Mysql学习(B站狂神说java的个人笔记二)
目录
一、事务
二、索引
三、权限管理和备份
四、规范数据库设计和三大范式
五、JDBC(重点)和第一个JDBC程序及解释
六、statement对象详解
七、SQL注入问题
八、PreparedStatement对象
九、使用IDEA连接数据库
十、JDBC操作事务
十一、数据库连接池
一、事务
1、什么是事务
要么都成功,要么都失败
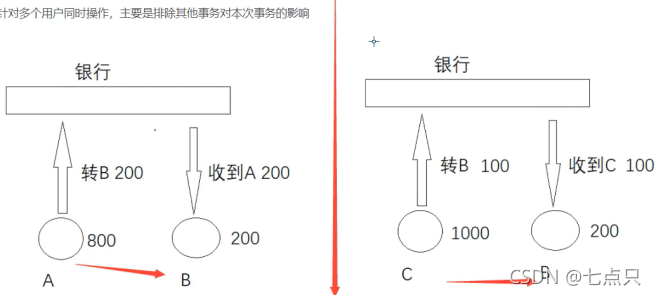
(1)例子:(都针对同一个事物,要么都完成要么不完成)
SQL执行 A给 B转账 A1000 --> 200 B200
SQL执行 B收到A的钱 A 800 --> B200
(2)事务原则:ACID原则,原子性,一致性,隔离性,持久性
(3)以上面的例题来解说:
①原子性:上述转钱的步骤,要么一起成功,或者一起失败,不能只发生其中一个
②一致性:只对一个事务的一致性,即最终的一致性,可以理解为上面A和B怎么转钱,他们的钱加起来永远都是1000,不会变
③持久性:表示事务结束后的数据不随着外界原因导致数据丢失,如果数据库未提交,恢复到原来;如果事务已经提交,持久化到数据库,即事务一旦提交就不能变了
④隔离性:针对多个用户同时操作,主要是排除其他事务对本次事务的影响
(4)事务隔离的一些错误:
①脏读:指一个事务读取了另外一个事务未提交的数据
②不可重复度:在一个事务内读取表中的某一行数据,多次读取结果不同(这个不一定是错,只是某些场合不对)
③虚读(幻读)
是指在一个事务内读取到了别的事务插入的数据,导致前后读取不一致。
2、执行事务
(1)mysql是默认开启事务自动提交的
SET autocommit =0 /*关闭*/
SETautocommit = 1 /*开启(默认的)*/
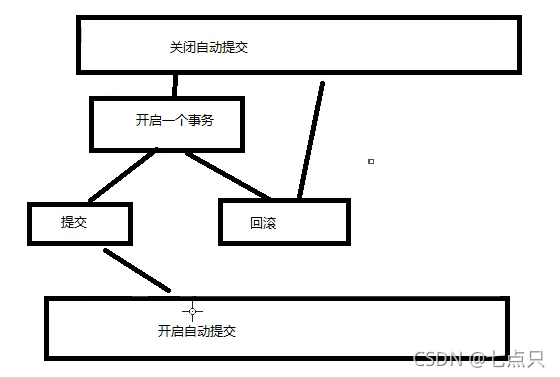
--手动处理事务
SET autocommit =0 --关闭自动提交--事务开启
START TRANSACTION --标记一个事务的开始,从这个之后的 sql 都在同一个事务内
INSERT XX
INSERT XX(这两个事务要么同时成功,要么失败)--提交:持久化(成功!)
COMMIT--回滚:回到|的原来的样子(失败!)
ROLLBACK
--事务结束(以下内容先了解即可)
SAVEPOINT 保存点名 --设置一个事务的保存点
ROLLBACK TO SAVEPOINT保存点名 --回滚到保存点
RELEASE SAVEPOINT 保存点名 --撤销保存点(2)顺序
(3)模拟场景
CREATE DATABASE shop CHARACTER SET utf8 COLLATE utf8_general_ci
--创建一个叫shop的数据库
USE shop --使用shop数据库
CREATE TABLE `account`(
`id` INT(3)NOT NULL AUTO_INCREMENT,'nameVARCHAR(30) NOT NULL,
`money DECIMAL(9,2) NOT NULL,PRIMARY KEY ( id )
)ENGINE=INNODB DEFAULT CHARSET=utf8
--创建一张account的表
INSERT INTO account(` name`, money `)VALUES ( 'A' ,2000.00),('B ',10000.00)
--给表插入一些数据--模拟转账:事务
SET autocommit = 0; --关闭自动提交
START TRANSACTION --开启一个事务(一组事务)
UPDATE account SET money=money-500 WHERE `name` = 'A' -- A减500
UPDATE account SET money=money+500 WHERE ‘name’ = 'B' -- A加500
COMMIT; --提交事务,就被持久化了!
ROLLBACK; --回滚
SET autocommit = 1; --恢复默认值二、索引
MySQL官方对索引的定义为:索引 (Index)是帮助MySQL高效获取数据的数据结构。提取句子主干,就可以得到索引的本质:索引是数据结构。
1、主键索引(PRIMARY KEY )
唯一的标识,主键不可重复,只能有一个列作为主键
2、唯一索引(UNIQUE KEY)
避免重复的列出现,唯一索引可以重复,多个列都可以标识位唯一索引
3、常规索引(KEY/INDEX)
默认的, index或key关键字来设置
4、全文索引(FullText)
在特定的数据库引擎下才有,MylSAM。
快速定位数据
5、基础语法
(1)索引的使用
①在创建表的时候给字段增加索引
②创建完毕后,增加索引
(2)显示所有的索引信息
例:SHOW INDEX FROM student
(3)增加一个全文索引(索引名)列名
例:ALTER TABLE schoo1.student ADD FULLTEXT INDEX`studentName ` ( studentName );
(4)EXPLAIN分析sql执行的状况
EXPLAIN SELECT *FROM student; --非全文索引
EXPLAIN SELECT *FROM student WHERE MATCH(studentName) AGAINST('刘');
注:索引在小数据量的时候,用户不大,但是在大数据的时候,区别十分明显
(5)索引原则
索引不是越多越好
不要对进程变动数据加索引·小数据量的表不需要加索引
索引一般加在常用来查询的字段上!
