提到,直接更新prefix的参数会导致优化的不稳定,因此会在prefix上加个mlp的映射: 参考文献: No Fine-Tuning, Only Prefix-Tuning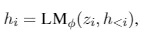


Prefix-Tuning
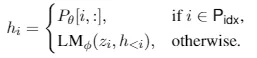
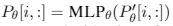
本文来自互联网用户投稿,文章观点仅代表作者本人,不代表本站立场,不承担相关法律责任。如若转载,请注明出处。 如若内容造成侵权/违法违规/事实不符,请点击【内容举报】进行投诉反馈!