pytorch教程龙曲良06-10
06手写数字识别1
每张图片2828

针对y=wx+b
对于手写数字图片来说可以用灰度0-1表示,所以就是2828值在0-1的矩阵,然后打平变成784的向量
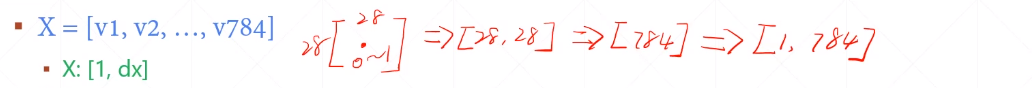
y的维度怎么表示
法1先讨论H1,H2,H3的维度,以下都表示维度,Hi不断作为Hi+1的一个输入,如[1,784]表示一行784列,但这样h1,h2…h9存在大小关系,没有相关性 ,
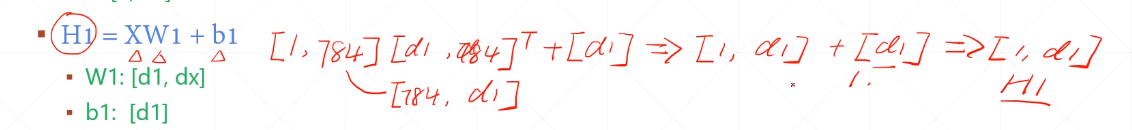

07手写数字识别02
法2用one-hot去表示概率,
1=[0,1,0,0,0,0,0,0,0,0]
3=[0,0,0,1,0,0,0,0,0,0]
求loss 欧式距离 (pred-Y)**2使得这个10维矩阵差最小


𝑝𝑟𝑒𝑑 = 𝑊3 ∗ {𝑊2 [𝑊1𝑋 + 𝑏1] + 𝑏2} + 𝑏3
这样还是可以优化成wx+b的形式,还是线性的,所以我们在每层加激活函数(sigmod function)变成非线性的,这样表达能力就增强了
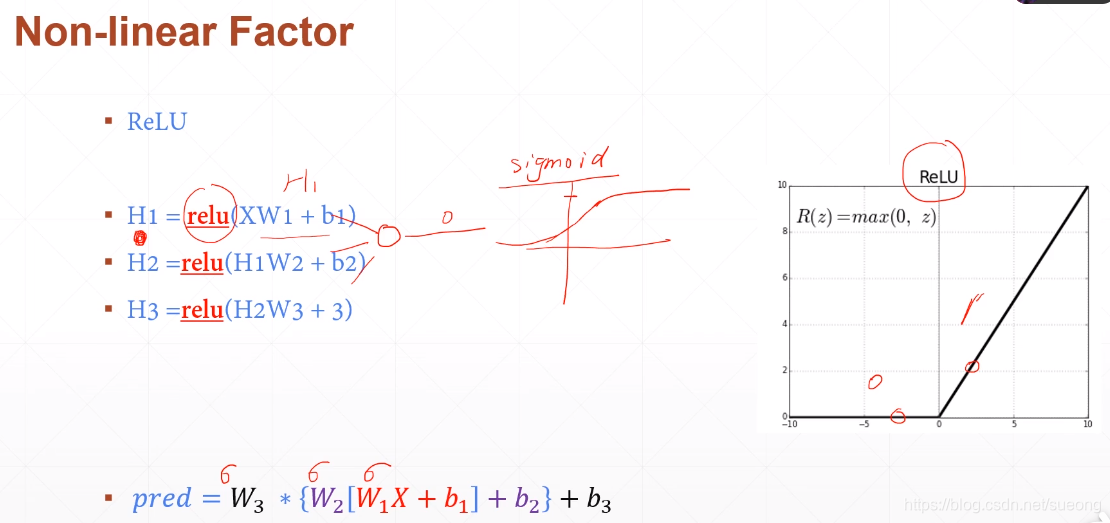
目标是:求和(pred-Y)**2最小,找到对于任意一个x都满足目标的w和b

