Linux DMA、Page Cache、Buffer Cache 和零拷贝
0. 前言
磁盘可以说是计算机系统最慢的硬件之一,读写速度相差内存 10 倍以上,所以针对优化磁盘的技术非常的多,比如零拷贝、直接 I/O、异步 I/O 等等,这些优化的目的就是为了提高系统的吞吐量,另外操作系统内核中的磁盘高速缓存区,可以有效地减少磁盘的访问次数。
这次,我们就以「文件传输」作为切入点,来分析 I/O 工作方式,以及如何优化传输文件的性能。
本文围绕下列几个知识点:
- 为什么使用DMA 技术
- 普通的数据交互
- 零拷贝技术
- Page Cache
- 大文件传输的实现方式
1. 为什么使用DMA 技术
在没有 DMA 技术前,I/O 的过程是这样的:
- 当应用程序需要读取磁盘数据时,调用read()从用户态陷入内核态,read()这个系统调用最终由CPU来完成;
- CPU向磁盘发起I/O请求,磁盘收到之后开始准备数据;
- 磁盘将数据放到磁盘缓冲区之后,向CPU发起I/O中断,报告CPU数据已经Ready了;
- CPU收到磁盘控制器的I/O中断之后,开始拷贝数据,完成之后read()返回,再从内核态切换到用户态;
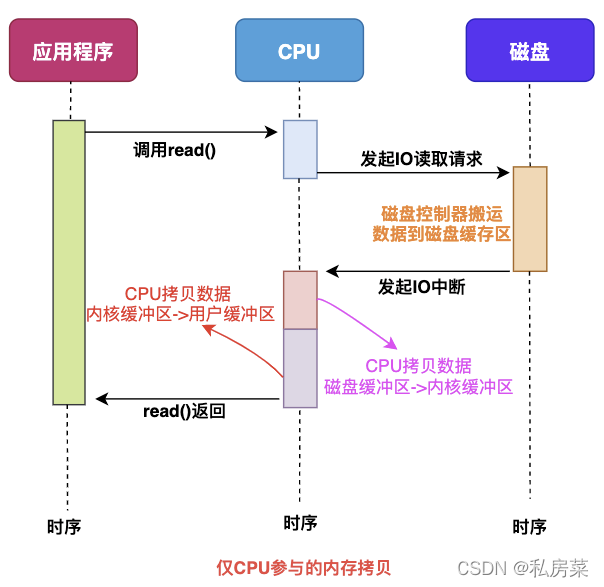
可以看到,整个数据的传输过程,都要需要 CPU 亲自参与搬运数据的过程,而且这个过程,CPU 是不能做其他事情的。
简单的搬运几个字符数据那没问题,但是如果我们用千兆网卡或者硬盘传输大量数据的时候,都用 CPU 来搬运的话,肯定忙不过来。
计算机科学家们发现了事情的严重性后,于是就发明了 DMA 技术,也就是直接内存访问(Direct Memory Access) 技术。
什么是 DMA 技术?简单理解就是,在进行 I/O 设备和内存的数据传输的时候,数据搬运的工作全部交给 DMA 控制器,而 CPU 不再参与任何与数据搬运相关的事情,这样 CPU 就可以去处理别的事务。
目前支持DMA的硬件包括:网卡、声卡、显卡、磁盘控制器等。
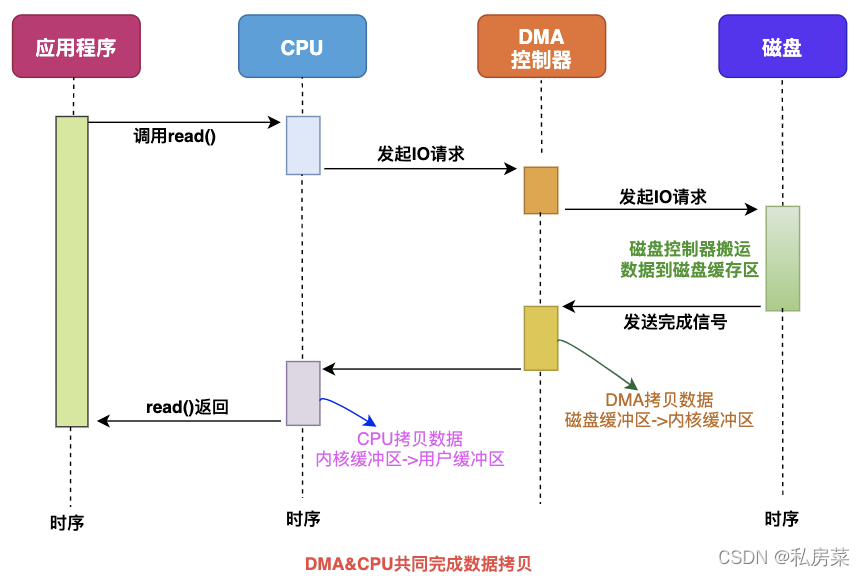
具体过程:
-
用户进程调用 read 方法,向操作系统发出 I/O 请求,请求读取数据到自己的内存缓冲区中,进程进入阻塞状态;
-
操作系统收到请求后,进一步将 I/O 请求发送 DMA,然后让 CPU 执行其他任务;
-
DMA 进一步将 I/O 请求发送给磁盘;
-
磁盘收到 DMA 的 I/O 请求,把数据从磁盘读取到磁盘控制器的缓冲区中,当磁盘控制器的缓冲区被读满后,向 DMA 发起中断信号,告知自己缓冲区已满;
