lammps reaxff力场断键分析
事情是这样的。最近照着一个毕业师兄的文章跑了个reaxff的模拟,在分析断键情况时又被lammps反人类的输出给难到了。在网上找了下也没有实现相应功能的脚本,于是乎自己动手丰衣足食,写了段脚本进行分析。
使用lammps的reax/c/bonds命令可以输出模拟爱过程中键相关的信息,输出格式如下:
# Timestep 0
#
# Number of particles 3128
#
# Max number of bonds per atom 4 with coarse bond order cutoff 0.300
# Particle connection table and bond orders
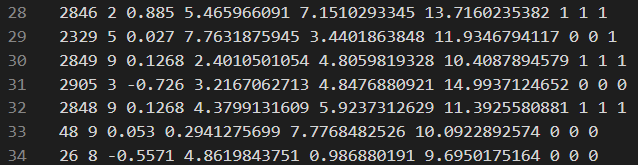
# id type nb id_1...id_nb mol bo_1...bo_nb abo nlp q 2846 2 3 2847 2845 248 0 1.361 1.295 1.109 3.829 0.000 0.8822851 9 1 2844 0 0.943 0.947 0.000 0.0372849 9 1 2840 0 0.949 0.997 0.000 0.0572905 3 3 2917 2901 2907 0 0.859 0.863 1.786 3.557 0.151 -0.6722848 9 1 2839 0 0.945 1.002 0.000 0.093第七行各参数的含义如下:
- id = atom id
- type = atom type
- nb = number of bonds
- id_1 = atom id of first bond
- id_nb = atom id of Nth bond
- mol = molecule id
- bo_1 = bond order of first bond
- bo_nb = bond order of Nth bond
- abo = atom bond order (sum of all bonds)
- nlp = number of lone pairs
- q = atomic charge
总之输出就是很反人类...没法从里面直接看出某种键的数量。
用于reaxff断键分析的python脚本
首先需要的从data文件中的到原子序号与原子类型的对应关系,第四行的范围为data文件中Atoms部分对应的行号。第九行为type序号与元素字母的对应关系,根据自己需求修改。
data文件对应部分
'''读取data文件atoms部分'''
with open('charge.data') as f:lines = f.readlines()data = lines[27:3155]#需要读取的data文件行号
#存储原子编号和类型
num = [int(line.split()[0]) for line in data]
type = [int(line.split()[1]) for line in data]
#修改原子类型为字母
type_map = {1: 'O', 2: 'C', 3: 'N', 4: 'C', 5: 'C', 6: 'O',7: 'C', 8: 'O', 9: 'H', 10:'O',11: 'C',12: 'H', 13:'C',14: 'C'}
type = [type_map[t] for t in type]
#将原子编号和类型转为字典对应
dict = dict(zip(num, type))然后读取reax/c/bonds输出部分的每一帧。这里需要注意reax/c/bonds的输出中第一行需要读取的数据前只隔了7行,后面每帧与前一帧的间隔是8行。图方便我把所有间隔设置为了8,因此需要人为给第一帧前随便加一行。
'''读取reaxff输出的键信息'''
with open('bonds.reaxff') as f:lines = f.readlines()# 初始化变量
bonds = []
skip_lines = 8
n_atoms = 3128
i = 0# 按块读取文件
while i < len(lines):# 跳过前8行i += skip_lines# 读取下一个数据块block = lines[i:i+n_atoms]# 将数据块添加到列表中bonds.append(block)# 更新计数器i += n_atoms计算需要的键的数量,这里以C-N为例:
'''计算键数量'''
bond_count = []
for bond in bonds: #对每一帧进行计算n_bond = 0for line in bond: #对每帧的每行进行计算atom = line.split() #空格分隔每行if dict.get(int(atom[0])) == 'C': #如果原子类型是Nnb = int(atom[2]) #邻居原子数for i in atom[3:3+nb]: #对每个邻居进行计算if(dict.get(int(i)) == 'N'): #如果邻居原子是Cn_bond = n_bond+1 #C-N键数量+1bond_count.append(n_bond)将计算结果写入文本:
'''写输出结果'''
with open('bond.txt','w') as f:f.write('帧数 键数\n')n = 0for i in bond_count:n = n+1f.write(str(n)+' '+str(i)+'\n')最终输出内容如下:

本文来自互联网用户投稿,文章观点仅代表作者本人,不代表本站立场,不承担相关法律责任。如若转载,请注明出处。 如若内容造成侵权/违法违规/事实不符,请点击【内容举报】进行投诉反馈!