y_pred是一个[1,10]的矩阵,[0.1, 0.8, 0.01, 0, 0.02, …]
而真实的y是[0, 1, 0, 0, 0, …]
p(0|x)=0.1表示给定一个新的x,它的标签是数字0的概率是0.1 p(1|x)=0.8表示给定一个新的x,它的标签是数字0的概率是0.8
…
max(pred)就是找到最大值0.8
argmax(pred)就是找到0.8的标签索引,label=1,我们希望max(pred)与真实值1越接近越好,这样就可以直接拿出他对应的标签
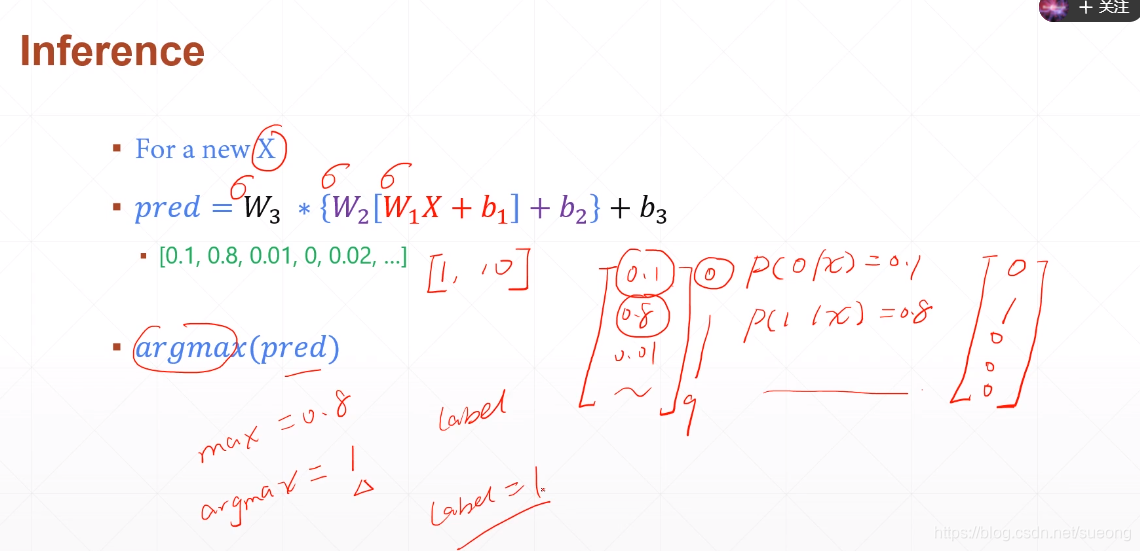
08基本数据类型1
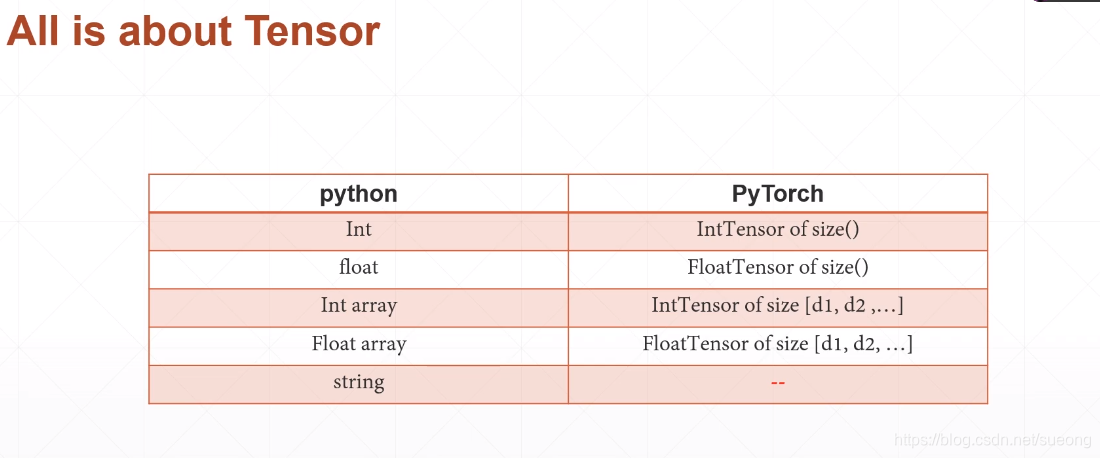
怎么表示string:
One – hot
▪ [0, 1, 0, 0, …]
缺少语义相关性,而且矩阵洗漱
▪ Embedding
▪ Word2vec
▪ glove
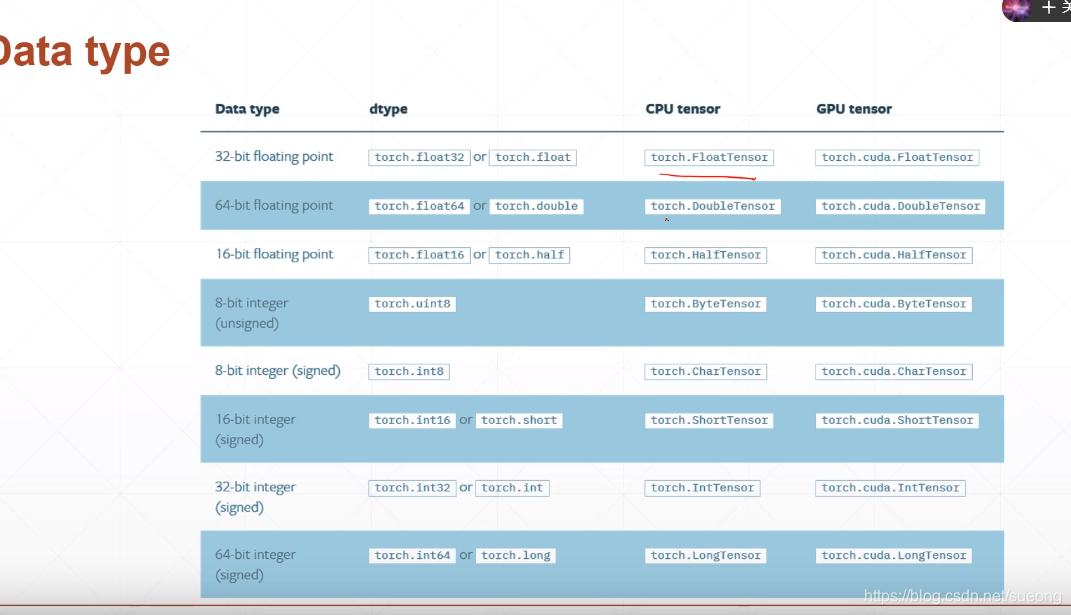
byteTensor比较tensor的大小,返回的0和1
三个重要的Tensor
FloatTensor IntTensor ByteTensor
Type check
randn(random normal distribution)是一种产生标准正态分布()的随机数或矩阵的函数。randn是均值为0方差为1的正态分布,返回一个n*n的随机项的矩阵.
[2,3]两行三列
一般检验用的是
a.type()和isinstance(a,torch.FloatTensor)

