Elasticsearch-Pipeline Aggregation
-
管道概念:支持对聚合分析的结果进行再次聚合分词

-
Pipeline的分析结果会输出到原结果中,根据位置的不同,分为两类
-
Sibling --结果和现有分析结果同级
-
mac,min,avg & sum Bucket
-
Stats,Extended Status Bucket
-
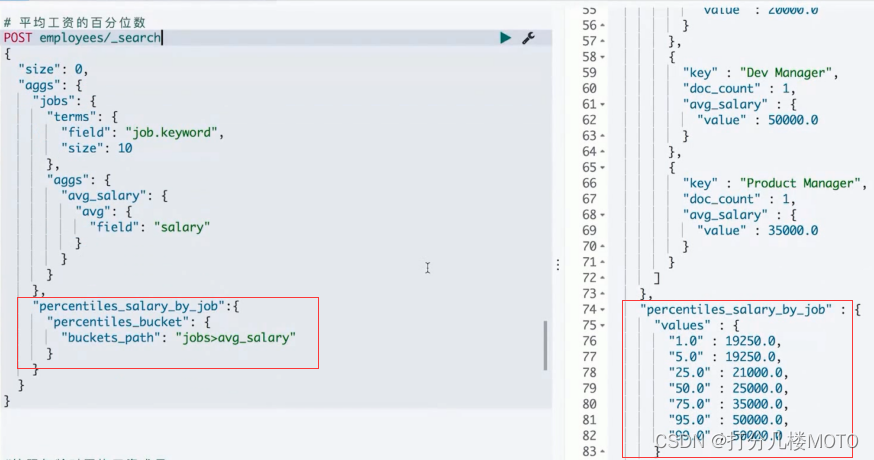
Percentiles Bucket
-
-
POST /employees/_search
{
"size":0,
"aggs": {
"jobs": {
"terms": {
"field": "job.keyword",
"size": 10
},
"aggs": {
"avg_salary": {
"avg": {
"field": "salary"
}
}
}
},
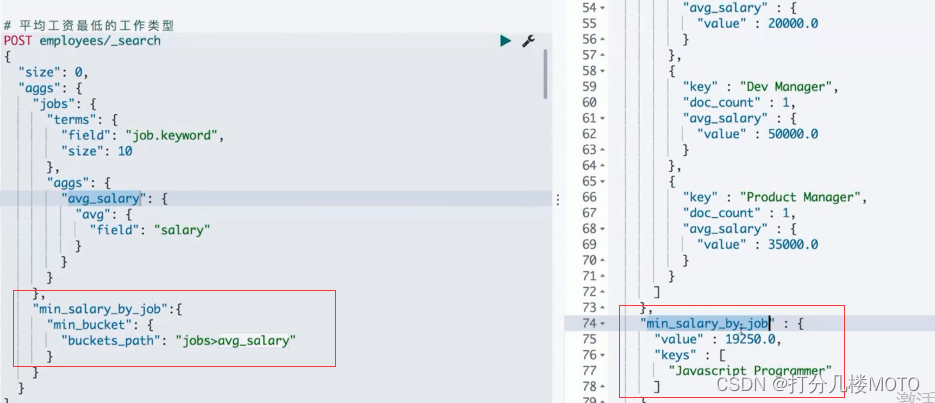
"min_salary_job":{
"min_bucket": {
"buckets_path": "jobs>avg_salary"
}
}
}
}
POST /employees/_search
{
"size":0,
"aggs": {
"jobs": {
"terms": {
"field": "job.keyword",
"size": 10
},
"aggs": {
"avg_salary": {
"avg": {
"field": "salary"
}
}
}
},
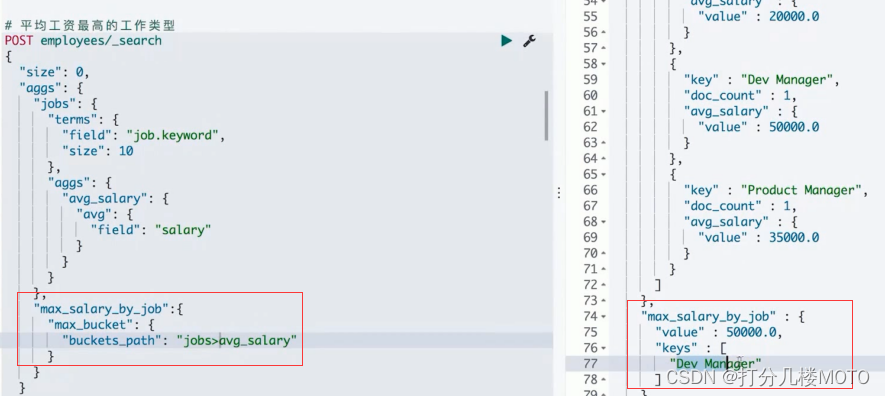
"min_salary_job":{
"max_bucket": {
"buckets_path": "jobs>avg_salary"
}
}
}
}
POST /employees/_search
{
"size":0,
"aggs": {
"jobs": {
"terms": {
"field": "job.keyword",
"size": 10
},
"aggs": {
"avg_salary": {
"avg": {
"field": "salary"
}
}
}
},
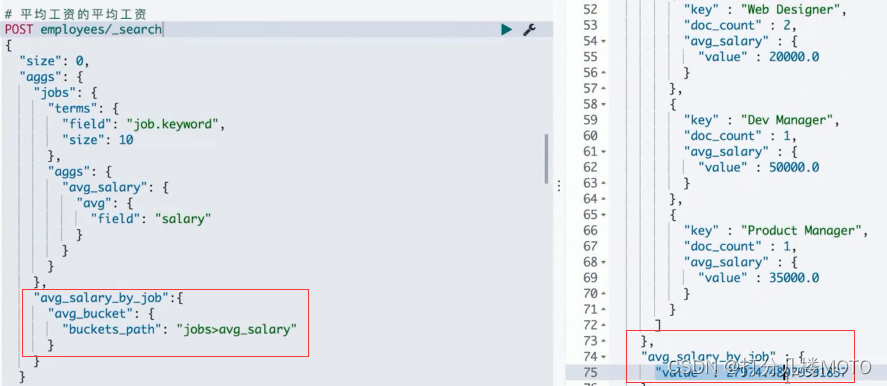
"min_salary_job":{
"avg_bucket": {
"buckets_path": "jobs>avg_salary"
}
}
}
}
POST /employees/_search
{
"size":0,
"aggs": {
"jobs": {
"terms": {
"field": "job.keyword",
"size": 10
},
"aggs": {
