《SQL必知必会(第4版)》读书笔记【全22课】
目录
- 内容提要&相关资源
- 正文
- 第1课 了解SQL
- 数据库基础
- 什么是SQL
- 第2课 检索数据
- 第3课 排序检索数据 ORDER BY
- 第4课 过滤数据
- 第5课 高级数据过滤
- 第6课 用通配符进行过滤
- 第7课 创建计算字段
- 第8课 使用函数处理数据
- 第9课 汇总数据
- 第10课 分组数据 GROUP BY & HAVING
- 第11课 使用子查询
- 第12课 联结表 JOIN
- 第13课 创建高级联结
- 第14课 组合查询 UNION
- 第15课 插入数据
- 数据插入 INSERT
- 从一个表复制到另一个表 SELECT INTO
- 第16课 更新和删除数据
- 更新数据 UPDATE
- 删除数据 DELETE
- 第17课 创建和操纵表
- 创建表 CREATE TABLE
- 更新表 ALTER TABLE
- 删除表 DROP TABLE
- 重命名表
- 第18课 使用视图
- 第19课 使用存储过程
- 第20课 管理事务处理(transaction processing)
- 第21课 使用游标(cursor)
- 第22课 高级SQL特性
- 约束
- 主键
- 外键
- 唯一约束
- 检查约束
- 索引
- 触发器
- 数据库安全
内容提要&相关资源
- 本书由浅入深地讲解了 SQL的基本概念和语法,涉及数据的排序、过滤和分组,以及表、视图、联结、子查询、游标、存储过程和触发器等内容,实例丰富,便于查阅。
- 新版增加了针对 Apache Open Office Base、MariaDB、SQLite 等 DBMS 的描述,并根据最新版本的 Oracle、SQL Server、MySQL 和 PostgreSQL 更新了相关示例。
- 本书适合SQL初学者。
- 英文原版勘误表: Errata: Sams Teach Yourself SQL in 10 Minutes (Fourth Edition).
- 英文原版第5版:Sams Teach Yourself SQL in 10 Minutes (Fifth Edition)
正文
第1课 了解SQL
数据库基础
- 数据库(database):保存有组织的数据的容器(通常是一个文件或一组文件)。
- 数据库软件:数据库管理系统(DBMS/Database Management System)。
数据库是通过DBMS创建和操纵的容器。
- 表(table):某种特定类型的结构化清单。
数据库名和表名的组合是唯一的,即在相同数据库中表名唯一不可重复,但在不同数据库中可使用相同表名。 - 模式(schema):关于数据库和表的布局及特性的信息。
模式可用来描述数据库中特定的表,也可以用来描述整个数据库(和其中表的关系)。
- 列(column):表中的一个字段。所有表都是由一个或多个列组成的。
- 数据类型(datatype):所允许的数据的类型。每个表列都有相应的数据类型,它限制(或允许)该列中存储的数据。
不同的DBMS中,相同的数据类型可能有不同的名称。 - 行(row):表中的一个记录。
- 主键(primary key):一列(或一组列),其值能够唯一标识表中的每一行。
应该总是定义主键。 - 主键需要满足的条件:
- 任意两行都不具有相同的主键值(Not Null)
- 每一行都必须具有一个主键值
- 主键列中的值不允许修改或更新
- 主键值不能重用(如果删去某行,不可将它的主键赋给以后的新行)
主键可以是多个列的组合,多列作为主键时,它们及它们的组合必须满足以上条件,它们的组合必须是唯一的,但单个列的值可以不唯一。
- 外键
什么是SQL
SQL(sequel)是Structured Query Language(结构化查询语言)的缩写,是一种专门用来与数据库沟通的语言。
第2课 检索数据
检索单个列
SELECT prod_name
FROM Products;
- 默认不排序
- 以分号分隔多条SQL语句
- SQL语句不区分大小写,但一般关键字大写,列名表名小写
- 是否换行无影响,但分成多行更利于阅读调试
检索多个列
SELECT prod_id, prod_name, prod_price
FROM Products;
- 选择多个列时,记得在列名间加上逗号,但最后一个列名后不加
检索所有列
SELECT *
FROM Products;
- 通配符(*)
检索不同的值 DISTINCT
SELECT DISTINCT vend_id
FROM Products;
- DISTINCT作用于所有的列,不仅仅是跟在其后的那一列.
限制结果
- SQL Server、 Access - TOP
SELECT TOP 5 prod_name
FROM Products;
- DB2
SELECT prod_name
FROM Products
FETCH FIRST 5 ROWS ONLY;
- Oracle
SELECT prod_name
FROM Products
WHERE ROWNUM <=5;
- MySQL、MariaDB、PostgreSQL、SQLite - LIMIT
SELECT prod_name
FROM Products
LIMIT 6 OFFSET 5;
-- 返回从第6行起的5行数据,即第7、8、9、10、11行
-- 在MySQL和MariaDB中,可省略OFFSET,即 LIMIT 5,6,逗号前的值对应OFFSET,逗号后的值对应LIMIT/* 给代码加注释的方法
SELECT prod_name, vend_id
FROM Products; */
第3课 排序检索数据 ORDER BY
- 子句(clause): SQL语句由子句构成,有些子句是必需的,有些则是可选的。一个子 句通常由一个关键字加上所提供的数据组成。
- ORDER BY 必须是SELECT语句中的最后一条子句;
- 可用非检索的列排序数据;
- 可按照多个列排序,排序顺序按规定进行
- 可按照列位置排序:
SELECT prod_id, prod_price, prod_name
FROM Products
ORDER BY 2, 3;
-- 按照列的相对位置对应列排序,即按照SELECT中的第二列prod_price、第三列prod_name排序
-- 按照这种方法将无法按照不在SELECT清单中的列排序
-- 两种排序方法(实际列名、相对列位置)可以混合使用
- 默认升序ASC,可使用DESC关键字进行降序。DESC关键字之应用到直接位于其前面的列名,如果想在多个列上进行降序排序,必须对每一列制定DESC关键字;
第4课 过滤数据
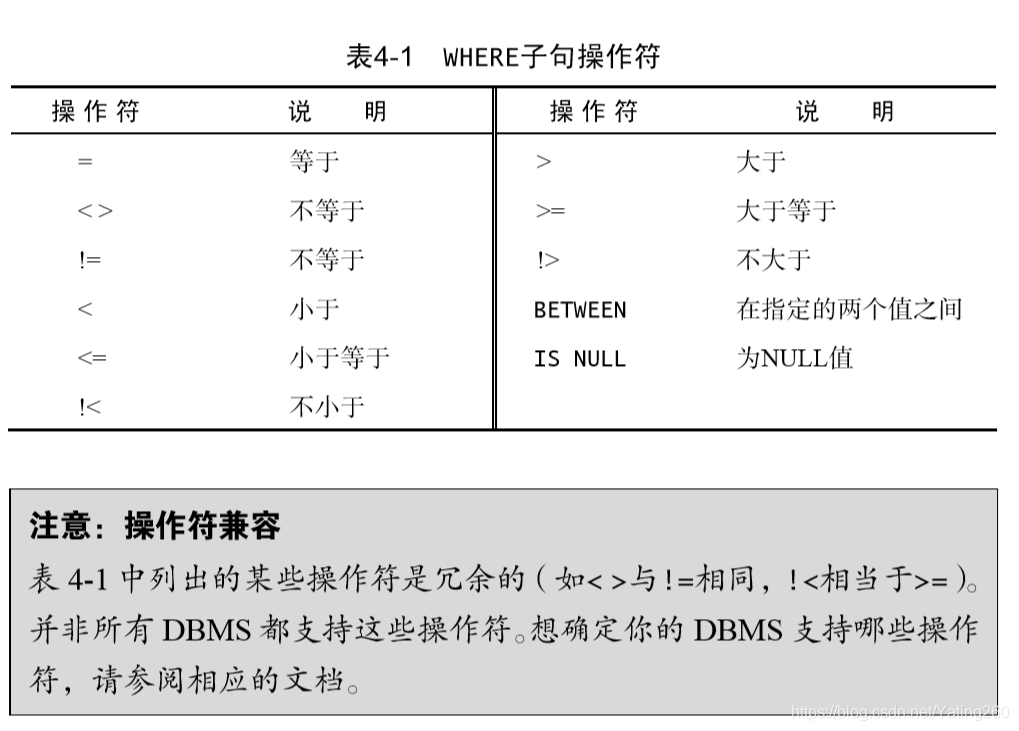
