数据结构之集合与映射
数据结构之集合与映射
这一次讲的是集合与映射但是对于一个学Java的学生来说,其实集合和映射是最熟悉的概念,所以我在这里就不说的太细了,集合的源码都看了不止一次了。
集合
简介
这里的集合指的Set也就是可以不能存储重复的元素,只是存储不同的单词的个数。我们还是遵循规范上来先完成一个借口
使用二叉搜索树完成Set
顶级接口
void add(E e);void remove(E e);boolean contains(E e);int getSize();boolean isEmpty();这是在顶级接口中的五个方法头,我只需要完成一个实体类,然后去用实体类实现这个接口,去规范我们的方法名。
构造
private BST bst;public BSTSet() {bst=new BST<>();}
我们使用一个类BSTSet去实现这个接口,这个类的底层采用的是我们之前完成的二叉搜索树,具体的完成的代码可以在我上传的资料里面进行下载,完成一个构造就是new BST<>;
基本方法
@Overridepublic void add(E e) {// TODO Auto-generated method stubbst.add(e);}@Overridepublic void remove(E e) {// TODO Auto-generated method stubbst.remove(e);}@Overridepublic boolean contains(E e) {// TODO Auto-generated method stubreturn bst.contains(e);}@Overridepublic int getSize() {// TODO Auto-generated method stubreturn bst.size();}@Overridepublic boolean isEmpty() {// TODO Auto-generated method stubreturn bst.isEmpty();}
基本的上是使用的全部都是二叉搜索树的东西,添加一个元素直接就是使用的二叉搜索树的添加功能,删除功能也是直接使用了二叉搜索树的方法,包含功能,查看set里面的元素是否会有重复的元素,然后是长度,直接去返回的是底层的二叉搜索树的长度,查询Set是否为空。
使用链表完成Set
简介
使用链表,链表也是使用我之前自己完成的链表
构造
private LinkedLists list;public LinckedListSet() {// TODO Auto-generated constructor stublist=new LinkedLists();}
这个链表Set的底层就是直接是之前自己完成的链表。
基本方法
@Overridepublic void add(E e) {// TODO Auto-generated method stubif(!list.contains(e)) {list.addFirst(e);}}@Overridepublic void remove(E e) {// TODO Auto-generated method stublist.removeElement(e);}@Overridepublic boolean contains(E e) {// TODO Auto-generated method stubreturn list.contains(e);}@Overridepublic int getSize() {// TODO Auto-generated method stubreturn list.getsize();}@Overridepublic boolean isEmpty() {// TODO Auto-generated method stubreturn list.isEmpty();}
这个类写的跟二叉搜索树做底层的Set只有一点不一样的地方,因为我们完成的二叉搜索树默认是忽略相同元素,但是链表不是的,链表就是直接加,不会考虑相同的元素会怎么样,所以在添加的时候需要先看看链表中有没有这个元素如果存在就不会再进行添加。
实验
在这里我们去写一个main方法去试验一个我们的这个Set是够正常使用的吗?然后我们去是用一个自己完成的工具类就是一个从文件中读取的功能public static boolean readFile(String filename, ArrayList我们只需要知道只需要传进去一个字符串类型的文件名,一个 ArrayList的对象用来存储所有的单词。
public static void main(String[] args) {System.out.println("pap");ArrayList arr=new ArrayList();FileOperation.readFile("pride-and-prejudice.txt", arr);System.out.println(arr.size());BSTSet set1=new BSTSet();for (String string : arr) {set1.add(string);}System.out.println(set1.getSize());
}
 这是执行的结果,具体解释一下逻辑,就是我从文件中读取出单词的合数然后,存进BSTSet里面,出现重复的不去管,我是用的文件是傲慢与偏见(英文版),一共是125901个单词,不重复的单词一共是6530个,这个Set效果还是不错的。
这是执行的结果,具体解释一下逻辑,就是我从文件中读取出单词的合数然后,存进BSTSet里面,出现重复的不去管,我是用的文件是傲慢与偏见(英文版),一共是125901个单词,不重复的单词一共是6530个,这个Set效果还是不错的。
复杂度分析
在上一篇博客中的复杂度没有写,我在这里进行一次比较,还是使用上面的读取文件作为测试,我们来进行一次实验,我们完成一个静态方法,在main方法里面直接调用。
public static double testSet(Set set,String filename) {long starttime = System.nanoTime();System.out.println(filename);ArrayList words=new ArrayList();if(FileOperation.readFile(filename, words)) {System.out.println(words.size());for (String string : words) {set.add(string);}System.out.println(set.getSize());}long endtime = System.nanoTime();return (endtime-starttime)/1000000000.0;}