"avg_salary": {
"avg": {
"field": "salary"
}
}
}
},
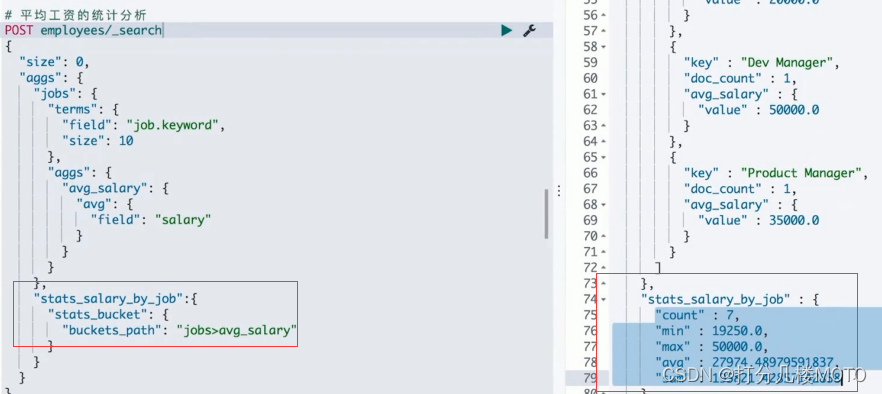
"min_salary_job":{
"stats_bucket": {
"buckets_path": "jobs>avg_salary"
}
}
}
}
POST /employees/_search
{
"size":0,
"aggs": {
"jobs": {
"terms": {
"field": "job.keyword",
"size": 10
},
"aggs": {
"avg_salary": {
"avg": {
"field": "salary"
}
}
}
},
"min_salary_job":{
"percentiles_bucket": {
"buckets_path": "jobs>avg_salary"
}
}
}
}
-
Parent --结果内嵌到现有的聚合分析结果之中(对分桶内部进行聚合)
-
Derivative (求导)
-
Cumultive Sum (累计求和)
-
Moving Function (滑动窗口)
-
moving_avg
-
bucket_script:会对每个桶执行一段脚本, 运算结果会添加到父聚集的结果中
-
bucket_selector:执行一段脚本,但它执行的结果一定是布尔类型, 并且决定当前桶是否出现在父聚集的结果中
-
bucket_sort:根据每桶中的具体指标值决定桶的次序
-
serial_diff
-
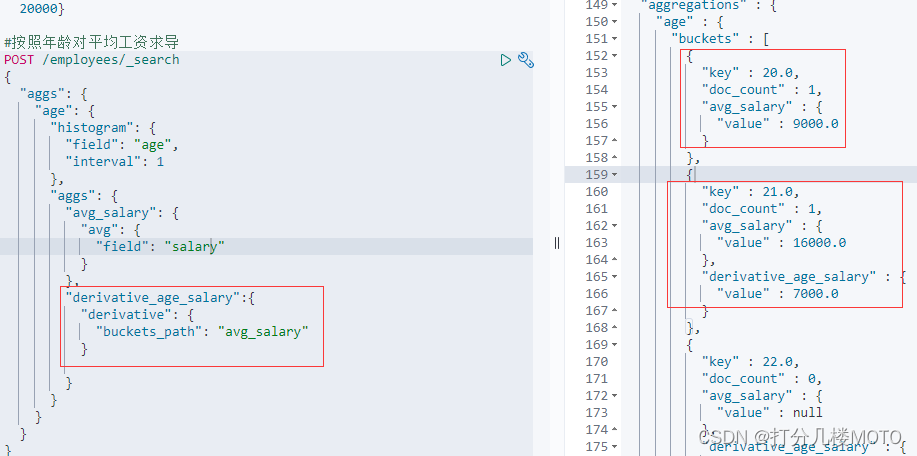
按照年龄对平均工资求导
POST /employees/_search
{
"aggs": {
"age": {
"histogram": {
"field": "age",
"interval": 1
},
"aggs": {
"avg_salary": {
"avg": {
"field": "salary"
}
},
"derivative_age_salary":{
"derivative": {
"buckets_path": "avg_salary"
}
}
}
}
}
}
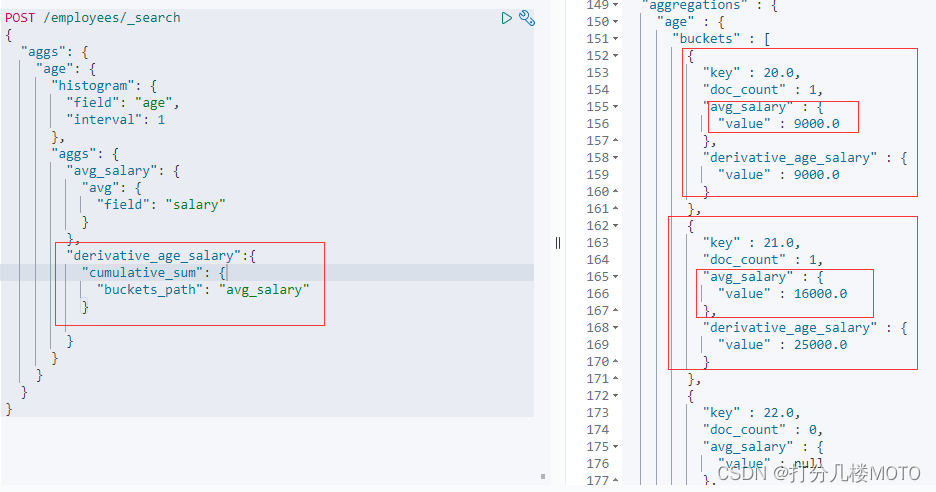
对平均工资进行累计求和
POST /employees/_search
{
"aggs": {
"age": {
"histogram": {
"field": "age",
"interval": 1
},
"aggs": {
"avg_salary": {
"avg": {
"field": "salary"
}
},
"derivative_age_salary":{