搜索条件(search criteria)/ 过滤条件(filter condition)
WHERE
SELECT prod_name, prod_price
FROM Products
WHERE prod_price BETWEEN 5 AND 10; SELECT prod_name
FROM Products
WHERE prod_price IS NULL;
第5课 高级数据过滤
- 操作符(operator): 用来联结或改变 WHERE 子句中的子句的关键字,也称为逻辑操作符 (logical operator)。
| 操作符 | 定义 |
|---|---|
| AND | 用在 WHERE 子句中的关键字,用来指示检索满足所有给定条件的行 |
| OR | WHERE 子句中使用的关键字,用来表示检索匹配任一给定条件的行 |
| 注意 | SQL默认优先处理AND,后处理OR;所以最好用括号明确分组操作符以避免错误。 |
| IN | WHERE 子句中用来指定要匹配值的清单的关键字,功能与 OR 相当 |
| NOT | WHERE 子句中用来否定其后条件的关键字 |
| 说明 | MariaDB 中的 NOT MariaDB 支持使用 NOT 否定 IN、BETWEEN 和 EXISTS 子句。大多数 DBMS允许使用 NOT 否定任何条件。 |
SELECT prod_name, prod_price
FROM Products
WHERE (vend_id = 'DLL01' OR vend_id = 'BRS01')AND prod_price >= 10; SELECT prod_name, prod_price
FROM Products
WHERE vend_id IN ( 'DLL01', 'BRS01' )
ORDER BY prod_name; SELECT prod_name
FROM Products
WHERE NOT vend_id = 'DLL01'
ORDER BY prod_name;
第6课 用通配符进行过滤
- 通配符(wildcard):用来匹配值的一部分的特殊字符。
通配符本身实际上是 SQL的 WHERE 子句中有特殊含义的字符。
通配符搜索只能用于文本字段(字符串),非文本数据类型字段不能使用 通配符搜索。 - 搜索模式(search pattern):由字面值、通配符或两者组合构成的搜索条件。
LIKE操作符
| 通配符 | 含义 | 注意 |
|---|---|---|
| 百分号(%) | 表示任何字符出现任意次数 | % 代表搜索模式中给定位置的0个、1个或多个字符; %不会匹配为 NULL 的行 |
| 下划线(_) | 只匹配单个字符 | _总是刚好匹配一个字符,不能多也不能少 |
| 方括号([]) | 用来指定一个字符集,它必须匹配指定位置(通配符的位置)的一个字符 | 此通配符可以用前缀字符^(脱字号)来否定;只有微软的 Access 和 SQL Server 支持集合 |
SELECT prod_id, prod_name
FROM Products
WHERE prod_name LIKE 'Fish%';
-- 检索任意以Fish起头的词,%告诉 DBMS接受 Fish 之后的任意字符,不管它有多少字符。
-- 说明:Access 通配符如果使用的是 Microsoft Access,需要使用*而不是%。
-- 说明:区分大小写 根据 DBMS的不同及其配置,搜索可以是区分大小写的。SELECT prod_id, prod_name
FROM Products
WHERE prod_name LIKE '%bean bag%';
-- 搜索模式'%bean bag%'表示匹配任何位置上包含文本 bean bag 的值,不论它之前或之后出现什么字符。 SELECT prod_id, prod_name
FROM Products
WHERE prod_name LIKE '__ inch teddy bear'; -- 两个下划线
-- 这个 WHERE 子句中的搜索模式给出了后面跟有文本的两个通配符。
-- 结果只显示匹配搜索模式的行,如“12 inch teddy bear ”、“18 inch teddy bear ”,因为搜索模式要求匹配两个通配符。
-- 说明:DB2 通配符 DB2不支持通配符_。
-- 说明:Access 通配符 如果使用的是 Microsoft Access,需要使用?而不是_。 FROM Customers
WHERE cust_contact LIKE '[JM]%'
ORDER BY cust_contact;
-- 此语句的WHERE子句中的模式为'[JM]%'。这一搜索模式使用了两个不同的通配符。
-- [JM]匹配方括号中任意一个字符,它也只能匹配单个字符。因此,任何多于一个字符的名字都不匹配。
-- [JM]之后的%通配符匹配第 一个字符之后的任意数目的字符,返回所需结果。
- 不要过度使用通配符。如果其他操作符能达到相同的目的,应该使用其他操作符。
- 在确实需要使用通配符时,也尽量不要把它们用在搜索模式的开始处。把通配符置于开始处,搜索起来是最慢的。
- 仔细注意通配符的位置。如果放错地方,可能不会返回想要的数据。
第7课 创建计算字段
- 字段(field):基本上与列(column)的意思相同,经常互换使用,不过数据库列一般称为列,而术语字段通常与计算字段一起使用。
计算字段并不实际存在于数据库表中。计算字段是运行时在 SELECT 语句内创建的。 - 拼接(concatenate):将值联结到一起(将一个值附加到另一个值)构成单个值。
| DBMS | 拼接 |
|---|---|
| Access、SQL Server | + |
| DB2、Oracle、PostgreSQL、SQLite、Open Office Base | II |
SELECT vend_name + ' (' + vend_country + ')'
FROM Vendors
ORDER BY vend_name; SELECT vend_name || ' (' || vend_country || ')'
FROM Vendors
ORDER BY vend_name; SELECT Concat(vend_name, ' (', vend_country, ')') --MySQL、MariaDB
FROM Vendors
ORDER BY vend_name;
去除值右边的所有空格 RTRIM()
许多数据库(不是所有)保存填充为列宽的文本值,而实际上你要的结果不需要这些空格。为正确返回格式化的数据,必须去掉这些空格。这可以使用 SQL的 RTRIM()函数来完成,如下所示:
SELECT RTRIM(vend_name) + ' (' + RTRIM(vend_country) + ')' -- 去掉vend_name和vend_country中的多余空格
FROM Vendors
ORDER BY vend_name;
- TRIM 函数
| 函数 | 用法 |
|---|---|
| TRIM() | 去掉字符串左右两边的空格 |
| RTRIM() | 去掉字符串右边的空格 |
| LTRIM() | 去掉字符串左边的空格 |
- 别名(alias)/ 导出列(derived column) AS
第8课 使用函数处理数据

文本处理函数
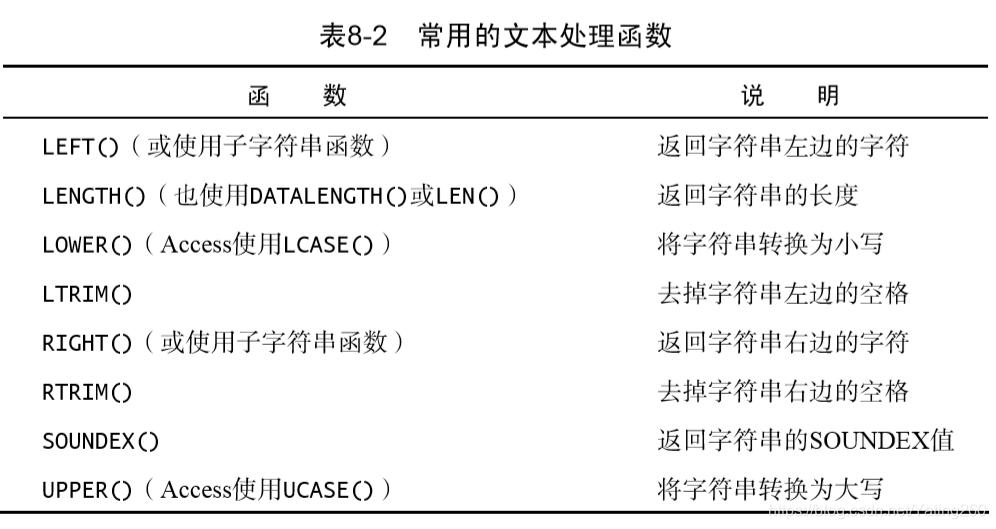
SOUNDEX 是一个将任何文本串转换为描述其语音表示的字母数字模式的算法。用以检索所有发音类似于检索内容的行。
Microsoft Access和 PostgreSQL不支持 SOUNDEX()。
SELECT cust_name, cust_contact
FROM Customers
WHERE SOUNDEX(cust_contact) = SOUNDEX('Michael Green');
输出:
| cust_name | cust_contact |
|---|---|
| Kids Place | Michelle Green |
日期和时间处理函数
每种DBMS都有自己的特殊形式,日期和时间函数在不同的DBMS中也差别很大,可移植性很差。以检索2012年的所有订单为例:
| DBMS | 函数 |
|---|---|
| SQL Server | WHERE DATEPART(yy, order_date) = 2012 |
| Access | WHERE DATEPART(‘yyyy’, order_date) = 2012 |
| PostgreSQL | WHERE DATE_PART(‘year’, order_date) = 2012 |
| Oracle | WHERE to_number(to_char(order_date, ‘YYYY’)) = 2012; WHERE order_date BETWEEN to_date(‘01-01-2012’) AND to_date(‘12-31-2012’); |
| MySQL MariaDB | WHERE YEAR(order_date) = 2012 |
| SQLite | WHERE strftime(’%Y’, order_date) = ‘2012’; |
数值处理函数

第9课 汇总数据
- 聚集函数(aggregate function):对某些行运行的函数,计算并返回一个值。
| 函数 | 说明 | 注意 |
|---|---|---|
| AVG() | 返回某列平均值 | 1. 只能用来确定特定数值列的平均值; 2. 忽略列值为NULL的行 |
| COUNT() | 返回某列行数 | 1.COUNT(*)对表中行的数目进行计数,不管表列中是否包含NULL; 2. COUNT(column)对特定列中具有值的行计数,忽略NULL |
| MAX() | 返回某列最大值 | 1. 可对非数值数据使用:在用于文本数据时,MAX()返回按该列排序后的最后一行; 2. 忽略列值为 NULL 的行 |
| MIN() | 返回某列最小值 | 同上 |
| SUM() | 返回某列值之和 | 1. 可合计计算值,如SUM(item_price*quantity); 2. 忽略列值为 NULL 的行 |
- 对所有行执行计算,指定 ALL 参数或不指定参数(因为 ALL 是默认行为)
- 只包含不同的值,指定 DISTINCT 参数
- Microsoft Access在聚集函数中不支持 DISTINCT
第10课 分组数据 GROUP BY & HAVING
规定:
- GROUP BY 子句可以包含任意数目的列,因而可以对分组进行嵌套,更细致地进行数据分组。
- 如果在 GROUP BY 子句中嵌套了分组,数据将在后指定的分组上进行汇总。换句话说,在建立分组时,指定的所有列都一起计算(所以不能从个别的列取回数据)。
- GROUP BY 子句中列出的每一列都必须是检索列或有效的表达式(但不能是聚集函数)。如果在 SELECT 中使用表达式,则必须在 GROUP BY 子句中指定相同的表达式。不能使用别名。
- 大多数 SQL实现不允许 GROUP BY 列带有长度可变的数据类型(如文本或备注型字段)。
- 除聚集计算语句外,SELECT 语句中的每一列都必须在 GROUP BY 子句中给出。
- 如果分组列中包含具有 NULL 值的行,则 NULL 将作为一个分组返回。 如果列中有多行 NULL 值,它们将分为一组。
- GROUP BY 子句必须出现在 WHERE 子句之后,ORDER BY 子句之前。
HAVING 和 WHERE 的差别:
WHERE 在数据分组前进行过滤,HAVING 在数 据分组后进行过滤。这是一个重要的区别,WHERE 排除的行不包括在分组中。这可能会改变计算值,从而影响 HAVING 子句中基于这些值过滤掉的分组。


第11课 使用子查询
- 查询(query):任何 SQL语句都是查询。但此术语一般指 SELECT 语句。
- 子查询(subquery)
在 SELECT 语句中,子查询总是从内向外处理。
作为子查询的 SELECT 语句只能查询单个列。企图检索多个列将返回错误。
完全限定列名:指定表名和列名,如Orders.cust_id
第12课 联结表 JOIN
关系表的设计就是要把信息分解成多个表,一类数据一个表。各 表通过某些共同的值互相关联(所以才叫关系数据库)。
可伸缩(scale):能够适应不断增加的工作量而不失败。设计良好的数据库或应用程序称为可伸缩性好(scale well)。
关系数据可以有效地存储,方便地处理。因此,关系数据库的可伸缩性远比非关系数据库要好。
联结是一种机制,用来在一条 SELECT 语句中关联表,因此称为联结。
联结不是物理实体,它在实际的数据库表 中并不存在。DBMS会根据需要建立联结,它在查询执行期间一直存在。
内联结(等值连接)
-
笛卡儿积(cartesian product):由没有联结条件的表关系返回的结果为笛卡儿积。检索出的行的数目将是第一个表中的行数乘以第二个表中的行数。
有时,返回笛卡儿积的联结,也称叉联结(cross join)。 -
INNER JOIN
SELECT vend_name, prod_name, prod_price
FROM Vendors
INNER JOIN Products
ON Vendors.vend_id = Products.vend_id; 第13课 创建高级联结
