长文预警【深度学习】基于 Pytorch 的网络训练
我是 雪天鱼,一名FPGA爱好者,研究方向是FPGA架构探索和数字IC设计。
关注公众号【集成电路设计教程】,获取更多学习资料,并拉你进“IC设计交流群”。
QQIC设计&FPGA&DL交流群 群号:866169462。
文章目录
- 一、数学基础:标量,向量,矩阵与张量
- 二、自动求导
- 三、线性回归与拟合
- 四、Pytorch 写法
- 五、实战
一、数学基础:标量,向量,矩阵与张量
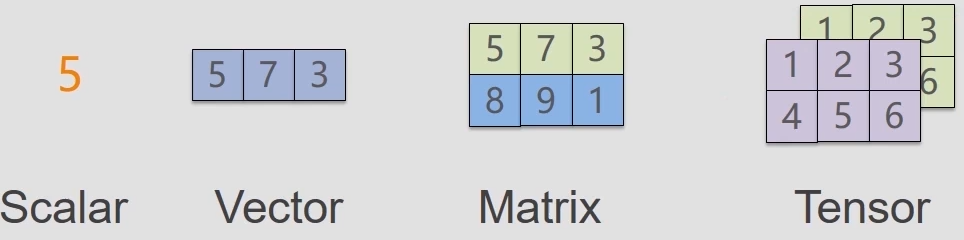
一个标量(Scalar)就是一个单独的数;
一个向量就是一列数,这些数是有序排列的。通过索引,、可以确定对应的每个单独的数;
矩阵是二维数组,其中的每一个元素被两个索引而非一个所确定。
几何代数中定义的张量是基于向量和矩阵的推广,通俗一点理解的话,可以将标量视为零阶张量,向量视为一阶张量,那么矩阵就是二阶张量,任意一张彩色图片表示成一个三阶张量,三个维度分别是图片的高度、宽度和色彩数据。所以Tensor一般指三阶及更高阶的张量。
二、自动求导
x = torch.tensor([2.0], requires_grad = True)
a = torch.tensor([4.0], requires_grad = True)
y = x * a# 求计算图各节点导数
y.backward() print(x.grad) # y 对 x 的偏导 -> a
print(a.grad) # y 对 a 的偏导 -> x
结果:
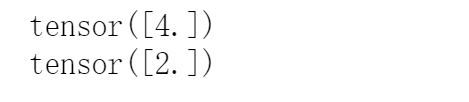
pytorch 自动求导方式很简单,定义一个表达式 y,然后 y 由变量(一般为标量)x1,x2,x3…计算得到,那么此时调用 y.backward() 进行反向传播,对各变量计算梯度(即偏导数),然后这些梯度会保存在变量的 grad 属性中。
再举个例子,如下所示,对 y=x**4 求导

三、线性回归与拟合

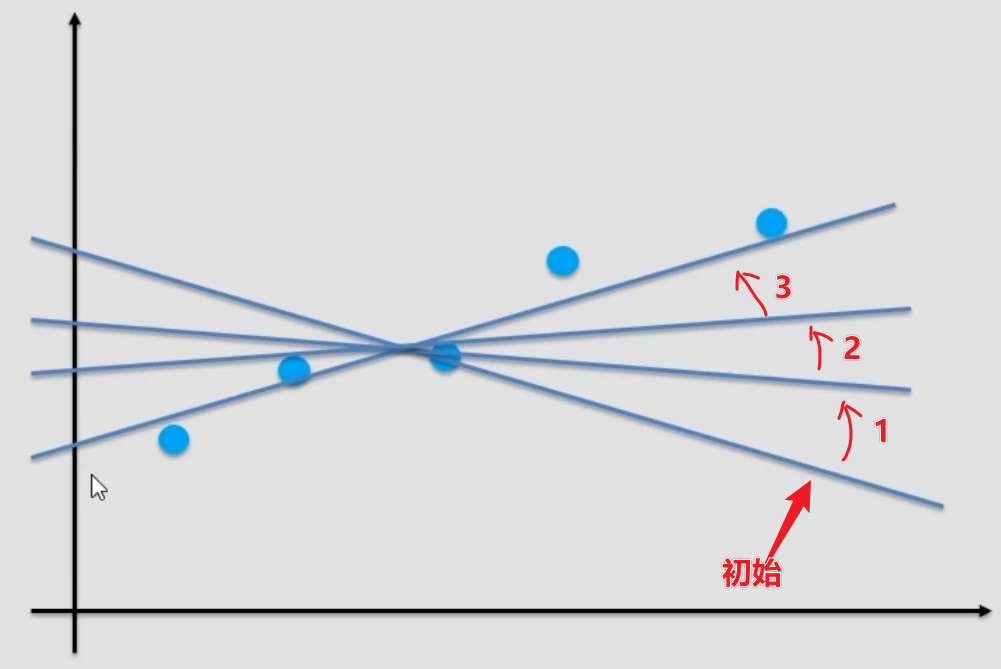
在上图中有很多蓝点,也就是数据,我们所要做的是找出一条直线,能尽可能多的经过这些数据点,也就是达到尽可能好的拟合效果,求出斜率W和截距b。
可采用迭代法,即先随机初始化一个 W 和 b,然后设置一个 loss函数(即能衡量拟合效果优劣的指标),然后根据 loss 去修改 W 和 b,目标是使 loss 尽可能的小,即拟合效果尽可能的好。示意图如下所示:
对于线性回归而言,这个衡量指标为:
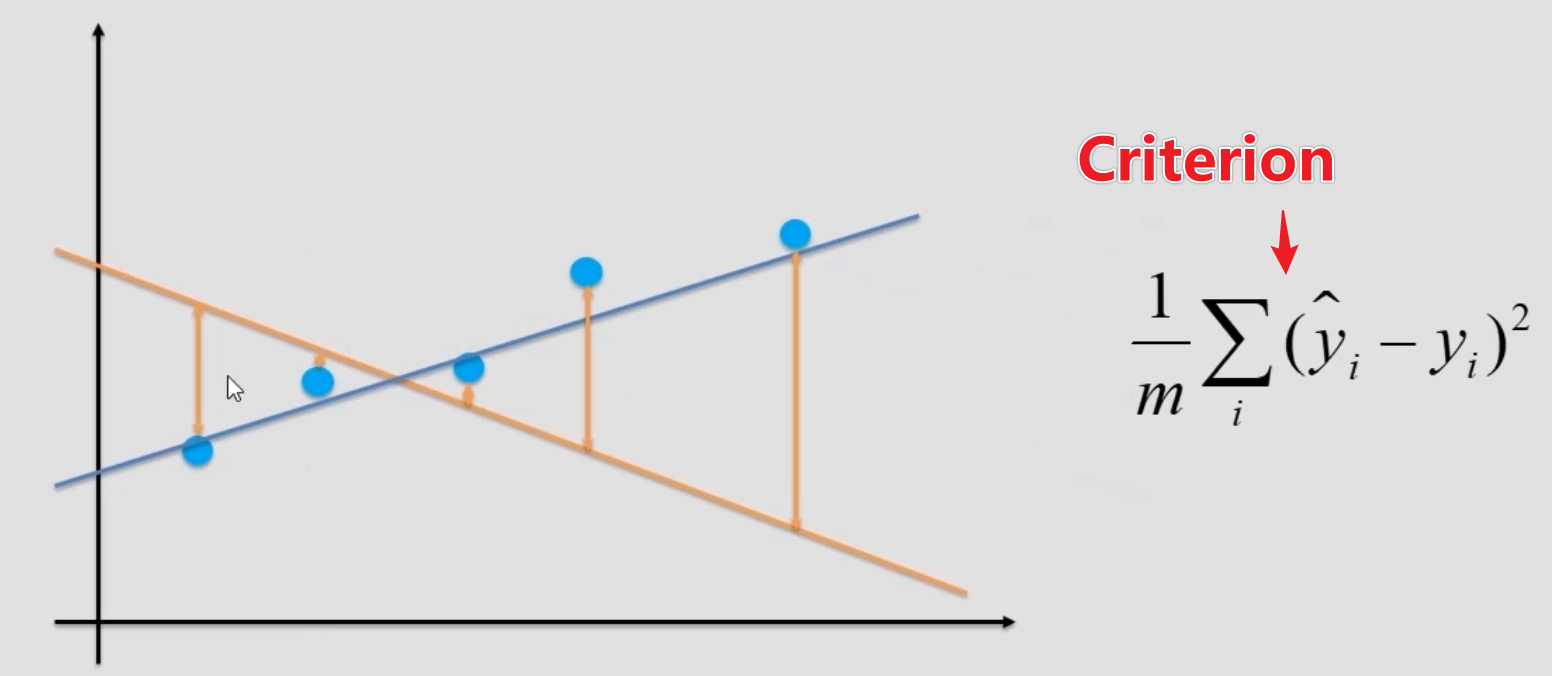
即预测值与真实值之间差值的均方差,每次调整 w 和 b ,都是为了使此 loss 更小,所以就可以转化为优化问题:

那么具体怎么调整 w,b呢?即在当前位置,w是变大还是变小,b是变大还是变小。
解决方法就是通过梯度(偏导数)来判断增大还是减小所要调整的参数,以 w 为例,当 loss 对 w 的偏导数,即梯度为正表示该处 loss 随 w 增大而增大,故减小 w,f反之梯度为负表示该处 loss 随 w 增大而增大减小,故增大 w。
而具体增大多少,减小多少则由学习率(learning rate)和梯度共同决定,学习率越大,收敛越快,这很容易理解,因为移动的步伐增大了嘛,但同时也可以错过最佳拟合点。
代码示例:
x_train = torch.rand(100)
y_train = x_train * 2 + 3 # 目标曲线:w = 2, b = 3, y = 2 * x + 3