(6)索引的数据结构
Hash类型的索引
Btree : lnnoDB的默认数据结构
三、权限管理和备份
1、SQLyog可视化管理
点击上面的小人或者按下CTRL+U

会出现一个弹窗,点击添加新用户
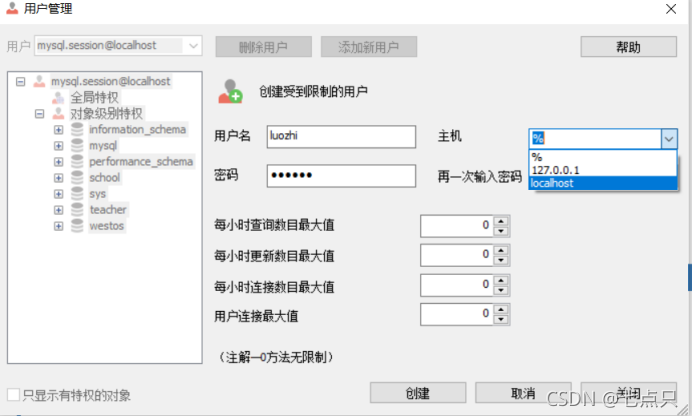
用户名密码自己取,主机选127.0.0.1或localhost都一样,选后之后点击创建
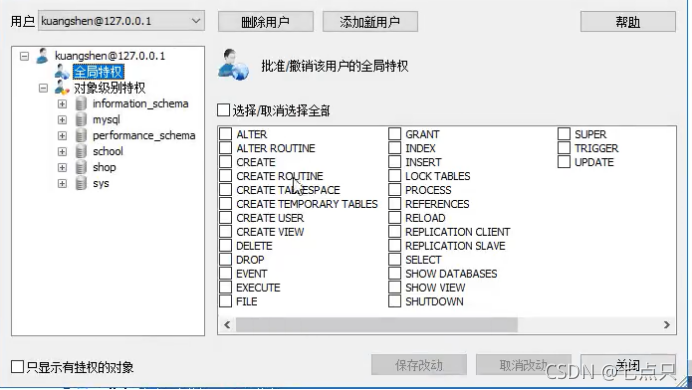
他会让你选一些权限,这些表的权限基本可以通过名字看出来,就是一些功能,能否创建一个表,删除,是否能够插入等等,如果点击选择全部,那么这个用户几乎可以干所有的事情
再点击保存改动这个用户就创建完了
试一下用这个用户链接,右键点击文件-新连接或者CTRL+M

注意MYSQL Host Address 这里,之前选的是上面,这里就填什么。如果选的是127.0.0.1这里就填127.0.0.1
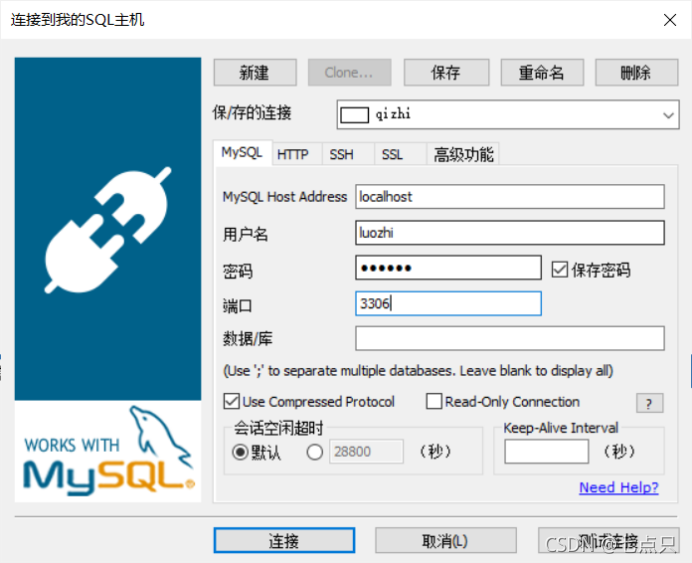
之后不难发现,用户换了,之前的默认是root用户

如果要删除用户的话,点击用户管理或ctrl+U,在用户中选中要删除的用户,点击删除用户,用户就删除了
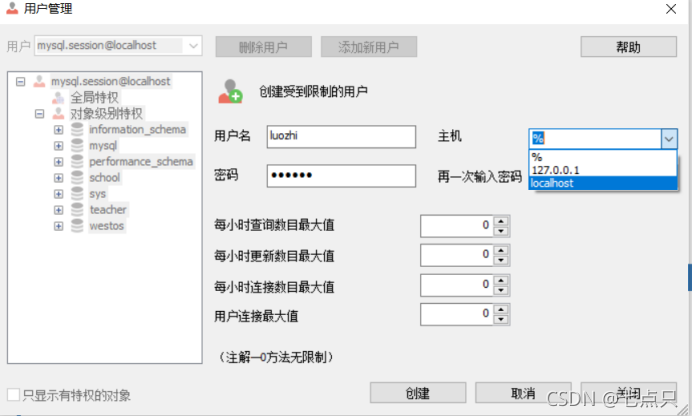
2、sql命令
(1)用户表:mysql.user
本质:就是对用户表这张表进行增删改查
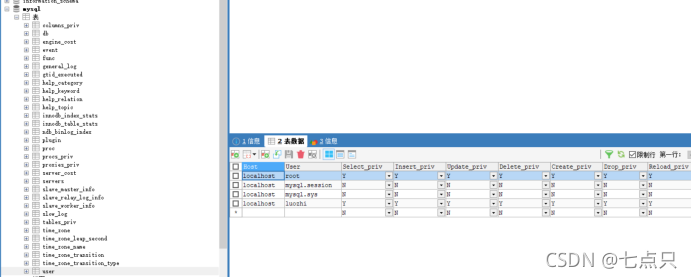
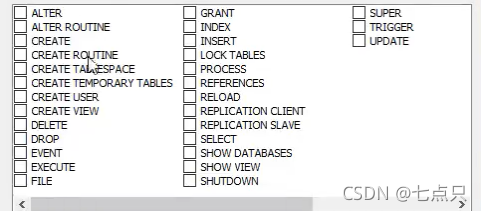
这张表基本上就是一些权限,跟之前用户管理里面的权限一致
(2)创建用户CREATE USER用户名IDENTIFIED BY '密码’
例:
例:CREATE USER kuangshen IDENTIFIED BY '123456'
修改密码(修改当前用户密码)
SET PASSWORD = PASSWORD( '123456 ')
修改密码(修改指定用户密码)
SET PASSWORD FOR kuangshen = PASSWORD( '123456 ')
重命名: RENAME USER原来名字 To 新的名字
RENAME USER kuangshen To kuangshen2
用户授权: ALL PRIVILEGES 全部的权限,库.表
(注:ALL PRIVILEGES 除了给别人授权,其他都能够干)
GRANT ALL PRIVILEGES ON *. * To kuangshen2
