[常规赛] 视杯视盘分割 (GAMMA挑战赛任务三) - 10月第2名方案
1 比赛介绍
GAMMA挑战赛是由百度在MICCAI2021研讨会OMIA8上举办的国际眼科赛事。MICCAI是由国际医学图像计算和计算机辅助干预协会 (Medical Image Computing and Computer Assisted Intervention Society) 举办的跨医学影像计算和计算机辅助介入两个领域的综合性学术会议,是该领域的顶级会议。OMIA是百度在MICCAI会议上组织的眼科医学影像分析 (Ophthalmic Medical Image Analysis) 研讨会,至今已举办八届。`
本常规赛为GAMMA挑战赛任务三
赛题背景:
青光眼是一种慢性神经退行性疾病,是世界上不可逆转但可预防的失明的主要原因之一。青光眼有许多变种,其特征是视神经盘受损,通常由高眼压引起。眼压升高是由于眼内房水异常积累的结果,是由眼排水系统的病理性缺陷引起的。当前段被这种液体饱和时,眼压逐渐升高,将玻璃体压向视网膜。如果这种情况继续不受控制,就会对神经纤维层、脉管系统和视神经盘造成损害,导致进行性和不可逆转的视力丧失,最终导致失明。
比赛地址:https://aistudio.baidu.com/aistudio/competition/detail/121/0/introduction
2 赛题说明
本任务的目的是将2D眼底图像中的视盘和视杯区域分割出来。
分割结果中视盘区域像素值置为128,视杯区域像素值置为0,其他区域像素值置为255。
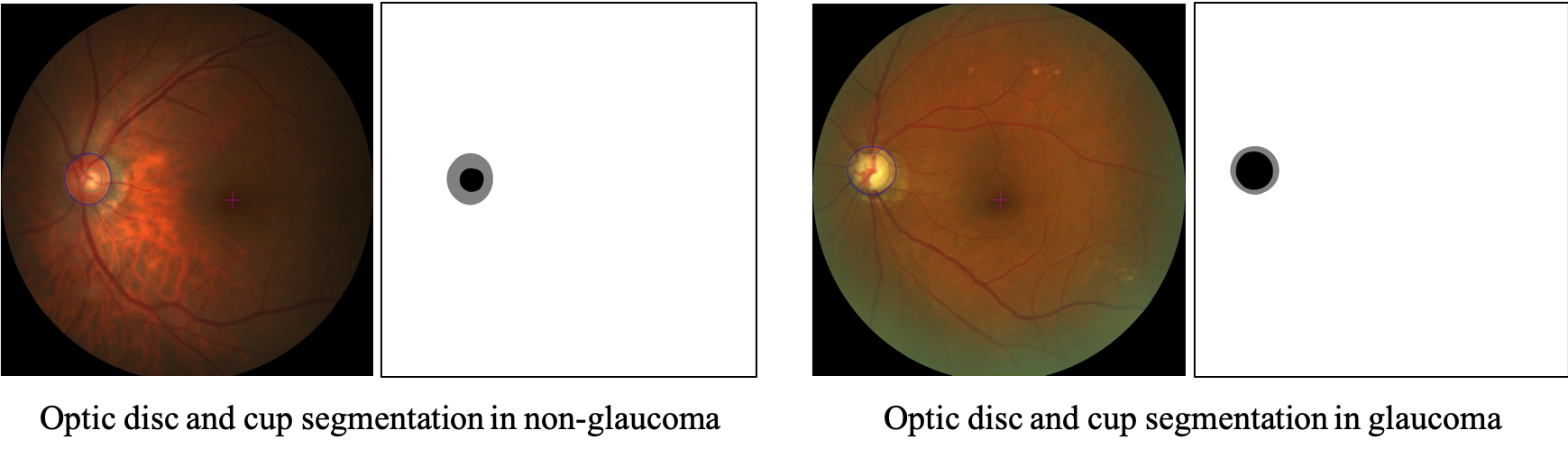
数据集中包含200个2D眼底彩照样本,分别为:训练集100对,测试集100对。
- 训练数据集包括100个样本0001-0100,每个样本对应一个2D眼底彩照数据,存储为0001.jpg。
- 视杯视盘分割金标准以bmp图像格式存储,每个样本的眼底图像对应一个视杯视盘分割结果图像。分割结果图像命名与输入的待分割眼底图像命名前缀一致。分割图像中,像素值为0代表视杯区域、像素值为128代表视盘中非视杯区域、像素值为255代表其他区域。所有样本的分割图像存储在Disc_Cup_Masks文件夹中。
- 测试数据集包括100个样本的数据对0101-0200,数据存储格式与训练集中一致。
3 项目步骤
- 该比赛是10月末出现,踩着月赛截止的尾巴,所以用 PaddleX 快速地对比赛数据做一个初探,后续再进行改进。
3.1 导入依赖
!pip install paddlex
import warnings
warnings.filterwarnings('ignore')import os
os.environ['CUDA_VISIBLE_DEVICES'] = '0'import paddle
import paddlex as pdx
from paddlex import transforms as Timport shutil
import glob
import numpy as np
import pandas as pdimport cv2
import imghdr
from PIL import Image
3.2 数据清洗
- 下载数据集至
data/dataset.zip。
!wget https://dataset-bj.cdn.bcebos.com/%E5%8C%BB%E7%96%97%E6%AF%94%E8%B5%9B/task3_disc_cup_segmentation.zip -O data/dataset.zip
- 解压数据集,然后变换至 PasclVOC 格式目录结构(JPEGImages、Annotations)。
data/training
├── Annotations
└── JPEGImages
!unzip -oq /home/aistudio/data/dataset.zip -d data/!mv data/training/fundus\ color\ images data/training/JPEGImages
!mv data/training/Disc_Cup_Mask data/training/Annotations
- 原图和标注图的 模式(mode) 分别为 RGB(真彩色、三通道) 和 L(8位灰度图);
- 原图和标注图的 尺寸(size) 需要一致;
- 将
0-128-255三个标注数值映射至从0开始递增的序列0-1-2,后续对模型预测结果进行逆映射即可。