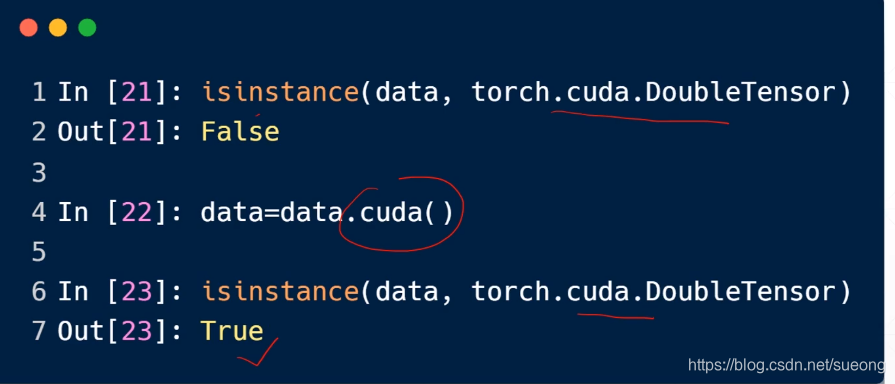
数据一样但是位置不同类型不同
data一开始放在cpu上就会false,搬到gpu就true
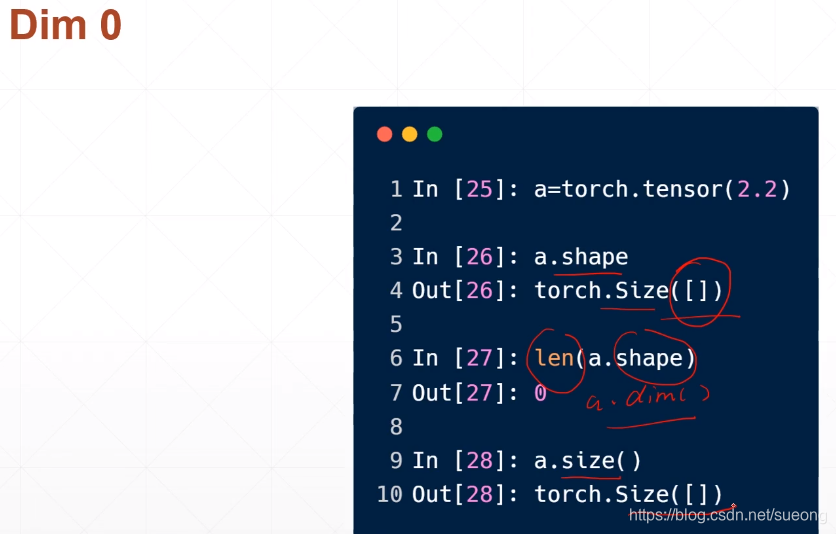
对于标量直接放入数字即可,产生的就是维度为0的tensor,因为求出的loss就是标量