# (x_train,y_train)即为要拟合的数据# 初始化 w 和 b
w = torch.tensor([0.0],requires_grad = True)
b = torch.tensor([0.0],requires_grad = True)# 拟合
lr = 0.015 # 学习率
loss_func = torch.nn.MSELoss() # loss 函数,衡量拟合效果,越小越好
for i in range(200):y_pre = x_train * w + b # 预测值loss = loss_func(y_train, y_pre) # 输入预测值与实际值,计算 lossif i % 10 == 0: # 每 10 轮输出一次 w, b, lossprint("Iter: %d, w: %.4f, b: %.4f, training loss: %.4f" % (i, w.item(), b.item(), loss.item()))loss.backward() # 反相传播,计算 loss 对 w 和 b 的偏导数# 调整 w 和 bw.data -= w.grad * lrb.data -= b.grad * lr# 梯度清零w.grad.data.zero_()b.grad.data.zero_()
结果:
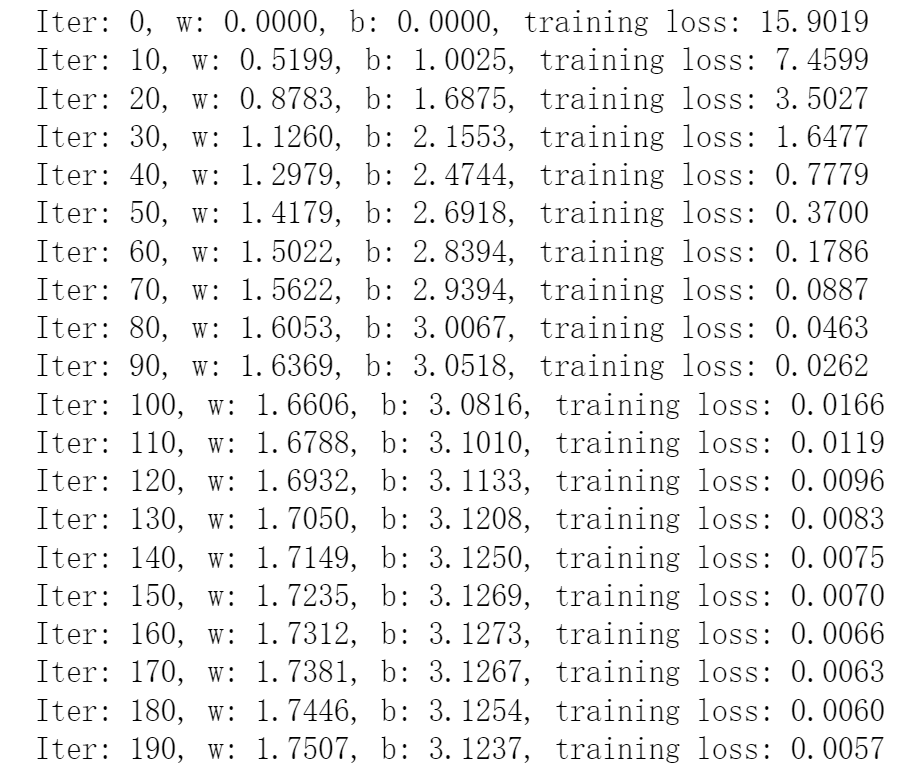
从结果上来看,可以发现 loss 越来越小,说明拟合结果越来越好, w 和 b 也是分别越来越靠近 2 和 3,这就是迭代法。
四、Pytorch 写法
写法总结为:

示例代码:
import torch # 1 定义 model,给训练输入,输出对应预测值
class SimpleLinear:def __init__(self):self.w = torch.tensor([0.0], requires_grad=True)self.b = torch.tensor([0.0], requires_grad=True)# 前向传播获得预测值def forward(self, x):y = self.w * x + self.breturn ydef parameters(self):return [self.w, self.b]def __call__(self, x):return self.forward(x)# 2 定义优化器
class Optimizer:def __init__(self, parameters, lr):self.parameters = parametersself.lr = lr# 更新参数def step(self):for para in self.parameters:para.data -= para.grad * self.lr# 清零参数的梯度def zero_grad(self):for para in self.parameters:para.grad.data.zero_()# 3 训练
def train():model = SimpleLinear()opt = Optimizer(model.parameters(), lr=0.3)for epoch in range(10):output = model(x_train)loss = loss_func(y_train, output)loss.backward()opt.step()opt.zero_grad()print('Epoch {},w:{:.4f} b:{:.4f},loss is {:.4f}'.format(epoch,model.parameters()[0].item(),model.parameters()[1].item(), loss.item()))train()