jpg_path_list = glob.glob('data/training/JPEGImages/*.jpg')for i in range(len(jpg_path_list)):jpg_path = jpg_path_list[i]jpg_name = str(jpg_path.split('/')[-1]).split('.')[0]ant_path = os.path.join('data/training/Annotations', f'{jpg_name}.png')if imghdr.what(jpg_path) and imghdr.what(ant_path):img_jpg = Image.open(jpg_path).convert('RGB')img_ant = Image.open(ant_path).convert('L')if img_jpg.size != img_ant.size:img_jpg = img_jpg.resize(img_ant.size, Image.ANTIALIAS)img_jpg.save(jpg_path)img_ant = np.array(img_ant, dtype='uint8')img_ant[img_ant == 0] = 0img_ant[img_ant == 128] = 1img_ant[img_ant == 255] = 2cv2.imwrite(ant_path, img_ant)else:if os.path.exists(jpg_path):os.remove(jpg_path)print('delete:', jpg_path)if os.path.exists(ant_path):os.remove(ant_path)print('delete:', ant_path)
3.3 数据集划分
- 这里并没有划分验证集。
!paddlex --split_dataset --format SEG\--dataset_dir data/training\--val_value 0.0001\--test_value 0
- 持久化训练过程,结果可对比、可复现。
!cp data/training/train_list.txt work/train_list.txt
!cp data/training/val_list.txt work/val_list.txt
!cp data/training/labels.txt work/labels.txt
3.4 数据增强与读取器
eval_transforms用于模型 predict 时传入(因为训练时没有验证集,则模型默认不会有预处理操作)。
以下是将大图重定义尺寸至 512x512 方便训练,加上翻转和色调变换及小概率模糊,最后归一化至 [-1, 1]。
train_transforms = T.Compose([T.Resize(target_size=(512, 512), interp='AREA'),T.RandomHorizontalFlip(0.5),T.RandomVerticalFlip(0.5),T.RandomDistort(brightness_range=0.5, brightness_prob=0.5,contrast_range=0.5, contrast_prob=0.5,saturation_range=0.5, saturation_prob=0.5,hue_range=18, hue_prob=0.5),T.RandomBlur(0.05),T.Normalize(mean=[0.5, 0.5, 0.5], std=[0.5, 0.5, 0.5]),
])eval_transforms = T.Compose([T.Resize(target_size=(512, 512), interp='AREA'),T.Normalize(mean=[0.5, 0.5, 0.5], std=[0.5, 0.5, 0.5]),
])
- 定义数据读取器。
train_dataset = pdx.datasets.seg_dataset.SegDataset(data_dir='data/training',file_list='work/train_list.txt',label_list='work/labels.txt',transforms=train_transforms,shuffle=True)
3.5 模型训练
- 选择 UNet + Dice Loss 进行训练。
model = pdx.seg.UNet(num_classes=len(train_dataset.labels),use_mixed_loss=[('DiceLoss', 1)])
- 训练 150 个轮次,批大小为 4,最高学习率为 0.001,使用 Warmup + Cosine decay 的学习率衰减策略。
num_epochs = 150
train_batch_size = 4
learning_rate = 0.001