表别名:
- 缩短SQL语句;
- 允许在一条SELECT语句中多次使用相同的表。
SELECT cust_name, cust_contact
FROM Customers AS C, Orders AS O, OrderItems AS OI
WHERE C.cust_id = O.cust_id
AND OI.order_num = O.order_num
AND prod_id = 'RGAN01';
-- Oracle中没有AS,可直接省略AS,如"Customers C"。
| 联结类型 | 内容 |
|---|---|
| 自联结(self-join) | 自联结通常作为外部语句,用来替代从相同表中检索数据的使用子查 询语句。 |
| 自然联结(natural join) | 自然联结排除多次出现,使每一列只能返回一次。 一般通过对一个表使用通配符(SELECT *),而对其他表的列使用明确的子集来完成。 |
| 外联结(outer join) | 包含了那些在相关表中没有关联行的行。 在使用 OUTER JOIN 语法时,必须使用 RIGHT 或 LEFT 关键字指定包括其所有行的表 (RIGHT 指出的是 OUTER JOIN 右边的表,而 LEFT 指出的是 OUTER JOIN 左边的表)。还存在另一种外联结,就是全外联结(full outer join),它检索两个表中的所有行并关联那些可以关联的行。 |
- Access、MariaDB、MySQL、Open Office Base和 SQLite不支持 FULL OUTER JOIN 语法。
使用联结和联结条件
- 注意所使用的联结类型。一般我们使用内联结,但使用外联结也有效。
- 关于确切的联结语法,应该查看具体的文档,看相应的DBMS支持何 种语法(大多数 DBMS使用这两课中描述的某种语法)。
- 保证使用正确的联结条件(不管采用哪种语法),否则会返回不正确的数据。
- 应该总是提供联结条件,否则会得出笛卡儿积。
- 在一个联结中可以包含多个表,甚至可以对每个联结采用不同的联结类型。虽然这样做是合法的,一般也很有用,但应该在一起测试它们前分别测试每个联结。这会使故障排除更为简单。
第14课 组合查询 UNION
- 并(union)/ 复合查询(compound query):执行多个查询(多条SELECT语句),并将结果作为一个查询结果集返回。
使用场景:
- 在一个查询中从不同的表返回结构数据;
- 对一个表执行多个查询,按一个查询返回数据。 (多数情况下相同于多个WHERE子句)
SELECT cust_name, cust_contact, cust_email
FROM Customers
WHERE cust_state IN ('IL','IN','MI')
UNION
SELECT cust_name, cust_contact, cust_email
FROM Customers
WHERE cust_name = 'Fun4All'; -- 等同于:SELECT cust_name, cust_contact, cust_email
FROM Customers
WHERE cust_state IN ('IL','IN','MI')
OR cust_name = 'Fun4All';
UNION规则:
- UNION 必须由两条或两条以上的 SELECT 语句组成,语句之间用关键字UNION分隔(因此,如果组合四条SELECT语句,将要使用三个UNION 关键字)。
- UNION 中的每个查询必须包含相同的列、表达式或聚集函数(不过, 各个列不需要以相同的次序列出)。
- 列数据类型必须兼容:类型不必完全相同,但必须是 DBMS可以隐含 转换的类型(例如,不同的数值类型或不同的日期类型)。
- UNION从查询结果集中自动去除了重复的行。
- 如果想返回所有的匹配行(不去重),可使用UNION ALL代替UNION。
- 在用 UNION 组合查询时,只能使用一条 ORDER BY 子句,它必须位于最后一条 SELECT 语句之后。
SELECT cust_name, cust_contact, cust_email
FROM Customers
WHERE cust_state IN ('IL','IN','MI')
UNION
SELECT cust_name, cust_contact, cust_email
FROM Customers
WHERE cust_name = 'Fun4All'
ORDER BY cust_name, cust_contact;
第15课 插入数据
数据插入 INSERT
1. 插入完整的行
- 法一:基础INSERT语句
给每一列提供一个值,如果某列没有值应该使用NULL值;各列必须以它们在表定义中出现的次序填充。
INSERT INTO Customers
VALUES('1000000006', 'Toy Land', '123 Any Street', 'New York', 'NY', '11111', 'USA', NULL, NULL);
- 法二:
明确列名,按照指定次序匹配指定列名不易出错。
INSERT INTO Customers(cust_id,cust_name, cust_address, cust_city, cust_state, cust_zip, cust_country, cust_contact, cust_email)
VALUES('1000000006', 'Toy Land', '123 Any Street', 'New York', 'NY', '11111', 'USA', NULL, NULL);
2. 插入部分行
使用上述法二,可以省略列,即只给某些列提供值,给其他列不提供值。
省略的列需满足一下任一条件:
- 该列定义为允许NULL值(无值或空值);
- 在表定义中给出默认值。
3. 插入某些查询的结果 (一条INSERT插入多行)
INSERT + SELECT
INSERT INTO Customers(cust_id, cust_contact, cust_email, cust_name, cust_address, cust_city, cust_state, cust_zip, cust_country)
SELECT cust_id, cust_contact, cust_email, cust_name, cust_address, cust_city, cust_state, cust_zip, cust_country
FROM CustNew;
INSERT SELECT 中的列名并不重要(不需要匹配列名),DBMS是根据列的位置来填充。