--查询权限
SHOW GRANTS FOR kuangshen2 --查看指定用户的权限
SHOW GRANTS FORroot@1ocalhost
-- ROOT用户权限:GRANT ALL PRIVTLEGES ON *.* To 'root' @'loca1host' WITH GRANT OPTION
撤销权限:REVOKE哪些权限,在哪个库撤销,给谁撤销
REVOKE ALL PRIVILEGES ON*.*FROM kuangshen2
删除用户:
DROP USER kuangshen
3、MySQL备份
(1)为什么要备份:
①保证重要的数据
②不丢失数据转移
(2)MySQL数据库备份的方式
①直接拷贝物理文件
②在Sqlyog这种可视化工具中手动导出
③使用命令行导出mysqldump命令行使用
(3)sqlyog手动导出
右键需要到处的表后点击备份/导出,
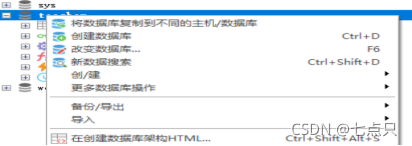
点击备份表作为SQL 转储,就叫sql转储,,一般情况下就只要结构和数据,结构就代表创建表的那些语句,数据就代表那些insert语句
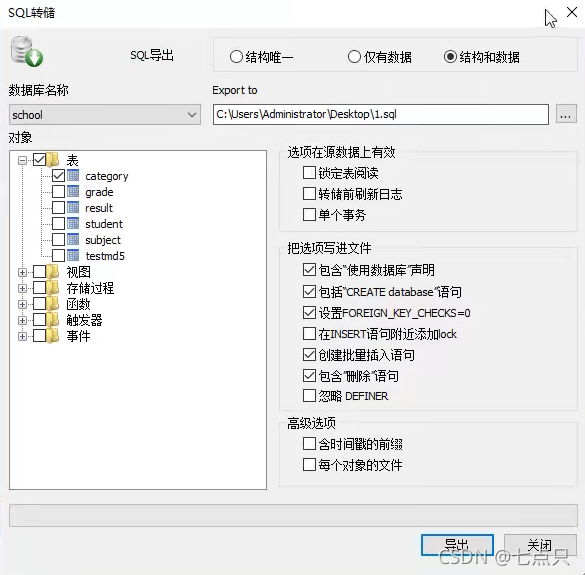
4、使用命令行导出mysqldump命令行使用
①语法: mysq1dump -h 主机 -u用户名-p 密码数据库﹑表名>物理磁盘位置/文件名
例:mysq1dump -hloca7host -uroot -p123456 school student >D:/a.sq1
②语法: mysq7dump -h 主机 -u用户名-p 密码数据库﹑表1表2表3>物理磁盘位置/文件
例:mysqldump -h1ocalhost -uroot -p123456 school student >D:/b.sq1
③语法:mysqldump -h主机 -u 用户名-p 密码数据库>物理磁盘位置/文件名例:mysq1dump -hlocalhost -uroot -p123456 schoo1 >D:/c.sq7
④导入数据
登录mysql的情况下,切换到指定的数据库#source备份文件(如果是要导入数据库就不用切换指定数据库,如果是导入表就需要)
切换后输入例子:source d : /a.sq1 I
不登入MySQL的情况下,输入语法:
mysql -u用户名-p密码库名<备份文件
注:还是推荐登入MySQL后再导入
⑤什么是使用使用备份:假设你要备份数据库,防止数据丢失。把数据库个朋友! sql文件给别人即可!