这是静态方法,方法传入一个set和一个文件名,先记录一下开始的时间,然后new一个ArrayList,还是使用我们的遍历文件的方法将所有的单词传到了ArrayList中,然后使用一个set去添加,就可以完成了。
public static void main(String[] args) {String name="pride-and-prejudice.txt";BSTSet bst=new BSTSet();double testSet = testSet(bst, name);System.out.println(testSet);System.out.println();LinckedListSet LLS=new LinckedListSet();double testSet1 = testSet(LLS, name);System.out.println(testSet1);System.out.println();}
我们在main方法中调用就可以完成了,将需要比较的元素直接传入就可以完成了。
 可以看得出二叉搜索树这个数据结构远远比链表要效率高,
可以看得出二叉搜索树这个数据结构远远比链表要效率高,
| 算法 | LinkListedSet | BSTSet(平均) | 最差 |
|---|---|---|---|
| add(增) | O(n) | O(h) | O(n) |
| contains | O(n) | O(h) | O(n) |
| remove | O(n) | O(h) | O(n) |
在这里需要去注意一个问题,就是二叉搜索树确实好用,但是如果插入的元素是迫使二叉搜索树成了一个链表,就是比如说是大量的元素出现在左子树或者是右子树,这是二叉搜索树的效率就是最低的O(n),二叉搜索数平均复杂度是O(h),h是二叉树的高度,h=log(n),所以我们在后面回去学习AVL树,这个树可以进行自旋,还有红黑树,建立在AVL的基础上的树,可以通过变化颜色进行自旋插入元素,还有B树和B+树,是建立在红黑树的基础之上的数据结构,是数据库的底层,具体的信息可以去看我的博客,我有一篇博客是大量的讲解树的。
映射
简介
什么是映射呢?从字面上去分析是指的数学上的映射,一一对应的关系,一个对一个关系,也就是我们说的一对一的关系,我们在Java用Map来表示,在Map中使用键值对来表示,一个键对应着一个值,其实的话也就是一个key对应着一个value,这个是一一对应的。
顶级接口
我们跟完成Set的接口一样需要先去定义一个接口,在这个接口中去规定我们应该使用的方法。
void add(K key,V value);V remove(K key);boolean contains(K key);V get(K key);void set(K key,V value);int getsize();boolean isEmpty();接口定义的 方法大多大同小异,但是因为是在Map中所以再添加元素和修改元素设置元素的时候要考虑将键和值一起加入到一个Map中去。然后我们去实现一个实体类去将这个接口进行继承。
实体类LinkesListMap
这个就是我们想要去实现的实体类,然后我们需要去实现我们的顶级接口,去将我们的方法实现。
构造
private Node dummuHead;private int size;public LinkesListMap(){dummuHead = new Node();size = 0;}
我们这里是使用的链表作为底层的映射,dummuHead是我们的虚拟头结点,我们在向链表中插入表头元素时更加的简单方便。
内部类–节点
private class Node{public K key;public V value;public Node next;public Node(K key,V value,Node next) {this.key=key;this.value=value;this.next=next;}public Node(K key,V value){this(key,value,null);}public Node() {this(null, null,null);}@Overridepublic String toString() {// TODO Auto-generated method stubreturn key.toString()+" "+value.toString();}}
这个就是我们使用的链表的底层,但是和我们平常使用的链表还是不一样,在这里我们存放了两个类的对象,key和value这两个类的变对象的类型可以有我们自己指定,然后是指向了下一个key,value对。
基础方法
@Overridepublic int getsize() {// TODO Auto-generated method stubreturn size;}@Overridepublic boolean isEmpty() {// TODO Auto-generated method stubreturn size==0;}@Overridepublic void add(K key, V value) {// TODO Auto-generated method stubNode node=getNode(key);if(node==null) {dummuHead.next=new Node(key, value, dummuHead.next);}else {node.value=value;}}@Overridepublic V remove(K key) {// TODO Auto-generated method stubNode prev=dummuHead;while(prev.next!=null) {if(prev.next.key.equals(key)) {break;}prev=prev.next;}if(prev.next!