双塔模型没效果了?请加大加粗!
很多研究表明,双塔在一个域表现不错,在其他域表现不好了。一个广泛被认同的观点就是双塔仅仅用了最后一层的点积算分,这限制了模型的召回能力。这篇论文

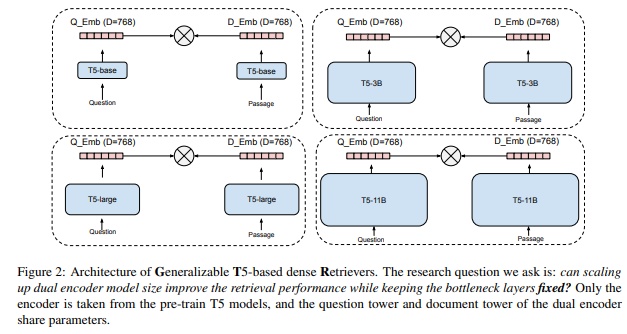
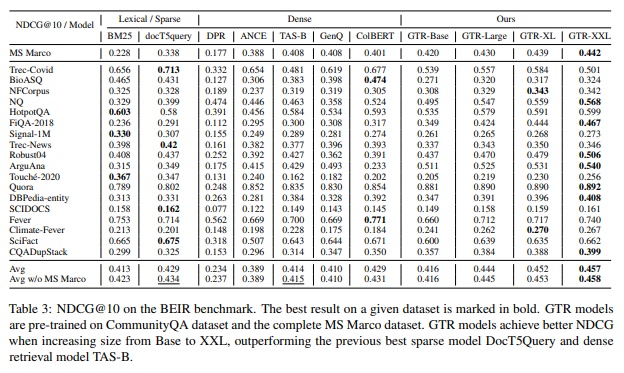
在query和document的召回任务中,他们分别被encode到同一空间中,然后使用近邻检索给query高效的找到对应document。很多论文都表示,点积(或是cos相似度)不能够有效抓住语意相关性,这篇论文并不赞同。值得注意的是,扩展双塔网络的capacity和预训练模型(像是bert)的扩展不同,因为有瓶颈层(用于点积的那层)的存在。提升encoder的capacity却不能改变点积限制了query和document交互信息的现实。为了验证这个假设,该文使用了T5模型,使得encoders可以有50亿的参数,并固定顶层为768维度如下图所示。最后评估了GTR在BEIR benchmark上zero shot的效果,在9个域和18个召回任务的表现是让人吃惊的。

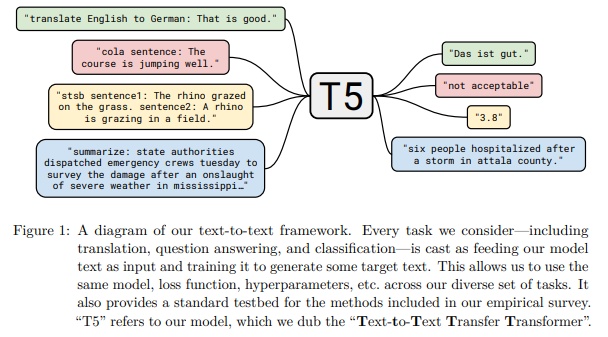
T5模型算是大力出奇迹的典范了,靠着统一框架和所有NLP任务都转换成Text-to-Text任务,同样的模型,同样的loss,同样的训练,同样的编码解码,完成了所有的NLP任务。
本文用的T5的预训练模型,直接把模型capacity从百万提升到亿,模型架构如下所示:
编码query和passage用的是encoder的mean pooling,并固定输出是768维度。loss使用的是batch内负采样,使用sampled softmax loss:
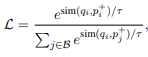
还可以补充一些负例,如下式所示:
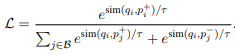
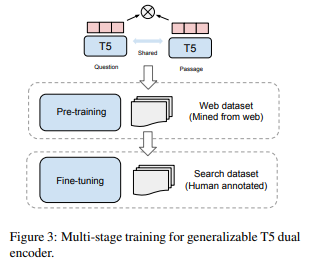
整个训练过程包含预训练步骤和fine-tuning步骤,web-mined语料库提供了很多半结构化的数据对(像是对话,问答),可以提供丰富的语意相关信息。还有些搜索数据集,往往是人工标注的,虽然质量高但是收集成本高。这篇论文使用T5模型的encoder进行初始化,并在从互联网收集的问答pair对上进行训练,然后在SentEval和Sentence Textual Similarity任务上进行评估。


- 1.Large Dual Encoders Are Generalizable Retrievers https://arxiv.org/pdf/2112.07899.pdf
- 2.Exploring the limits of transfer learning with a unified textto-text transforme r https://arxiv.org/pdf/1910.10683.pdf
本文来自互联网用户投稿,文章观点仅代表作者本人,不代表本站立场,不承担相关法律责任。如若转载,请注明出处。 如若内容造成侵权/违法违规/事实不符,请点击【内容举报】进行投诉反馈!