四、规范数据库设计和三大范式
1、为什么要设计数据库
当数据库比较复杂的时候,我们就需要设计了
糟糕的数据库设计:
数据冗余,浪费空间
数据库插入和删除都会麻烦、异常【屏蔽使用物理外键】
程序的性能差
良好的数据库设计:
节省内存空间
保证数据库的完整性
方便我们开发系统
软件开发中,关于数据库的设计:
分析需求:分析业务和需要处理的数据库的需求
概要设计:设计关系图E-R图
2、设计数据库额步骤(个人博客)
①收集信息,分析需求
用户表(用户登录注销,用户的个人信息,写博客,创建分类)。分类表(文章分类,谁创建的)
文章表(文章的信息)
评论表
友链表(友链信息)
自定义表(系统信息,某个关键的字,或者一些主字段)key : value。说说表(发表心情.. id... content....create_time)
②标识实体(把需求落地到每个字段)
③标识实体之间的关系
写博客: user --> blog
创建分类:user -> category。关注: user ->user
友链:links
评论: user-user-blog
3、三大范式
(1)
第一范式(1NF)
原子性:保证每一列不可再分
例如:
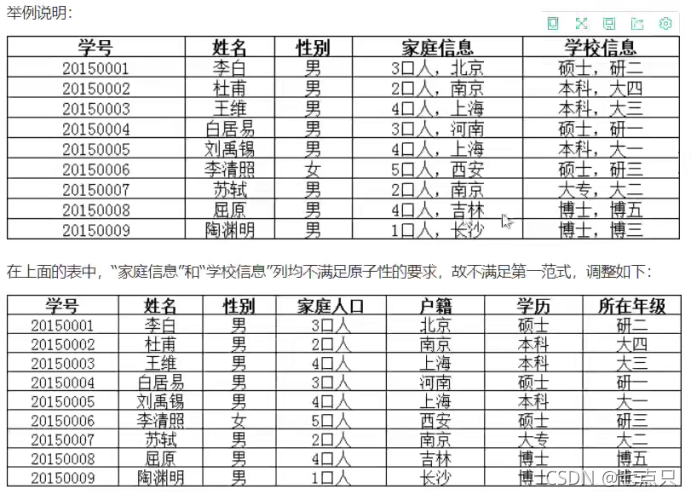
第二范式(2NF)
前提:满足第一范式每张表只描述—件事情
(第二范式需要确保数据库表中的每一列都和主键相关,而不能只与主键的某一部分相关(主要针对联合主键而言))
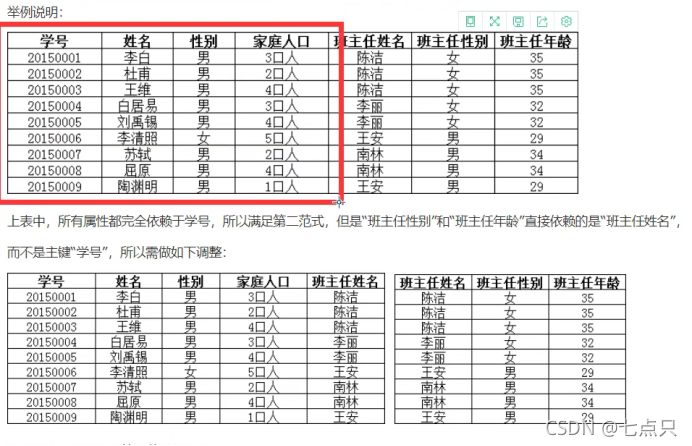
第三范式(3NF)
前提:满足第一范式和第二范式
第三范式需要确保数据表中的每一列数据都和主键直接相关,而不能间接相关。
(2)(规范数据库的设计)规范性和性能的问题:
关联查询的表不得超过三张表
①考虑商业化的需求和目标,(成本,用户体验!)数据库的性能更加重要。
②在规范性能的问题的时候,需要适当的考虑一下规范性!
③故意给某些表增加一些冗余的字段。(从多表查询中变为单表查询)
④故意增加一些计算列(从太数据量降低为小数据量的查询:索引)
五、JDBC(重点)和第一个JDBC程序及解释
1、数据库驱动
驱动:声卡,显卡,数据库
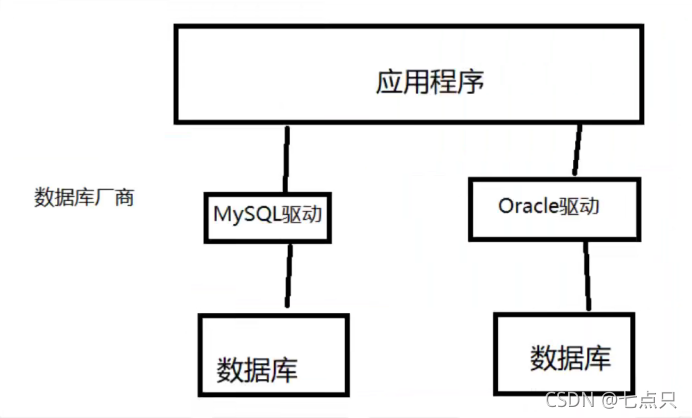
我们的程序会通过数据库驱动和数据库打交道
2、
SUN公司为了简化开发人员的(对数据库的统一)操作,提供了一个(Java操作数据库的)规范,俗称JDBC这些规范的实现由具体的厂商去做~
对于开发人员来说,我们只需要掌握JDBC接口的操作即可!