=null) {Node delNode=prev.next;prev.next=delNode;delNode.next=null;return delNode.value;}return null;}@Overridepublic boolean contains(K key) {// TODO Auto-generated method stubreturn getNode(key)!=null;}@Overridepublic V get(K key) {// TODO Auto-generated method stubNode node =getNode(key);return node==null?null:node.value;}@Overridepublic void set(K key, V value) {// TODO Auto-generated method stubNode node=getNode(key);if(node==null) {throw new IllegalArgumentException("bucunzai");}node.value=value;}
添加方法中先将key去new一个新的Node,如果key为空,则直接添加,否则的话就改变value的值。删除操作先去找到key值得对应的node,然后去使用移除这个链表中移除Node节点的方法去移除就好了。更新操作是找到key的节点的值,然后去更新他的value。
测试
我们写一个main函数来将这个链表的映射实现一下,用来打印两个单词出现的次数。
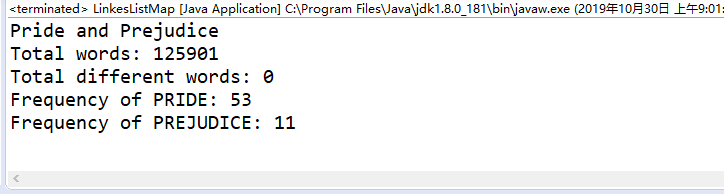
public static void main(String[] args) {System.out.println("Pride and Prejudice");ArrayList words = new ArrayList<>();if (FileOperation.readFile("pride-and-prejudice.txt", words)) {System.out.println("Total words: " + words.size());LinkesListMap map = new LinkesListMap<>();for (String word : words) {if (map.contains(word))map.set(word, map.get(word) + 1);elsemap.add(word, 1);}System.out.println("Total different words: " + map.getsize());System.out.println("Frequency of PRIDE: " + map.get("pride"));System.out.println("Frequency of PREJUDICE: " + map.get("prejudice"));}System.out.println();}
实体类BSTMap
我们使用BST二叉搜索树来完成一个Map的结构,因为是底层是树,所以和链表就有所不同。
节点Node
private class Node{public K key;public V value;public Node left,right;public Node(K key,V value) {this.key=key;this.value=value;left=null;right=null;}}private Node root;private int size;
我们在这里需要注意的是,我们没有办法全部使用树的结构,于是我们就定义一个节点,里面存放键值对,指向左子树右子树的地址。
基础代码
@Overridepublic int getsize() {// TODO Auto-generated method stubreturn size;}@Overridepublic boolean isEmpty() {// TODO Auto-generated method stubreturn size==0;}
获取二叉搜索树的长度和判断搜索二叉树是否为空的方法。
元素的增加
/*** 添加的方法*/@Overridepublic void add(K key, V value) {// TODO Auto-generated method stubroot=add(root,key,value);}/*** 添加的具体的实现* @param node* @param key* @param value* @return*/private Node add(Node node ,K key, V value) {if(node==null) {size++;return new Node(key,value);}if(key.compareTo(node.key)<0) {node.left = add(node.left,key,value);}else if(key.compareTo(node.key)>0){node.right = add(node.right,key,value);}else {node.value=value;}return node;}
具体的逻辑是将我们主要的功能代码放在了private的重写方法中,在private方法中传入三个值,一个是Node的结点,一个key,一个是value,如果Node节点是null,就使用key和value去new 一个Node,并且返回,是这个Node元素接在他应该接的位置上,然后如果他不是nul,代表这个树在寻找一个位置,所以我们就要比较他的值,比较key的值,比较Node节点的key和我们新传入的key的值,去找到这个节点应该应该在的位置。
最后一个else有一种情况就是有相同的key但是value不同可以是直接去替换,在Java成型的集合中,使用的是put的方法来进行完成的,put方法中,如果没有这个元素则进行添加操作,但是如果这个元素存在比较两者的value值,如果不同则旧的就会顶替掉新的。
修改结点的值
private Node getNode(Node node,K key) {if(node==null) {return null;}if(key.compareTo(node.key)==0) {return node;}else if(key.compareTo(node.key)<0) {return getNode(node.left, key);}//>else {return getNode(node.right, key);}}@Overridepublic void set(K key, V value) {// TODO Auto-generated method stubNode node=getNode(root, key);if(node==null) {throw new IllegalArgumentException("does not exist");}node.value=value;}
