Python爬取a站视频弹幕
Python爬取a站视频弹幕
- 单页爬取分析
- 翻页分析
- 编写爬虫代码
- 导库
- 表头设置
- 获取所有视频的videoId以及视频名称
- 获取弹幕列表
- 写入本地
- main方法
- 完整代码
- 运行效果
单页爬取分析
以这个为例子https://www.acfun.cn/bangumi/aa5024874_36188_327049
首先,我们按F12进入控制台
然后按Ctrl+F,查找我们在视频中看到的弹幕以图中为例,我们查找“乌乌乌乌乌”的位置,由此我们找到了弹幕在网址中的位置,我们用xpath匹配一下弹幕,可以发现,

我们只匹配到了28条弹幕,明显这并不是网页的所有弹幕,所有有可能弹幕是动态加载出来的,我们点击控制台中的Network,然后继续按Ctrl+F查找弹幕的位置,比如查找“三表人才”,

我们可以看到,我们所要查找的弹幕在下面这个网址里面出现过
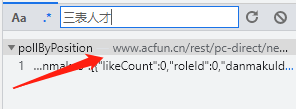
我们点击网址,观察发现,他是以post方式请求的,

我们拉到最后查看它的传入的data参数,
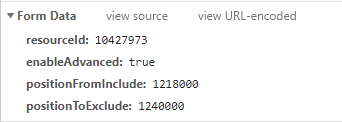
接着,我们多点开几个弹幕网址,分析他的data参数规律,
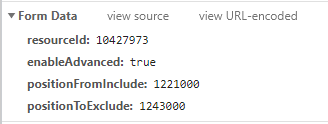
发现,同个视频的resourceId是不变的,enableAdvanced也是固定的,所以接下来我们分析另外两个参数,
我们将positionFromInclude设为0,positionToExclude设为1000000,然后发起请求,观察,

我们发现positionToExclude并不等于我们所设的1000000而是30000,所以我们有证据怀疑它的positionFromInclude和positionToExclude是以30000的倍数递增的,我们再将positionFromInclude设为30000,positionToExclude设为60000,
观察发现,确实如我们所料,由此我们掌握了爬取弹幕的开始条件,接着我们来分析一下爬取弹幕的结束条件,我们将positionFromInclude和positionToExclude设一个较大值来观察,

我们发现它的“addCount”返回0,所以我们可以将这个设为我们的结束条件。
接着,我们点开“danmakus”可以发现里面正是我们要爬取的弹幕,我们点开其中一条弹幕来观察,

发现里面有我们要爬取的弹幕的各种信息。
到此,我们分析完了单页的爬取要点。
翻页分析
在单页分析中我们知道它的resourceId是不变的,我们点开下一个视频观察它的弹幕网址,发现它的resourceId跟上一个视频不一致,所以我们将resourceId定为我们的翻页条件,下面我们分析如何找到所有视频的resourceId。
首先,我们在视频网址中右击点击查看网页源代码,接着按Ctrl+F查找我们第二个视频的resourceId即10427974,因为我们想要的是在第一个找到下一个视频乃至所有视频的相关信息