-
DMA 收到磁盘的信号,将磁盘控制器缓冲区中的数据拷贝到内核缓冲区中,此时不占用 CPU,CPU 可以执行其他任务;
-
当 DMA 读取了足够多的数据,就会发送中断信号给 CPU;
-
CPU 收到 DMA 的信号,知道数据已经准备好,于是将数据从内核拷贝到用户空间,系统调用返回;
可以看到, 整个数据传输的过程,CPU 不再参与数据搬运的工作,而是全程由 DMA 完成,但是 CPU 在这个过程中也是必不可少的,因为传输什么数据,从哪里传输到哪里,都需要 CPU 来告诉 DMA 控制器。
早期 DMA 只存在在主板上,如今由于 I/O 设备越来越多,数据传输的需求也不尽相同,所以每个 I/O 设备里面都有自己的 DMA 控制器。
2. 普通的数据交互
如果服务端要提供文件传输的功能,我们能想到的最简单的方式是:将磁盘上的文件读取出来,然后通过网络协议发送给客户端。
传统 I/O 的工作方式是,数据读取和写入是从用户空间到内核空间来回复制,而内核空间的数据是通过操作系统层面的 I/O 接口从磁盘读取或写入。
代码通常如下,一般会需要两个系统调用:
read(file, tmp_buf, len);
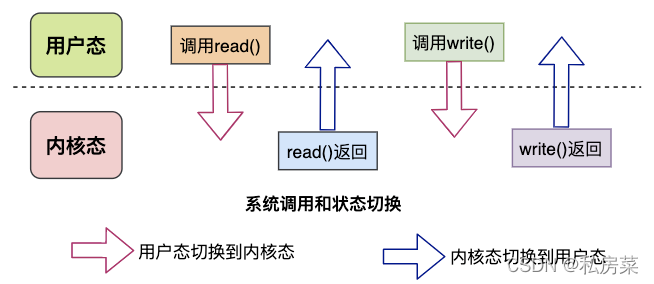
write(socket, tmp_buf, len);系统调用syscall是应用程序和内核交互的桥梁,每次进行调用/返回就会产生两次切换:
- 调用syscall 从用户态切换到内核态
- syscall返回 从内核态切换到用户态
来看下完整的数据拷贝过程简图:
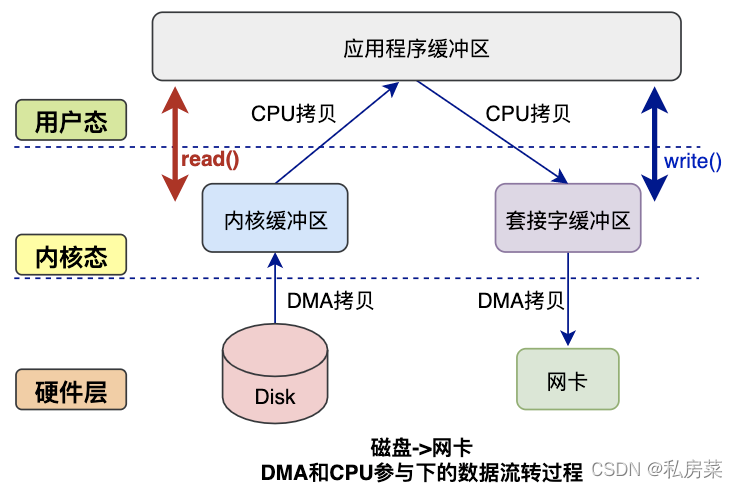
首先,期间共发生了 4 次用户态与内核态的上下文切换,因为发生了两次系统调用,一次是 read() ,一次是 write(),每次系统调用都得先从用户态切换到内核态,等内核完成任务后,再从内核态切换回用户态。
上下文切换到成本并不小,一次切换需要耗时几十纳秒到几微秒,虽然时间看上去很短,但是在高并发的场景下,这类时间容易被累积和放大,从而影响系统的性能。
其次,还发生了 4 次数据拷贝,其中两次是 DMA 的拷贝,另外两次则是通过 CPU 拷贝的,下面说一下这个过程:
-
第一次拷贝,把磁盘上的数据拷贝到操作系统内核的缓冲区里,这个拷贝的过程是通过 DMA 搬运的。
-
第二次拷贝,把内核缓冲区的数据拷贝到用户的缓冲区里,于是我们应用程序就可以使用这部分数据了,这个拷贝到过程是由 CPU 完成的。
-