"cumulative_sum": {
"buckets_path": "avg_salary"
}
}
}
}
}
}
moving_fn
- 由于使用滑动窗口运算时每次移动1个位置,这就要求moving_fn所在聚集桶与桶间隔必须固定,所以这两种管道聚集只能在histogam和date_histogam聚集中使用
- moving_fn管道聚集则可以对落在窗口内的父聚集结果做各种自定义的运算
POST /employees/_search
{
"aggs": {
"age": {
"histogram": {
"field": "age",
"interval": 1
},
"aggs": {
"avg_salary": {
"avg": {
"field": "salary"
}
},
"moving_avg_salary":{
"moving_fn": {
"buckets_path": "avg_salary",
"window": 10,
"script":"MovingFunctions.min(values)"
}
}
}
}
}
}
-
在示例中,最外层的父聚集day_price是1个date_histogam桶型聚集,它根据文档的timestamp字段按天将文档分桶。day_price聚集包含avg_price和smooth_price两个子聚集,其中avg_price聚集是一个求AvgTicketPrice字段在1个桶内平均值的avg聚集,而smooth_price则是一个使用滑动窗口做平均值平滑的管道聚集,窗口宽度由参数window设置为10,默认值为5。
通过返回结果比较avg_price与smooth_price就会发现,后者由于经过了滑动窗口运算,数据变化要平滑得多。moving_fn聚集包含一个用于指定运算脚本的script参数,在脚本中可以通过values访问buckets_path参数指定的指标值。moving_fn还内置了一个MovingFunctions类,包括多个运算函数:
- max()
- min( )
- sum( )
- stdDev( ) 标准偏差
- unweightedAvg( ) 无加权平均值
- linearWeightedAvg( ) 线性加权移动平均值
- ewma( ) 指数加权移动平均值
- holt( ) 二次指数加权移动平均值
- holtWinters( ) 三次指数加权移动平均值
bucket_script、bucket_selector、bucket_sort
POST /kibana_sample_data_flights/_search?filter_path=aggregations
{
"aggs": {
"date_price_diff": {
"date_histogram": {
