搜索算法相似度问题之BM25
在实践中,无论是搜索问题,还是文本问题,如何找到相似的文本都是一个常见的场景,但TFIDF文本相似度计算用多了,年轻人往往会不记得曾经的经典。
毕业快4年了,最近准备梳理一下《我毕业这4年》,在整理文档时看到了好久之前的一个比赛,想起了当时TFIDF、BERT的方案都没在指标上赢过BM25的情景,本期我们来聊一聊相似文本搜索的相关知识点。

BM25是信息索引领域用来计算Query与文档相似度得分的经典算法,不同于TFIDF,BM25的公式主要由三个部分组成:
- 对Query进行语素解析,生成语素qi;
- 对于每个搜索结果D,计算每个语素qi与D的相关性得分;
- 将qi相对于D的相关性得分进行加权求和,从而得到Query与D的相关性得分。
公式如下:
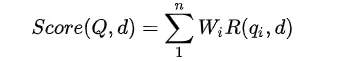
其中,Q表示Query,qi表示Q解析之后的一个语素,d表示一个搜索结果文档,Wi表示语速qi的权重,R(qi,d)表示语素qi与文档d的相关性得分。

class BM25:def __init__(self, corpus, tokenizer=None):self.corpus_size = len(corpus)self.avgdl = 0self.doc_freqs = []self.idf = {}self.doc_len = []self.tokenizer = tokenizerif tokenizer:corpus = self._tokenize_corpus(corpus)nd = self._initialize(corpus)self._calc_idf(nd)def _initialize(self, corpus):nd = {} # word -> number of documents with wordnum_doc = 0for document in corpus:self.doc_len.append(len(document))num_doc += len(document)frequencies = {}for word in document:if word not in frequencies:frequencies[word] = 0frequencies[word] += 1self.doc_freqs.append(frequencies)for word, freq in frequencies.items():try:nd[word]+=1except KeyError:nd[word] = 1self.avgdl = num_doc / self.corpus_sizereturn nddef _tokenize_corpus(self, corpus):pool = Pool(cpu_count())tokenized_corpus = pool.map(self.tokenizer, corpus)return tokenized_corpusdef _calc_idf(self, nd):raise NotImplementedError()def get_scores(self, query):raise NotImplementedError()def get_batch_scores(self, query, doc_ids):raise NotImplementedError()def get_top_n(self, query, documents, n=5):assert self.corpus_size == len(documents), "The documents given don't match the index corpus!"scores = self.get_scores(query)top_n = np.argsort(scores)[::-1][:n]return [documents[i] for i in top_n]
在这里,用自己之前写过的一个真实案例,来介绍一下。任务提供一个论文库(约含20万篇论文),同时提供对论文的描述段落,来自论文中对同类研究的介绍。任务需要为描述段落匹配三篇最相关的论文。
1.2 任务描述
本次比赛将提供一个论文库(约含20万篇论文),同时提供对论文的描述段落,来自论文中对同类研究的介绍。参赛选手需要为描述段落匹配三篇最相关的论文。
例子:
描述段落:
An efficient implementation based on BERT [1] and graph neural network (GNN) [2] is introduced.
相关论文:
[1] BERT: Pre-training of deep bidirectional transformers for language understanding.
[2] Relational inductive biases, deep learning, and graph networks.
1.3 评测方案
准确率(Precision): 提交结果的准确性通过 Mean Average Precision @ 3 (MAP@3) 打分,具体公式如下:
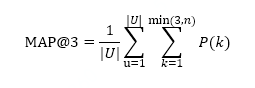
其中,|U|是需要预测的press_id总个数,P(k)是在k处的精度,n是paper个数。
2 题意分析
从任务描述中我们可以看到,该任务需要对描述段落匹配三篇最相关的论文。单从形式上可以理解为这是一个“完形填空”任务。但相较于在本文的相应位置上填上相应的词语不同的是,这里需要填充的是一个Sentence,也就是论文的题目。但是如果你按照这个思路去寻求解决方案,你会发现在这个量级的文本数据上,一般算力是满足不了的。
既然如此,那我们不如换一个思路来思考这个问题,“对描述段落匹配三篇最相关的论文”,其实最简单的实现方式是计算描述段落和论文库里所有论文的相似度,找出最相似的即可。但这同样会存在一个问题,通过对数据进行探查你会发现“An efficient implementation based on BERT [1] and graph neural network (GNN) [2] is introduced.”这一描述段落,同时引用了两篇文章,那么在计算相似度时,到底哪个位置该是哪篇文章呢?
基于分析中提到的问题和难点,本次比赛给出了以下解决方案。
3 建模核心思路
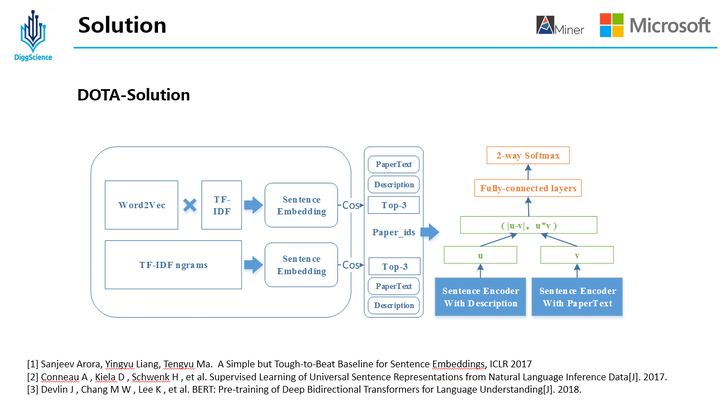
在解决本问题时,使用了两种方式,其一是利用Wrod2Vec方法,将描述段落利用Word2Vec得到每个词的词向量,同时对句子中的词使用IDF为权重进行加权得到Sentence Embedding,同时为了得到更好的效果,这里做了一个改进,即使用Smooth Inverse Frequency代替IDF作为每个词的权重;其二是利用BM25得到Sentence Embedding。两种方法各自计算余弦相似度得到3篇论文,去重后召回集中每个段落有3-6篇不等的召回论文。
在排序阶段,我们利用Bi-LSTM对描述段落Description和论文文本PaperText组成句子对(Description,PaperText)进行编码,在中间层对两个向量进行差值和内积操作后,在输出层经过Dense和Softmax层后得到概率值后排序。
4 算法核心思想
4.1 SIF Sentence Embedding

