就知道调bert,都不知道加个对比学习吗?
说到句向量,大家除了第一反应是用bert的CLS作为句向量,还有就是用word2vec学到每个词的向量,然后把句子中所有的词向量做pooling作为句子的向量。有篇论文SimCSE提到可以引入对比学习。
先回顾下对比学习,对比学习的目标无非就是让相似的数据点离的更近,疏远不相关的。假设有一系列pair对:
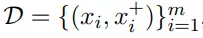
Xi和Xi+是语意相关的,然后可以使用in-batch内负样本配合交叉熵损失。整个学习目标可以用下式表达:
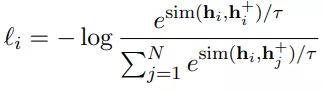
T控制温度,sim是cos相似度,h是bert或者RoBERTa输出的句向量。在对比学习最重要的就是如何构建(Xi,Xi+)对,在图像领域就是各种裁剪,旋转等操作。NLP中就很难有这种操作。
无监督SimCSE
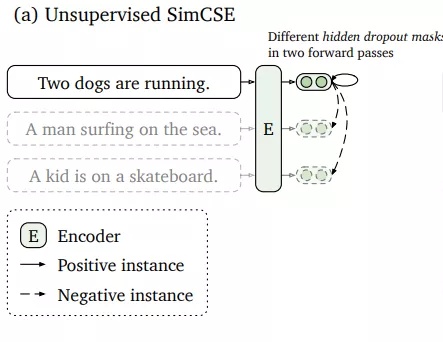
取一个集合的句子{xi}i=1~m,让xi+= xi。两个一样的正例,怎么能work? loss都是0了。重点就是用独立采样的dropout mask。标准的bert中,dropout的mask都是在全连接层上的。现在我们简单的把同样的输入放到encoder两次,通过两种不同的dropout masks z和z'(transformer中标准的dropout mask),然后得到两个embeddings,训练目标就变成了下式:
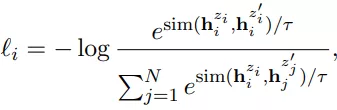
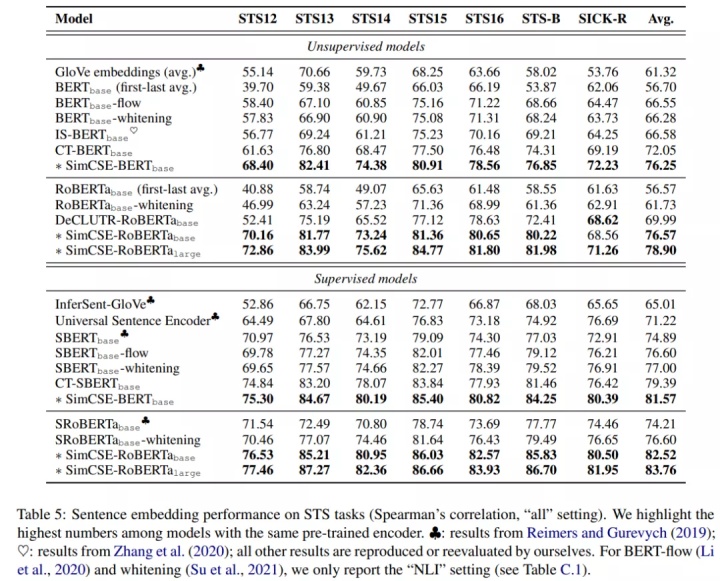
无监督SimCSE和其他方法对比,效果也是最好的:
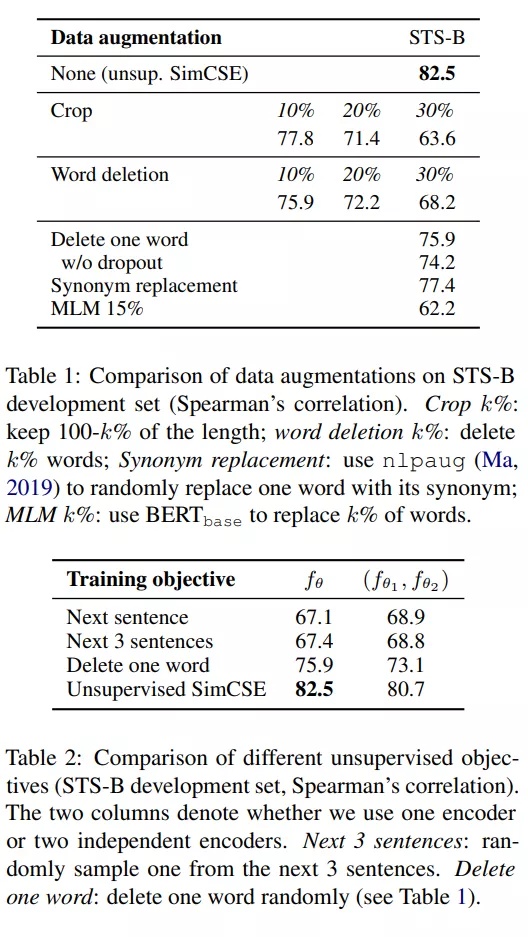
有监督的SimCSE
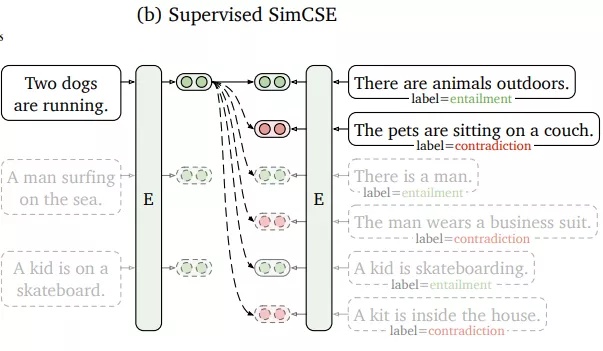
充分利用NLI(自然语言推理)数据集中的相互冲突的句子作为强负例。在NLI数据集,给定一个前提,注释者需要手动编写一个绝对正确(蕴涵)、一个可能正确(中立)和一个绝对错误(矛盾)的句子。所以样本从(Xi,Xi+)扩展成了(Xi,Xi+,Xi-),训练目标变成了下式:
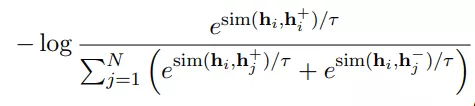
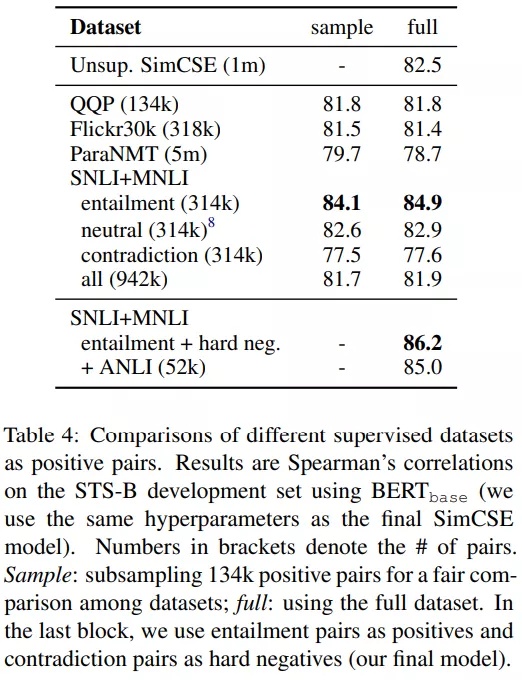
从结果上看,可以显著提升效果。论文还尝试了混合unsupervised SimCSE,发现没有任何帮助。使用双重encoder的框架也会降低效果。
实验
论文在STS任务比较了无监督和有监督SimCSE和之前句向量的方法,结果如下图所示:
参考文献
就知道调bert,都不知道加个对比学习吗?
本文来自互联网用户投稿,文章观点仅代表作者本人,不代表本站立场,不承担相关法律责任。如若转载,请注明出处。 如若内容造成侵权/违法违规/事实不符,请点击【内容举报】进行投诉反馈!