第三次拷贝,把刚才拷贝到用户的缓冲区里的数据,再拷贝到内核的 socket 的缓冲区里,这个过程依然还是由 CPU 搬运的。
-
第四次拷贝,把内核的 socket 缓冲区里的数据,拷贝到网卡的缓冲区里,这个过程又是由 DMA 搬运的。
我们回过头看这个文件传输的过程,我们只是搬运一份数据,结果却搬运了 4 次,过多的数据拷贝无疑会消耗 CPU 资源,大大降低了系统性能。
3. 零拷贝技术
我们可以看到,如果应用程序不对数据做修改,从内核缓冲区到用户缓冲区,再从用户缓冲区到内核缓冲区。两次数据拷贝都需要CPU的参与,并且涉及用户态与内核态的多次切换,加重了CPU负担。
我们需要降低冗余数据拷贝、解放CPU,这也就是零拷贝Zero-Copy技术。
目前来看,零拷贝技术的几个实现手段包括:mmap+write、sendfile、sendfile+DMA收集、splice等。
3.1 mmap 方式
在前面我们知道,read() 系统调用的过程中会把内核缓冲区的数据拷贝到用户的缓冲区里,于是为了减少这一步开销,我们可以用 mmap() 替换 read() 系统调用函数。
buf = mmap(file, len);
write(sockfd, buf, len);mmap() 系统调用函数会直接把内核缓冲区里的数据「映射」到用户空间,这样,操作系统内核与用户空间就不需要再进行任何的数据拷贝操作。
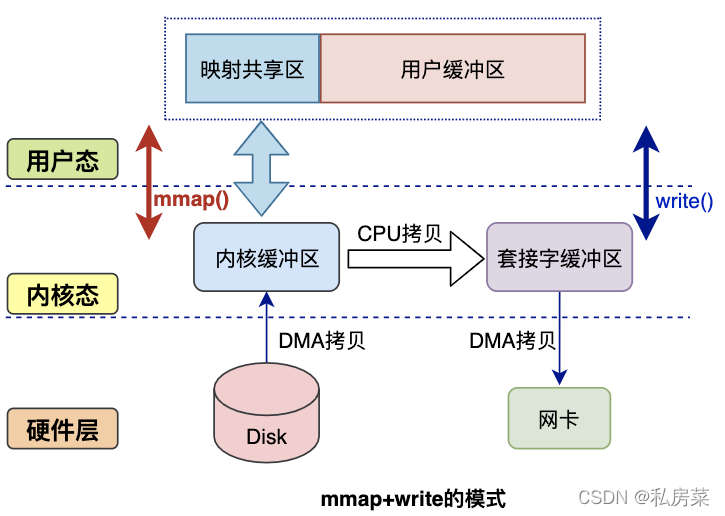
具体过程如下:
-
应用进程调用了
mmap()后,DMA 会把磁盘的数据拷贝到内核的缓冲区里。接着,应用进程跟操作系统内核「共享」这个缓冲区; -
应用进程再调用
write(),操作系统直接将内核缓冲区的数据拷贝到 socket 缓冲区中,这一切都发生在内核态,由 CPU 来搬运数据; -
最后,把内核的 socket 缓冲区里的数据,拷贝到网卡的缓冲区里,这个过程是由 DMA 搬运的。
我们可以得知,通过使用 mmap() 来代替 read(), 可以减少一次数据拷贝的过程。
但这还不是最理想的零拷贝,因为仍然需要通过 CPU 把内核缓冲区的数据拷贝到 socket 缓冲区里,而且仍然需要 4 次上下文切换,因为系统调用还是 2 次。
mmap对大文件传输有一定优势,但是小文件可能出现碎片,并且在多个进程同时操作文件时可能产生引发coredump的signal。
3.2 sendfile 方式
mmap+write方式有一定改进,但是由系统调用引起的状态切换并没有减少。
sendfile系统调用是在 Linux 内核2.1版本中被引入,它建立了两个文件之间的传输通道。