怎么检查dim=0
a.shape
len(a.shape)
a.dim()
a.size()
dim=1 维度为1,即vector,dim=1的tensor常常用于计算bias和linear input
torch.tensor([1.1])#是指定数字的一个一维向量
torch.tensor([1.1,2.2])#是指定两个数字的一个一维向量
torch.FloatTensor(1)#是随机的一个长度为1的一维向量
torch.FloatTensor(2)#是随机的一个长度为21的一维向量,向量中两个数
data=np.ones(2)#随机的一个长度为2的一维向量
torch.from_numpy(data)#数字没变,但是数据类型变成了from_numpy
在pt0.3版本以前没有dim=0的存在,loss=0.3打印出的是[0.3]表示的是dim=1的一维向量,虽然一个数字的一维向量可以表示向量,但是不好区别
0.3版本以后才是打印出0.3标量
完全区分了标量和向量

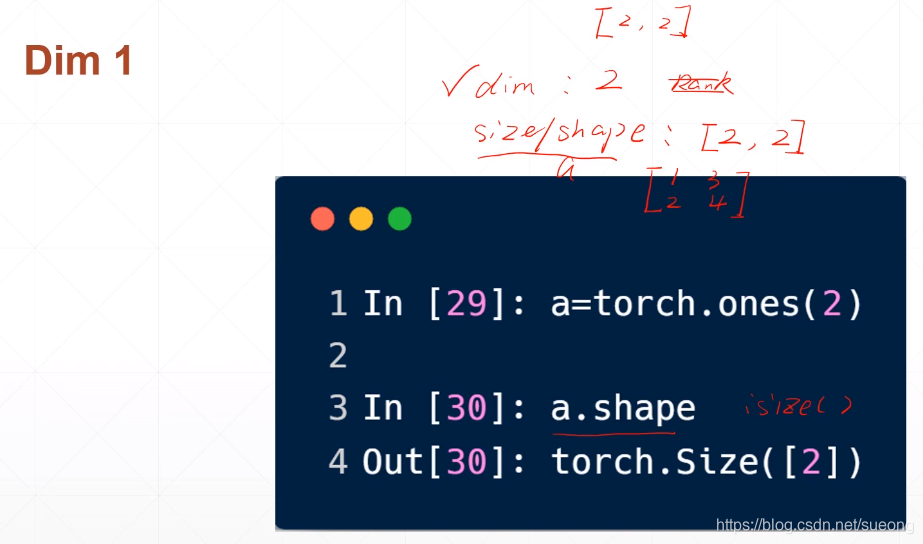
怎么得到dim=1的shape或者size:a.shape
区别dim,shape,size
dim是指维度,(类比一维数组)
size/shape指的是dim的长度/形状(元素长度)
tensor指的是具体的矩阵
09数据类型02
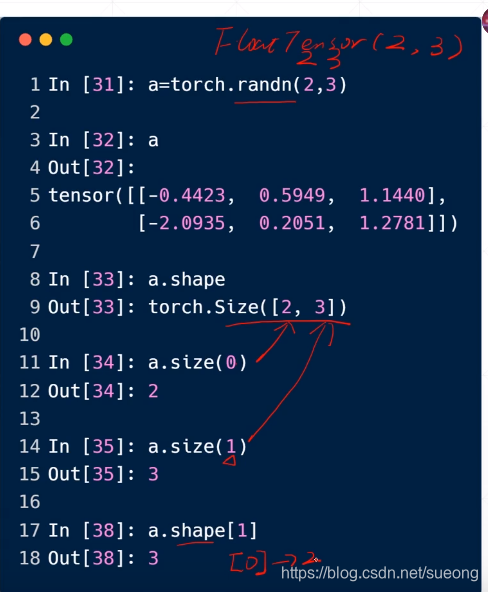
dim=2
a=torch.randn(2,3)#或者FloatTensor(2,3) 两行三列的矩阵
a.size(0)#返回第一个维度长度
a.size(1)#返回第二个维度长度
适用于Linear Input batch
比如有4张784维的照片,即写成[4,784]
dim=2,shape=[ 4,784]
(4行784列,每行代表一张图片)
dim=3
适用于RNN input Batch,比如每一句话10个单词,每个单词用100维的one-hot编码,一句话表示为:[word,features] [10,100]