SIF Sentence Embedding 使用预训练好的词向量,使用加权平均的方法,对句子中所有词对应的词向量进行计算,得到整个句子的embedding向量。
SIF 的计算分为两步:
1) 对句子中的每个词向量,乘以一个独特的权重b,权重b是一个常数 a除以a与该词频率的和,这种做法的会对出现频率高词进行降权,也就是说出现频次越高,其权重也就越小;
2) 计算句向量矩阵的第一主成分u,让每个Sentence Embedding减去它在u上的投影,具体参见论文[2];
这里,利用该方法做召回,在验证集上的准确性要比其他两种方式效果好。
(1)对句子中所有单词求平均得到sentence embedding;
(2)对句子中所有单词利用IDF值加权后求平均得到sentence embedding。
4.2 InferSent
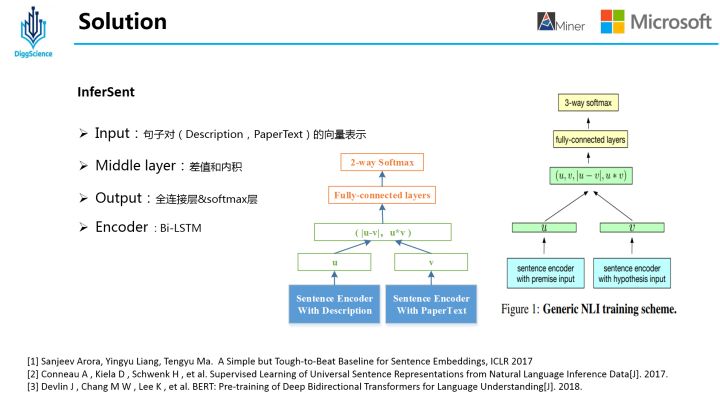
InferSent相似度模型是Facebook提出了一种通过不同的encoder得到Sentence Embedding,然后计算两个Sentence Embedding的差值、点乘得到交互向量,计算两者之间的相似度。
这里,对原始论文方法做了两处修改:
其一是针对这个问题对3-way softmax层(entailment,contradiction,neutral)做了相应的修改变为2-way softmax;
其二是中间层去掉了u和v,只使用差值和内积两种特征表征方式;
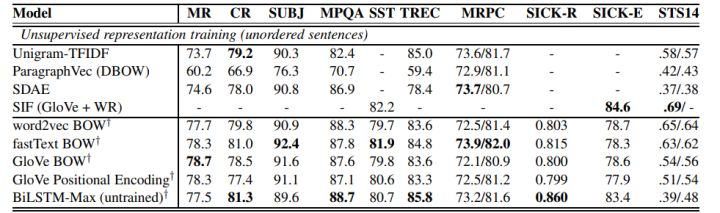
同时在7中编码器:1)LSTM, 2)GRU, 3)bi-GRU, 4)bi-LSTM(mean pooling), 5)bi-LSTM(max pooling), 6)self-attention, 7)CNN 中选用了Bi-LSTM MaxPooling的方式。
4.3 Others-BERT
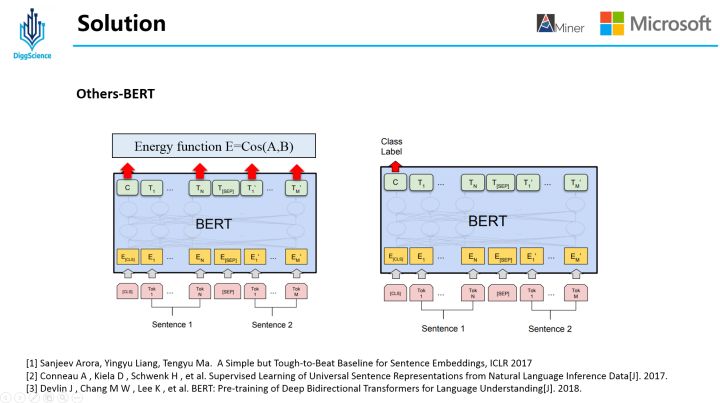
当时,在BERT时代,解决方案的尝试中少不了它的身影,这里我们用BERT尝试了两种方案,其一是利用BERT对Description和PaperText进行编码后,计算文本的余弦相似度;其二是在上述整体模型中,用BERT替换InferSent部分。
参考文献:
[1] Sanjeev Arora, Yingyu Liang, Tengyu Ma. A Simple but Tough-to-Beat Baseline for Sentence Embeddings, ICLR 2017
[2] Conneau A , Kiela D , Schwenk H , et al. Supervised Learning of Universal Sentence Representations from Natural Language Inference Data[J]. 2017.
[3] Devlin J , Chang M W , Lee K , et al. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding[J]. 2018.
本文来自互联网用户投稿,文章观点仅代表作者本人,不代表本站立场,不承担相关法律责任。如若转载,请注明出处。 如若内容造成侵权/违法违规/事实不符,请点击【内容举报】进行投诉反馈!