sendfile方式只使用一个函数就可以完成之前的read+write 和 mmap+write的功能,这样就少了2次状态切换,由于数据不经过用户缓冲区,因此该数据无法被修改。
#include
ssize_t sendfile(int out_fd, int in_fd, off_t *offset, size_t count); 它的前两个参数分别是目的端和源端的文件描述符,后面两个参数是源端的偏移量和复制数据的长度,返回值是实际复制数据的长度。
首先,它可以替代前面的 read() 和 write() 这两个系统调用,这样就可以减少一次系统调用,也就减少了 2 次上下文切换的开销。
其次,该系统调用,可以直接把内核缓冲区里的数据拷贝到 socket 缓冲区里,不再拷贝到用户态,这样就只有 2 次上下文切换,和 3 次数据拷贝。如下图:
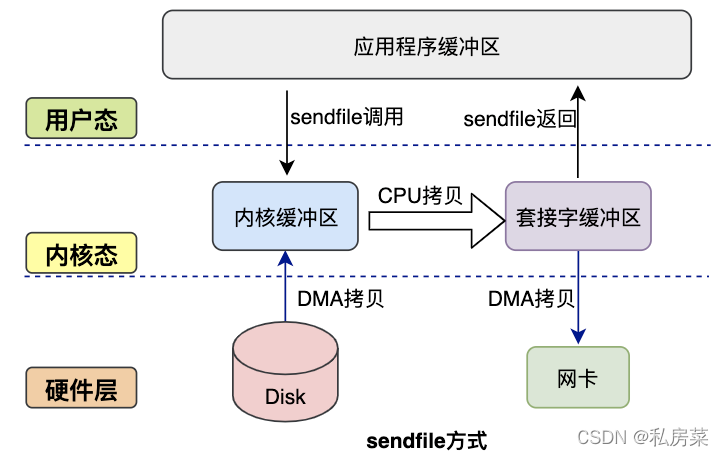
从图中可以看到,应用程序只需要调用sendfile函数即可完成,只有2次状态切换、1次CPU拷贝、2次DMA拷贝。
但是sendfile在内核缓冲区和socket缓冲区仍然存在一次CPU拷贝,或许这个还可以优化。
3.3 sendfile + DMA 收集
Linux 2.4 内核对 sendfile 系统调用进行优化,但是需要硬件DMA控制器的配合。
升级后的sendfile将内核空间缓冲区中对应的数据描述信息(文件描述符、地址偏移量等信息)记录到socket缓冲区中。
DMA控制器根据socket缓冲区中的地址和偏移量将数据从内核缓冲区拷贝到网卡中,从而省去了内核空间中仅剩1次CPU拷贝。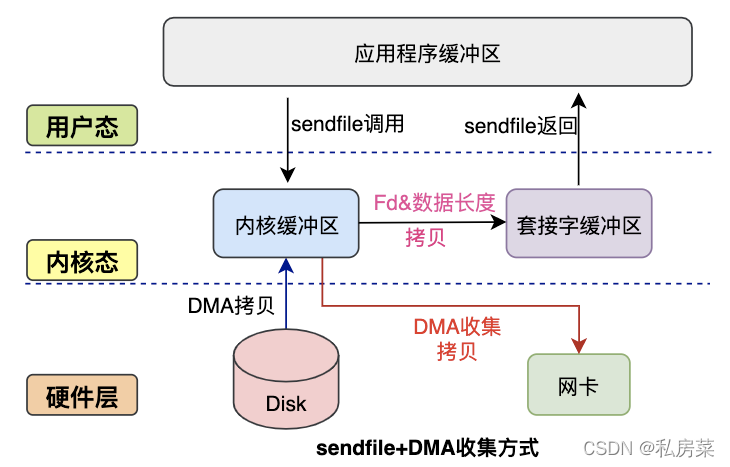
这就是所谓的零拷贝(Zero-copy)技术,因为我们没有在内存层面去拷贝数据,也就是说全程没有通过 CPU 来搬运数据,所有的数据都是通过 DMA 来进行传输的。
零拷贝技术的文件传输方式相比传统文件传输的方式,减少了 2 次上下文切换和数据拷贝次数,只需要 2 次上下文切换和数据拷贝次数,就可以完成文件的传输,而且 2 次的数据拷贝过程,都不需要通过 CPU,2 次都是由 DMA 来搬运。
所以,总体来看,零拷贝技术可以把文件传输的性能提高至少一倍以上。
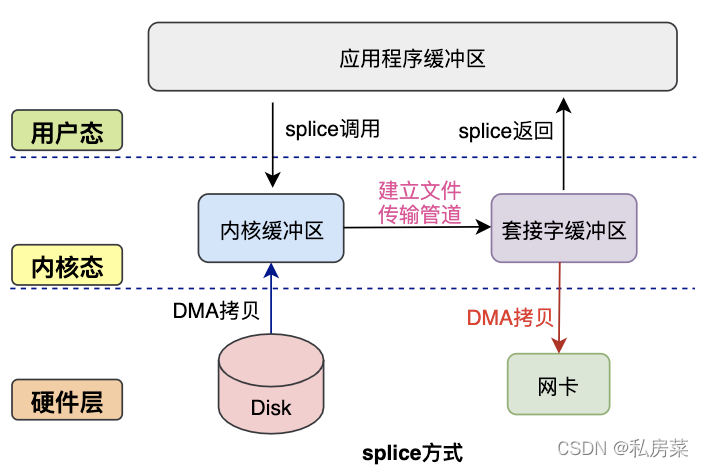
3.4 splice 方式
splice系统调用是Linux 在 2.6 版本引入的,其不需要硬件支持,并且不再限定于socket上,实现两个普通文件之间的数据零拷贝
