概率 + 统计 随机变量及其分布(二)
随机变量
设随机试验的样本空间为S={e}. X=X(e)是定义在样本空间S上的实值单值函数. 称X=X(e)为随机变量.
离散型随机变量的概率分布
随机变量X的所有可能取值是有限多个或可列无限多个, 这种随机变量称为离散型随机变量 。
设X所有可能取的值为, 称
(1)
为离散型随机变量X的分布律。 由概率的定义, 满足如下两个条件
分布律也可用表格的形式来表示:

三个重要的离散型随机变量
(0-1)分布
设随机变量X只可能取0与1两个值, 它的分布律是
则称X服从以p为参数的(0-1)分布或两点分布. (0-1)分布的分布律也可写成
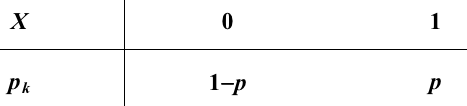
二项分布
用X表示n重贝努利试验中事件A发生的次数,则
称随机变量X 服从参数为n和p的二项分布,记作X~B(n,p)
当n=1时,二项分布就是(0-1)分布。
泊松分布
设随机变量X所有可能取的值为0 , 1 , 2 , … , 且概率分布为:
其中是常数,则称 X 服从参数为
的泊松分布,记作
泊松(Poisson)定理:设是一常数,n是任意正整数,设
则对于任一固定的非负整数k,有
定理表明: n比较大, p很小时, 以n , p为参数的二项分布的概率值可以由参数为l=np的泊松分布的概率值近似。
随机变量的分布函数
设X是一个随机变量,称为X的分布函数,记作F(X)。
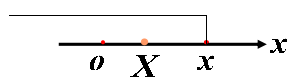
如果将 X 看作数轴上随机点的坐标,那么分布函数 F(x) 的值就表示 X落在区间内的概率。
对任意实数,随机点落在区间
内的概率为:
连续型随机变量 及其分布
对于随机变量 X , 如果存在非负可积函数 ,
,使得对任意实数
,有
则称 X为连续型随机变量, 称
为 X 的概率密度函数,简称为概率密度。
对任意实数,有
对连续型随机变量X , 有
三种重要的连续型随机变量
均匀分布

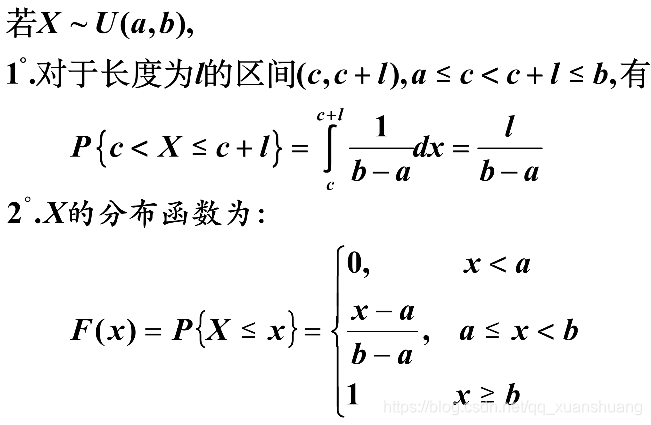
指数分布

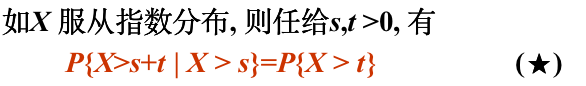
性质(★)称为无记忆性. 指数分布在可靠性理论和排队论中有广泛的运用.
正态分布



标准正态分布


正态分布与标准正态分布的 分布函数之间的关系
若,则
可以认为,X 的取值几乎全部集中在区间内。这在统计学上称作"
准则"
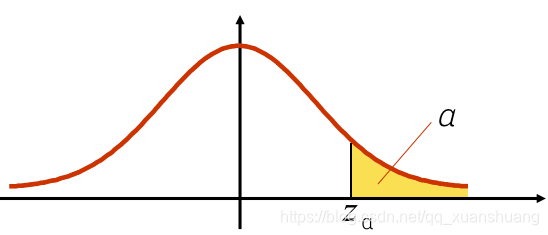
标准正态分布的上分位
设,若
满足条件
,则称点
为标准正态分布的上
分位。
由的对称性知
。
一维随机变量函数的分布
设随机变量 X 的分布已知,Y=g (X) (设g 是连续函数),我们利用 X 的分布来求 Y 的分布。


本文来自互联网用户投稿,文章观点仅代表作者本人,不代表本站立场,不承担相关法律责任。如若转载,请注明出处。 如若内容造成侵权/违法违规/事实不符,请点击【内容举报】进行投诉反馈!