发现刚好有我们想要的,可以发现他代表的是videoId的值,在这里想要匹配出所有的videoId,用xpath并不方便,所以用re来匹配

可以发现,它正好有我们想要的所有翻页条件,我们顺便可以匹配出所有的视频名称作为我们后续保存数据的文件名,

至此,我们已经有爬取整一部视频的所有条件了。
编写爬虫代码
编译器这里采用的是anaconda的Spyder,因为他能实时看到并保存变量的值,非常有利与爬虫调试。
导库
import re
import csv
import json
import requests
from fake_useragent import UserAgent
表头设置
def getHeaders():# 这里调用了fake_useragent里面的UserAgent类,可以随机获取User-Agentuser_agent = UserAgent()ua = user_agent.Firefox # 模拟火狐浏览器headers = {"User-Agent":ua}return headers
获取所有视频的videoId以及视频名称
def getVid(): # 设置重试次数start_url = 'https://www.acfun.cn/bangumi/aa5024874_36188_327049'retry_count = 5while retry_count > 0:try:res = requests.get(start_url, headers = getHeaders(), timeout=10)text = res.textpat_vid = '"videoId":(\d{8})'vids = re.findall(pat_vid, text, re.S)[1:]pat_title = ',"episodeName":"(.*?)","'titles = re.findall(pat_title, text)[1:]return zip(titles,vids)except:retry_count -= 1return None
获取弹幕列表
def getHtmlJson(vid, pos):danmu_url = 'https://www.acfun.cn/rest/pc-direct/new-danmaku/pollByPosition'data = {'resourceId': vid,'enableAdvanced': 'true','positionFromInclude': str(pos * 30000),'positionToExclude': str((pos+1) * 30000)}retry_count = 5while retry_count > 0:try:res = requests.post(danmu_url, data=data, headers = getHeaders())text = res.texthtml_json = json.loads(text)return html_jsonexcept:retry_count -= 1print(".",end='')return None
写入本地
def writeCSV(path, danmu):danmakuId = danmu['danmakuId']userId = danmu['userId']body = ",".join(danmu['body'].split(",")) # 将英文逗号换为中文逗号,方便后续分析color = danmu['color']rank = danmu['rank']isLike = danmu['isLike']likeCount = danmu['likeCount']createTime = danmu['createTime']info = [danmakuId, userId, body, color, rank, isLike, likeCount, createTime]with open(path, 'a+', newline='', encoding='utf-8') as csvfile:writer = csv.writer(csvfile)writer.writerow(info)return None
main方法
if __name__ == '__main__':csvheader=['弹幕id','用户id','弹幕','颜色','rank','isLike','likeCount','创建时间']for title,vid in getVid():path = 'G:\\桌面文件\\爬取a站弹幕\\{}.csv'.format("_".join(title.split(" ")))with open(path, 'a+', newline='', encoding='utf-8') as csvfile:writer = csv.writer(csvfile)writer.writerow(csvheader)print("正在爬取{}的弹幕".format("_".join(title.split(" "))))pos = 0num = 0while True:html_json = getHtmlJson(vid, pos)pos += 1if html_json['addCount'] == 0:breakelse:for danmu in html_json['danmakus']:writeCSV(path, danmu)num += 1# 每爬1000条弹幕输出一个*if num % 1000 == 0:print("*",end='')print()
完整代码
# -*- coding: utf-8 -*-
"""
Created on Sun Jun 27 17:51:16 2021@author: feng
"""
import re
import csv
import json
import requests
from fake_useragent import UserAgentstart_url = 'https://www.acfun.cn/bangumi/aa5024874_36188_327049'def getHeaders():user_agent = UserAgent()ua = user_agent.Firefoxheaders = {"User-Agent":ua}return headersdef getVid(): retry_count = 5while retry_count > 0:try:res = requests.get(start_url, headers = getHeaders(), timeout=10)text = res.textpat_vid = '"videoId":(\d{8})'vids = re.findall(pat_vid, text, re.S)[1:]pat_title = ',"episodeName":"(.*?)","'titles = re.findall(pat_title, text)[1:]return zip(titles,vids)except Exception as e:print(e)retry_count -= 1return Nonedef getHtmlJson(vid, pos):danmu_url = 'https://www.acfun.cn/rest/pc-direct/new-danmaku/pollByPosition'data = {'resourceId': vid,'enableAdvanced': 'true','positionFromInclude': str(pos * 30000),'positionToExclude': str((pos+1) * 30000)}retry_count = 5while retry_count > 0:try:res = requests.post(danmu_url, data=data, headers = getHeaders())text = res.texthtml_json = json.loads(text)return html_jsonexcept:retry_count -= 1print(".",end='')return Nonedef writeCSV(path, danmu):danmakuId = danmu['danmakuId']userId = danmu['userId']body = ",".join(danmu['body'].split(",")) # 将英文逗号换为中文逗号,方便后续分析color = danmu['color']rank = danmu['rank']isLike = danmu['isLike']likeCount = danmu['likeCount']createTime = danmu['createTime']info = [danmakuId, userId, body, color, rank, isLike, likeCount, createTime]with open(path, 'a+', newline='', encoding='utf-8') as csvfile:writer = csv.writer(csvfile)writer.writerow(info)return Noneif __name__ == '__main__':csvheader=['弹幕id','用户id','弹幕','颜色','rank','isLike','likeCount','创建时间']for title,vid in getVid():path = 'G:\\桌面文件\\爬取a站弹幕\\{}.csv'.format("_".join(title.split(" ")))with open(path, 'a+', newline='', encoding='utf-8') as csvfile:writer = csv.writer(csvfile)writer.writerow(csvheader)print("正在爬取{}的弹幕".format("_".join(title.split(" "))))pos = 0num = 0while True:html_json = getHtmlJson(vid, pos)pos += 1if html_json['addCount'] == 0:breakelse:for danmu in html_json['danmakus']:writeCSV(path, danmu)num += 1if num % 1000 == 0:print("*",end='')print()
运行效果



如果想用excel查看数据的话,需要建立空白excel表格重新导入,不然可能会乱码之类的。

本文来自互联网用户投稿,文章观点仅代表作者本人,不代表本站立场,不承担相关法律责任。如若转载,请注明出处。 如若内容造成侵权/违法违规/事实不符,请点击【内容举报】进行投诉反馈!