#include
ssize_t splice(int fd_in, loff_t *off_in, int fd_out, loff_t *off_out, size_t len, unsigned int flags); splice 系统调用可以在内核缓冲区和socket缓冲区之间建立管道来传输数据,避免了两者之间的 CPU 拷贝操作。
splice也有一些局限,它的两个文件描述符参数中有一个必须是管道设备。
3.5 使用零拷贝技术的项目
事实上,Kafka 这个开源项目,就利用了「零拷贝」技术,从而大幅提升了 I/O 的吞吐率,这也是 Kafka 在处理海量数据为什么这么快的原因之一。
如果你追溯 Kafka 文件传输的代码,你会发现,最终它调用了 Java NIO 库里的 transferTo方法:
@Overridepublic
long transferFrom(FileChannel fileChannel, long position, long count) throws IOException { return fileChannel.transferTo(position, count, socketChannel);
}如果 Linux 系统支持 sendfile() 系统调用,那么 transferTo() 实际上最后就会使用到 sendfile() 系统调用函数。
曾经有大佬专门写过程序测试过,在同样的硬件条件下,传统文件传输和零拷拷贝文件传输的性能差异,你可以看到下面这张测试数据图,使用了零拷贝能够缩短 65% 的时间,大幅度提升了机器传输数据的吞吐量。
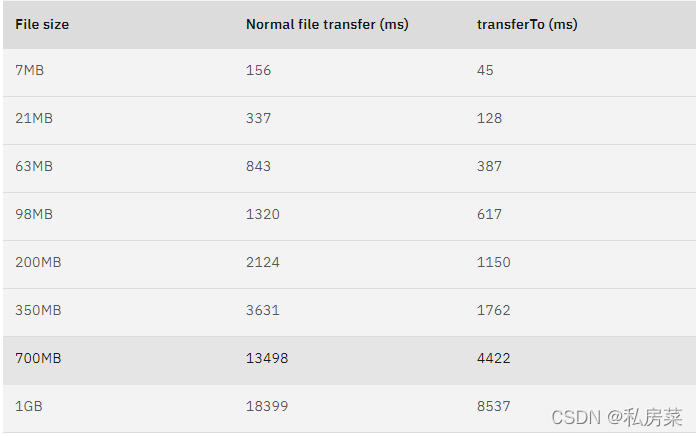
数据来源于:https://developer.ibm.com/articles/j-zerocopy/
4. Page Cache
回顾前面说道文件传输过程,其中第一步都是先需要先把磁盘文件数据拷贝「内核缓冲区」里,这个「内核缓冲区」实际上是磁盘高速缓存(Page Cache)。
由于零拷贝使用了 PageCache 技术,可以使得零拷贝进一步提升了性能,我们接下来看看 PageCache 是如何做到这一点的。
读写磁盘相比读写内存的速度慢太多了,所以我们应该想办法把「读写磁盘」替换成「读写内存」。于是,我们会通过 DMA 把磁盘里的数据搬运到内存里,这样就可以用读内存替换读磁盘。
但是,内存空间远比磁盘要小,内存注定只能拷贝磁盘里的一小部分数据。
那问题来了,选择哪些磁盘数据拷贝到内存呢?