从一个表复制到另一个表 SELECT INTO
SELECT INTO 将数据复制到一个新表(有的 DBMS可以覆盖已经存在的表,这依赖于 所使用的具体 DBMS)。
SELECT *
INTO CustCopy
FROM Customers;
-- 这条 SELECT 语句创建一个名为 CustCopy 的新表,并把 Customers 表 的整个内容复制到新表中CREATE TABLE CustCopy AS
SELECT * FROM Customers;
-- MariaDB、MySQL、Oracle、PostgreSQL和 SQLite
第16课 更新和删除数据
更新数据 UPDATE
- 更新表中的特定行
基本的UPDATE语句由三部分组成:- 要更新的表
- 列名和它们的新值
- 确定要更新那些行的过滤条件
UPDATE Customers
SET cust_email = 'kim@thetoystore.com'
WHERE cust_id = '1000000005'; -- 更新单列UPDATE Customers
SET cust_contact = 'Sam Roberts', cust_email = 'sam@toyland.com'
WHERE cust_id = '1000000006'; -- 更新多列UPDATE Customers
SET cust_email = NULL
WHERE cust_id = '1000000005'; -- 删除某列的值
- 更新表中的所有行
不加WHERE过滤条件。
删除数据 DELETE
- 从表中删除特定的行
DELETE FROM Customers
WHERE cust_id = '1000000006';
- 从表中删除所有行
TRUNCATE TABLE table_name;
DELETE FROM table_name;
DELETE * FROM table_name;
使用 UPDATE 或 DELETE 时所遵循的重要原则:
- 除非确实打算更新和删除每一行,否则绝对不要使用不带 WHERE 子句 的 UPDATE 或 DELETE 语句。
- 保证每个表都有主键,尽可能像 WHERE 子句那样使用它(可以指定各主键、多个值或值的范围)。
- 在 UPDATE 或 DELETE 语句使用 WHERE 子句前,应该先用 SELECT 进行测试,保证它过滤的是正确的记录,以防编写的 WHERE 子句不正确。
- 使用强制实施引用完整性的数据库, 这样 DBMS将不允许删除其数据与其他表相关联的行。
- 有的 DBMS 允许数据库管理员施加约束,防止执行不带 WHERE 子句的 UPDATE 或 DELETE 语句。如果所采用的 DBMS支持这个特性,应该使用它。
第17课 创建和操纵表
创建表 CREATE TABLE
CREATE TABLE Products
( prod_id CHAR(10) NOT NULL, vend_id CHAR(10) NOT NULL, prod_name CHAR(254) NOT NULL, prod_price DECIMAL(8,2) NOT NULL, prod_desc VARCHAR(1000) NULL
);
-- NULL为默认设置,可省略CREATE TABLE OrderItems
( order_num INTEGER NOT NULL, order_item INTEGER NOT NULL, prod_id CHAR(10) NOT NULL, quantity INTEGER NOT NULL DEFAULT 1, -- 在插入行时如果不给出值,DBMS将自动采用默认值 item_price DECIMAL(8,2) NOT NULL
);
默认值常用于日期或时间戳列。
更新表 ALTER TABLE
使用 ALTER TABLE 更改表结构,必须给出下面的信息:
- 在 ALTER TABLE 之后给出要更改的表名(该表必须存在,否则将 出错);
- 列出要做哪些更改(ADD/DROP)。
ALTER TABLE Vendors
ADD vend_phone CHAR(20); -- 增加列ALTER TABLE Vendors
DROP COLUMN vend_phone; -- 删除列
复杂的表结构更改一般需要手动删除过程,它涉及以下步骤:
- 用新的列布局创建一个新表;
- 使用 INSERT SELECT 语句从旧表复制数据到新表。有必要的话,可以使用转换函数和计算 字段;
- 检验包含所需数据的新表;
- 重命名旧表(如果确定,可以删除它);
- 用旧表原来的名字重命名新表; (6) 根据需要,重新创建触发器、存储过程、索引和外键。
删除表 DROP TABLE
DROP TABLE CustCopy;
重命名表
| DBMS | 语句 |
|---|---|
| DB2、MariaDB、MySQL、Oracle、PostgreSQL | RENAME |
| SQL Server | sp_rename |
| SQLite | ALTER TABLE |
第18课 使用视图
- 视图(view):通过相关的名称存储在数据库中的一个“假表”。作为视图,它不包 含任何列或数据,包含的是一个查询。
视图的规则和限制:
- 与表一样,视图必须唯一命名;
- 对于可以创建的视图数目没有限制。
- 创建视图,必须具有足够的访问权限。这些权限通常由数据库管理人员授予。
- 视图可以嵌套,即可以利用从其他视图中检索数据的查询来构造视图。所允许的嵌套层数在不同的 DBMS中有所不同(嵌套视图可能会严重降低查询的性能,因此在产品环境中使用之前,应该对其进行全 面测试)。
- 许多 DBMS禁止在视图查询中使用 ORDER BY 子句。
- 有些 DBMS要求对返回的所有列进行命名,如果列是计算字段,则需要使用别名。
- 视图不能索引,也不能有关联的触发器或默认值。
- 有些 DBMS把视图作为只读的查询,这表示可以从视图检索数据,但 不能将数据写回底层表。详情请参阅具体的 DBMS文档。
- 有些 DBMS 允许创建这样的视图,它不能进行导致行不再属于视图的插入或更新。例如有一个视图,只检索带有电子邮件地址的顾客。如果更新某个顾客,删除他的电子邮件地址,将使该顾客不再属于视图。这 是默认行为,而且是允许的,但有的 DBMS可能会防止这种情况发生。
创建视图 CREATE VIEW view_name
CREATE VIEW ProductCustomers AS
SELECT cust_name, cust_contact, prod_id
FROM Customers, Orders, OrderItems
WHERE Customers.cust_id = Orders.cust_id