step_each_epoch = train_dataset.num_samples // train_batch_sizedecayed_lr = paddle.optimizer.lr.CosineAnnealingDecay(learning_rate=learning_rate,T_max=step_each_epoch * num_epochs)decayed_lr = paddle.optimizer.lr.LinearWarmup(learning_rate=decayed_lr,warmup_steps=step_each_epoch * 10,start_lr=0.0,end_lr=learning_rate)optimizer = paddle.optimizer.Momentum(learning_rate=decayed_lr,momentum=0.9,weight_decay=paddle.regularizer.L2Decay(1e-4),parameters=model.net.parameters())
- 模型开始训练,传入配置好的 optimizer,每5个Epoch保存一次,并输出一个step过程的训练日志。
model.train(train_dataset=train_dataset,num_epochs=num_epochs,train_batch_size=train_batch_size,optimizer=optimizer,save_interval_epochs=5,log_interval_steps=step_each_epoch * 5,pretrain_weights='IMAGENET',save_dir='output/UNet_Dice',use_vdl=True)
4 模型预测与提交
- 加载模型(Epoch 150)。
model = pdx.load_model('output/UNet_Dice/epoch_150')
2021-10-30 12:49:55 [INFO] Model[UNet] loaded.
获取模型预测的掩膜 label_map ,并对类别标记进行逆映射(0-1-2: 0-128-255),最后另存为 work/Disc_Cup_Segmentations/*.bmp。
!mkdir work/Disc_Cup_Segmentationslabel_list = glob.glob('data/testing/fundus color images/*.jpg')for path in label_list:img = cv2.imread(path)img = img.astype('float32')result = model.predict(img, eval_transforms)label = ['label_map']label[label == 0] = 0label[label == 1] = 128label[label == 2] = 255label = np.uint8(label)img_name = str(path.split('/')[-1]).split('.')[0]cv2.imwrite(f"work/Disc_Cup_Segmentations/{img_name}.bmp", label)
- 将所预测的结果 *.bmp 打包为提交文件 *.zip。
%cd work/
!zip -r -q Disc_Cup_Segmentations.zip Disc_Cup_Segmentations
%cd ../
- 将测试集上最优模型拷贝至
work/目录下,生成版本文件以持久化。
!mkdir work/UNet_Dice
!cp -r output/UNet_Dice/epoch_150 work/UNet_Dice/epoch_150
- 本次项目的主要产出均已经保存至
work/目录下,方便后续的模型融合等步骤进行。
!tree work/
work/
├── Disc_Cup_Segmentations.zip
├── labels.txt
├── train_list.txt
├── UNet_Dice
│ └── epoch_150
│ ├── model.pdopt
│ ├── model.pdparams
│ └── model.yml
└── val_list.txt2 directories, 7 files│ ├── model.pdparams
│ └── model.yml
└── val_list.txt2 directories, 7 files
5 项目总结
本项目使用 PaddleX 开发工具搭建了在 IMAGENET 上预训练权重的 UNet 模型,利用随机翻转、色调扰动等数据增强方式,结合 Dice Loss 损失函数和 Warmup + Cosine decay 的技巧,实现了视杯视盘语义分割任务。
改进方向
- 数据预处理;
- 模型选择;
- 训练超参数的调优;
我的 AI Studio 主页
本文来自互联网用户投稿,文章观点仅代表作者本人,不代表本站立场,不承担相关法律责任。如若转载,请注明出处。 如若内容造成侵权/违法违规/事实不符,请点击【内容举报】进行投诉反馈!