我们都知道程序运行的时候,具有「局部性」,所以通常,刚被访问的数据在短时间内再次被访问的概率很高,于是我们可以用 PageCache 来缓存最近被访问的数据,当空间不足时淘汰最久未被访问的缓存。
还有一点,读取磁盘数据的时候,需要找到数据所在的位置,但是对于机械磁盘来说,就是通过磁头旋转到数据所在的扇区,再开始「顺序」读取数据,但是旋转磁头这个物理动作是非常耗时的,为了降低它的影响,PageCache 使用了「预读功能」(PAGE_READAHEAD)。
比如,假设 read 方法每次只会读 32 KB 的字节,虽然 read 刚开始只会读 0 ~ 32 KB 的字节,但内核会把其后面的 32~64 KB 也读取到 PageCache,这样后面读取 32~64 KB 的成本就很低,如果在 32~64 KB 淘汰出 PageCache 前,进程读取到它了,收益就非常大。
所以,PageCache 的优点主要是两个:
-
缓存最近被访问的数据;
-
预读功能;
这两个做法,将大大提高读写磁盘的性能。
但是,在传输大文件(GB 级别的文件)的时候,PageCache 会不起作用,那就白白浪费 DMA 多做的一次数据拷贝,造成性能的降低,即使使用了 PageCache 的零拷贝也会损失性能
这是因为如果你有很多 GB 级别文件需要传输,每当用户访问这些大文件的时候,内核就会把它们载入 PageCache 中,于是 PageCache 空间很快被这些大文件占满。
另外,由于文件太大,可能某些部分的文件数据被再次访问的概率比较低,这样就会带来 2 个问题:
-
PageCache 由于长时间被大文件占据,其他「热点」的小文件可能就无法充分使用到 PageCache,于是这样磁盘读写的性能就会下降了;
-
PageCache 中的大文件数据,由于没有享受到缓存带来的好处,但却耗费 DMA 多拷贝到 PageCache 一次;
所以,针对大文件的传输,不应该使用 PageCache,也就是说不应该使用零拷贝技术,因为可能由于 PageCache 被大文件占据,而导致「热点」小文件无法利用到 PageCache,这样在高并发的环境下,会带来严重的性能问题。
4.1 如何查看系统page cache
通过读取/proc/meminfo 节点可以获取系统的内存情况:
shift:/ # cat /proc/meminfo
MemTotal: 2671980 kB
MemFree: 165672 kB
MemAvailable: 1524260 kB
Buffers: 24024 kB
Cached: 1383552 kB
SwapCached: 0 kB
Active: 913012 kB
Inactive: 1072464 kB
Active(anon): 457344 kB
Inactive(anon): 134480 kB
Active(file): 455668 kB
Inactive(file): 937984 kB
Unevictable: 9160 kB
Mlocked: 9160 kB
Shmem: 5472 kB- 如果不考虑mlock的话,一个更符合逻辑的等式是:
公式一:
【Active(file) + Inactive(file) + Shmem + SwapCached】 = 【Cached + Buffers + SwapCached】两边的等式都是Page Cache,即:
公式二:
Page Cache = 【Cached + Buffers + SwapCached】由公式一可以推论出:
公式三:
Cached = Active(file) + Inactive(file) + Shmem - Buffers- 如果有mlock的话,等式应该如下(mlock包括file和anon两部分,/proc/meminfo中并未分开统计,下面的mlock_file只是用来表意,实际并没有这个统计值):
公式四:
【Active(file) + Inactive(file) + Shmem + Mlocked + SwapCached】 = 【Cached + Buffers + SwapCached】由公式四可以推论出:
公式三:
Cached = Active(file) + Inactive(file) + Shmem + Mlocked - Buffers4.2 page 与Page Cache