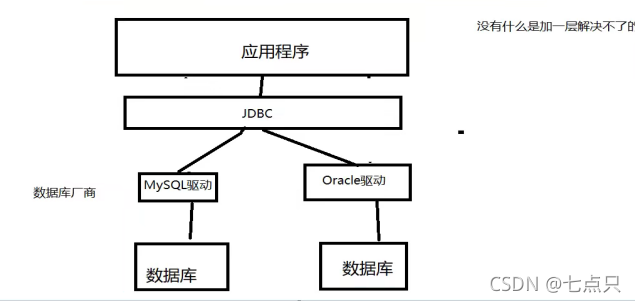
3、学习这个需要知道两个包:java.sql javax.sql
还需要导入一个数据库驱动包:mysql-connector-java-5.1.47.jar(中间的数字代表版本号,不同的版本对应的版本号不同)
4、第一个JDBC程序
(1)创建测试数据库
CREATE DATABASE jdbcstudy CHARACTER SET utf8 COLLATE utf8_general_ci;
USE jdbcstudy;
CREATE TABLE users(
id INT PRIMARY KEY,
NAME VARCHAR(40),
PASSwORD VARCHAR(40),
emai1 VARCHAR(60) ,
birthday DATE
);
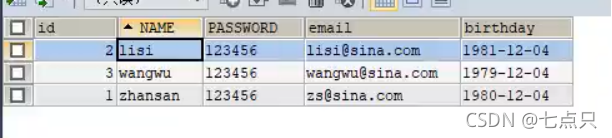
INSERT INTO users(id ,NAME ,PASSWORD , emai1,birthday)
VALUES (1, 'zhansan ' , '123456' , 'zs@sina.com', '1980-12-04 '),
(2, '1isi' , '123456' , '1isi@sina.com ' , '1981-12-04 '),
(3 , 'wangwu ' , '123456' , 'wangwu@sina.com ' , '1979-12-04 ');在sqlyog创建之后的的结果
(2)在JDBC下写代码
package com.kuang.lesson01;import java.sql.*;
//我的第一个JDBC程序
public class JdbcFirstDemo {
public static void main(String[] args) throws ClassNotFoundException,SQLException {
// 加载驱动
class.forName( "com.mysql.jdbc.Driver"); // 固定写法,加载驱动//用户信息和urL
//useUnicode=true&characterEncoding=utf8&useSSL=true
String url = "jdbc:mysq1://localhost:3306/jdbcstudy?useUnicode=true&characterEncoding=utf8&useSSL=true";
String username = "root" ;
String password = "123456";//.连接成功,数据库对象Connection代表数据库
Connection connection = DriverManager.getConnection(url, username,password);//执行SQL的对象Statement执行sqL的对象
Statement statement = connection.createStatement();//执行SQL的对象去执行SQL,可能存在结果,查看返回结果
String sql = "SELECT *FROM users" ;
ResultSet resultSet = statement. executeQuery(sql);//返回的结果集,结果集中封装了我们全部的查询出来的结果while (resultset.next()){
System.out.println("id=" + resultset.getobject("id"));
System.out.println("name=" +resultset.getobject("NAME"));
System.out.println("pwd=" + resultset.getobject("PASSWORD"));
System.out.println( "email=" + resultset.getobject("email"));
System.out.println("birth=" + resultset.getobject("birthday"));
System.out.println("====================================");
}//释放连接
resultset.close(;statement.close();connection.close();
}
}执行之后输出的结果:
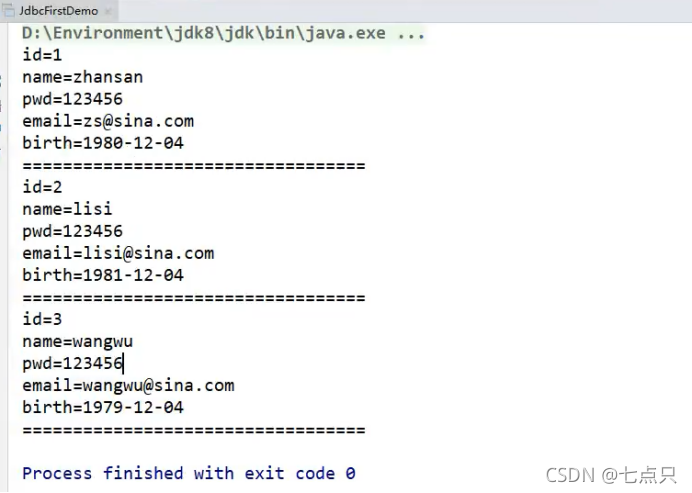
5、步骤总结:
①加载驱动
②连接数据库DriverManager
③获得执行sql的对象Statement
④获得返回的结果集
⑤释放连接
6、解释:
(1)DrivierManager
// Drive rManager.registerDriver(new com.mysql. jdbc.Driver());
class.forName("com.mysql.jdbc.Driver");//固定写法,加载驱动
connection connection = DriverManager.getconnection(url,username,password);
// connection代表数据库
//数据库设置自动提交//事务提交
//事务滚回
connection . rollback();
connection . commit();
connection . setAutocommit();
(2)URL
string ur1 = "jdbc :mysql: / /localhost: 3306/jdbcstudy?useUnicode=true&characterEncoding=utf8&usessL=true ";
// mysql默认端口: 3306
//协议://主机地址:端口号/数据库名?参数1&参数2&参数3
// oralce 默认端口号: 1521
/ /jdbc:oracle:thin: @1ocalhost:1521:sid
(3)
Statement执行SQL的对象 PrepareStatement执行SQL的对象(这两个的作用都差不多)
string sql = "SELECT *FROM users"; //编写sQL
statement.executeQuery() ;//查询操作返回Resultset
statement.execute(); //执行任何SQL
statement.executeUpdate();//更新、插入、删除。都是用这个,返回一个受影响的行数
(4)
ResultSet查询的结果集:封装了所有的查询结果
获得指定的数据类型
resu1tset.getobject(); //在不知道列类型的情况下使用
//如果知道列的类型就使用指定的类型
Resultset.getstring();
resultset.getInt();
resultset. getFloat();
resultset. getDate();
resultset. getobject();
(5)遍历、指针
resultset.beforeFirst();//移动到最前面
resultset.afterLast();//移动到最后面
resultset.next();//移动到下一个数据
resultset.previous();//移动到前一行
resultset.absolute(row);//移动到指定行
(6)释放资源
//释放连接
resultset.close();
statement.close();
connection . close(); //产耗资源,用完关掉
六、statement对象详解
1、statement对象
Jdbc中的statement对象用于向数据库发送SQL语句,想完成对数据库的增删改查,只需要通过这个对象向数据库发送增删改查语句即可。
Statement对象的executeUpdate方法,用于向数据库发送增、删、改的sql语句,executelUpdate执行完后,将会返回一个整数((即增删改语句导致了数据库几行数据发生了变化)。
Statement.executeQuery方法用于向数据库发送查询语句,executeQuery方法返回代表查询结果的ResultSet对象。
2、 CRUD操作 create
使用executeUpdate(String sql)方法完成数据添加操作,示例操作:
statement st = conn.createstatement();
String sql= "insert into user(... ) values(.... . ) ";
int num = st.executeupdate(sql);
if(num>0){
System. out.println("插入成功! ! ! ");
}3、CRUD操作 delete
使用executeUpdate(String sql)方法完成数据删除操作,示例操作:
statement st = conn.createstatement();
String sql = "delete from user where id=1";
int num = st.executepdate(sql);
if(num>0){
System.out.print1n(“删除成功!! ! ");
}4、CRUD操作read
使用executeQuery(String sql)方法完成数据查询操作,示例操作:
statement st = conn.createstatement();
String sql = "select * from user where id=1";