AND OrderItems.order_num = Orders.order_num; -- 创建一个名为ProductCustomers的视图SELECT cust_name, cust_contact
FROM ProductCustomers
WHERE prod_id = 'RGAN01'; -- 使用视图进行查询
删除视图 DROP VIEW view_name
视图重命名:先删除,再重新创建
第19课 使用存储过程
- 存储过程:为以后使用而保存的一条或多条SQL语句。可将其视为批文件,虽然它们的作用不仅限于批处理。
存储过程的好处:简单、安全、高性能。
这里的例子只适用于Oracle和SQL Server
- 存储过程的执行 EXECUTE
EXECUTE AddNewProduct( 'JTS01', 'Stuffed Eiffel Tower', 6.49, 'Plush stuffed toy with the text La ➥Tour Eiffel in red white and blue' );
-- 这里执行一个名为 AddNewProduct 的存储过程,将一个新产品添加到 Products 表中。
-- AddNewProduct 有四个参数,分别是:供应商 ID (Vendors 表的主键)、产品名、价格和描述。
-- 这4个参数匹配存储过程中4个预期变量(定义为存储过程自身的组成部分)。此存储过程将新行 添加到 Products 表,并将传入的属性赋给相应的列。
对于具体的 DBMS,可能包括以下的执行选择:
- 参数可选,具有不提供参数时的默认值;
- 不按次序给出参数,以“参数=值”的方式给出参数值。
- 输出参数,允许存储过程在正执行的应用程序中更新所用的参数。
- 用 SELECT 语句检索数据。
- 返回代码,允许存储过程返回一个值到正在执行的应用程序。
- 创建存储过程
Oracle
CREATE PROCEDURE MailingListCount (ListCount OUT INTEGER -- 参数 ListCount 从存储过程返回一 个值而不是传递一个值给存储过程(out)
)
IS
v_rows INTEGER;
BEGIN SELECT COUNT(*) INTO v_rows FROM Customers WHERE NOT cust_email IS NULL; ListCount := v_rows;
END;
-- 存储过程的代码括在 BEGIN 和 END 语句中,这里执行一条简单的 SELECT 语句,它检索具有邮件地址的顾客。
-- 然后用检索出的行数设置 ListCount(要传递的输出参数)var ReturnValue NUMBER
EXEC MailingListCount(:ReturnValue);
SELECT ReturnValue;
-- 这段代码声明了一个变量来保存存储过程返回的任何值,然后执行存储过程,再使用 SELECT 语句显示返回的值。
| 关键字 | 行为 |
|---|---|
| OUT | 从存储过程返回一值 |
| IN | 传递值给存储过程 |
| INOUT | 既传递值给存储过程也从存储过程传回值 |
SQL Server
CREATE PROCEDURE MailingListCount
AS
DECLARE @cnt INTEGER
SELECT @cnt = COUNT(*)
FROM Customers
WHERE NOT cust_email IS NULL;
RETURN @cnt;
-- 此存储过程没有参数。调用程序检索 SQL Server的返回代码提供的值。
-- 其中用 DECLARE 语句声明了一个名为@cnt 的局部变量(SQL Server中所 有局部变量名都以@起头);
-- 然后在 SELECT 语句中使用这个变量,让它包含 COUNT()函数返回的值;
-- 最后,用 RETURN @cnt 语句将计数返回给调用程序。 DECLARE @ReturnValue INT
EXECUTE @ReturnValue=MailingListCount;
SELECT @ReturnValue;
-- 这段代码声明了一个变量来保存存储过程返回的任何值,然后执行存储过程,再使用 SELECT 语句显示返回的值。
CREATE PROCEDURE NewOrder @cust_id CHAR(10)
AS
-- Declare variable for order number
DECLARE @order_num INTEGER
-- Get current highest order number
SELECT @order_num=MAX(order_num)
FROM Orders
-- Determine next order number
SELECT @order_num=@order_num+1
-- Insert new order
INSERT INTO Orders(order_num, order_date, cust_id)
VALUES(@order_num, GETDATE(), @cust_id)
-- Return order number
RETURN @order_num; -- 此存储过程在 Orders 表中创建一个新订单。
-- 它只有一个参数,即下订单顾客的 ID。订单号和订单日期这两列在存储过程中自动生成。
-- 代码首先声明一个局部变量来存储订单号。
-- 接着,检索当前最大订单号(使用 MAX()函数)并增加 1(使用 SELECT 语句)。
-- 然后用 INSERT 语句插入由 新生成的订单号、当前系统日期(用 GETDATE()函数检索)和传递的顾客 ID组成的订单。
-- 最后,用 RETURN @order_num 返回订单号(处理订单物品需要它)。CREATE PROCEDURE NewOrder @cust_id CHAR(10)
AS
-- Insert new order
INSERT INTO Orders(cust_id)
VALUES(@cust_id)
-- Return order number
SELECT order_num = @@IDENTITY;-- 此存储过程也在 Orders 表中创建一个新订单。
-- 这次由DBMS生成订单号。
-- 大多数DBMS都支持这种功能;SQL Server中称这些自动增量的列为标识字段(identity field),而其他DBMS称之为自动编号(auto number)或序列 (sequence)。
-- 传递给此过程的参数也是一个,即下订单的顾客 ID。
-- 订单号和订单日期没有给出,DBMS对日期使用默认值(GETDATE()函数),订单号自动生成。