page 是linux 内存管理分配的基本单位,一般一个page 为4K大小。
Page Cache 是由多个page 组成,是4K 的整数倍。
另外,不是所有的page 都可以组成Page Cache,Linux 系统上供用户可访问的内存分为:
- File-backed pages:与文件对应的pages,也就是Page Cache 中的pages,这些页最大的问题就是脏页回盘;
File-backed pages 内存回收的代价比价低,Page Cache 通常对应于一个文件上的若干顺序块,因此可以通过顺序 I/O 的方式落盘。另一方面,如果 Page Cache 上没有进行写操作(所谓的没有脏页),甚至不会将 Page Cache 回盘,因为数据的内容完全可以通过再次读取磁盘文件得到。
- Anonymous pages:匿名pages,进程在运行时堆栈需要分配的内存空间;
Anonymous pages 内存回收代价比较高,这是因为 Anonymous pages 通常随机地写入持久化交换设备。另一方面,无论是否有更操作,为了确保数据不丢失,Anonymous pages 在 swap 时必须持久化到磁盘。
更多可以查看:Linux 内核Page Cache 和Buffer Cache 关系及演化历史
5. Buffer Cache
Buffer cache 又称为块缓冲,是对物理磁盘上的一个磁盘块进行的缓冲,其大小通常为1k,磁盘块页是磁盘的组织单位。设立buffer cache 的目的是为了在程序多次访问同一个磁盘时,减少访问时间。程序将磁盘块读入buffer cache,在下一次访问磁盘时首先看是否在buffer cache 中找到磁盘块,命中可以减少访问磁盘时间。不命中则需要重新读入到buffer cache 中。
磁盘的最小数据单位为sector,每次读写磁盘都是以sector 为单位对磁盘进行操作。sector大小跟具体的磁盘类型有关,有的为512B,有的是4KB。无论用户是希望读取1个byte,还是10个byte,最终访问磁盘时,都必须以sector为单位读取,如果裸读磁盘,那意味着数据读取的效率会非常低。
同样,如果用户希望向磁盘某个位置写入(更新)1个byte的数据,他也必须整个刷新一个sector,言下之意,则是在写入这1个byte之前,我们需要先将该1byte所在的磁盘sector数据全部读出来,在内存中,修改对应的这1个byte数据,然后再将整个修改后的sector数据,一口气写入磁盘。
为了降低这类低效访问,尽可能的提升磁盘访问性能,内核会在磁盘sector上构建一层缓存,他以sector的整数倍力度单位(block),缓存部分sector数据在内存中,当有数据读取请求时,他能够直接从内存中将对应数据读出。当有数据写入时,他可以直接再内存中直接更新指定部分的数据,然后再通过异步方式,把更新后的数据写回到对应磁盘的sector中。这层缓存则是块缓存Buffer Cache。
对buffer cache 的写分两种:
- 直接写,程序在写buffer cache 后也写磁盘,要读时从buffer cache 上读;
- 后台写,程序在写完buffer cache 后,并不立即写磁盘,因为有可能程序在很短时间内又需要写文件。如果直接写,就需要多次写磁盘,效率比较低。
简单说来,page cache用来缓存文件数据,buffer cache用来缓存磁盘数据。在有文件系统的情况下,对文件操作,那么数据会缓存到page cache,如果直接采用dd等工具对磁盘进行读写,那么数据会缓存到buffer cache。
因此 Page Cache 是与文件系统同级的;块是物理上的概念。
Page Cache 与 buffer cache 的共同目的都是加速数据 I/O:写数据时首先写到缓存,将写入的页标记为 dirty,然后向外部存储 flush,也就是缓存写机制中的 write-back(另一种是 write-through,Linux 默认情况下不采用);读数据时首先读取缓存,如果未命中,再去外部存储读取,并且将读取来的数据也加入缓存。操作系统总是积极地将所有空闲内存都用作 Page Cache 和 buffer cache,当内存不够用时也会用 LRU 等算法淘汰缓存页。