Resultset rs = st.executeUpdate(sql);
while(rs.next()){
//根据获取列的数据类型,分别调用rs的相应方法映射到java对象中
}5、代码实现
(1)提取工具类 (也就是正常情况下,在JDBC下写代码都应该包括以下步骤(上面有提到过):
①加载驱动
②连接数据库DriverManager
③获得执行sql的对象Statement
④获得返回的结果集
⑤释放连接
而每一次都要执行加载驱动,释放连接等操作,这个步骤变化的就只有sql和结果,其他都不变,如果每一次都要写一遍会降低写代码速度,因此,对这些不改变的步骤我们要提取工具(创建一个工具类),使用的时候直接链接即可
)
package com. kuang.lesson02.utils;import java.io.IOException;
import java.io.Inputstream;
import java.sql.*;
import java.util.Properties;public class Jdbcutils {
private static string driver = null;
private static string url = null;
private static string username = null;
private static string password = null;
static {
try{
Inputstream in=
Jdbcutils.class.getclassLoader().getResourceAsstream(" db .properties");
Properties properties = new Properties();
properties.load(in);driver = properties.getProperty("driver");
url= properties.getProperty("url");
username = properties.getProperty("username "');
password = properties.getProperty("password");//驱动只用加载一次
class.forName(driver);
}catch (Exception e) {
e.printstackTrace(;
}
}//获取连接
public static connection getconnection() throws SQLException {
return DriverManager. getconnection(url,username,password);
}//释放连接资源
public static void release(connection conn,statement st,Resultset rs){
if (rs !=null){
try {
rs.close();
}catch (SQLException e) {
e.printstackTrace(;
}
}
}
}(2)编写增删改的方法,executeupdate(以下都是例子)
(下面的代码将上面的工具封装到了名为 Jdbcutils的工具类中)
package com. kuang. lesson02;
import com. kuang.lesson02.utils . ]dbcutils;import java.sql.connection;
import java.sql.Resultset;
import java.sql.SQLException;
import java.sql. statement;public class TestInsert {
public static void main(string[] args) {
connection conn = null;
statement st = null;
Resultset rs = null;
try {
conn = Jdbcutils.getconnection(); //获取数据库连接,
st = conn . createstatement();//获得SQL的执行对象
String sql = "ITSERT INTo users(id,` NAME`,` PASSWORD`, `email `, `birthday` )" +
"VALUES(4, 'kuangshen ' , '123456' , '24736743@qq.com' , ' 2020-01-01')"int i = st.executeupdate(sql);
if (i>0){
System. out.println("插入成功!");
}}catch (sQLException e) {
e.printstackTrace(;finally {
dbcutils.release(conn , st,rs);
}
}
}
package com. kuang. lesson02;
import com. kuang. 1esson02.utils .Jdbcutils;
import java.sql.connection;
import java.sql.Resultset;
import java.sql.SQLException;
import java.sql.statement;public class TestDelete {
public static void main(string[] args) {
Connection conn = null;
statement st = null;
Resultset rs = null;try {
conn = jdbcutils.getconnection(); //获取数据库连接
st = conn. createstatement();//获得SQL的执行对象
String sql = "DELETE FROM users WHERE id = 4";
Int i = st.executeupdate(sql);
if (i>0){
System.out.print1n("删除成功! ");
}
}catch (SQLException e) {
e.printstackTrace();
}finally {
Jdbcutils.release(conn , st,rs);
}
}
}package com. kuang.lesson02;
import com. kuang.lesson02.uti1s . Jdbcutils;
import java.sql. connection;
import java.sql.Resultset;
import java.sql.sQLException;
import java.sql.statement;public class Testupdate {
public static void main(string[] args) {
connection conn = null;
statement st = null;
Resultset rs = null;try {
conn = jdbcutils.getconnection(); //获取数据库连接
st = conn. createstatement();//获得SQL的执行对象
String sql = "UPDATE users SET NAME*='kuangshen ' , email ='24736743@qq.com’ WHERE id=1";
int i = st.executeupdate(sql);
if (i>0){
System. out.print1n("更新成功! ");
}}catch(SQLException e) {
e.printstackTrace(;finally {
Jdbcutils.release(conn , st,rs);
}
}
}
(3)查询 executeQuery
package com. kuang. lesson02;
import com.kuang.lesson02.uti1s .Jdbcutils;
import java.sql.connection;
import java.sql.Resultset;
import java.sql.sQLException;
import java.sql.statement;public class Testselect {
public static void main(string[] args) {
connection conn =null;
statement st = null;Resu7tset rs = null;
try {
conn = jdbcutils.getconnection();
st = conn . createstatement();/ / SQL
String sql = "select * from users where id = 1";
rs = st.executeQuery (sql);//查询完毕会返回一个结果集
while (rs.next()){
System. out. println(rs. getstring ( "NAME"));
}
}catch (SQLException e) {
e.printstackTrace();
}finally {
Jdbcutils.release(conn , st,rs);
}
}
}七、SQL注入问题
sql存在漏洞,会被攻击导致数据泄露(SQL会被拼接)

八、PreparedStatement对象
1、PreparedStatement可以防止SQL注入。效率更好!