如果多句话,每次送20句话,batch=20,20句sentence,[word,batch,features] [10,20,100]
rand()是0-1的均匀随机分布
a=torch.rand(1,2,3)
#因为第一个维度是1,所以一个【】,两个[],[]内三个元素A,B,C
#tensor([【[A,B,C],[E,D,F]】])
#([[[A,B,C],[E,D,F]]])dim=3,首尾分别跟着三个[和]a[0]#返回的是第一个元素的第一个元素就是维度为[2,3]的tensor([[A,B,C],[E,D,F]])
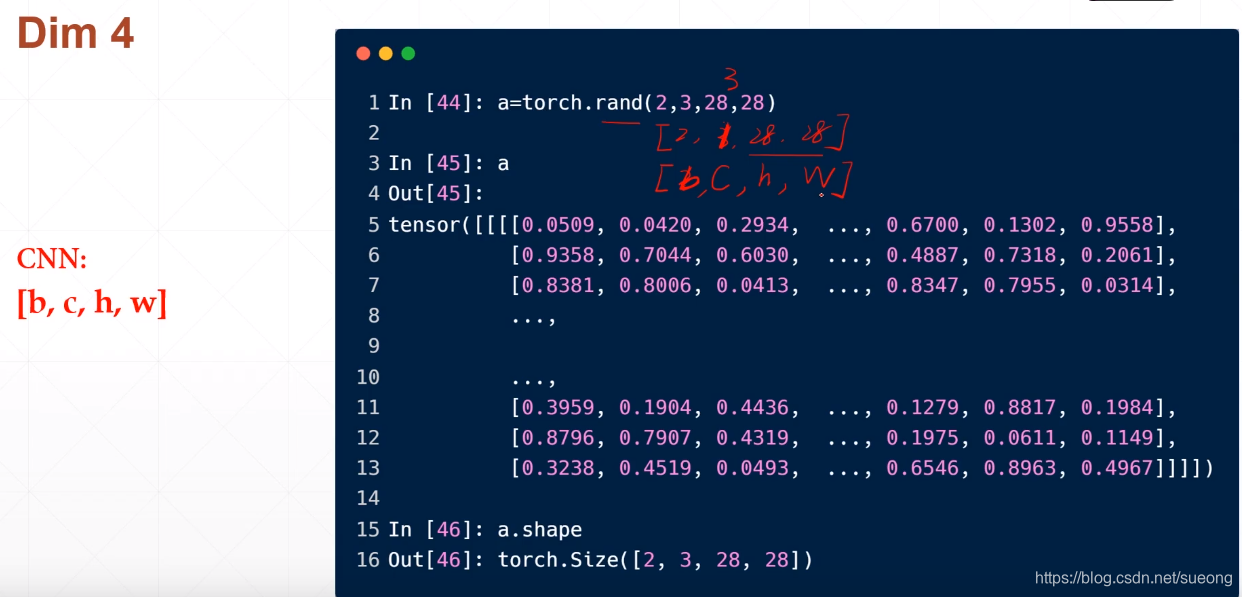
dim=4适用于cnn,图片,[b,c,h,w]即[batch,channel,height,width]
[2,3,28,28]#表示2张图片(batch=2),通道数为3则为彩色图片(RGB),通道数为1是灰色图片,28,28分别表示图片的长和宽
numel就是"number of elements"的简写。numel()可以直接返回int类型的元素个数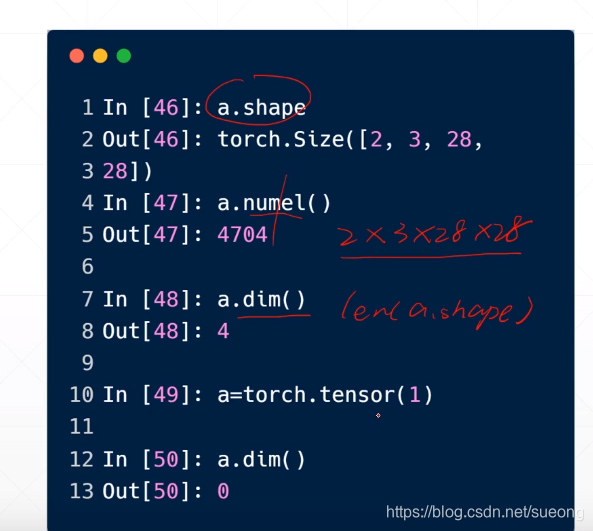
10创建Tensor01
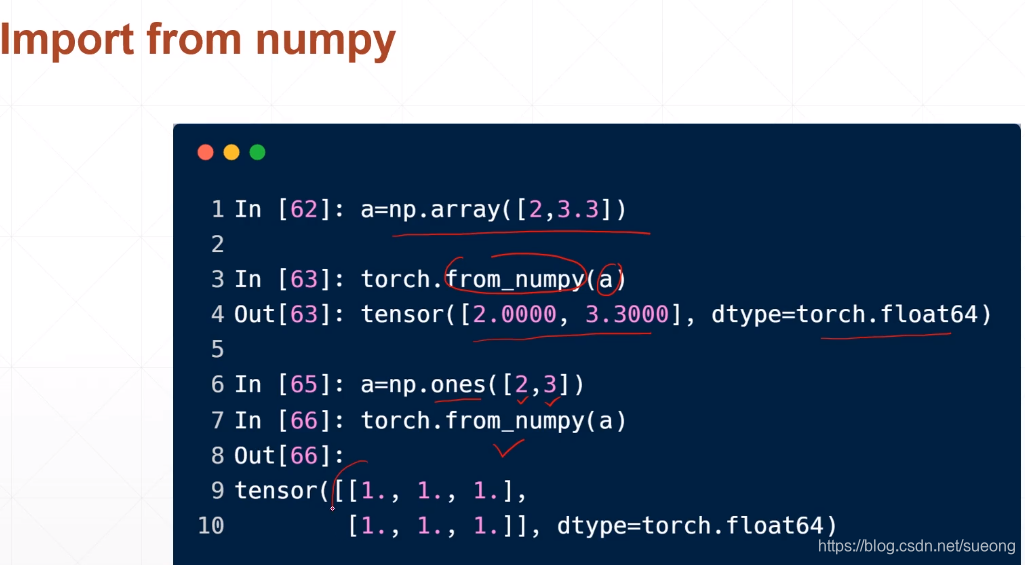
1import from numpy使用torch.from_numpy
a=np.array([2,3.3])
#创建一个dim=1,长度为2的向量,最左边只跟了一个[
torch.from_numpy(a)a=no.ones([2,3])#创建一个所有元素都是1的两行三列的矩阵
torch.from_numpy(a)
2import from list
注:
torch.tensor()#接收的指定的元素的值
torch.Tensor()和torch.FloatTensor()#接受的是shape数据的维度
