达梦数据库管理HUGE表的基本操作
1 HUGE表
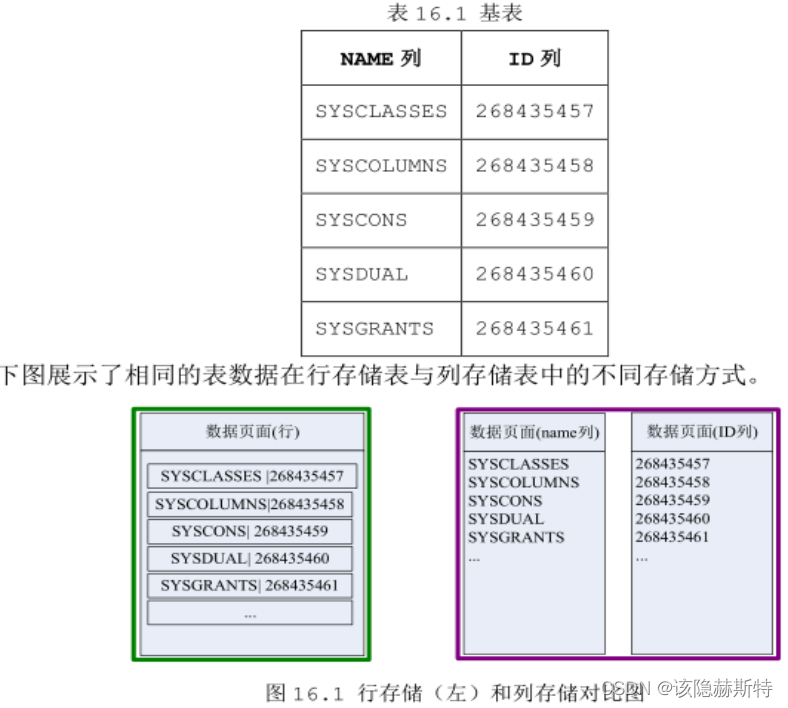
列存储是以列为单位进行存储的,每一个列的所有行数据都存储在一起,而且一个指定的页面中存储的都是某一列的连续数据。Huge File System(检查 HFS)是达梦数据库实现的,针对海量数据进行分析的一种高效、简单的列存储机制。列存储表(也称为 HUGE 表)就是建立在 HFS 存储机制上的一种表。
HUGE 表与普通行表一样,可以进行增、删、改操作,操作方式也是一样的。但 HUGE
表的删除与更新操作的效率会比行表低一些,并发操作性能也会比行表差一些,因此在HUGE中不宜做频繁的删除及更新操作。总之,HUGE 表比较适合做分析型表的存储。
HUGE表建立在自己特有的表空间HTS上,最多可创建32767个HUGE表空间,相关信息存储动态视图在V$HUGE_TABLESPACE中。HUGE表是通过HTS存储机制来管理的,姓党与一个文件系统。创建一个HTS,就是创建要给空的文件目录。在创建一个 HUGE 表并插入数据时,数据库会在指定的 HTS 表空间目录下创建一系列的目录及文件。
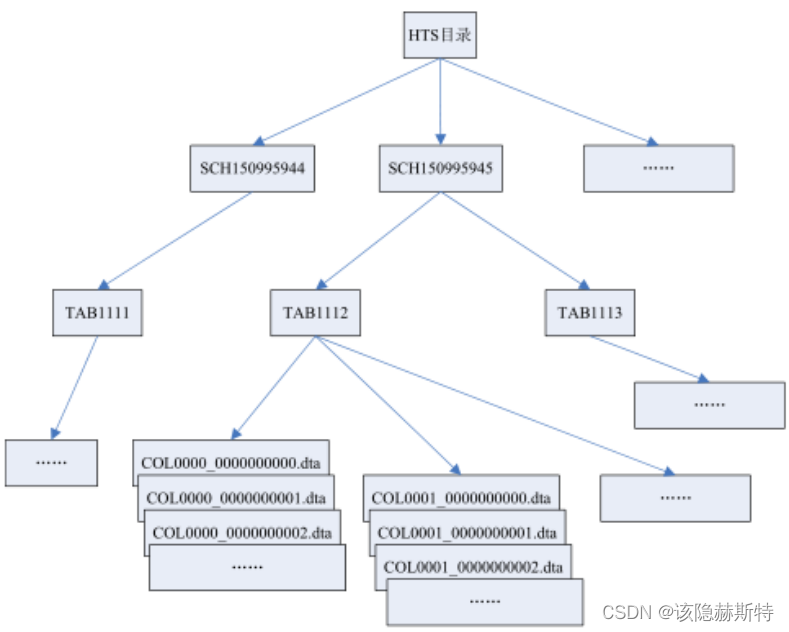
成功创建HUGE表,需以下步骤:
1)在HTS目录下创建这个表对应的模式目录,录名为“SCH+长度为9的ID号”
组成的字符串。
2)在模式目录下创建对应的表目录。表目录名为”TAB+长度为4的ID号”,表目录中存放的是这个表中所有的文件。
3)在新创建表后插入数据时,每一个列对应一个以dta为后缀的文件,文件大小可以在建表时指定,默认为64M,文件名为”COL+长度为4的列号_长度为10的行号”。
系统对于一个文件,其内部存储是按照区来管理的,区是文件内部数据管理的最小单位,也是唯一的单位。一个区中,可以存储单列数据的行数是在创建表时指定的,一经指定,在这个表的生命过程就不能再修改。所以,对于定长数据,一个区的大小是固定的;而对于变长数据,一般情况下区大小都是不相同的。每一个区的开始位置及长度在文件内都是 4K 对齐的。
HUGE 表的存储方式有以下几个优点:
1. 同一个列的数据都是连续存储的,可以加快某一个列的数据查询速度;
2. 连续存储的列数据,具有更大的压缩单元和数据相似性,可以获得远优于行存储的压缩效率,压缩的单位是区;
3. 条件扫描借助数据区的统计信息进行精确过滤,可以进一步减少 IO,提高扫描效率;
4. 允许建立二级索引;
5. 支持以 ALTER TABLE 的方式添加或者删除 PK 和 UNIQUE 约束。会自动创建新的文件来存储不断增长的数据。
2创建过程:
- 创建一个HUGETABLECE(HTS)
SQL> create HUGE TABLESPACE huge1 path '/home/dmdba/dmdbms/test/DAMENG/HTS';