2、举例说明:
import java.sql.connection;import java.util.Date;
import java.sql.Preparedstatement;
import java.sql.sQLException;
public class TestInsert {
public static void main( String[] args) {
Connection conn = null;
Preparedstatement st = nul1;
try {
conn =. jdbcUtils.getConnection();//区别
//使用?占位符代替参数
String sql = "insert into users(id, `NAME`, `PASSWORD` , ' email `, `birthday`) values(?,?,?,?,?)st = conn.prepareStatement(sql);//预编译SsQL,先写sqL,然后不执行//手动给参数赋值
st.setInt( parameterlndex: 1, x:4); //id
st.setstring( parameterIndex: 2, x: "qinjiang" );
st.setstring( parameterlndex: 3,x: "1232112");
st.setstring( parameterIndex: 4, x: "24734673@qq.com") ;//注意点:sqL.Date 数据库专用的方法 java.sqL.Date()
// utiL.Date java专用的方法 new Date().getTime()获得时问戳
st.setDate( parameterIndex: 5,new java.sql.Date(new Date().getTime()));//执行
int i = st.executeUpdate();if (i>0)i
System.out.print1n("插入成功!");
}
}catch (SQLException e) i
e.printstackTrace();finally {
dbcUtils.reLease( conn,st, rs: null);
}
}
}package com.kuang.lesson03;
import com.kuang.lesson02.utils.Jdbcutils;
import java.sql.connection;
import java.sql.Preparedstatement;
import java.sql.Resultset;
import java.sql.SQLException;public class Testselect {
public static void main( String[ ] args) {connection conn = null;
Preparedstatement st = null;
Resultset rs = null;try {
conn = jdbcUtils.getconnection();String sql = "select * from users where id = ?";//编写SQLst = conn. prepareStatement(sq1); //预编译st. setInt( parameterlndex: 1, x:2); //传递参数,如果要查id=3就把x后面的数字改为3rs = st. executeQuery(); //执行
if (rs. next()){
System. out . println(rs. getString( columnLabel: "NAME"));
}
} catch (SQLException e) {
e.printstackTrace();finally {
dbcUtils.reLease( conn,st, rs: null);
}
}
}注:PreparedStatement防止lsQL注入的本质,把传递进来的参数当做字符假设其中存在转义字符,就直接忽略,’会被直接转义
九、使用IDEA连接数据库
1、Database的隐藏问题
在JDBC里一般都会在右侧边会有,但是有的同学可能会没有
没有的同学可以看到下侧,有一个小电脑一样的东西,你点一下它就没有了,再点一下就又有了

2、
点击databases里面的+号,点击data source 里面会出现很多的数据源,选中我们的MySQL
会弹出一个熟悉的连接框,注意要把bin目录导入才能连接成功
如果出现下面这个driver是空的,那么你在点击测试连接的时候就会失败,因为没有导入bin目录
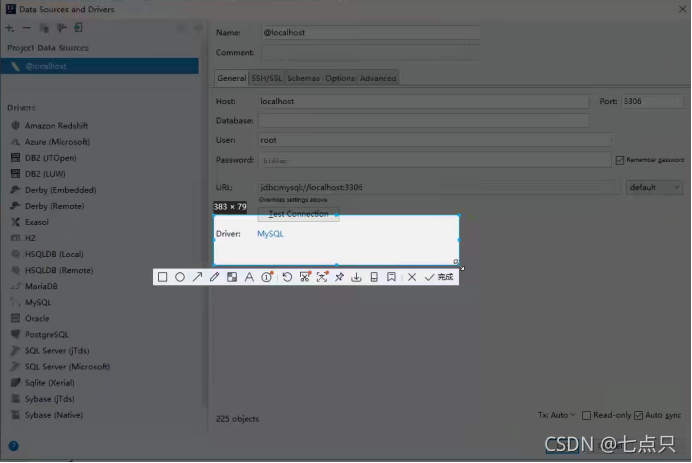
所以到记得导入bin目录
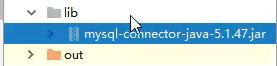
如果还是连接不上的话
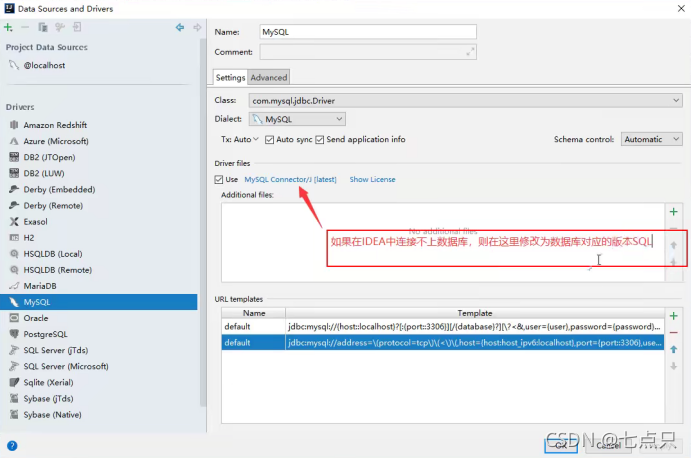
出现successful代表连接成功
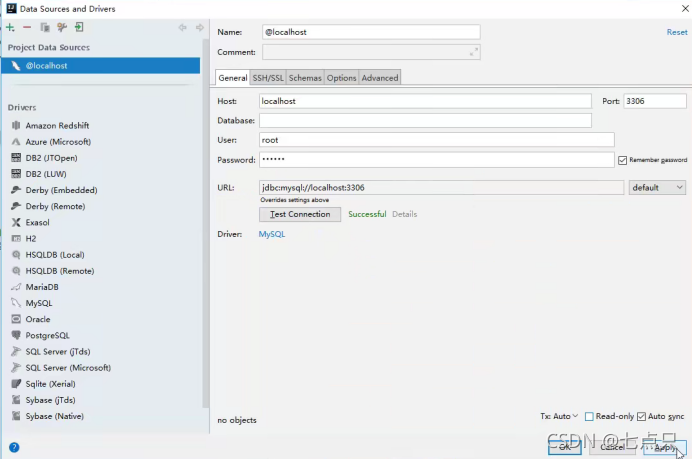
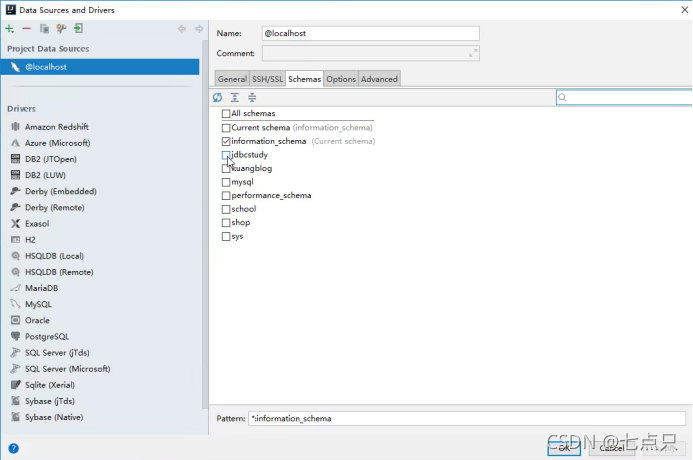
连接成功后选择数据库,打开这个设置
在schemas里面选中你要选择的数据库,再apply-OK
如果想要查看里面的表就直接双击该表即可
如果要修改里面的表,修改完成后记得点击绿色的箭头,否则会提示修改失败
 如果要编写SQL的话
如果要编写SQL的话
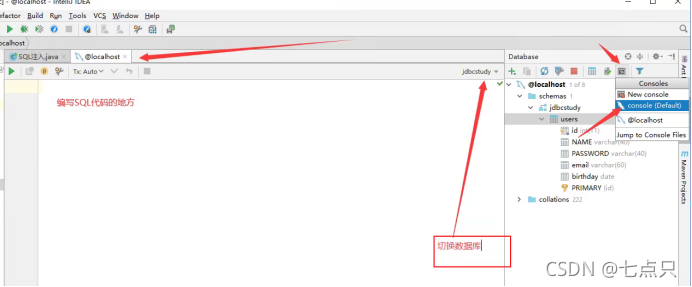
十、JDBC操作事务
1、成功案例:
import com.kuang.lesson02.utils. JdbcUtils;
import java.sql.Connection;
import java.sql.PreparedStatement;
import java.sql.ResultSet;