在 Linux 2.4 版本的内核之前,Page Cache 与 buffer cache 是完全分离的。但是,块设备大多是磁盘,磁盘上的数据又大多通过文件系统来组织,这种设计导致很多数据被缓存了两次,浪费内存。所以在 2.4 版本内核之后,两块缓存近似融合在了一起:如果一个文件的页加载到了 Page Cache,那么同时 buffer cache 只需要维护块指向页的指针就可以了。只有那些没有文件表示的块,或者绕过了文件系统直接操作(如dd命令)的块,才会真正放到 buffer cache 里。因此,我们现在提起 Page Cache,基本上都同时指 Page Cache 和 buffer cache 两者,本文之后也不再区分,直接统称为 Page Cache。
更多可以查看:Linux 内核Page Cache 和Buffer Cache 关系及演化历史
6. 大文件传输的实现方式
上面一节说到对于大文件传输如果使用Page Cache 会带来性能问题,那针对大文件的传输,我们应该使用什么方式呢?
我们先来看看最初的例子,当调用 read 方法读取文件时,进程实际上会阻塞在 read 方法调用,因为要等待磁盘数据的返回,如下图:
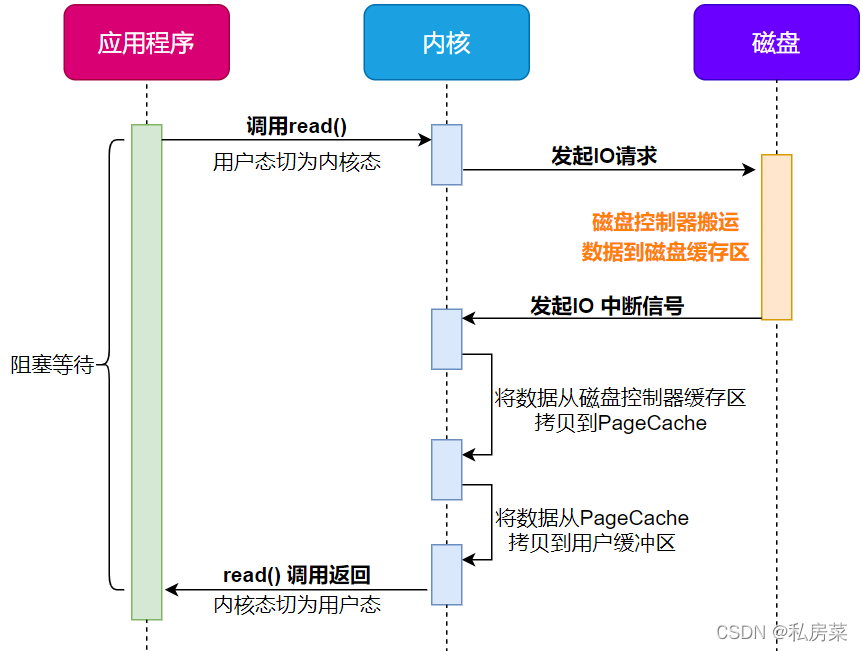
具体过程:
-
当调用 read 方法时,会阻塞着,此时内核会向磁盘发起 I/O 请求,磁盘收到请求后,便会寻址,当磁盘数据准备好后,就会向内核发起 I/O 中断,告知内核磁盘数据已经准备好;
-
内核收到 I/O 中断后,就将数据从磁盘控制器缓冲区拷贝到 PageCache 里;
-
最后,内核再把 PageCache 中的数据拷贝到用户缓冲区,于是 read 调用就正常返回了。
对于阻塞的问题,可以用异步 I/O 来解决,它工作方式如下图:
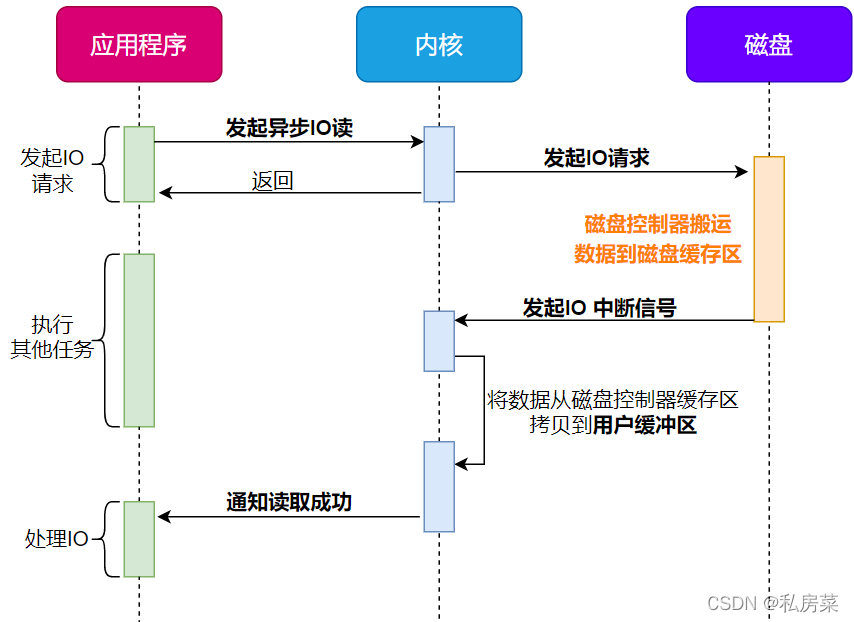
它把读操作分为两部分:
-
前半部分,内核向磁盘发起读请求,但是可以不等待数据就位就可以返回,于是进程此时可以处理其他任务;
-
后半部分,当内核将磁盘中的数据拷贝到进程缓冲区后,进程将接收到内核的通知,再去处理数据;
而且,我们可以发现,异步 I/O 并没有涉及到 PageCache,所以使用异步 I/O 就意味着要绕开 PageCache。
绕开 PageCache 的 I/O 叫直接 I/O,使用 PageCache 的 I/O 则叫缓存 I/O。通常,对于磁盘,异步 I/O 只支持直接 I/O。
前面也提到,大文件的传输不应该使用 PageCache,因为可能由于 PageCache 被大文件占据,而导致「热点」小文件无法利用到 PageCache。
于是,在高并发的场景下,针对大文件的传输的方式,应该使用「异步 I/O + 直接 I/O」来替代零拷贝技术。
直接 I/O 应用场景常见的两种:
-
应用程序已经实现了磁盘数据的缓存,那么可以不需要 PageCache 再次缓存,减少额外的性能损耗。在 MySQL 数据库中,可以通过参数设置开启直接 I/O,默认是不开启;
-
传输大文件的时候,由于大文件难以命中 PageCache 缓存,而且会占满 PageCache 导致「热点」文件无法充分利用缓存,从而增大了性能开销,因此,这时应该使用直接 I/O。
另外,由于直接 I/O 绕过了 PageCache,就无法享受内核的这两点的优化:
-
内核的 I/O 调度算法会缓存尽可能多的 I/O 请求在 PageCache 中,最后「合并」成一个更大的 I/O 请求再发给磁盘,这样做是为了减少磁盘的寻址操作;
-
内核也会「预读」后续的 I/O 请求放在 PageCache 中,一样是为了减少对磁盘的操作;
于是,传输大文件的时候,使用「异步 I/O + 直接 I/O」了,就可以无阻塞地读取文件了。
所以,传输文件的时候,我们要根据文件的大小来使用不同的方式:
-
传输大文件的时候,使用「异步 I/O + 直接 I/O」;
-
传输小文件的时候,则使用「零拷贝技术」;
参考:
https://mp.weixin.qq.com/s/oPv1-wrhYjiOC1o0M0tjMA
linux dma 拷贝内存数据_彻底搞懂零拷贝ZeroCopy技术
Linux 内核Page Cache 和Buffer Cache 关系及演化历史
本文来自互联网用户投稿,文章观点仅代表作者本人,不代表本站立场,不承担相关法律责任。如若转载,请注明出处。 如若内容造成侵权/违法违规/事实不符,请点击【内容举报】进行投诉反馈!