结果:

五、实战
以 MNIST 数据集为例,做手写数字识别网络的训练与评估。
示例代码:
import math
import torch
import torch.nn as nn
import torch.nn.functional as F
from torchvision import datasets, transforms
import torch.utils.data# 定义 model
class Net(nn.Module):def __init__(self):super(Net, self).__init__()# torch.nn.Conv2d(in_channels, out_channels, kernel_size,# stride=1, padding=0, dilation=1, groups=1, bias=True, padding_mode='zeros')self.conv1 = nn.Conv2d(1, 32, 3, 1)self.conv2 = nn.Conv2d(32, 64, 3, 1)self.dropout1 = nn.Dropout2d(0.25)self.dropout2 = nn.Dropout2d(0.5)self.fc1 = nn.Linear(9216, 128)self.fc2 = nn.Linear(128, 10)def forward(self, x):x = self.conv1(x)x = F.relu(x)x = self.conv2(x)x = F.max_pool2d(x, 2)x = self.dropout1(x)x = torch.flatten(x, 1)x = self.fc1(x)x = F.relu(x)x = self.dropout2(x)x = self.fc2(x)output = F.log_softmax(x, dim=1)return outputdef train(model, device, train_loader, optimizer, epoch):model.train()total = 0for batch_idx, (data, target) in enumerate(train_loader):# 获取实际值,可以简单理解: data -> x target -> ydata, target = data.to(device), target.to(device)optimizer.zero_grad() # 梯度清零output = model(data) # 获得预测值loss = F.nll_loss(output, target) # 计算 lossloss.backward() # loss 反向传播optimizer.step() # 更新参数# 训练进度统计total += len(data) # 目前训练图片数progress = math.ceil(batch_idx / len(train_loader) * 50)print("\rTrain epoch %d: %d/%d, [%-51s] %d%%" %(epoch, total, len(train_loader.dataset),'-' * progress + '>', progress * 2), end='')def test(model, device, test_loader):model.eval()test_loss = 0correct = 0with torch.no_grad():for data, target in test_loader:# 获取实际值data, target = data.to(device), target.to(device)# 获取预测值output = model(data)# 计算 losstest_loss += F.nll_loss(output, target, reduction='sum').item() # sum up batch losspred = output.argmax(dim=1, keepdim=True) # get the index of the max log-probabilitycorrect += pred.eq(target.view_as(pred)).sum().item()test_loss /= len(test_loader.dataset)print('\nTest: average loss: {:.4f}, accuracy: {}/{} ({:.0f}%)'.format(test_loss, correct, len(test_loader.dataset),100. * correct / len(test_loader.dataset)))def main():epochs = 2 # 训练总轮数batch_size = 64torch.manual_seed(0)device = torch.device("cuda" if torch.cuda.is_available() else "cpu")train_loader = torch.utils.data.DataLoader(datasets.MNIST('../data/MNIST', train=True, download=False,transform=transforms.Compose([transforms.ToTensor(),transforms.Normalize((0.1307,), (0.3081,))])),batch_size=batch_size, shuffle=True)test_loader = torch.utils.data.DataLoader(datasets.MNIST('../data/MNIST', train=False, download=False, transform=transforms.Compose([transforms.ToTensor(),transforms.Normalize((0.1307,), (0.3081,))])),batch_size=1000, shuffle=True)model = Net().to(device)optimizer = torch.optim.SGD(model.parameters(), lr=0.025, momentum=0.9)for epoch in range(1, epochs + 1):train(model, device, train_loader, optimizer, epoch)test(model, device, test_loader)# torch.save(model.state_dict(), "mnist_cnn.pt")
main()
结果:

至此基于 Pytorch 的网络训练与评估就讲解完毕了,不知道你有没有理解呢?
本文来自互联网用户投稿,文章观点仅代表作者本人,不代表本站立场,不承担相关法律责任。如若转载,请注明出处。 如若内容造成侵权/违法违规/事实不符,请点击【内容举报】进行投诉反馈!