import java.sql.sQLException;public class TestTransaction1 {
public static void main( String[] args) {
Connection conn = null;
PreparedStatement st = null;
Resultset rs = null;try {
conn = JdbcUtils.getConnection();
//关闭数据库的自动提交,自动会开启事务
conn . setAutoCommit(false); //开启事务
String sql1 = "update account set money = money-100 where name = 'A'";
st = conn. prepareStatement(sql1);
st.executeUpdate();
String sql2 = "update account set money = money+100 where name = 'B'
st = conn. prepareStatement( sq12);
st.executeUpdate( );//业务完毕,提交事务conn. commit();
System.out.println("成功! ");}catch ( SQLException e) {
try {
conn. rol1back()//如果失败则回滚事务
}catch ( SQLException e1) {
e1.printStackTrace();
}
e. printStackTrace();
}finally {
JdbcUtils.release( conn, st,rs) ;
}
}
}2、失败案例:
import com.kuang.lesson02.utils. JdbcUtils;
import java.sql.Connection;
import java.sql.PreparedStatement;
import java.sql.ResultSet;
import java.sql.sQLException;public class TestTransaction1 {
public static void main( String[] args) {
Connection conn = null;
PreparedStatement st = null;
Resultset rs = null;try {
conn = JdbcUtils.getConnection();
//关闭数据库的自动提交,自动会开启事务
conn . setAutoCommit(false); //开启事务
String sql1 = "update account set money = money-100 where name = 'A'";
st = conn. prepareStatement(sql1);
st.executeUpdate();
String sql2 = "update account set money = money+100 where name = 'B'
st = conn. prepareStatement( sq12);
st.executeUpdate( );int x=1/0;//这个语句本来就是错的,所以添加之后,会出错,出错就回滚//业务完毕,提交事务conn. commit();
System.out.println("成功! ");}catch ( SQLException e) {
try {
conn. rol1back()//如果失败则回滚事务
}catch ( SQLException e1) {
e1.printStackTrace();
}
e. printStackTrace();
}finally {
JdbcUtils.release( conn, st,rs) ;
}
}
}解释:虽然执行了第一条语句A给B转了100块钱,但是由于加了一个报错的语句,导致回滚后,会回滚到执行第一条语句之前,所以不存在A给B转钱了B没给A转钱的情况
3、代码实现
①开启事务:conn .setAu toCommit(false);
②一组业务执行完毕,提交事务
③可以在catch 语句中显示的定义回滚语句,但默认失败就会回滚
十一、数据库连接池
1、池化技术:首先我们要知道数据库连接---执行完毕---释放 、 连接--释放是十分浪费资源的,而池化技术就是提前准备一些预先的资源,过来就连接预先准备好的。
就比如一个银行如果每次迎接一个人都要开门--等待--服务---关门,就会很浪费资源,所以我们在里面多加了业务员,让业务员对接顾客,等到完全没有顾客的时候再关门,此时就相当于关闭服务:开门---业务员---等待---服务---关门。此时就涉及到需要多少个业务员,也就是最小连接数
,一般情况下,会根据常用连接数来设置,常用链接数是10,那么最小连接数也设置为10;最大连接数,就可以理解为业务最高承载上线,如果超过最大连接数,那么剩下的人就只能排队等待;等待超时就是如果等待了超过这个时间,就让他自己走,也就告诉他我们这里有异常,不用来了
2、编写连接池,实现一个接口DataSource
(1)开源数据源实现
DBCP
C3PO
Druid: 阿里巴巴
使用了这些数据库连接池之后,我们在项目开发中就不需要编写连接数据库的代码了!
(2)DBCP:
需要用到的jar包
commons-dbcp-1.4.commons-pool-1.6
(3)C3PO
需要用到的jar包
c3pO-0.9.5.5、mchange-commons-java-0.2.19
(4)结论
无论使用什么数据源,本质还是一样的,DataSource接口不会变,方法就不会变
本文来自互联网用户投稿,文章观点仅代表作者本人,不代表本站立场,不承担相关法律责任。如若转载,请注明出处。 如若内容造成侵权/违法违规/事实不符,请点击【内容举报】进行投诉反馈!