-- 在SQL Server上可在全局变量@@IDENTITY 中得到自动生成的ID,它返回到调用程序(这里使用 SELECT 语句)。 第20课 管理事务处理(transaction processing)
事务处理是一种机制,用来管理必须成批执行的SQL操作,保证数据库不包含不完整的操作结果。即,要么完全执行,要么完全不执行。如果没有错误发生,整组语句提交给(写到)数据库表;如果发生错误,则进行回退(撤销),将数据库恢复到某个已知且安全的状态。
-
事务(transaction)指一组 SQL语句;
-
回退(rollback)指撤销指定 SQL语句的过程;
-
提交(commit)指将未存储的 SQL语句结果写入数据库表;
-
保留点(savepoint)指事务处理中设置的临时占位符(placeholder), 可以对它发布回退(与回退整个事务处理不同)。
-
SQL Server
BEGIN TRANSACTION
...
COMMIT TRANSACTION
- MariaDB、MySQL
START TRANSACTION
...
- Oracle
SET TRANSACTION ...
- PostgreSQL
BEGIN
...
撤销 ROLLBACK
DELETE FROM Orders;
ROLLBACK;
-- 执行 DELETE 操作,然后用 ROLLBACK 语句撤销
保存更改 COMMIT
隐式提交(implicit commit):提交(写或保存)操作时自动进行的。
进行明确的提交,需使用COMMIT语句。
-- SQL Server
BEGIN TRANSACTION
DELETE OrderItems WHERE order_num = 12345
DELETE Orders WHERE order_num = 12345
COMMIT TRANSACTION -- Oracle
SET TRANSACTION
DELETE OrderItems WHERE order_num = 12345;
DELETE Orders WHERE order_num = 12345;
COMMIT;
占位符
要支持回退部分事务,必须在事务处理块中的合适位置放置占位符。这样,如果需要回退,可以回退到某个占位符。
在 MariaDB、MySQL和 Oracle中 创建占位符,可使用 SAVEPOINT 语句。
SAVEPOINT delete1;
SQL Server:
SAVE TRANSACTION delete1;
第21课 使用游标(cursor)
- 结果集(result set):SQL查询所检索出的结果。
- 游标(cursor):一个存储在DBMS服务器上的数据库查询,它时被SELECT语句检索出来的结果集。
游标主要用于交互式应用,其中用户需要滚动屏幕上的数据,并对数据进行浏览或做出更改。
使用游标的步骤:
- 在使用游标前,必须声明(定义)它。这个过程实际上没有检索数据, 它只是定义要使用的 SELECT 语句和游标选项。
- 一旦声明,就必须打开游标以供使用。这个过程用前面定义的 SELECT 语句把数据实际检索出来。
- 对于填有数据的游标,根据需要取出(检索)各行。
- 在结束游标使用时,必须关闭游标,可能的话,释放游标(有赖于具体的 DBMS)。
创建游标
- DB2、MariaDB、MySQL和 SQL Server:
DECLARE CustCursor CURSOR
FOR
SELECT * FROM Customers
WHERE cust_email IS NULL
- Oracle、PostgreSQL:
DECLARE CURSOR CustCursor
IS
SELECT * FROM Customers
WHERE cust_email IS NULL
打开游标
OPEN CURSOR CustCursor
使用游标
FETCH 语句指出要检索哪些行,从何处检索它们以及将它们放于何处(如变量名)。
-- Oracle
-- 这个例子使用 FETCH 检索当前行,放到一个名为 CustRecord 的变量中。
-- 这里的 FETCH 位于 LOOP 内,因此它反复执行。
-- 代码 EXIT WHEN CustCursor%NOTFOUND 使在取不出更多的行时终止处理(退出循环)。
-- 这个例子也没有做实际的处理,实际例子中可用具体的处理代码替换占位符DECLARE TYPE CustCursor IS REF CURSOR RETURN Customers%ROWTYPE;
DECLARE CustRecord Customers%ROWTYPE
BEGIN OPEN CustCursor; LOOP FETCH CustCursor INTO CustRecord; EXIT WHEN CustCursor%NOTFOUND; ... END LOOP; CLOSE CustCursor;
END;
-- SQL Server
-- 在此例中,为每个检索出的列声明一个变量,FETCH 语句检索一行并保存值到这些变量中。
-- 使用 WHILE 循环处理每一行,条件 WHILE @@FETCH_STATUS = 0 在取不出更多的行时终止处理(退出循环)。
-- 这个例子也不进行具体的处理,实际代码中,应该用具体的处理代码替换其中的...占位符。 DECLARE @cust_id CHAR(10), @cust_name CHAR(50), @cust_address CHAR(50), @cust_city CHAR(50), @cust_state CHAR(5), @cust_zip CHAR(10), @cust_country CHAR(50), @cust_contact CHAR(50), @cust_email CHAR(255)
OPEN CustCursor
FETCH NEXT FROM CustCursor INTO @cust_id, @cust_name, @cust_address, @cust_city, @cust_state, @cust_zip, @cust_country, @cust_contact, @cust_email
WHILE @@FETCH_STATUS = 0
BEGIN FETCH NEXT FROM CustCursor INTO @cust_id, @cust_name, @cust_address, @cust_city, @cust_state, @cust_zip, @cust_country, @cust_contact, @cust_email
END
CLOSE CustCursor 关闭游标
- DB2、Oracle、PostgreSQL