在这里我们并只是使用一个add方法来修改节点的值,我们来使用一个自己完成的元素对于元素进行修改,这里我们先完成一个辅助的方法,getNode,这个方式,我放进去一个Node节点和key的值,这个方法的作用是找到这个key值所在的节点,并且返回这个节点的值,然后就是set,由getNode返回的Node的节点,然后直接去修改这个节点中的值。
删除操作
@Overridepublic V remove(K key) {// TODO Auto-generated method stubNode node=getNode(root, key);if(node!=null) {root=remove(root,key);return node.value;}return null;}private Node remove(Node node,K key) {if(node==null) {return null;}//左子树找到位置if(key.compareTo(node.key)<0) {node.left=remove(node.left, key);return node;}//右子树找到位置else if(key.compareTo(node.key)>0) {node.right=remove(node.right, key);return node;}//找到位置else {//左子树为空if(node.left==null) {Node rightNode=node.right;node.right=null;size--;return rightNode;}//右子树为空if(node.right==null) {Node leftNode=node.left;node.left=null;size--;return leftNode;}//找到指定位置右子树中最小的一个节点,当做根Node success=minimun(node.right);//删除这个最小的元素success.right=removeMin(node.right);//承接他的左子树success.left=node.left;node.left=node.right=null;return success;}}private Node minimun(Node node) {if(node.left==null) {return node;}return minimun(node.left);}
使用的是搜索二叉树的删除的方法,上面有使用的方法的注释。
试验
我们在这里比较一下我们完成的这个二叉搜索树和链表的Map哪一个效果会变得更好,我们还是使用一个main方法来带用一个静态方法,方法里传入一个借口,还有我们上面用的文件名,还是通过遍历文件来实现这个问题。
public static double testmap(Map map, String filename) {long start = System.nanoTime();System.out.println(filename);ArrayList words = new ArrayList<>();if (FileOperation.readFile("pride-and-prejudice.txt", words)) {System.out.println("Total words: " + words.size());for (String word : words) {if (map.contains(word))map.set(word, map.get(word) + 1);elsemap.add(word, 1);}System.out.println("Total different words: " + map.getsize());System.out.println("Frequency of PRIDE: " + map.get("pride"));System.out.println("Frequency of PREJUDICE: " + map.get("prejudice"));}System.out.println();long end = System.nanoTime();return (end-start)/1000000000.0;}public static void main(String[] args) {String filename="pride-and-prejudice.txt";BSTMap bst=new BSTMap();double time1 = testmap(bst, filename);System.out.println(time1);LinkesListMap bst1=new LinkesListMap();double time2 = testmap(bst1, filename);System.out.println(time2);}  这个就是我们实现的结果,最后能看得出来,二叉搜索树的效率远远的大于链表,同样是一个Map,但是在时间复杂度上效率差距的很大。
这个就是我们实现的结果,最后能看得出来,二叉搜索树的效率远远的大于链表,同样是一个Map,但是在时间复杂度上效率差距的很大。
| 操作 | LinkedListMap(链表Map) | BSTMap(二叉搜索树Map) | 平均 |
|---|---|---|---|
| 增add | O(n) | O(h) | O(logn) |
| 删remove | O(n) | O(h) | O(logn) |
| 改set | O(n) | O(h) | O(logn) |
| 查get | O(n) | O(h) | O(logn) |
| 查contains | O(n) | O(h) | O(logn) |
本文来自互联网用户投稿,文章观点仅代表作者本人,不代表本站立场,不承担相关法律责任。如若转载,请注明出处。 如若内容造成侵权/违法违规/事实不符,请点击【内容举报】进行投诉反馈!