- 创建一个非事务型HUGE表t1。(创建失败)

- 创建一个非事务型HUGE表T2

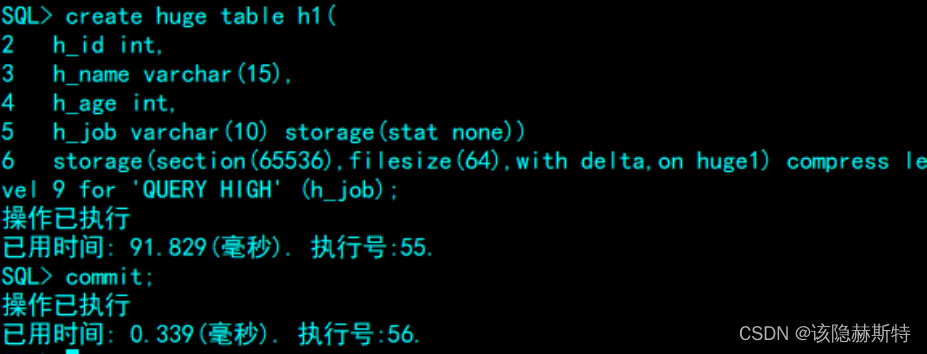
- 创建一个事务型HUGE表h1,属于表空间huge1,h1表的区大小为65536行,文件大小为64M,h_job列指定的区大小为不做统计信息,其他列(默认)都做统计信息,指定h_job列压缩类型为查询高压缩率(query high),压缩级别为9.
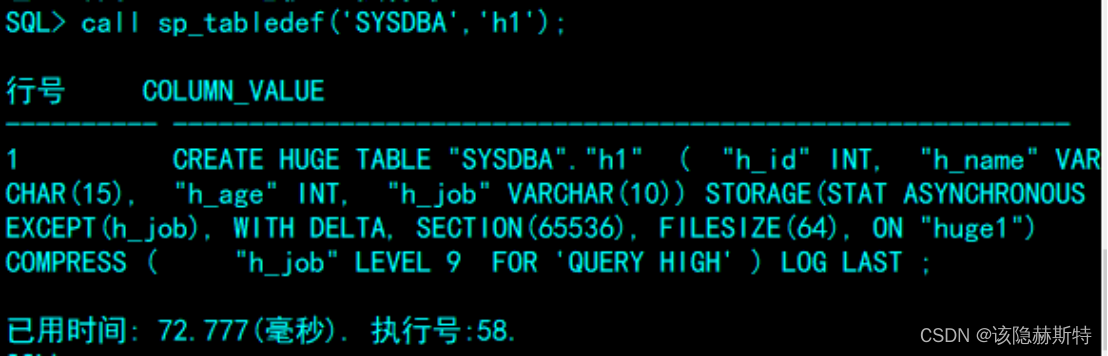
3查看HUGE表定义
SQL> call sp_tabledef('SYSDBA','h1');
4查看数据存储情况
HUGE 表有一个很好的特点就是有 AUX 辅助表,其中用户可以利用的信息很多,因为每一条记录对应一个区,所以可以查看每一个区的存储情况,每一个列的存储情况及每一个列中具有相同区ID的所有数据的情况等,还包括了很精确的统计信息,用户可以通过观察AUX辅助表中的信息对表进行一些相应的操作。
本文来自互联网用户投稿,文章观点仅代表作者本人,不代表本站立场,不承担相关法律责任。如若转载,请注明出处。 如若内容造成侵权/违法违规/事实不符,请点击【内容举报】进行投诉反馈!