CLOSE CustCursor
- Microsoft SQL Server
CLOSE CustCursor
DEALLOCATE CURSOR CustCursor
第22课 高级SQL特性
约束
- 约束(constraint):管理如何插入或处理数据库数据的规则
DBMS 通过在数据库表上施加约束来实施引用完整性(referential integrity)。
大多数约束是在表定义中定义的,用 CREATE TABLE 或 ALTER TABLE 语句。
主键
创建主键
-- 法一
CREATE TABLE Vendors
( vend_id CHAR(10) NOT NULL PRIMARY KEY, vend_name CHAR(50) NOT NULL, vend_address CHAR(50) NULL, vend_city CHAR(50) NULL, vend_state CHAR(5) NULL, vend_zip CHAR(10) NULL, vend_country CHAR(50) NULL
); -- 法二 (SQLite不允许)
ALTER TABLE Vendors
ADD CONSTRAINT PRIMARY KEY (vend_id);
外键
外键是表中的一列,其值必须列在另一表的主键中。
外键可以保证引用完整性,利用外键还可以防止意外删除数据。
CREATE TABLE Orders
( order_num INTEGER NOT NULL PRIMARY KEY, order_date DATETIME NOT NULL, cust_id CHAR(10) NOT NULL REFERENCES ➥Customers(cust_id)
); ALTER TABLE Orders
ADD CONSTRAINT
FOREIGN KEY (cust_id) REFERENCES Customers (cust_id)
唯一约束
唯一约束用来保证一列(或一组列)中的数据是唯一的。它们类似于主键,但存在以下重要区别。
- 表可包含多个唯一约束,但每个表只允许一个主键。
- 唯一约束列可包含 NULL 值。
- 唯一约束列可修改或更新。
- 唯一约束列的值可重复使用。
- 与主键不一样,唯一约束不能用来定义外键。
检查约束
检查约束用来保证一列(或一组列)中的数据满足一组指定的条件。检查约束的常见用途有以下几点。
- 检查最小或最大值。例如,防止 0个物品的订单(即使0是合法的数)。
- 指定范围。例如,保证发货日期大于等于今天的日期,但不超过今天起一年后的日期。
- 只允许特定的值。例如,在性别字段中只允许 M 或 F。
CREATE TABLE OrderItems
( order_num INTEGER NOT NULL, order_item INTEGER NOT NULL, prod_id CHAR(10) NOT NULL, quantity INTEGER NOT NULL CHECK (quantity > 0), item_price MONEY NOT NULL
);ADD CONSTRAINT CHECK (gender LIKE '[MF]')
索引
索引用来排序数据以加快搜索和排序操作的速度。
主键数据总是排序的,这是 DBMS的工作。 因此,按主键检索特定行总是一种快速有效的操作。
可以在一个或多个列上定义索引,使 DBMS保存 其内容的一个排过序的列表。在定义了索引后,DBMS 以使用书的索引类似的方法使用它。DBMS 搜索排过序的索引,找出匹配的位置,然后检索这些行。
- 索引改善检索操作的性能,但降低了数据插入、修改和删除的性能。 在执行这些操作时,DBMS必须动态地更新索引。
- 索引数据可能要占用大量的存储空间。 并非所有数据都适合做索引。取值不多的数据(如州)不如具有更多可能值的数据(如姓或名),能通过索引得到那么多的好处。
- 索引用于数据过滤和数据排序。如果你经常以某种特定的顺序排序数据,则该数据可能适合做索引。
- 可以在索引中定义多个列(例如,州加上城市)。这样的索引仅在以州加城市的顺序排序时有用。如果想按城市排序,则这种索引没有用处。
索引用CREATE INDEX语句创建(不同DBMS创建索引的语句变化很大)。
CREATE INDEX prod_name_ind
ON Products (prod_name);
索引必须唯一命名。
ON 用来指定被索引的表,而索引中包含的列在表名后的圆括号中给出。
触发器
==触发器是特殊的存储过程,它在特定的数据库活动发生时自动执行。==触发器可以与特定表上的 INSERT、UPDATE 和DELETE 操作(或组合)相关联。
根据所使用的DBMS的不同,触发器可在特定操作执行之前或之后执行。
触发器的常见用途:
- 保证数据一致。例如,在 INSERT 或 UPDATE 操作中将所有州名转换为大写。
- 基于某个表的变动在其他表上执行活动。例如,每当更新或删除一行时将审计跟踪记录写入某个日志表。
- 进行额外的验证并根据需要回退数据。例如,保证某个顾客的可用资金不超限定,如果已经超出,则阻塞插入。
- 计算计算列的值或更新时间戳。
-- 创建一个触发器,它对所有 INSERT 和 UPDATE 操作,将 Customers 表中的 cust_state 列转换为大写。 -- SQL Server
CREATE TRIGGER customer_state
ON Customers
FOR INSERT, UPDATE
AS
UPDATE Customers
SET cust_state = Upper(cust_state)
WHERE Customers.cust_id = inserted.cust_id; -- Oracle和 PostgreSQL
CREATE TRIGGER customer_state
AFTER INSERT OR UPDATE
FOR EACH ROW
BEGIN
UPDATE Customers
SET cust_state = Upper(cust_state)
WHERE Customers.cust_id = :OLD.cust_id
END;
数据库安全
一般说来,需要保护的操作有:
- 对数据库管理功能(创建表、更改或删除已存在的表等)的访问;
- 对特定数据库或表的访问;
- 访问的类型(只读、对特定列的访问等);
- 仅通过视图或存储过程对表进行访问;
- 创建多层次的安全措施,从而允许多种基于登录的访问和控制;
- 限制管理用户账号的能力。
本文来自互联网用户投稿,文章观点仅代表作者本人,不代表本站立场,不承担相关法律责任。如若转载,请注明出处。 如若内容造成侵权/违法违规/事实不符,请点击【内容举报】进行投诉反馈!