比如torch.Tensor(2,3)创建一个两行三列的tensor,但是有时候Tensor也可以接收指定数据,但是要用[]list括起来,比如torch.Tensor([2.,3.2])创建的是一个一维度向量,tensor([2.0000,3.2000])
但是为了不混淆,
一般用小写tensor接受具体数据torch.tensor([A,B,C]),一般用大写Tensor 接受shape,torch.Tensor(d1,d2,d3)

uninitialized
创建了一片空间不希望初始化
Torch.empty()#接受的是shape
torch.FloatTensor(d1,d2,d3)a=torch.FloatTensor([1,2])
b=torch.tensor([1,2])
c=torch.Tensor([1,2])
print(a)
print(b)
print(c)
'''
tensor([1., 2.])
tensor([1, 2])
tensor([1., 2.])'''

未初始化的数据没有规则,很大或者很小,之后不给未初始化的数据赋值可能会报错,torch.nan或者torch.inf

不设置的话默认是FloatTensor类型
当设置为DoubleTensor时候,输入
torch.tensor([1,1])#一行两列dim=1torch.Tensor(2,3)#两行三列 dim=2
他们的类型会自动转化为DoubleTensor

随机初始化
rand:值在[0,1]之间,接收的是shape rand_like:接收的是tensor,相当于把a.shape读出来再送给rand函数
randint:值在我们指定的[min,max)之间,
torch.randint(min,max,shape)
如torch.randint(1,10,[3,3])

本文来自互联网用户投稿,文章观点仅代表作者本人,不代表本站立场,不承担相关法律责任。如若转载,请注明出处。 如若内容造成侵权/违法违规/事实不符,请点击【内容举报】进行投诉反馈!