"field": "timestamp",
"fixed_interval": "1d"
},
"aggs": {
"stat_price_day": {
"stats": {
"field": "AvgTicketPrice"
}
},
"diff": {
"bucket_script": {
"buckets_path": {
"max_price": "stat_price_day.max",
"min_price": "stat_price_day.min"
},
"script": "params.max_price - params.min_price"
}
},
"gt990": {
"bucket_selector": {
"buckets_path": {
"max_price": "stat_price_day.max",
"min_price": "stat_price_day.min"
},
"script": "params.max_price - params.min_price > 990"
}
},
"sort_by": {
"bucket_sort": {
"sort": [
{
"diff": {
"order": "desc"
}
}
]
}
}
}
}
}
}
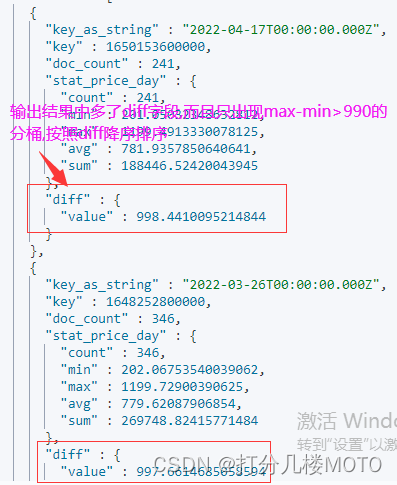
- diff是一个 bucket_script管道聚集,它的作用是向最终聚集结果中添加 代表最大值与最小值之差的diff字段。它通过buckets_path定义了两个参数max_price和min_price,并在script参数中通过脚本计算了这两个值的差作为最终结果,而这个结果将出现在整个聚集结果中
- gt990是一个bucket_selector管道聚集,它的作用是筛选哪些桶可以出现在最终的聚集结果中。它也在buckets_path中定义了相同的参数,不同的是它的script参数运算的不是差值,而是差值是否大于990,即“ params.max_price - params.min_price > 990 "。如果差值大于990即运算结果为true,那么当前桶将被选取到结果中,否则当前桶将不能在结果中出现
- sort_by是一个bucket_sort管道聚集,它的作用是给最终的聚集结果排序。它通过sort参数接收一组排序对象,在示例中是使用diff聚集的结果按倒序排序。所以示例整体的运算效果就是将那些票价最大值与最小值大于990的桶选取出来,并在桶中添加diff字段保存最大值与最小值的差值,并按diff字段值降序排列。
本文来自互联网用户投稿,文章观点仅代表作者本人,不代表本站立场,不承担相关法律责任。如若转载,请注明出处。 如若内容造成侵权/违法违规/事实不符,请点击【内容举报】进行投诉反馈!